








12月5-6日,由智猩猩与智东西联合主办的2024中国生成式AI大会(上海站)在上海圆满收官。在第二日的「AI Infra峰会」上,GMI Cloud亚太区总裁King Cui发表了主题为《全球化布局:AI企业如何补齐算力短板,保障GPU集群稳定性》的演讲。
GMI Cloud成立于2023年,是一家AI Native Cloud服务商,旨在为企业AI应用提供最新、最优的GPU资源,为全球新创公司、研究机构和大型企业提供稳定安全、高效经济的AI云服务解决方案。其研发团队主要来自谷歌X Lab,具备丰富的AI领域专业知识。King Cui是云计算领域资深专家,已有十几年从业经验,今年正式加入GMI Cloud。
本次演讲中,King Cui分享道,“目前中国AI出海处于加速期,算力作为其中的核心生产资料正发挥重要作用。构建高稳定性的GPU集群是实现AI出海降本增效的必由之路,可以帮助企业在AI全球化浪潮中取胜。”
在确保GPU集群的高稳定性方面,GMI Cloud除了拥有稳定的尖端GPU芯片优势以外,其还自主研发了Cluster Engine,整合了对GPU卡、GPU节点、高速存储以及高速网络的控制,为客户提供三种核心服务形态:裸机、虚拟机、容器。这些服务在不同的层面上支持AI机器学习、基础平台设施以及HPC高性能运算。此外,作为Nvidia全球Top10 NCP,GMI Cloud在交付前会进行严格的验证流程。
GMI Cloud还与IDC协作,拥有充足的备件,提供及时的维修,在更短的交付时间,确保停机时间最小化。另外值得一提的是,他们灵活的选型方案符合各类AI出海企业需求,King Cui在大会现场进行演讲时引起众人关注。
以下为King Cui的演讲实录:
今天给大家分享的主题是,在AI全球化的布局下,AI企业如何在海外补齐高端GPU的算力短板,并且保证整个GPU集群的稳定性。
一、快速了解一下GMI Cloud
首先我们来快速认识下GMI Cloud。GMI Cloud是一家AI Native Cloud公司,我们专门做AI时代的GPU Cloud。关于我们公司,主要有三点:
1.我们是全球Top10的Nvidia Cloud Partner,也是Nvidia Preferred Partner,可以提供英伟达全套最新最强的GPU云服务。
2.我们与英伟达是战略合作伙伴关系,同时获得了全球顶级GPU ODM厂商的投资,在亚太区有GPU的优先分配权,能在最短时间拿到最新最强的GPU。现在亚太很多云厂商还没有提供H200的服务,但我们已经在今年八月份就向客户提供H200云服务,目前具备几千卡的H200集群。
