








芯东西(公众号:aichip001)
作者 | 程茜
编辑 | 漠影
AI PC正在GPGPU芯片之上迸发出新的生命力!
智东西3月14日报道,在一年一度的行业大会世界移动通信大会上,PC、手机、机器人等各路终端设备无不与AI深度绑定。
作为全球AI PC龙头的联想亮出了自家系列AI PC解决方案,其产品背后的AzureBlade M.2加速卡正是支持其AI PC体验的关键动力。AzureBlade M.2加速卡就来自国内清华系GPGPU创企珠海芯动力科技。芯动力成为联想在笔记本电脑dNPU方案领域的首位合作伙伴。
在大模型时代,边缘设备迎来了新的机遇期,春节爆火的DeepSeek更是加速了这一进程,以AI PC、AI手机为代表的诸多硬件连番炸场。
其背后的原因是,大模型对数据处理的实时性、隐私性要求不断提高,边缘设备能够在靠近数据源的地方进行数据处理;边缘设备可承担部分数据预处理和简单推理任务,拓宽应用场景边界;DeepSeek凭借算法优化进一步加速了大模型在边缘设备上的部署与应用进程,让大模型以更低资源消耗在边缘设备高效运行。
这股边缘AI爆发的热潮宛如一把双刃剑,在为行业带来新契机的同时,也向AI芯片企业抛出了一连串棘手难题,高性能、低延时、低功耗、兼容多种操作系统……联想与芯动力的合作正是这道难题的最新解法。
边缘AI时代爆发前夜,M.2加速卡的独特优势是什么?其为何能入局AI PC龙头企业联想的产品布局中?我们试图通过拆解芯动力的产品,找到这些问题的答案。
一、DeepSeek引爆边缘AI,芯片厂商机遇挑战并存
在当下,端侧设备部署大模型的风潮汹涌。然而,这股热潮背后横亘着一个核心命题:端侧设备以及AI芯片是否足以承载大模型所需的性能。
因此,端侧AI爆发呈现出两大显著趋势。
一方面,端侧设备部署大模型这把火烧的更旺了。
此前,受限于硬件性能和模型技术,端侧部署的模型诸多无法处理复杂任务,这也导致端侧AI应用场景有限,但更靠近用户的端侧设备在保护用户数据隐私方面、实时反馈方面更有优势。
DeepSeek以开源和低成本的特性极大拉低了大模型部署的门槛,使得端侧设备部署更高性能大模型的可能性增强。同时,基于DeepSeek的算法优化策略,使得支持长文本处理等复杂任务的高性能大模型与端侧设备适配,开发者还可以通过蒸馏优化等生成特定场景性能更强的小模型。对于中小企业或者个人开发者而言,能更快速相关端侧AI应用。
随之而来的是,AI手机、AI PC到AI眼镜等加速涌现,端侧AI爆发已成共识。

▲华为、OPPO、荣耀、vivo、小米在手机端部署大模型
然而另一方面,端侧AI的爆发,于AI芯片厂商既是蓬勃发展的难得机遇,也带来了诸多严峻挑战 。
AI在手机、PC、智能穿戴等诸多端侧设备中应用不断拓展,使得AI芯片需求大幅增加,并且由于其设备形态、应用场景多元化,不同场景对芯片需求各异,为芯片厂商提供了更多差异化竞争的机会。
