








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
今年一开年,NVIDIA GeForce RTX 50系列GPU终于猛兽出笼,能玩顶配游戏,能做AI开发。赶上春节期间上市,估计会成为不少消费者的硬核新年礼物。
国内外有区别的是旗舰卡RTX 5090,RTX 5090起售价1999美元,中国合规版RTX 5090 D起售价16499元。其他非旗舰产品的价格则至少减半。

关注新显卡的朋友们可能还有很多疑问,比如RTX 5090和RTX 5090D有什么区别?除去AI外,其他设计的变化和性能提升有多少?AI和显卡的深度融合到底是噱头还是真有用?
在CES 2025期间,芯东西受邀参加了NVIDIA闭门编辑日,听多位NVIDIA副总裁连讲一整天的大师课,涉及很多GPU性能提升、基准测试和技术原理的细节。在此将一些干货整理分享给大家。
先说结论,如果你不关注AI,只想看传统显卡性能提升,可能50系列显卡会让你略感失望,因为从架构来看,RTX Blackwell和上一代Ada架构相差不大,硬实力升级幅度比较收敛,但是围绕AI的软实力提升可以称得上十分惊艳。
这也是NVIDIA迄今最大胆的一次将AI和游戏显卡高度融合,并让AI成为提升性能的头号主角。
RTX 5090的TDP是575W,比上一代高125W。这么高的功耗,怎么快速冷却呢?以前的设计是空气进来后撞到PCB板拐弯,从一个较小的排气口排出,风扇转得越快噪声越大。NVIDIA则把原来的PCB拿掉,中间做了个更小更紧凑的PCB板,让气流可以从两边风扇的散热鳍片直接顺滑通过,效率更高,还大降噪音。