3.我们致力于为所有AI企业打造一套独立的AI云原生平台,不做贸易,只做AI Cloud。我们希望为所有企业提供具备高稳定性的GPU集群云服务。
我们致力于为所有企业提供一套稳定、高效、安全、好用的GPU Cloud,铸就全球领先的AI Cloud。目前我们在美国、中国台湾、泰国、马来西亚等多个国家和地区提供云服务,主要提供H100和H200,集群总规模接近万卡规模。今年十月份,GMI Cloud刚刚完成8200万美金的A轮融资,这笔资金将也将用于GMI Cloud在全球AI算力服务方面的布局。
二、中国AI出海是大势所趋,算力需求和GPU集群稳定性是核心痛点
介绍完公司,我们来讲第二部分,AI出海的趋势和算力的挑战。我们为什么要做一家出海的云服务公司呢?在分析这点之前,我们要首先回顾过去中国30多年经济高速发展的2个核心底层因素。
第一是人口红利和城镇化的高速发展,这个底层因素带动了产业高速发展,推动了中国经济GDP高速增长。
第二个底层驱动的核心因素是通信基础设施的发展。从2G到3G到4G到5G,通信基础设施的发展使得人机交互的信息传输媒介发生了从文字、图片、视频的演进。移动互联网的高速发展催生了很多新创公司,也使得国内几个头部云计算厂商实现了几百亿人民币市值的跃迁。
但到今天,这两个核心因素已经进入失速期。中国的城镇化率已经高达66%,中国移动网民用户数量接近11亿,AI时代正式来临,出海趋势比较明晰了,所以我们一定要做出海。
从技术的发展来看,我们这代人是非常幸运的,我们经历了整个互联网时代的发展和移动互联网时代的演进,目前正在进入AI时代。从1990年到2010年的20年是互联网时代,从2005年到2020年的15年是移动互联网时代,但这两个时代都已经进入技术普惠点,不再有高速增长的机会。从2022年开始,AI时代兴起,就像1995年的互联网时代一样,未来会有巨大的机会。它的发展速度会比以前每个时代都更加猛烈,所以我们要抓住这波人工智能浪潮。
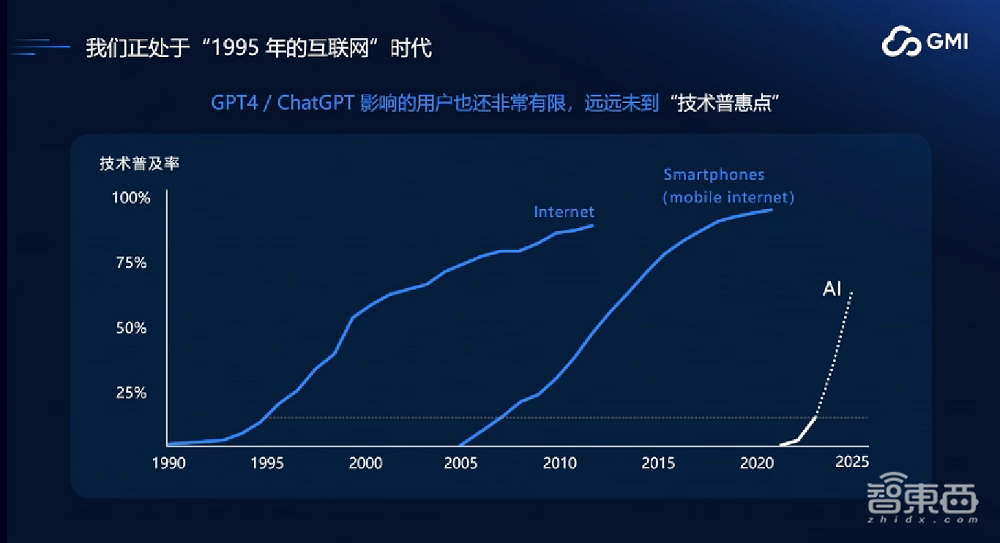
当前行业的发展趋势是,做AI就一定要做出海。我相信所有企业在做AI的同时,一定要立足于全球,一定要做全球化的生意。截止到今年8月份,全球AI产品总量大概有1717个,其中中国相关的AI产品有280个,出海相关的接近95个,超过三分之一。
我截取了AI产品榜前30名的APP,中国AI出海的APP前9个月的时间,整体MAU(月度活跃用户)已经翻了一倍,并且还在高速增长。但从MAU角度来看,相比第一名的ChatGPT,中国企业还有很大的增长空间。

AI出海趋势的底层是中国的产品力竞争。AI有三要素:算法、数据和算力,算力是非常核心的生产资料。那我们出海时如何解决算力问题?