但更为关键的是,AI芯片的性能要符合当下端侧设备的发展趋势,主要集中在性能、功耗、成本、可扩展性上。
包括端侧设备对功耗要求极高,需要芯片兼顾低功耗、高性能,且当下算法和模型仍在不断更新迭代,芯片厂商需要确保芯片高效适配新的模型和算法。此外,端侧设备的厂商对成本更为敏感,芯片厂商需要降低芯片的制造成本、研发成本等,以提高产品的市场竞争力。
以AI PC为例,用户基于其需要处理的生成任务各不相同,文字、图片、视频生成等应用尽有,因此对于计算资源和处理能力的要求也有区别。
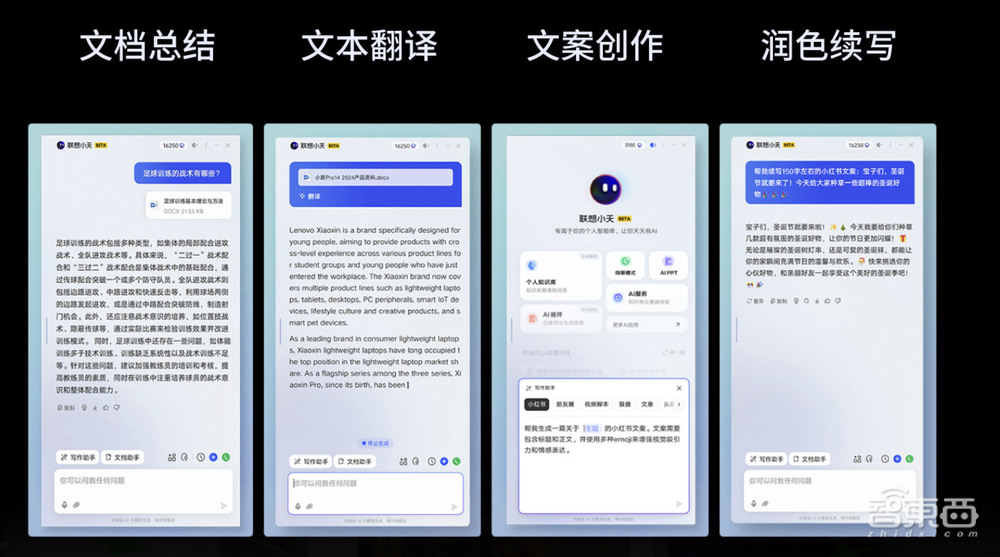
▲联想AI PC个人AI助力小天部分功能(图源:联想官方)
这种情况下,以通用计算为核心的计算架构在处理生成任务时可能面临性能有限、效率低下、能耗高、灵活性不足等瓶颈,因此从以通用计算为核心的计算架构向更加高性能的异构AI计算架构升级,成为当下增强端侧设备生成式AI体验的重要路径。
通过让CPU、GPU、NPU等不同计算单元“各司其职”、协同运作,构建高性能异构AI计算架构,便能依据各类生成任务的特性,实现任务的合理分配 。
此外,对于AI芯片而言,在满足性能与功耗等严苛要求的同时,还需提供更高的性价比,才能吸引PC厂商在设备中选用,同时也让终端用户更乐于接受搭载此类芯片的产品。
在这个关键节点,以AI PC为代表的端侧设备正在呼唤相匹配的AI芯片,加速大模型在端侧的繁荣。
二、小体积、高性能、低功耗、高性价比,M.2加速卡成AI PC致胜利器
就在2025世界移动通信大会(MWC 2025)上,我们看到了AI PC龙头联想和国产AI芯片厂商芯动力联手的成果。
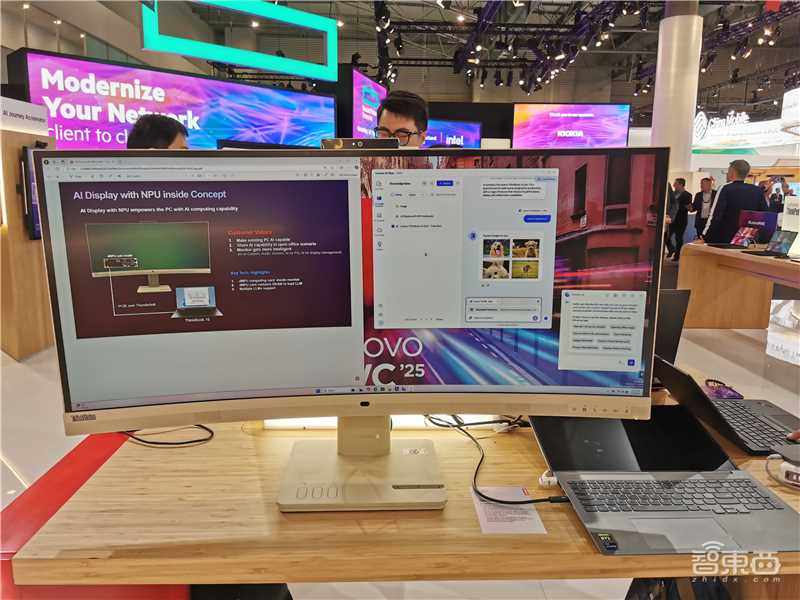
联想全新升级的AI PC系列产品亮相,而支持其AI体验的关键之一,正是芯动力基于可重构并行处理器RPP打造的AzureBlade M.2加速卡。

联想相关负责人在MWC上介绍,联想AI PC实现了将大模型放到本地端推理的突破,尽管传统本地推理大都采用集成(CPU+iNPU)或独立显卡GPU,但经过多重对比发现,在运行大语言模型时,通常依赖GPU进行加速,iNPU只有在特定的场景中才能被调用。联想AI PC最终采用了芯动力AzureBlade M.2加速卡,并命名为dNPU。M.2加速卡在进行大模型推理时具有高效率、低功耗性能,同时可进一步释放显卡能力,在提高效率的同时更节约能耗。

▲AI NOW不做大模型推理:右侧GPU usage和dNPU占用率均为0%
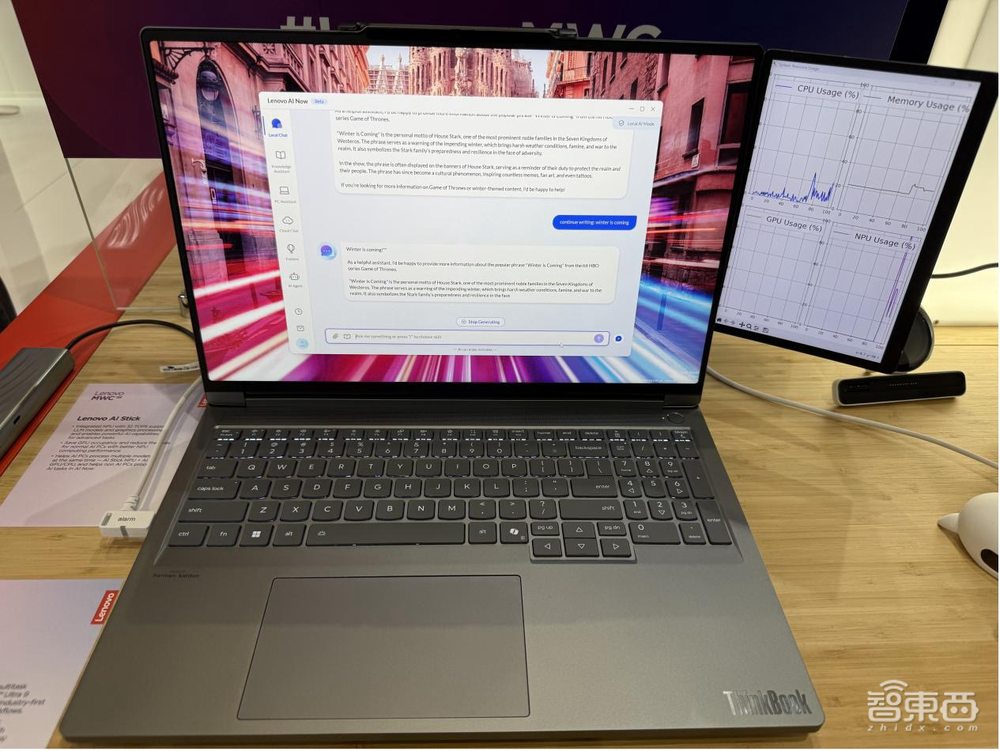
▲AI NOW进行大模型推理:右侧GPU usage仍为0%,dNPU在40%上下