我们将从以下8个方面,详细解析RTX 50系列消费级GPU的特点:
1、RTX 50系列的基础规格与基准测试表现;
2、Blackwell架构的设计目标、主要变化;
3、DLSS 4多帧生成的效果及用途;
4、多帧生成的技术原理与难点;
5、图形业首个实时Transformer模型应用;
6、首次将AI引入可编程着色器;
7、给游戏世界构建AI队友、AI助手、AI敌人;
8、AI PC本地部署生成式AI模型,优化直播和3D创意工作。
注:本文信息量偏大,读者朋友可直接跳至感兴趣的章节阅读。
一、游戏+AI性能猛兽出笼:全系显存换新,畅玩超250帧4K游戏
RTX 5090仍然采用台积电NVIDIA 4N定制工艺,面积变得更大。上一代4090的GPU芯片面积是608mm²,RTX 5090系列的面积则增加到744mm²。
RTX 5090拥有920亿个晶体管、21760个CUDA核心(比上一代多50%),AI峰值算力是3352TOPS。RTX 5090 D硬件配置是一样的,AI算力受合规限制到2375TOPS,也就是比5080高了约32%。
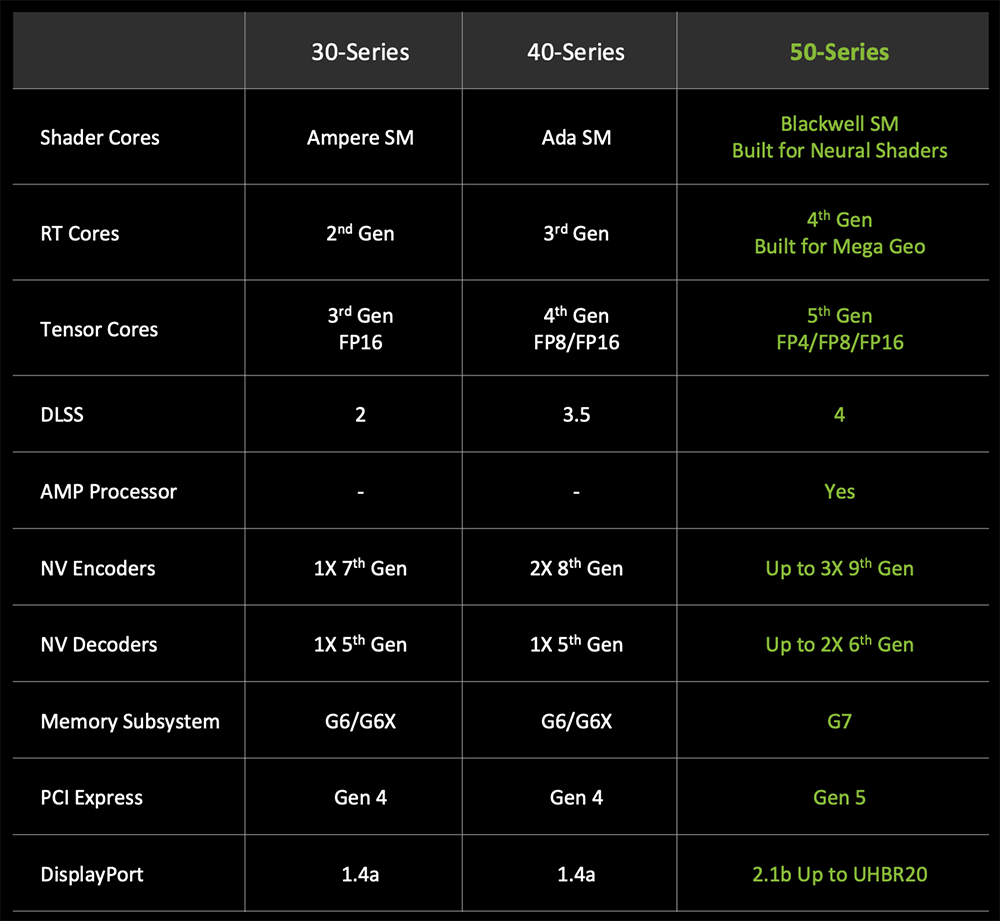
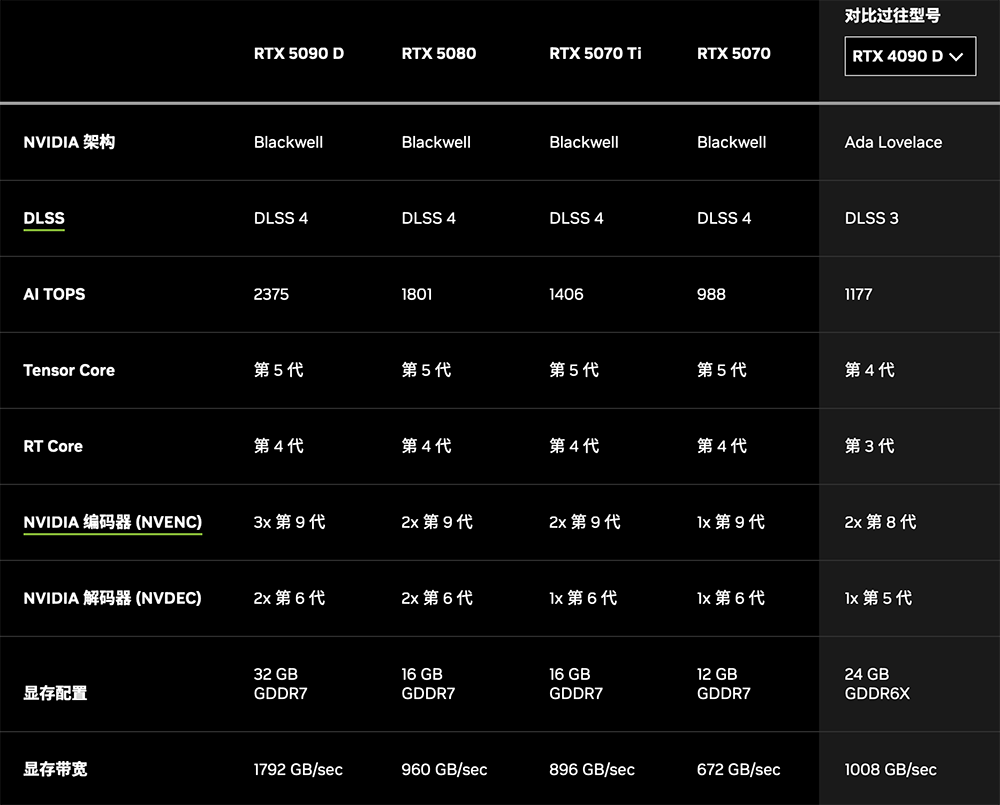 ▲RTX 50系列显卡规格
▲RTX 50系列显卡规格
目前公开的RTX 50系列GPU,显存都升级到GDDR7,位宽、容量做了分级:5090是512bit、32GB,5080和5070 Ti是256bit、16GB,5070是192bit、12GB。
GeForce RTX 50系列笔记本电脑GPU规格也同步更新,相比上一代,能效更高、能跑2倍大的AI模型、视频编辑速度快40%,电池寿命延长40%。
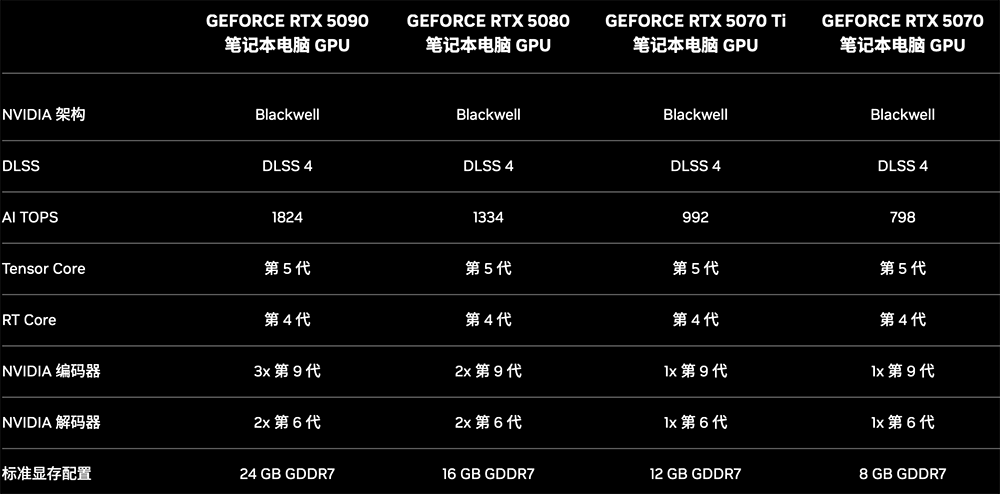 ▲RTX 50系列笔记本电脑GPU规格
▲RTX 50系列笔记本电脑GPU规格
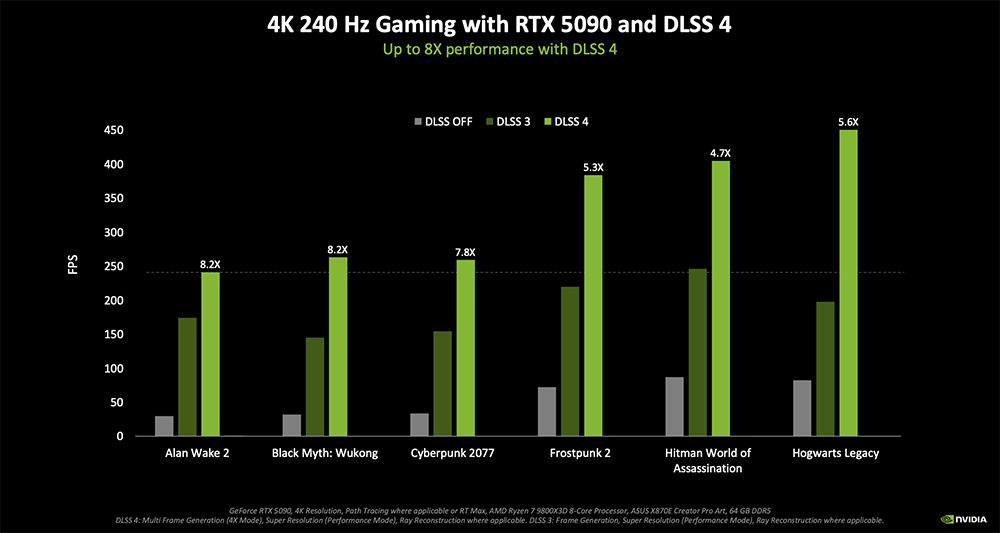
令人印象深刻的依然是AI技术,性能最多暴涨至8倍。
尤其是DLSS 4,在跑《黑神话:悟空》、《赛博朋克 2077》等硬件密集型光线追踪游戏时,4K分辨率下帧率超过200FPS,而且显著减少延迟。
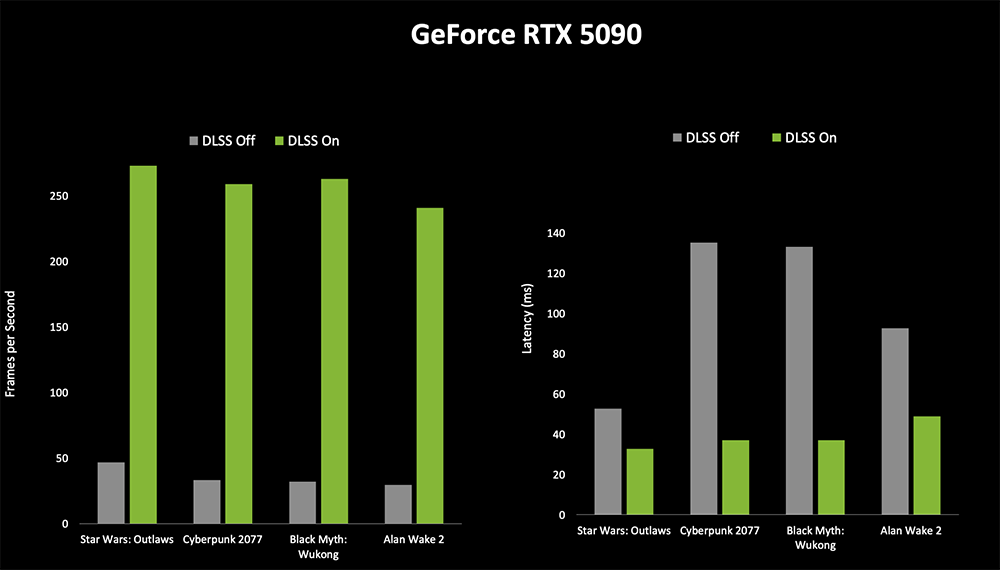
RTX 5090 / 5090 D无疑是性能猛兽,开DLSS 4和全景光追时升级幅度非常可观。NVIDIA官方公布的游戏及渲染测试显示,4K分辨率、最高游戏设置的情况下,在开DLSS 4时,RTX 5090 / 5090 D / 5080基本上都表现出至少翻倍的性能提升。
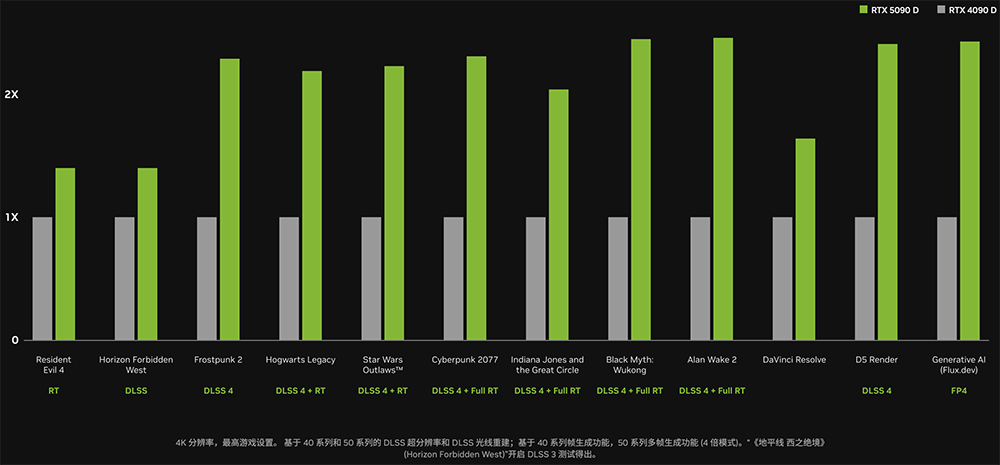
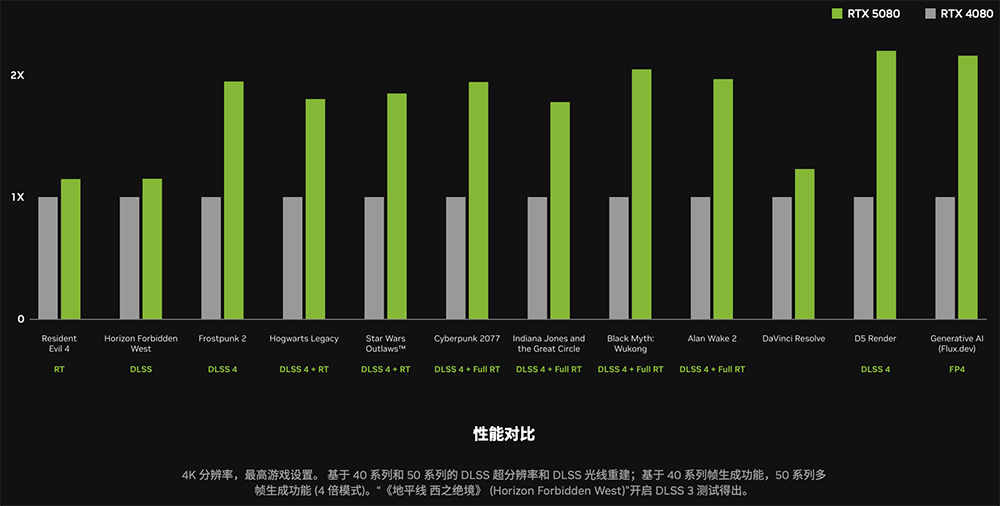
RTX 5070 Ti / 5070也借助DLSS 4实现了超过翻倍的性能提升,在采用 2560×1440 分辨率、最高游戏设置的情况下,能以高帧率畅玩《心灵杀手2》、《黑神话:悟空》、《赛博朋克2077》等游戏。
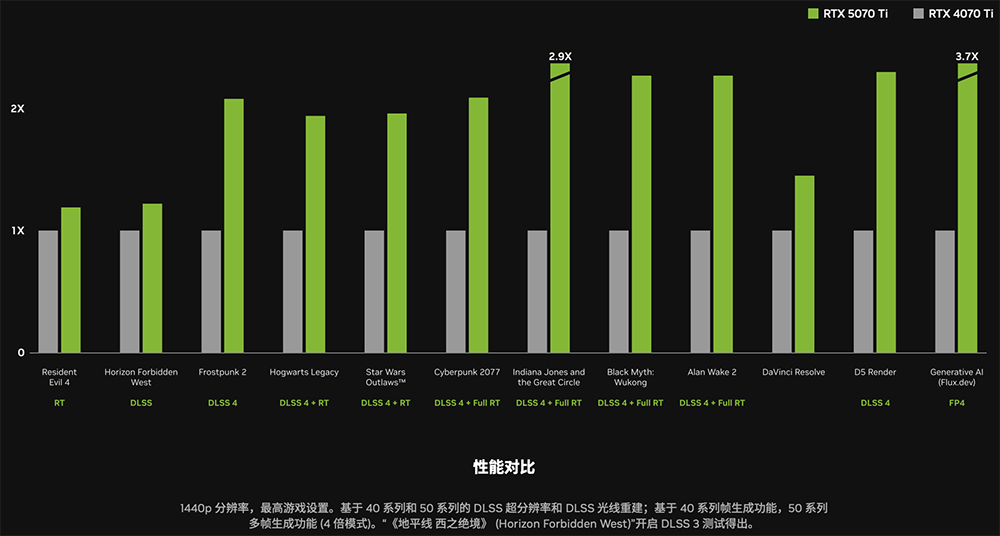
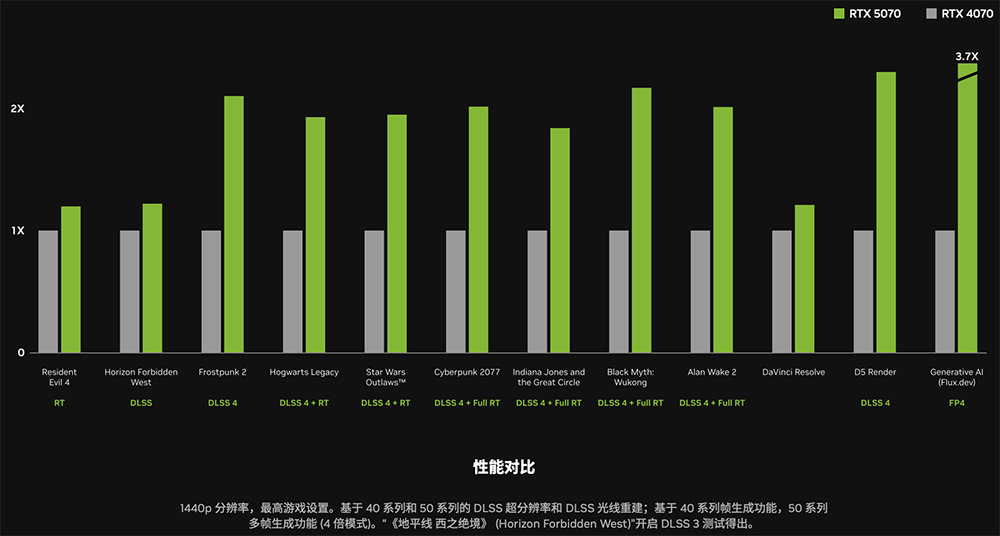
不过在没开DLSS的情况下,例如《生化危机4》,RTX 50系列相比上一代的提升幅度更小一些,约提升15%~30%。
这些基准测试性能对比已经在官网公布。
RTX 5070的硬件规格虽然难与旗舰卡相提并论,但通过DLSS 4等AI软实力的提升,NVIDIA称其性能表现已经堪比前代旗舰卡4090。

二、Blackwell架构:支持神经网络渲染,FP4精度AI算力暴涨
RTX 50系列GPU采用Blackwell架构。NVIDIA称Blackwell融合了AI驱动的神经网络渲染和光线追踪,是自25年前推出可编程着色以来最重要的计算机图形创新。