中国的国产GPU很强,但相比高端GPU来讲还有一定差距。因为各种原因,我们国内在高端优先的顶尖GPU储备量不够。同时,AI时代的发展时间不长,大家对于推理稳定性的运维经验也不足。
所以,我们在海外时发现,所有的IDC、服务器、能源等供应商,他们的标准化和稳定性的考量也不充分。所以,目前在海外做AI推理面临的最大挑战就是稳定性问题。
这个图(下图)大家并不陌生,Meta了公布Llama 3-405B大模型用了16000张H100的卡,训练了54天,总共出现了466次故障中断,其中419次是意外发生的,而GPU相关的高达200多次。Meta是全球顶尖的互联网公司,他们有非常强大的推理能力,但大部分厂商在面对这么高故障率的GPU集群时,是难以应对的,所以选择一个非常稳定的GPU服务提供商是十分关键的。
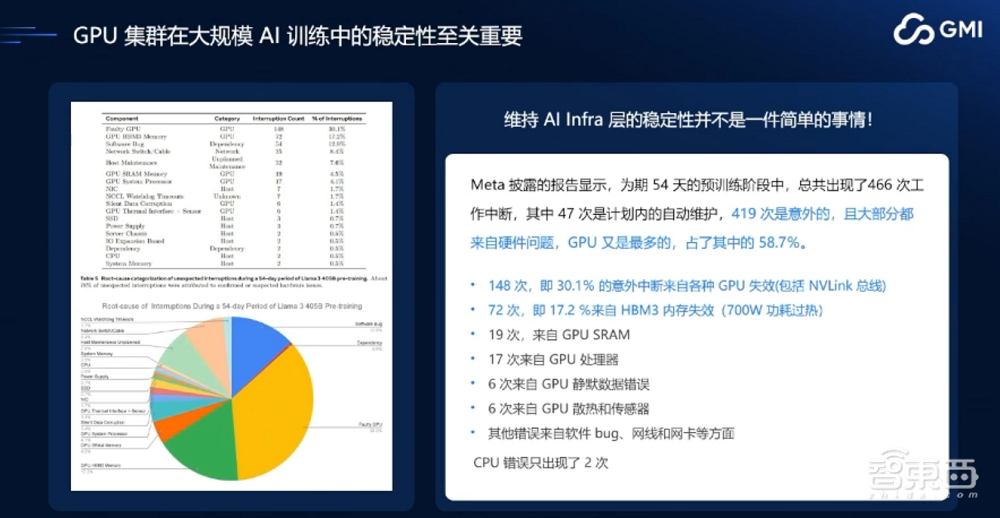
GPU集群的稳定性与公司付出的经济成本(含研发成本)有直接联系,在出海时有人想选择最便宜的GPU裸金属服务提供方,这也许在GPU单价上节省了10%-20%,但如果稳定性不够,整个公司研发的总成本可能会成倍增长。
从公司总体成本来讲,选择一个具备高稳定性、安全高效的GPU云服务提供方,总成本其实更低。所以无论是降本还是增效,选择高稳定性的GPU集群是最重要的。
三、Cluster Engine、NCP验证体系、故障预防策略“三管齐下”,承诺99%SLA
GMI Cloud如何保证GPU集群的高稳定性,面对故障时的应对措施又是怎样的?
GMI Cloud致力于对外提供全栈AI应用平台。
- 最底层的硬件架构层,我们提供高性能的GPU服务器,包括大容量的存储系统以及高带宽的数据通道。
- IaaS层,我们完成了所有容器化的梳理,今年年底我们还会推出Serverless技术。同时我们对网络和存储都做了API的封装,可以以API方式对外提供服务。IaaS层和GPU硬件架构层所有相关软件技术完全由GMI Cloud自主研发和管控。
- 再往上是模型层。开发者或小微企业可以直接使用开源的大模型。这时我们可以提供更多便利性,支持一站式把开源大模型直接部署到我们的集群,不需要做任何代码开发就可以直接上手使用。