从具体的效果来看,联想PC上的个人智能体AI NOW执行推理任务主要在dNPU内完成,无需占用 CPU、显存或GPU资源,整个推理过程中,CPU的资源占用极低,仅在数据预处理以及数据传输环节占用少量资源,可以显著提高推理速度和整体性能。
这种设计整体优化了系统运行的高性能和低功耗。
具体来看,AI PC等端侧设备通常受限于紧凑空间,内部留给各类组件的体积十分有限,因此M.2加速卡的体积也要足够小。
芯动力基于RPP架构自主研发的AI芯片AE7100尺寸仅为17mm×17mm,集成了该芯片的M.2加速卡尺寸为22mmx88mm,大小与半张名片相当。

与之相匹配的是强大的性能,M.2加速卡拥有高达32TOPs的算力以及60GB/s的内存带宽,功耗也被严格控制在8w以下,同时可支撑大模型在AI PC等设备上运行,适配了Deepseek、Llama3-8B、Stable Diffusion、通义千问等开源模型。
为了让M.2加速卡与PC自然融合,芯动力采用扇出型封装,用玻璃载板替代ABF材料,既减小了芯片面积,还实现了低成本先进封装。
值得一提的是,端侧AI应用开发的需求多样化,因此AI芯片需要降低开发者的软件适配和调试难度、成本,让其更容易实现AI应用的兼容,帮助其更快开发出相应应用。
在此基础上,AE7100实现从底层指令集到上层驱动的全面兼容,沿用英伟达软件栈,并进行了指令集、驱动层和开发库的优化,提升开发效率与逻辑实现的直观性。
同时,由于M.2加速卡兼容CUDA和ONNX,能够满足各类AI应用的多样化需求,其高算力和内存带宽能确保数据的高效稳定处理与传输。无论是图像识别、自然语言处理等需要大量数据运算的AI任务,还是对数据实时性要求高的场景,该加速卡都能保障数据处理和传输的顺畅,避免因算力不足或数据传输瓶颈导致的应用性能下降。
在AI和非AI设备上,M.2加速卡都实现了兼容。如AI智能调整、隐私保护等,联想AI Monitor内置M.2加速卡,可以实现监控用户的动作和姿势,实时调整屏幕的倾斜角度和高度,以及用户离开电脑前自动模糊屏幕等;对于非AI设备,联想AI Monitor可以与其配合使用,利用M.2加速卡的算力处理来自用户的请求。
可以看出,M.2加速卡针对端侧设备部署大模型的优化是全方位的。也正因如此,在当前端侧AI发展浪潮下,全球AI PC巨头联想选择了与芯动力联手。
将视角拉长,我们发现,这正是芯动力在AI时代精准洞察行业趋势,积累势能的最好体现。
三、“六边形战士”剑指边缘AI,契合端侧大模型部署痛点
想要剖析芯动力在当下的优势,可以从其针对并行计算设计的芯片架构说起。
芯动力将其自研的RPP架构称作“六边形战士”,主要解决的就是高性能、通用性可以兼得的难题。