RTX Blackwell架构的设计目标包括优化新神经网络工作负载、减少显存占用、提高能效等。
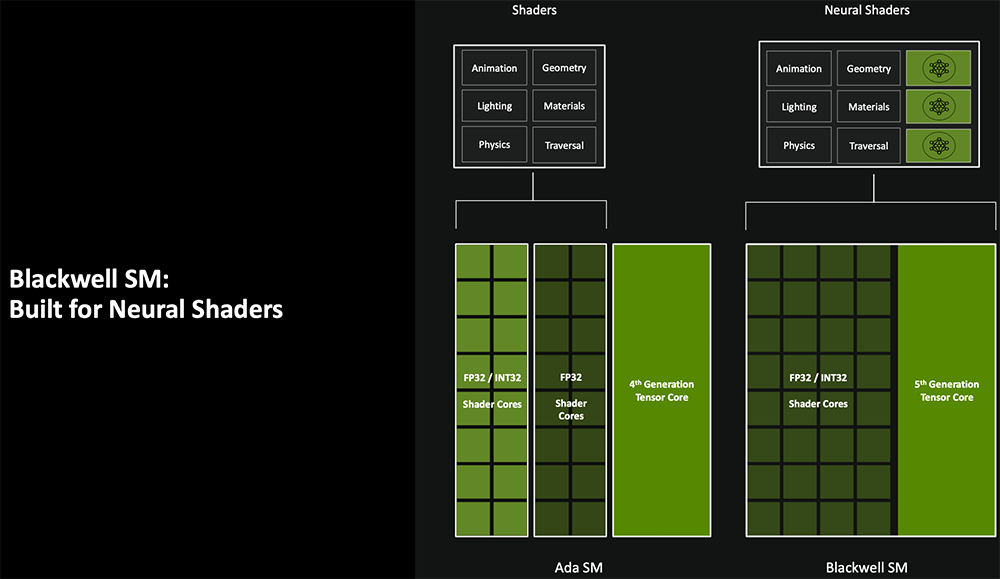
上一代Ada架构的SM多单元流处理器里,Shader Core有一半仅支持FP32,一半可以同时支持FP32/INT32。Blackwell SM则变成所有Shader Core都支持FP32/INT32,并首次支持神经网络着色器,可提供125TFLOPS算力;承载AI计算的Tensor Core由第四代升级到第五代。
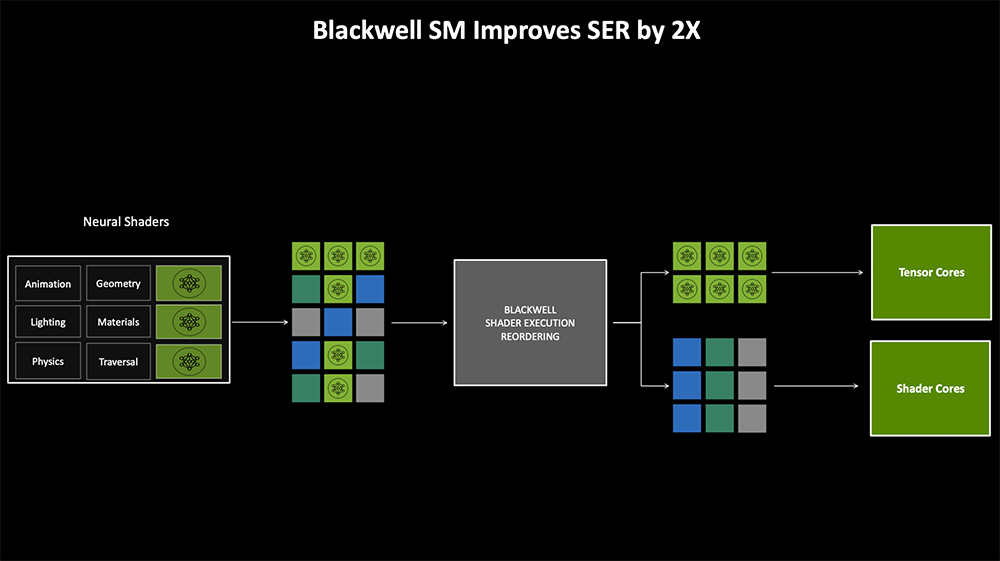
下图中间灰框是着色器执行重排序(SER),用于优化GPU光线追踪和图形渲染。它会遍历并重新排序工作,把相同工作分别放在一起,提高运行效率,将整体重排序性能翻倍。
负责光线追踪计算的Blackwell第四代RT Core,能够更好支持NVIDIA RTX Mega Geometry技术。该技术可将场景中的光线追踪三角形数量增加多达100倍,能够更有效地处理超大几何图形簇。
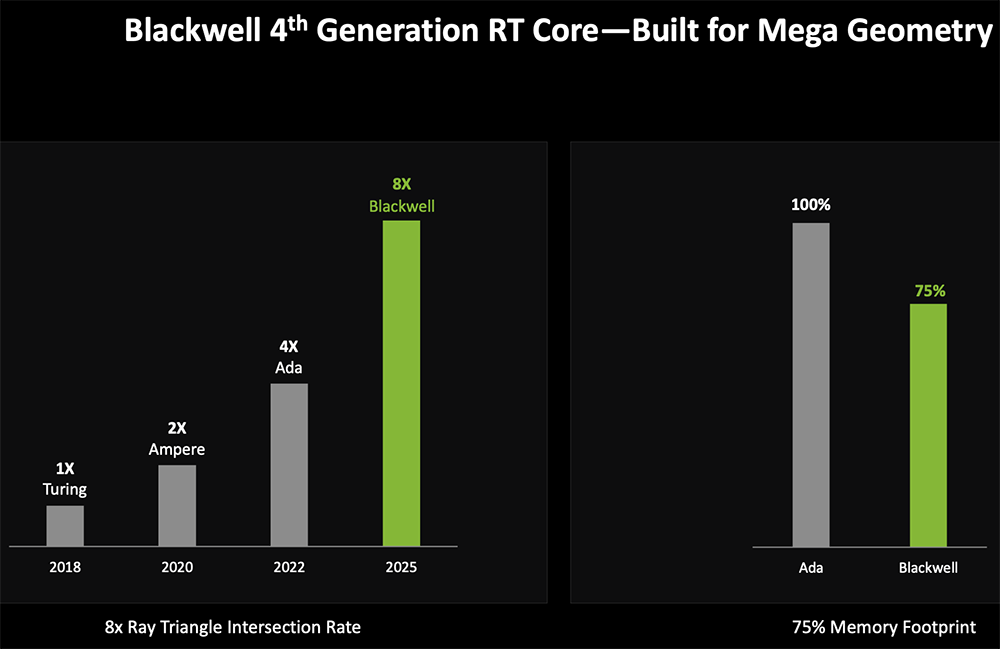
RT Core增加了对线性扫描球体(Linear-swept spheres)、三角形簇交汇引擎(Triangle Cluster Intersection Engine)、三角形簇解压缩(Triangle Cluster Decompression)的支持,可支持的几何复杂度增加很多。
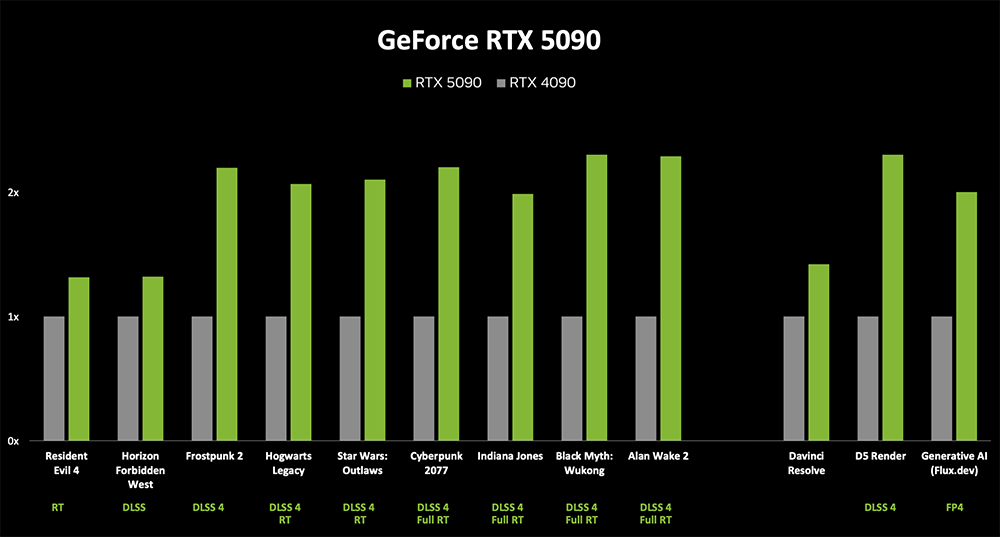
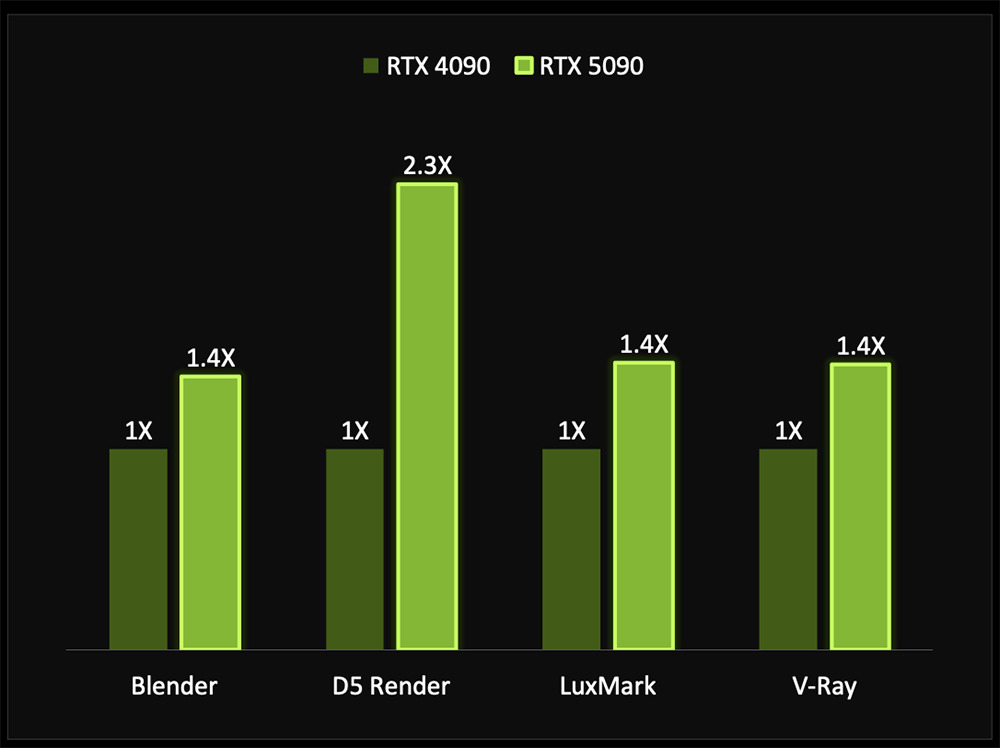
Blackwell也更擅长加速3D渲染,可将采用生成式AI的3D工作流的性能,较上一代提升50%。相比上一代,由第四代RT Core驱动的3D渲染,性能提升约40%。使用D5 Render时,RTX 5090的性能更是达到上一代的2.3倍。这对3D内容创作大有裨益。
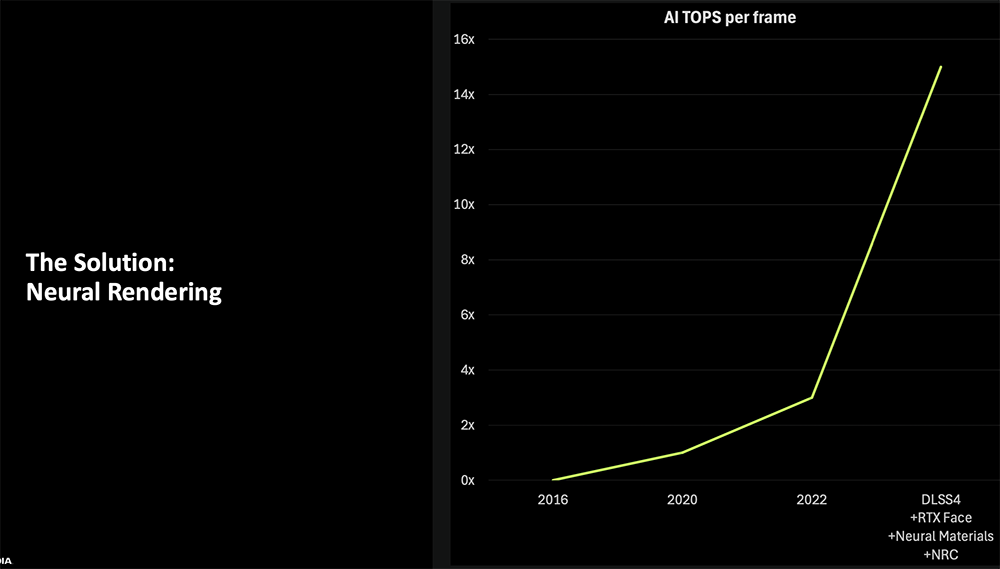
得益于神经网络渲染架构,Blackwell的每帧AI TOPS相比上一代最多提升达8倍。
针对AI运算,第五代Tensor Core首度增加对FP4精度的支持,AI推理性能是上一代Ada FP8的2倍,并使生成式AI模型能够在PC本地运行,占用的显存更小。现在RTX 50系列GPU已经能支持本地运行视频生成模型了。
举个例子,同样是跑Black forest labs图像生成模型FLUX.1,用RTX 4090在FP16精度下要花15秒、占用超过23GB的显存,而用RTX 5090在FP4精度下只花5秒、占用10GB显存。