具备技术实力的公司可以在我们集群上部署自己的大模型做fine-tuning,我们可以提供专家服务,帮助大家把模型训练得更好。
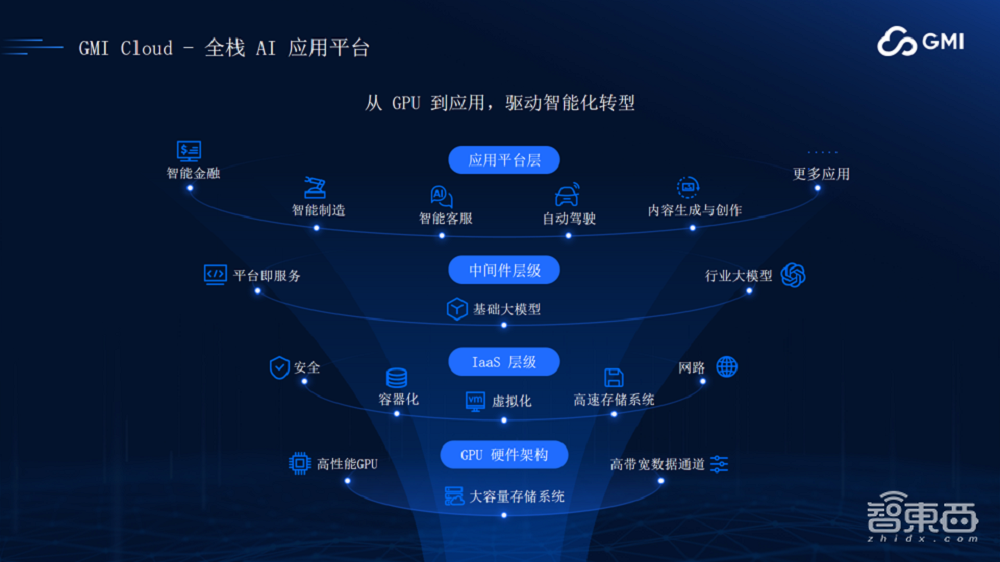
对于整个GPU集群的管理,我们自主研发了一套平台,叫Cluster Engine,能够实现所有资源的调度和管理。
在计算层面的资源调度,GMI Cloud提供裸金属、虚拟机还有容器化等服务。在存储层面,GMI Cloud提供基于NVME和RDMA的高性能分布式存储,也包括冷热分离。我们完成了所有形态的研发。在网络层面,我们支持IB虚拟化,能够帮助企业客户使用更加高速稳定的IB网络。

这里举个例子,这是一个万卡集群的IB网络架构(见下图),总共用了1280台H100服务器,总共有10264张卡,也是一个常见的400G×8的3.2T的三层IB高速网络架构。这里面有一万多张H100的GPU卡,如果从正常的SLA表现来看,可能每3-4个小时就会中断一次。
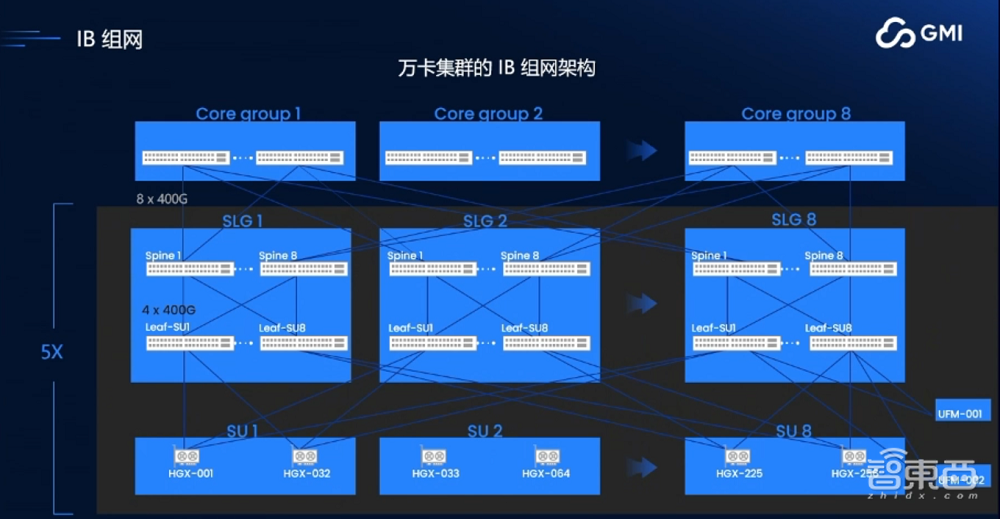
目前我们公司是为数不多真正具备万卡IB网络集群运维实践的公司。在网络虚拟化层面,我们也做了许多相关技术,能够最大化利用资源,具体有三个好处:第一,通过网络虚拟化,我们在资源管理上能做到很好的隔离,使不同用户之间不会发生资源争抢,提高整个IB网络的使用效率;第二,性能会有提升;第三,成本会优化。
通过虚拟化技术,我们提高了现有集群的硬件使用效率,从而进一步优化整体成本。基于IB网络,我们实现了VPC参考架构,这个VPC与传统云计算的VPC没有太大差异,只是每个VPC里面用的是IB网络。比如在国外某所大学的私有GPU集群里,我们提供了IB网络的VPC,可以把不同学院、不同教授的实验分配到不同VPC中,各个之间不会发生资源隔离和争抢,这对客户来说是很好的体验。
讲完容器和网络,我们再看存储。我们基于不同场景做了存储分级。如果是做备份需求,我们可以提供成本较优的SATA存储。如果是对时效性要求高、吞吐较高的场景,比如做模型训练的Checkpoint存储,或者自动驾驶数据加载的高性能读写存储,我们提供了基于NVME的GPFS存储系统。根据不同场景需求,我们提供不同性价比的存储产品。