这一架构既结合了NPU的高效率与GPU的高通用性优势,更具备DSP的低延时,可满足高效并行计算及AI计算应用,如图像计算、视觉计算、信号处理计算等,大大提高了系统的实时性和响应速度。
芯动力的优势在于,其是首家采用CUDA作为芯片架构的设计方向,利用数据流结构避免数据与计算单元间反复调用带来的效率损失。并且其具有编译器、运行时环境、高度优化的RPP库,可全面兼容CUDA的端到端完整软件栈,实现边缘AI应用的快速高效部署。
这契合了当下大模型部署在端侧设备的诸多痛点。
正如联想相关负责人所说:“dNPU代表了未来大模型在PC等本地端推理的技术方向和趋势。”
展望未来,该芯片可以提升大模型在端侧部署时的推理速度,并降低功耗、提升能效,推动多元化AI应用涌现的同时,为AI PC带来更多增长空间。或许在未来,dNPU对PC的加持会使其成为与GPU类似的电脑标配。
此外,dNPU可以以独立的标准化插件存在,给用户提供了更高的性价比和灵活性,如果其对生成式AI能力没有更高需求,用户可以不采用dNPU。反之,若将dNPU集成至CPU中,会导致产品价格过高,降低用户的购买欲望。
或许在不远的将来,dNPU就会作为标准化插件,广泛出现在市面上所有可选择配置的电脑机型中。边缘AI时代的爆发已经有迹可循。
边缘计算作为云端算力有效补充,同样是大模型落地的必然趋势。
大模型由于参数规模庞大、计算复杂度高,对算力的需求极为严苛,将大模型部署在云端,虽然能利用强大的云端算力,但数据往返云端的过程会产生不可忽视的延迟,这对于如自动驾驶、智能安防等对实时性要求极高的应用场景而言是致命的。
DeepSeek的出现,意味着边缘AI竞赛来到新的节点。在边缘设备上运行更复杂、更强大的AI模型成为现实,吸引了众多企业和开发者投身于边缘AI领域的创新与竞争。
在这之前,芯动力基于RPP架构打造的AI芯片,已经凭借高性能、低功耗、低成本等优势,在泛安防/边缘服务器、工业影像/机器视觉、信号处理/医疗影像、机器人等边缘AI应用市场有众多应用落地,并与浪潮信息等众多重磅玩家达成战略合作。
可以确定的是,芯动力RPP芯片架构的应用潜力正被无限释放出来,看到这一发展趋势的芯动力,也加快了产品的发布节奏。据了解,今年,芯动力将推出基于RPP集成Chiplet的8nm R36芯片,2027年将推出更高性能的3nm R72芯片。
结语:RPP架构为边缘AI时代爆发积势
AI时代的产业发展速度之快、变化之多可谓有目共睹,从日常生活中的智能语音助手,到工业领域的智能生产系统,AI的应用正以前所未有的广度与深度渗透进各个行业。这一浪潮下,AI芯片需要具备更强大的计算能力以满足复杂运算需求,才能承接住这一波市场红利。
因此,精准洞察产业发展趋势、坚持自研创新、将自身业务体系做到极致才能有效应对市场变化。芯动力RPP架构的出现就是很好的例证,未来,其将基于这一“六边形战士”带给边缘AI时代什么样的惊喜,我们拭目以待。