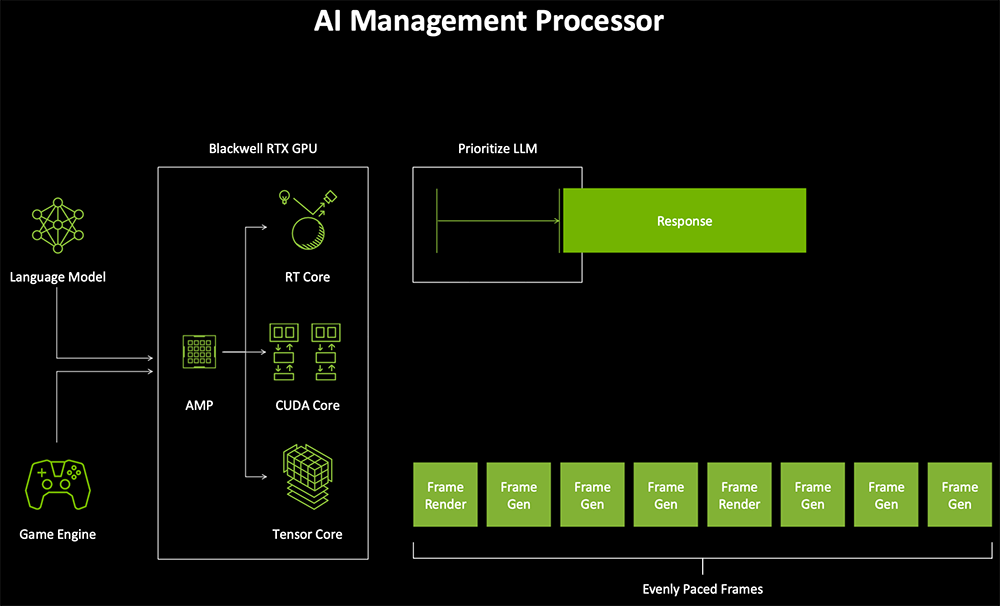
Blackwell还添加了一个可编程的AI管理处理器,可以实现对AI和图形工作负载同时运行的智能调度分配。比如在玩游戏时,它能优先保证AI队友第一时间作出响应。
Blackwell显示引擎和编解码器同样更新迭代。显示引擎首度支持DP 2.1,能运行更高的刷新率;还新增了对硬件级Flip Metering的支持,用于优化多帧生成中的帧节奏逻辑。
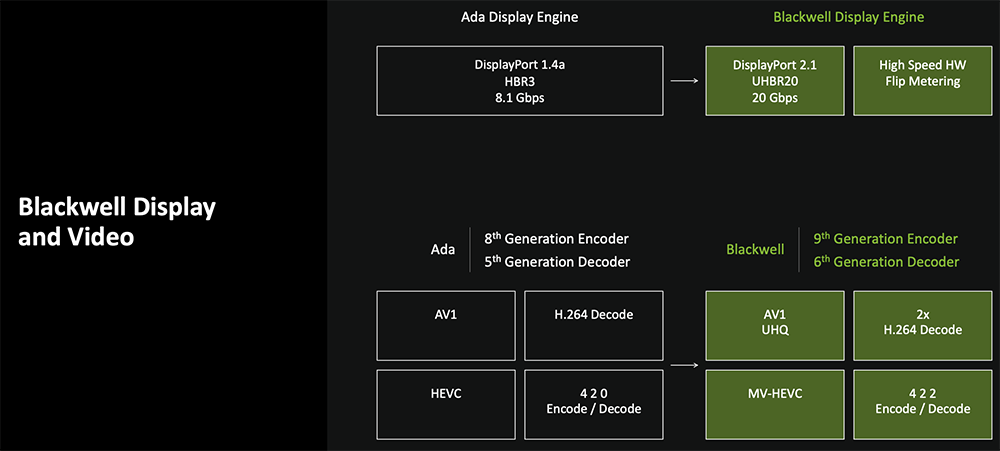
升级的还有视频编解码,现支持4:2:2格式的硬件编解码,能够更好地服务于专业级视频编辑。第9代视频编码器可在DaVinci Resolve、Adobe Premiere Pro等应用中实现快速视频导出,并使用AI驱动特效。
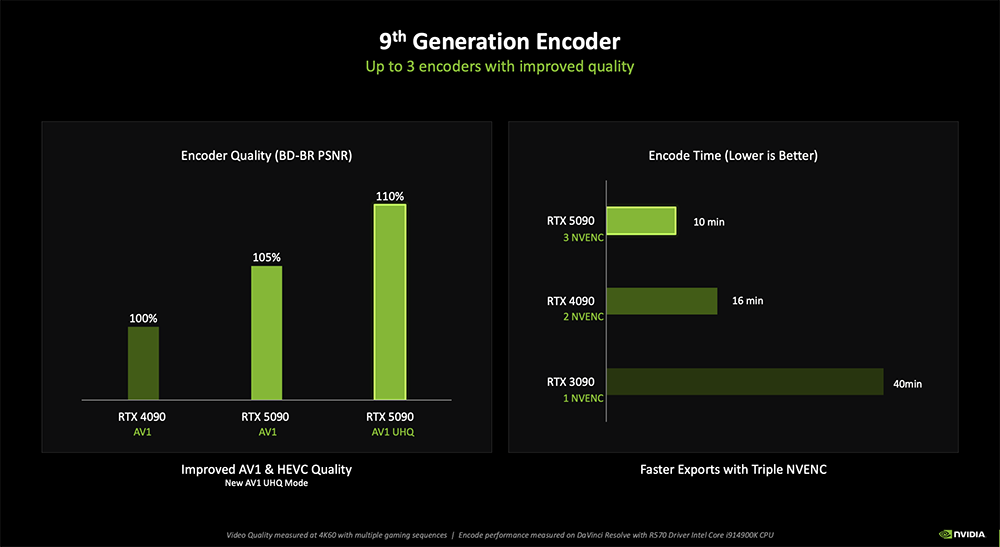
三、DLSS 4多帧生成:帧率暴涨至8倍,占用更少显存
近年来DLSS(深度学习超级采样)已经成为RTX系列GPU升级的重头戏,用于提高帧率,同时提供媲美原始分辨率渲染的清晰高质量图像。
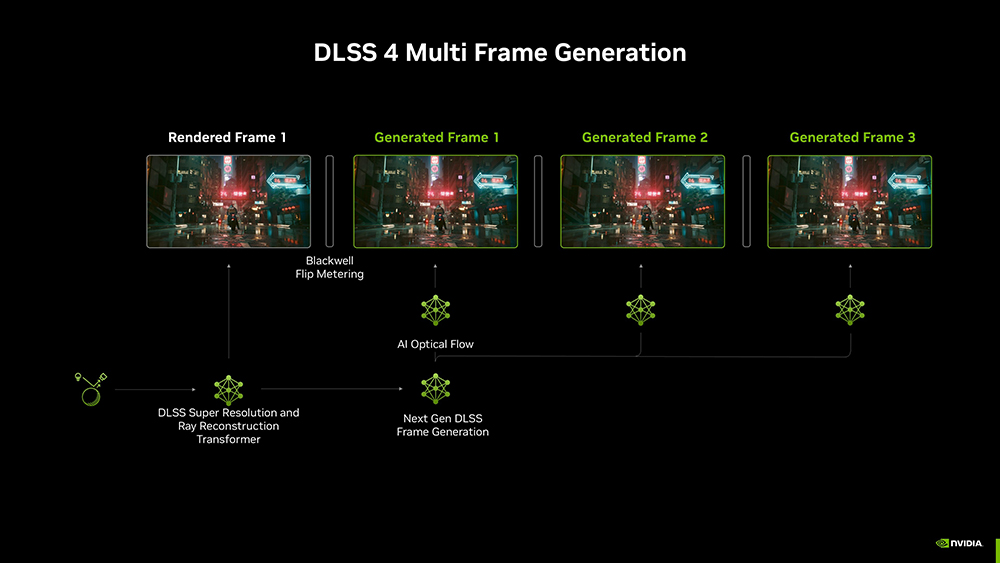
RTX 50系列里最抢眼的技术当属最新引入的DLSS 4,首次推出多帧生成功能。
 ▲支持DLSS技术的硬件
▲支持DLSS技术的硬件
多帧生成可以为每个渲染帧额外生成最多3帧。整套DLSS技术全开,可将运行游戏或应用的帧率提高到传统图像渲染时的8倍、单帧生成时的1.7倍。
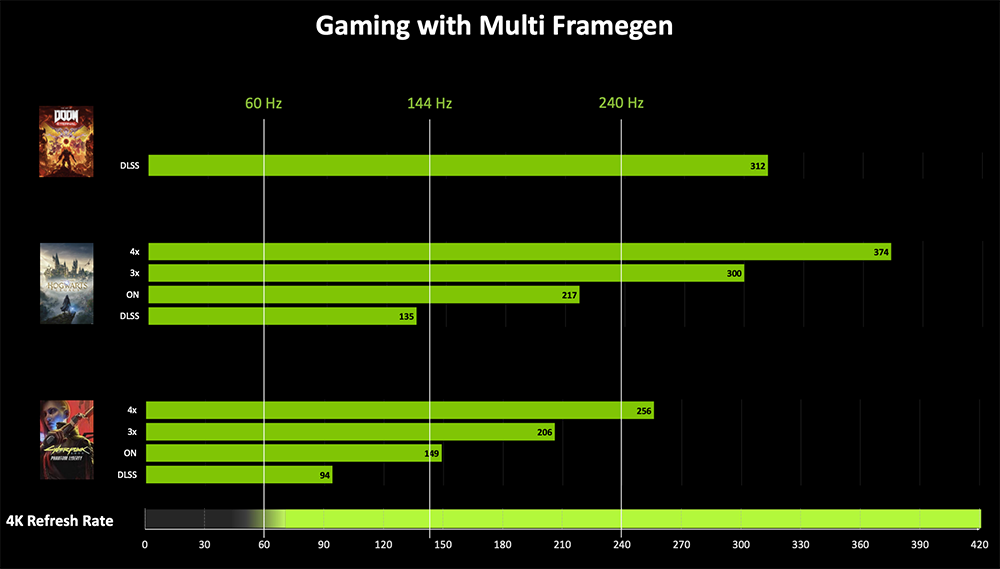
仅用超分辨率或光线重建,4个像素中有3个是AI生成的;添加单帧生成时,8个像素中有7个是由AI生成的;最后通过DLSS 4多帧生成,16个像素中就有15个由AI生成。
![]()
可以看几张对比图,来直观感受下开DLSS 4对画面细节的优化效果有多明显。
镜中重影得到优化:

纹理更精细:

发丝、光影的质量也显著提升:

开了DLSS 4后,RTX 5090显卡可以驾驭4K 240 FPS全景光线追踪游戏。

比如玩《赛博朋克2077》,与传统渲染相比,RTX 5090的帧率提高近8倍,PC延迟减少一半,图像质量也得到增强。
NVIDIA还针对RTX 40和50系列GPU强化了帧生成模型。新CNN模型速度提高了40%,显存占用量减少了30%。例如在《战锤40000:暗潮》中,使用DLSS帧生成,在4K、最高设置下提供了10%更快的帧率,同时减少了400MB的显存使用量。

同时,DLSS光线重建、DLSS超分辨率和DLAA也转由Transformer模型驱动, 它将进一步提升RTX20、30、40、50系卡的DLSS 性能体验。
在1月30日产品上市时,将有超过75款游戏和应用支持DLSS 4。《黑神话:悟空》也将在新卡发售当天支持DLSS 4,并在未来提供对DLSS 4的原生支持。
除了游戏外,DLSS 4还将用于虚幻引擎5、D5 Render、Chaos Vantage等创作应用,显著增强实时视图的端口体验,提高D5 Render中的帧速率,使得设计师能更好地迭代和协作工作。
四、多帧生成的技术难点:控制成本、帧节奏、延迟
RTX 50系列能用上多帧生成,得益于Blackwell硬件和DLSS软件创新的相辅相成。
DLSS 3帧生成功能在2022年发布,用AI模型来预测序列中的下一帧。该帧生成AI模型使用游戏里的运动矢量、深度等数据和RTX 40系列光流加速器的光流场,在每对传统渲染的帧之间创建一个额外帧。
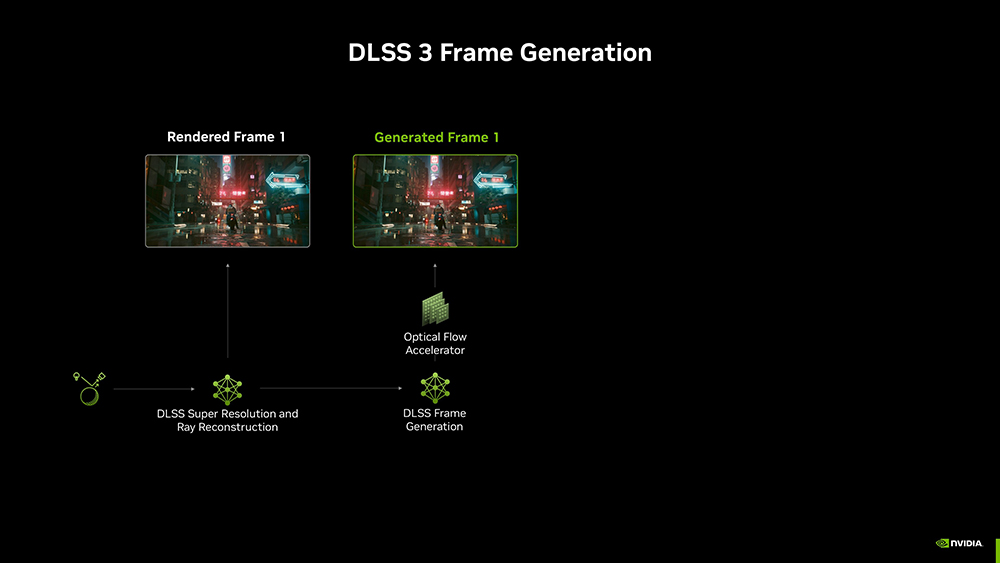
而要实现多帧生成,成本就变得很高。因为每个新生成的帧都需要光流加速器和AI模型,性能成本会限制GPU,导致输入帧率降低。
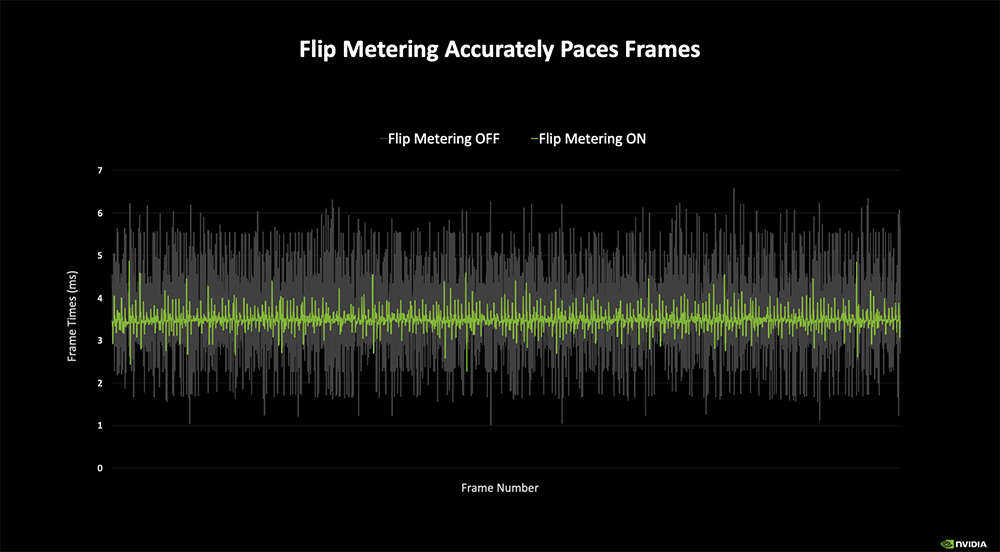
多帧生成难在需要一致且精确的帧节奏。DLSS 3帧生成使用基于CPU的帧节奏,由于不同游戏引擎在CPU和GPU之间划分工作负载的方式不同,其可变性可能会随着其他帧而增加,导致每帧之间的帧间隔是变化的,会造成卡顿。
对此,NVIDIA研究团队开发了一个全新AI模型,搭配Blackwell的硬件级Flip Metering,确保GPU提供一致且最佳的帧率。高效的AI模型取代了硬件光流加速器,来加快光流场生成速度,能显著降低生成额外帧的计算成本。
Flip Metering可以调整帧传送速度,使GPU在生成和渲染帧时能更高效地进行时序管理,实现更稳定的帧生成,避免严重卡顿。
如果一款游戏运行所有DLSS 4功能,包括超分辨率、光线重建、多帧生成,GPU需要在几毫秒内为每个渲染帧运行5个AI模型,否则DLSS多帧生成可能会成为减速器。
这就需要配备更强的硬件。基于Blackwell第五代Tensor Core,RTX 50系列的AI处理性能最高达到上一代GPU的2.5倍。新帧生成后,其节奏均匀,从而能提供流畅的体验。
针对AI补帧会增加延迟的问题,NVIDIA的解法是引入Reflex 2来优化图像渲染管线,最多能将延迟减少75%。Reflex低延迟模式通过在GPU与CPU之间进行精确渲染同步来降低PC延迟。Reflex 2引入了一种新技术Frame Warp,可以在将渲染帧发送到显示器之前,根据最新鼠标输入数据来更新渲染帧,以提高游戏响应速度。
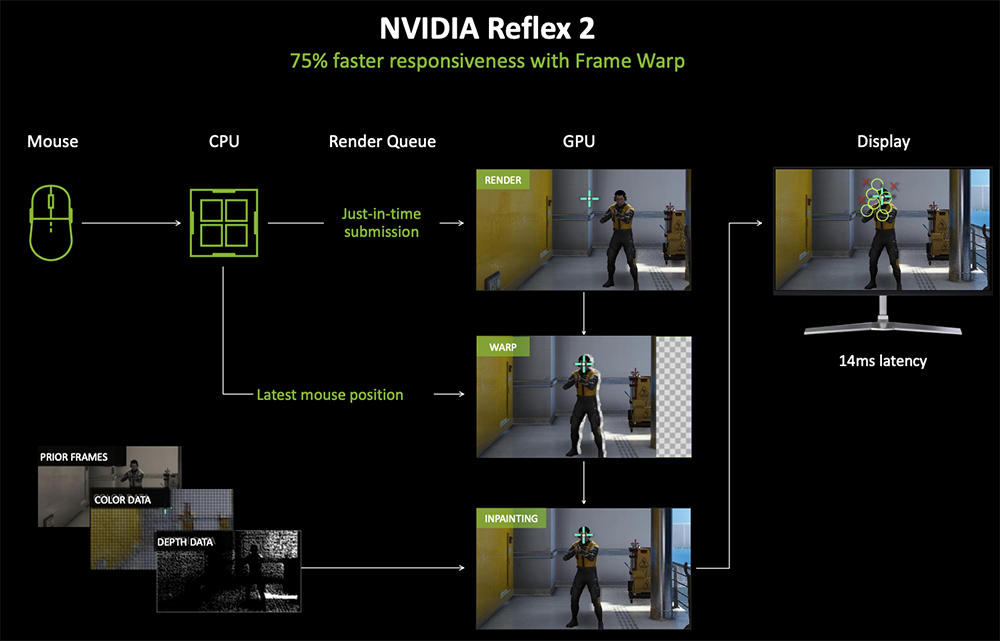
NVIDIA还开发了一个Inpaint预测修补技术,用于修复前一帧的颜色与深度数据的空白区域,让画面更加接近原生渲染效果。

五、DLSS 4全面引入Transformer:增强画质,提升稳定性,减少重影
DLSS 4的光线重建、超分辨率、深度学习抗锯齿(DLAA),都采用了由NVIDIA超级计算机训练的全新Transformer模型。

DLSS 4是Transformer模型首次以高实时帧率生成连续图像,由Blackwell Tensor Core提供额外硬件加速。新模型使用多达2倍以上的参数、4倍的Tensor Core计算能力,能够更深入地理解场景、更好地渲染游戏场景中复杂部分,提高帧到帧之间的稳定性,减少重影,增加光照细节和运动细节。
以前DLSS使用卷积神经网络(CNN),通过将少量相邻像素局部聚合并跟踪连续帧中的区域变化来生成新像素。但经过六年改进,这种方法已经逐渐到达极限。
Transformer是当前主流大模型所采用的架构。新DLSS Transformer模型采用ViT(视觉Transformer),可实现自注意力操作来跟踪评估整个帧和多帧中每个像素的相对重要性。与CNN相比,Transformer可以用更大的数据集训练,更具通用性和可扩展性,能在更大的像素窗口内轻松识别更长距离的模式,而且更多关注到有问题的细微区域。
光线重建改用Transformer模型,可大幅提升图像质量。例如《心灵杀手2》游戏场景中,相比CNN,Transformer模型改善了高度精细的铁丝网围栏的稳定性,减少了风扇叶片上的重影,并消除了电线周围的闪烁。