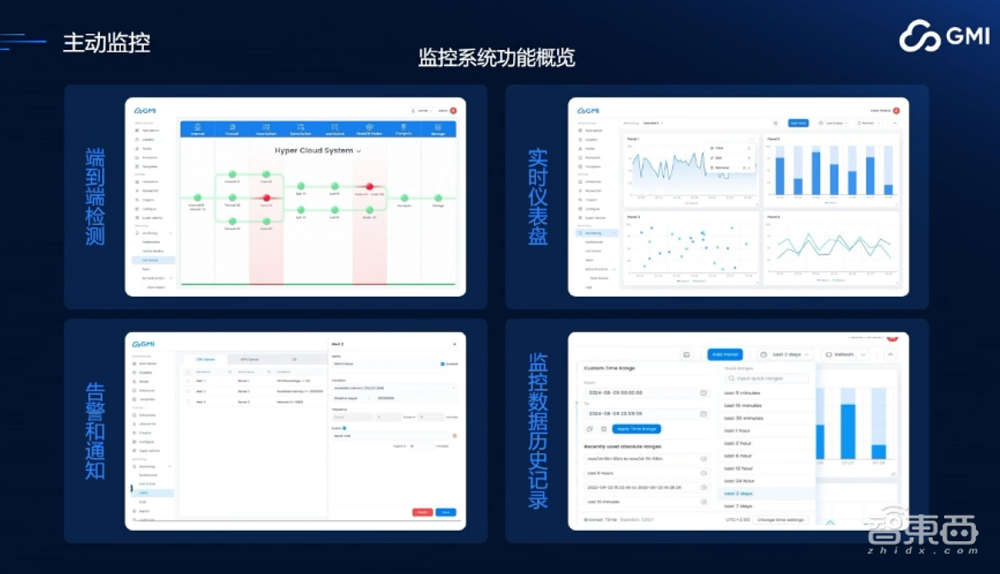
对于大规模集群来说,可观测性非常重要。我们提供了主动监控功能,通过自研平台能够实时监控和告警,并且快速定位问题,在最短时间恢复集群。这是我们集群目前提供的端到端检测、实时仪表盘、故障告警通知及数据历史记录监控(下图),“端到端监测”是目前很多客户反馈非常方便的定位功能,我们可以发现是哪个节点、哪台机器出了问题,快速进行修复和调整。
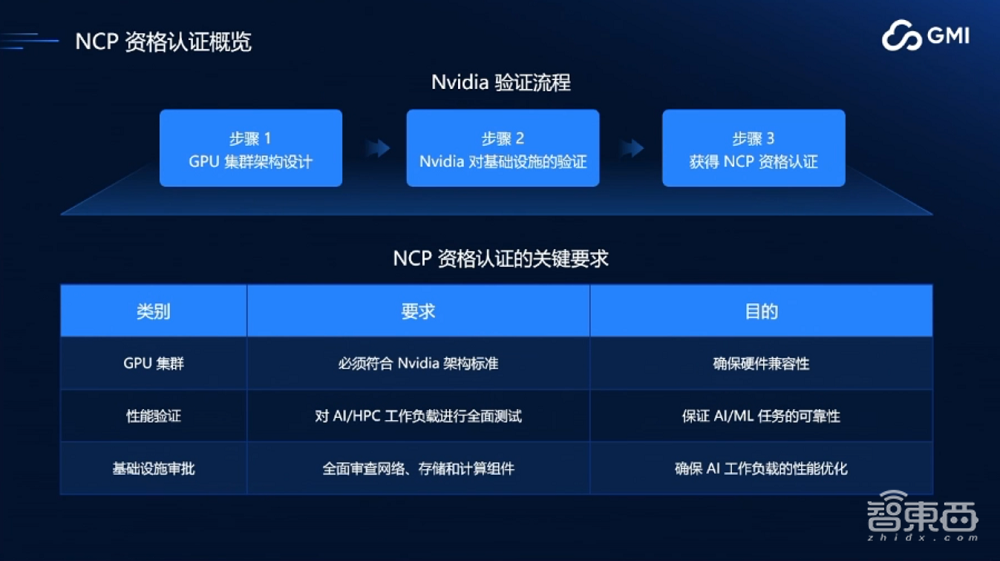
然后再讲一讲GMI Cloud的验证体系。为了保证集群的高稳定性,GMI Cloud有两套体系:第一套是作为Nvidia Cloud Partner的Nvidia验证体系,第二套是在真正交付给客户之前的、GMI Cloud自有稳定性验证测试体系。
Nvidia的NCP认证体系非常严格。首先要做整个集群方案设计,然后通过NCP评估,再做整个集群建设。建设完成后Nvidia会派人检查和测试,最终才能获得资质许可。
此外,在交付之前的验证,我们还会自己做硬件层面测试、系统配置测试,对网络和存储做压力测试,确保这套集群既能实现单机测试,也能实现整个跨集群分布式训练需求。
第三部分,我们看看故障的预防策略和应对措施。没有人能保证集群稳定性达到100%,难免会出现一些问题,比如GPU硬件的掉卡或故障。我们要在最短时间内实现硬件替换。GMI Cloud与IDC伙伴和ODM厂商保持深度紧密的合作关系。我们有3-5%的备机率和备件率,能在硬件故障时通过IDC本地伙伴快速更换。
通过问题源头追溯和SLA签订,我们能对外承诺使用Cluster Engine的GPU云服务可达到99%的SLA。这是目前全球GPU云服务厂商中为数不多能在合同中约定99%SLA的厂商。同时我们提供7×24小时服务响应及技术咨询服务,确保快速解决硬件故障,减少停机时间,为客户保持高稳定性系统。
四、研发团队来自谷歌X Lab,可提供私有、按需两种方案