超分辨率的Transformer模型效果也很好,显示更稳定,图像细节也更丰富,将先以测试版的形式发布。

具有光线重建、超分辨率、DLAA的DLSS游戏都可以升级到新的DLSS Transformer模型。
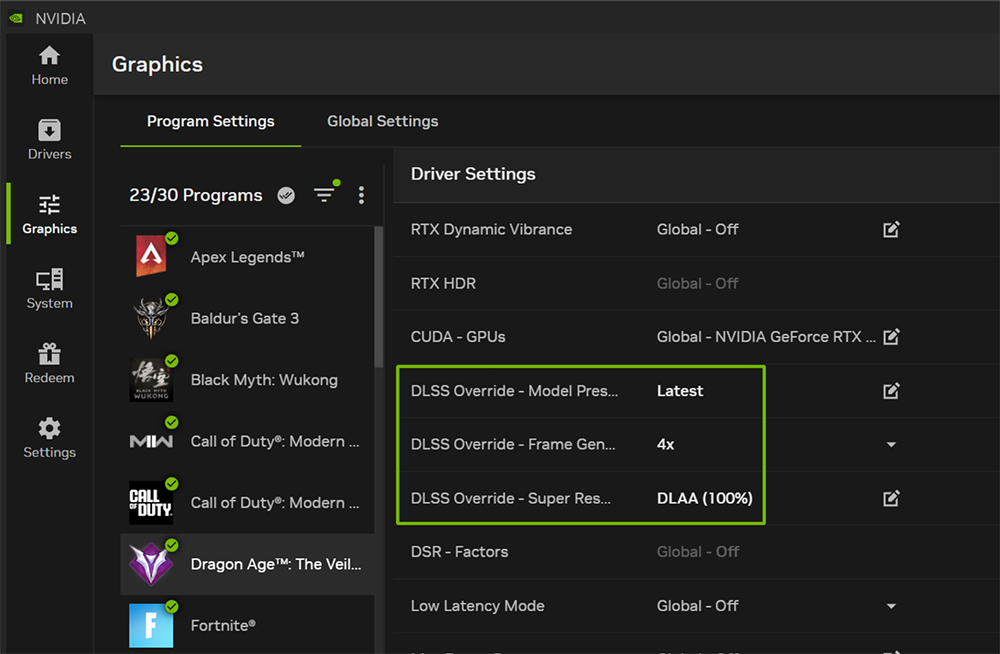
对于尚未更新到最新DLSS的游戏,NVIDIA app Driver设置菜单中增加了DLSS优设(DLSS Override)选项,可在Frame Generation下拉菜单中设定所需的输出模式。
六、将AI引入着色器,秀材质、皮肤、毛发渲染黑科技
自2001年GeForce 3引入第一个可编程着色器起,NVIDIA 20多年来持续点亮图形创新,推出高级着色语言、几何着色器、计算着色器、Low-level编程,以及2018年发布的光线追踪。
到RTX 50系列GPU,Blackwell开发人员首次将小型AI网络引入可编程着色器,在实时游戏中解锁电影级材质、光照等。NVIDIA将它命名为RTX神经网络着色器,称其重塑了着色器的编程方式,可用于将纹理压缩多达7倍。
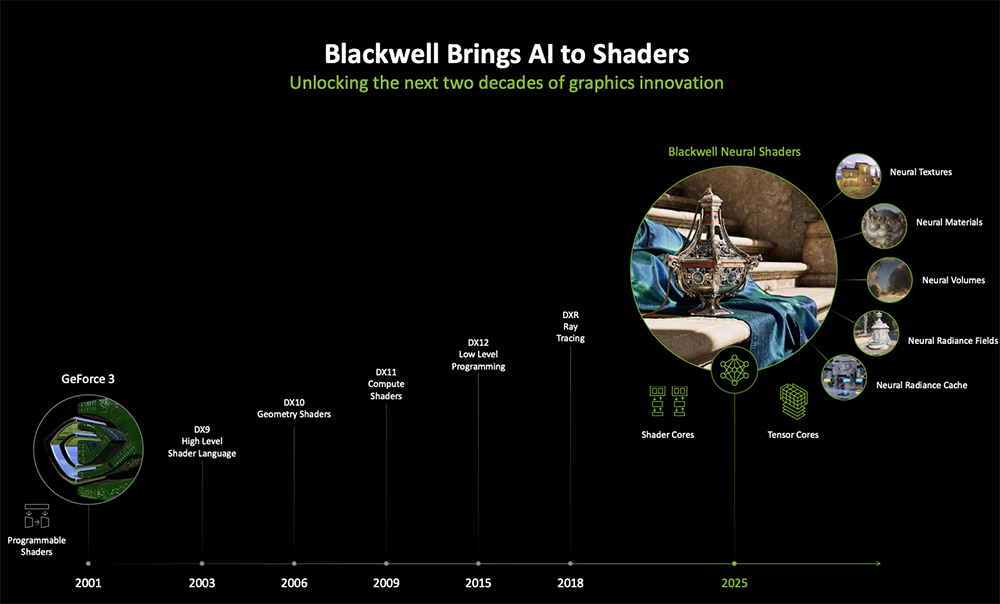
DirectX将很快支持一个由NVIDIA和微软合作创建的新API,Cooperative Vectors。它可以真正利用到Tensor Core的能力,更充分加速Windows上的神经网络着色器。相信神经网络技术将很快取代传统图形管线的一部分。
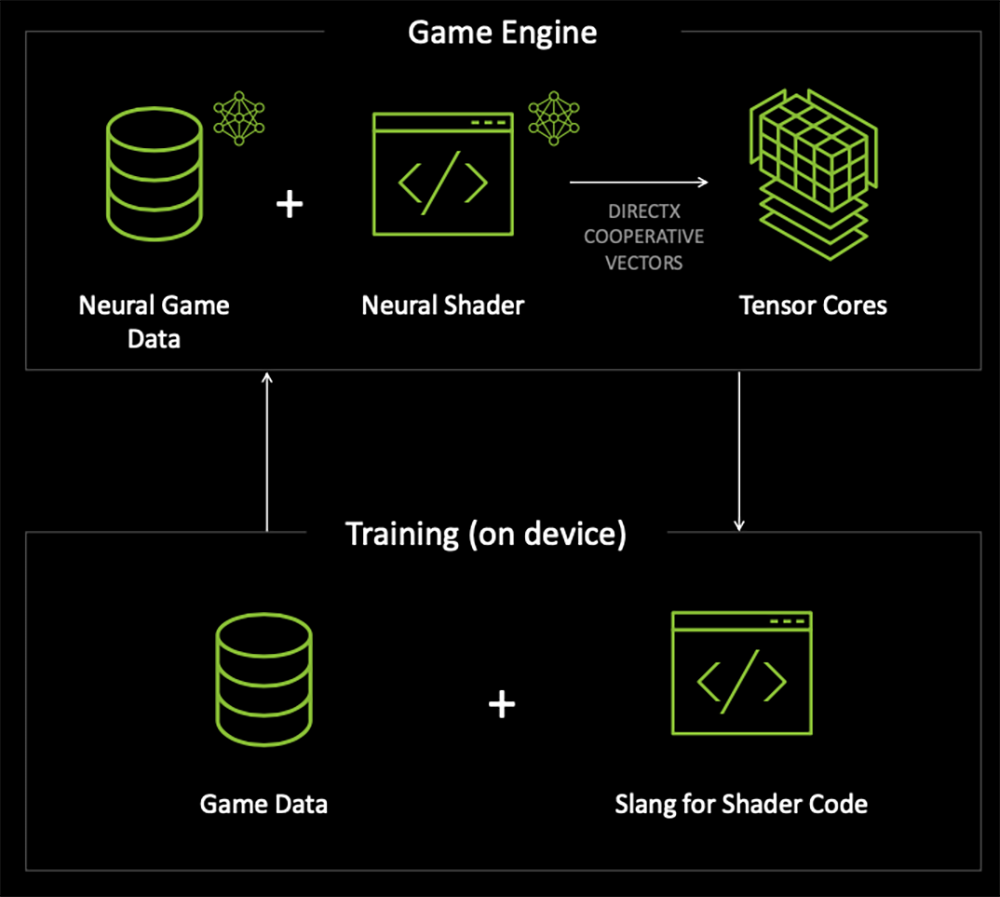
神经网络材质就是一个例子。传统材质采用带有实时图形的着色编程,光线与材质交互的计算量和数据存储量浩大,如果是电影级渲染,可能要用成百上千行代码。而RTX Neural Materials通过引入一个只有几层的小型AI神经网络,能大幅减少着色器编程代码量和数据。在Zorah游戏演示中,用传统材质要占用47MB显存,用RTX Neural Material则可将显存占用量压缩至16MB,视觉效果还更逼真。

RTX Neural Radiance Cache是一个更准确地追踪间接光线的方法。与许多只用推理的神经网络技术不同,该技术有一个实时自训练网络,接受了特定游戏数据训练,学习了任何给定阵列所应达到的间接光照情况,能通过追踪每像素一次光线弹射推断出更多的弹射。
还有RTX Skin,针对半透明材料,NVIDIA借鉴了迪士尼的电影渲染技术,将次表面散射算法首次引入实时光线追踪。

RTX Neural Faces采用简单的光栅化面部和3D姿势数据作为输入,并使用生成式AI实时推理,渲染出稳定、高质量的数字面孔。NVIDIA在不同的光照条件下,用不同的情绪和动画、不同的遮挡(比如部分脸被遮盖),在每一个可能的姿势下做渲染,然后在超级计算机上创建一个模型,用于构建特色角色的照片级逼真图像,再在游戏系统上进行部署。

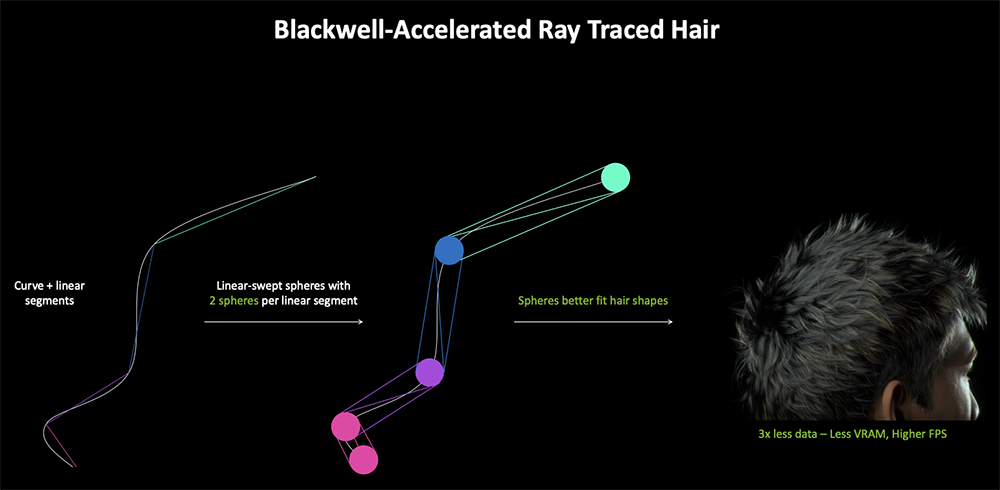
渲染毛发也很有挑战性。光线追踪的毛发渲染成本高昂。传统毛发渲染技术无法兼顾性能和图像质量,需要用很多三角形来保证精度。在NVIDIA展示的例子中,一个角色的毛发渲染要用到600万个三角形。
全新RTX Hair技术改用Linear-swept spheres单元,能够让角色头发看起来更逼真细致、阴影更准确。相比多边形,球体能更好地贴近真正的毛发。这种渲染方式运行速度更快,图像质量更高,同时大幅减少显存占用。
RTX Mega Geometry是一项突破性技术,可以智能地聚集和更新复杂几何体,以进行实时光线追踪计算,能够减少CPU开销,提高帧率,并减少大量光线追踪场景中的显存消耗。
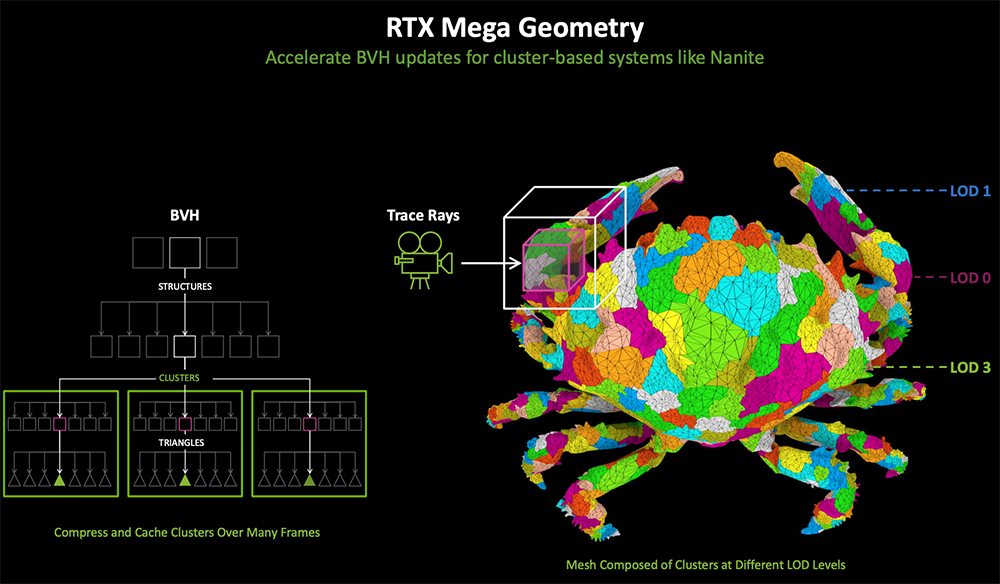
近30年来游戏里的几何体数量一路飙涨,Zorah游戏场景有超过5亿个三角形,启用RTX Mega Geometry技术后能在RTX 50系列GPU上流畅运行。
《夺宝奇兵:古老之圈》未来的更新将引入全新NVIDIA RTX Hair技术。《心灵杀手 2》将率先采用RTX Mega Geometry技术。
七、自主AI agent涌入游戏:AI队友、AI助手、AI Boss
一个充满生命感的游戏世界,会是什么样子?
可能是一个充满自主AI的模拟空间,你的队友、系统、敌人等角色都由自主AI agent驱动。
而让AI去复制人类决策,是一个困难的感知认知行动,它要像人一样具备感知、认知、记忆、规划与行动的能力。
NVIDIA ACE便旨在为自主游戏角色提供支持。使用该技术,开发者可以创建在本地设备上运行的自主AI队友,协助玩家畅玩游戏。
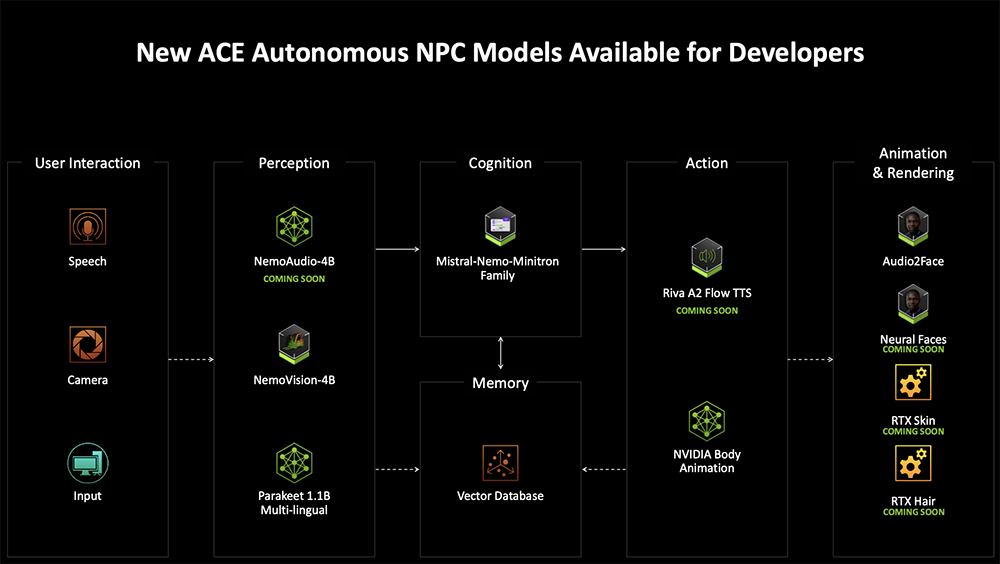
感知方面,ACE有音频理解模型Nemoaudio-4B-Instruct、视觉理解模型Cosmos Nemotron-4B-Instruct-v2。比如玩枪战游戏,它能理解枪声的状态与位置,据此来制定计划;在复杂游戏场景中,视觉理解模型能够掌握很多关于游戏中发生事情的信息。
认知方面,ACE提供了Mistral NeMo Minitron instruct模型系列,有不同参数版本,规划模型能输出agent将要执行计划的纯文本,基于这个计划,行动选择模型将产生一些行动;音频生成模型Riva A2 Flow TTS是一个文本转语音模型,可输出自然、有感情的音频。
在呈现更好的动画效果上,ACE提供由音频驱动的全新AI面部模型新一代Audio2Face,能让游戏角色说话时的表情和口型更贴合;还有由文本驱动的身体运动ACE AI Body Motion,只需输入文本,就能从大量动作捕捉数据中生成动画序列,可以帮动画师节省时间。还可以用前文提过的RTX Neural Faces、RTX Skin、RTX Hair等套件,来渲染出栩栩如生的数字人。
动作游戏《动物朋克》的demo中便使用ACE来实现游戏中的语音理解,使角色互动更自然细腻,从而增强游戏的代入感。玩家可以用语音或文本,要求AI更改游戏中的装备涂装,比如更换飞船的颜色或logo中的动物形象。
ACE驱动的自主角色正在集成到战术竞技游戏《绝地求生》、人生模拟游戏InZOI、多人在线角色扮演游戏《传奇5》中。
在《绝地求生》中,由ACE提供支持的AI队友可以跟玩家讨论战略、提供游戏建议或者闲聊,也能计划和执行战略行动,与人类玩家动态合作以确保生存。
InZOI中由ACE支持的CPC角色Smart Zoi,可以根据生活目标和游戏内的事件自主调整行为,能做出规划、制定决策、提供反馈。它支持通过自然语言来定制性格、关系、记忆。每一天结束时,Smart Zoi会分析获得的经验,由此影响它第二天的行为,从而塑造出一个真正独特且个性化的性格。
《传奇5》则设置了一个AI Boss。以往基于固定脚本的Boss会遵循可预测的模式来行动,比较乏味。而由大语言模型驱动的突袭Boss能够分析玩家信息,识别每个玩家的独特技能,从而调整战术。这样一来,玩家在每次游戏会话中都能遇到独特的Boss,它的攻击策略变得更不可预测,也更具挑战性。
考虑到游戏玩家很难找到一个适合自己系统和喜好的最佳配置,NVIDIA发布了一个AI助手Project G-Assist。该AI助手通过NVIDIA app提供,可以帮助提高RTX PC系统的性能。
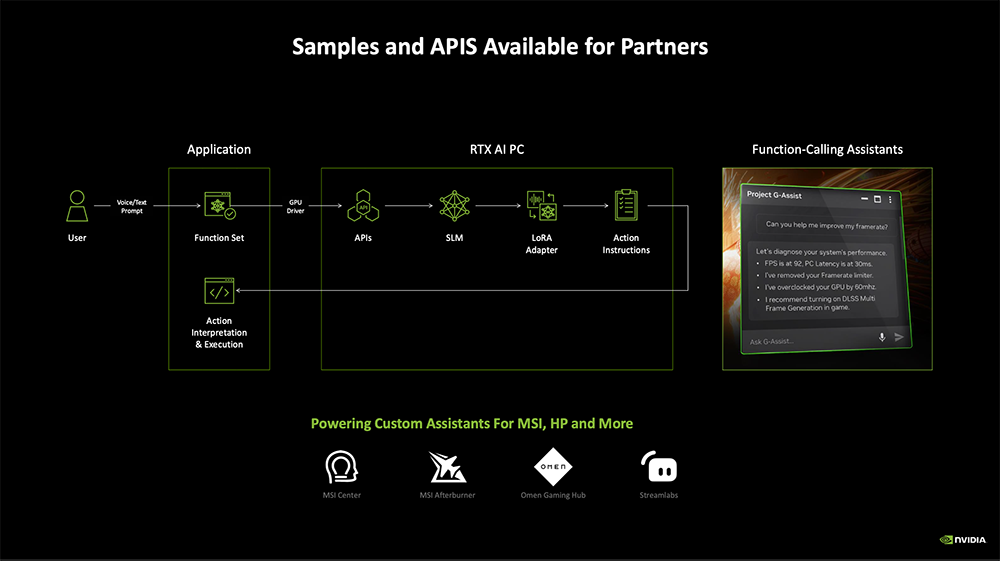
Project G-Assist支持用户用语音或文本命令来控制系统,可以优化帧率、延迟、能效等,支持利用AI来诊断和监控性能,还能通过插件调用不同系统,定制周边照明、管理风扇噪音。
NVIDIA创建了一个插件框架,使得外设制造商可以构建和测试自己的插件和辅助工具、连接流行的AI工具。
八、RTX AI PC:轻松部署生成式AI模型,用AI增强视频体验和3D创作
除了畅玩游戏外,RTX 50系列GPU还有一个重要功能——加速AI模型训练和推理。
GeForce做AI开发最早可以追溯到2012年,开启深度学习革命的AlexNet模型就是用GeForce GTX 580训练的。根据NVIDIA披露的数据,在去年发表的AI研究论文中,超过30%都提及对GeForce RTX的使用。
全新Blackwell架构首度支持FP4精度,AI推理性能翻倍。其使用案例涵盖大语言模型、视觉语言模型、图像生成、语音、用于检索增强生成的嵌入模型、PDF提取、计算机视觉等。
你可以用ChatRTX定制专属AI聊天机器人,通过文本或语音搜索个人笔记、文件及照片;用Broadcast应用做AI降噪和背景替换,提升视频会议通话、语音聊天和直播的体验;用RTX Video通过AI超分辨率和视频HDR技术,将互联网视频升级为超清4K HDR视频。
Broadcast应用为直播者提供了2项由AI提供支持的测试版功能:1)Studio Voice,用于去除噪音和混响,升级麦克风音频;2)Virtual Key Light,通过AI补光改善主播的面部光影,从而提升与玩家的互动氛围。
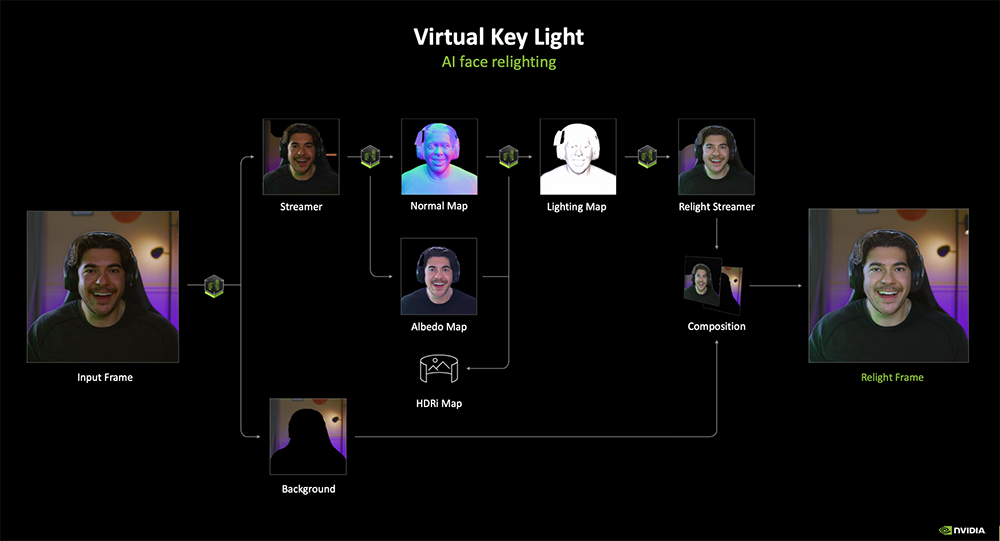
Streamlabs正在推出由NVIDIA ACE和Inworld AI框架提供支持的智能流媒体助手。它可以充当联合主持人、制作人和技术助理来辅助直播,比如做些点评、和观众互动或者提供排除故障的建议。这个AI助手将在今年下半年发布。
包括NVIDIA Studio专属AI工具套件在内,有超过100款由AI赋能并由RTX加速的创意应用可辅助内容创作,比如加速图像生成、增强视频编辑、助力3D设计等。
利用NVIDIA NIM微服务和AI蓝图,你还可以在RTX AI PC上本地运行最新的生成式AI模型。
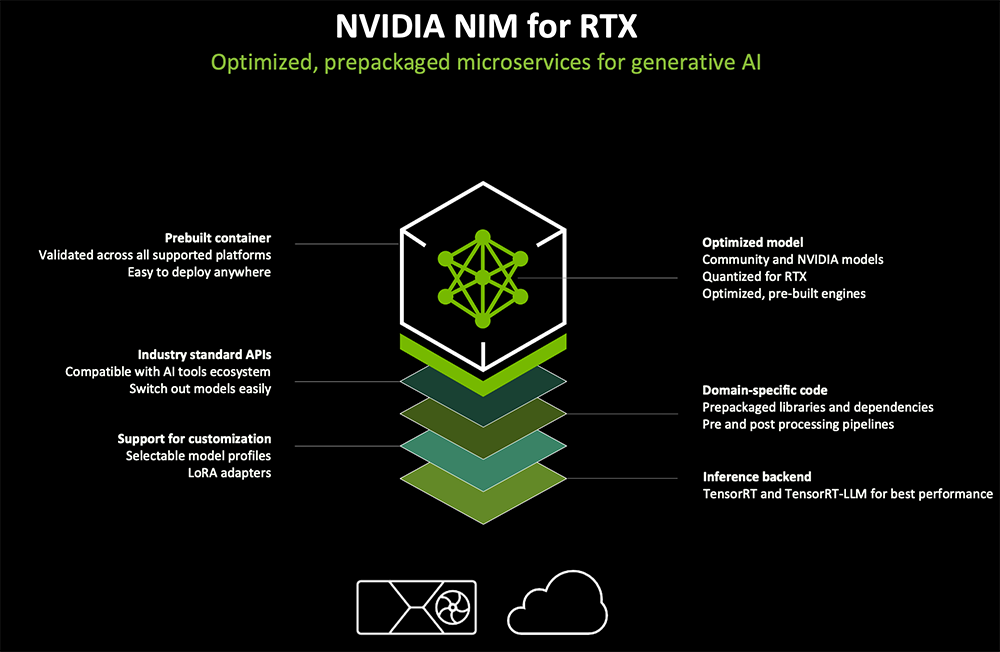
NIM微服务针对RTX GPU优化,包括在PC上运行AI所需的各种组件,包含为RTX优化的基础模型、领域特定代码、推理后端(TensorRT、TensorRT-LLM)、支持定制化的工具、行业标准API、预构建容器。
可以把这些微服务想象成堆积木,易组装和使用。NIM微服务可从ChatRTX、AnythingLLM、ComfyUI、LM Studio等常用开发者工具中体验前沿AI,让做AI开发变容易。
第一波RTX NIM微服务将在2月份上线。