接下来,我想讲讲对AI Infra选型的思考,并结合两个实际案例进行分享。
在出海过程中,选型有几个因素需要考虑。AI场景中,是长期租用还是短期租用?还要根据业务需求选择是做推理还是训练,同时也要根据经济情况,选择目前普遍使用的H100,或性能更高的H200,亦或未来会推出的GB200。
综合考虑,我们提供两种方案:第一种是Private Cloud,可以根据客户需求和地点选择,在全球合法的国家和地区帮助选择IDC,定制GPU服务器,提供长期稳定服务。第二种是On-Demand的标准产品,可以按卡时计费。客户可能只需要使用一两张卡,训练一两天就释放,不需要为短期GPU需求付出高昂的购机成本。
除了以上所讲,我们还提供专业的AI顾问和咨询服务。我们的研发团队主要来自谷歌X Lab,在深度学习和机器学习领域积累了丰富经验,可以为企业客户提供专业化的AI咨询和建议。
最后分享两个案例。
第一个是某大型互联网招聘平台,他们在全球化过程中希望基于业务定制招聘垂直场景的大模型。我们在海外帮他们构建私有GPU集群,从IDC选址到GPU服务器定制,到云管理平台组件,以及模型训练建议,提供端到端解决方案。让企业客户可以专注业务研发,提高效率,加速模型训练。
另一个是在线直播平台,主要做主播与观众连麦。在涉及不同语言时,以前的技术需要先语音转文字(ASR),再文字转语音(TTS),目前的端到端大模型,可以实现不同语言之间的无缝对话。这家公司基于开源大模型做fine-tuning,不需要长期租用大集群,只需在fine-tuning时使用几台服务器再训练几天或一周。他们采购了GMI Cloud的On-Demand服务来完成模型fine-tuning和调优。
五、结语
总结一下,今天我们从GPU云服务提供商角度分享了在AI全球化视角下如何提供高稳定性GPU云集群。
在集群稳定性方面通过三个方式,具备主动监控的Cluster Engine云平台、英伟达验证体系和交付测试体系、主动运维监控策略,通过这三个维度保证GPU集群稳定性。最后结合两个实际案例分享了AI Infra选型的思考,希望可以给大家的业务发展带来帮助。
最后祝所有AI企业在全球化过程中业务蓬勃发展,谢谢大家。