NIM微服务针对Windows PC集成AI模型做了优化。适用于Linux的Windows子系统为Windows 11上的AI开发以及Windows Copilot Runtime提供了跨平台环境。
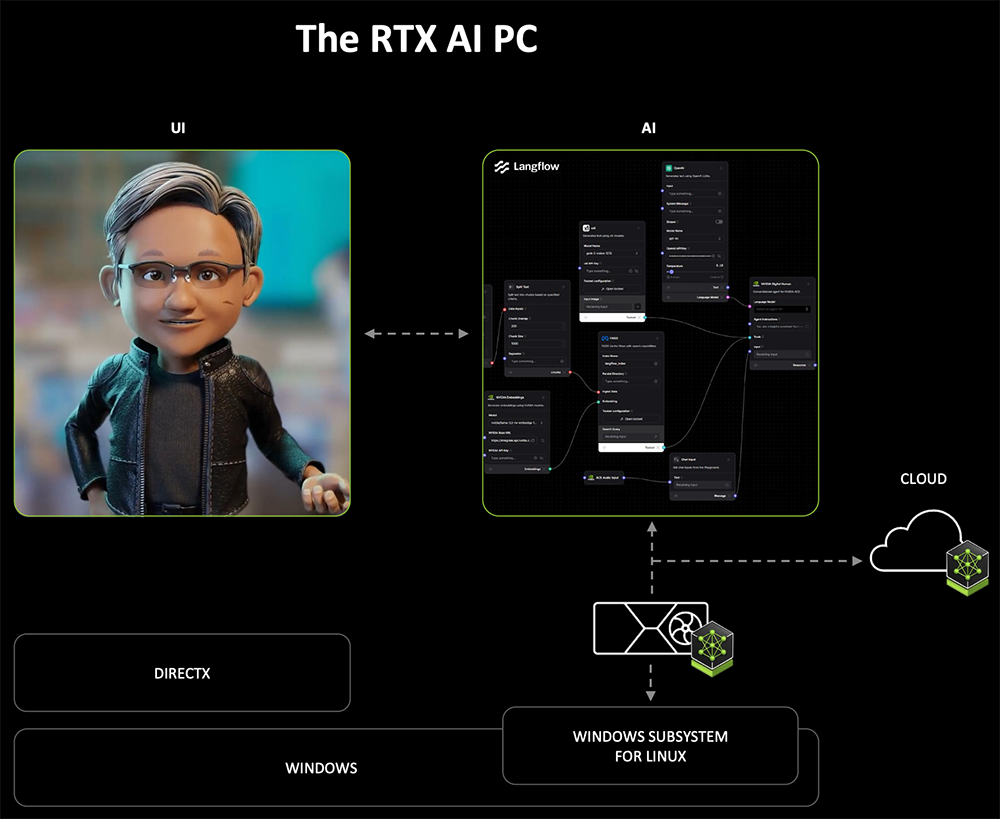
将NIM微服务与AI蓝图(AI Blueprint)结合,可以快速设置、定制和部署AI驱动的工作流。
AI蓝图基于NIM微服务构建,向开发者提供了如何使用微服务来构建AI体验的预配置参考,比如基于PDF创建播客、构建数字人、生成由3D场景引导的图像等应用。
NVIDIA展示了一款具有视觉能力的PC虚拟形象Project R2X,它可以协助桌面应用和视频电话会议、阅读和总结文档等。R2X可以通过常用开发者框架连接到GPT-4o、Grok等云端AI服务以及NVIDIA NIM微服务和AI蓝图。该虚拟形象采用RTX Neural Faces渲染,用完全生成的像素来增强传统光栅化渲染,然后用Audio2Face模型来优化面部表情和对口型。
还有一个由3D引导的生成式AI蓝图,可实现对图像生成更精细的控制。创作者可以用Blender等3D渲染器中布置的简单3D物体来引导AI图像生成:手动或用AI生成创建3D资产,将其放到场景中,设置3D视图相机,由FLUX NIM微服务驱动的预打包工作流将可以通过插件使用当前布景来生成与3D场景相匹配的高质量图像。

NVIDIA也提供了在RTX上开始使用NIM和AI蓝图的建议:先在网页端体验NIM,然后在RTX一键下载安装和运行NIM;有一个管理AI开发项目的工具AI Workbench,便于共享项目和协同管理;你还可以尝试集成agent、构建数字人并连接到UI。
消费级GPU RTX 50系列、4090、4080以及台式工作站GPU RTX 6000、5000都将从2月起首发支持NIM微服务和AI蓝图。来自Black Forest Labs、Meta、Stability AI、Mistral等顶级模型开发商的NIM微服务和RTX AI PC AI蓝图流程即将发布。

GeForce RTX 50系列笔记本电脑将于今年3月开始发布。针对能效改进,AI驱动型技术Max-Q可从GPU、CPU、显存、散热、软件、屏幕等方面优化笔记本电脑。全新Blackwell Max-Q技术包括DLSS 4、GDDR7电压优化、加速频率切换、低延迟休眠、高级电源门控等,有助于提升能效和性能、延长电池续航时间。

结语:AI与游戏的融合更加极致
正如前文所述,这次RTX 50系列将升级重点和卖点放在了AI软实力上,把AI和游戏的融合玩得更加极致,不仅能驾驭高画质游戏,在专业3D内容创作和渲染能力上也更具吸引力。
想必不少骨灰级游戏发烧友、专业3D制作渲染人员已经搓手准备好将RTX 5090 D放进购物车了。
随着摩尔定律逐渐走到头,硬件提升也会受到一定束缚。而NVIDIA工程师的思路非常灵活,通过新硬件和 AI 驱动的神经网络渲染的结合显著提高GPU性能。DLSS 等神经网络渲染技术提高了图形性能,同时也提高了游戏的图像质量。随着神经网络着色器的推出,Blackwell 为游戏渲染的未来开启了大门。
正如黄仁勋在主题演讲中强调的,GeForce显卡系列和AI相辅相成的关系,过去 GeForce助力了AI的发展,现在AI又反过来加速革新GeForce。
至于显卡实际性能、用AI补帧对游戏体验的真实影响,请关注将在不久后发布的评测。
这次RTX 50系列GPU的主要升级,你怎么看?
