








机器人前瞻(公众号:robot_pro)
作者 | 许丽思
编辑 | 漠影
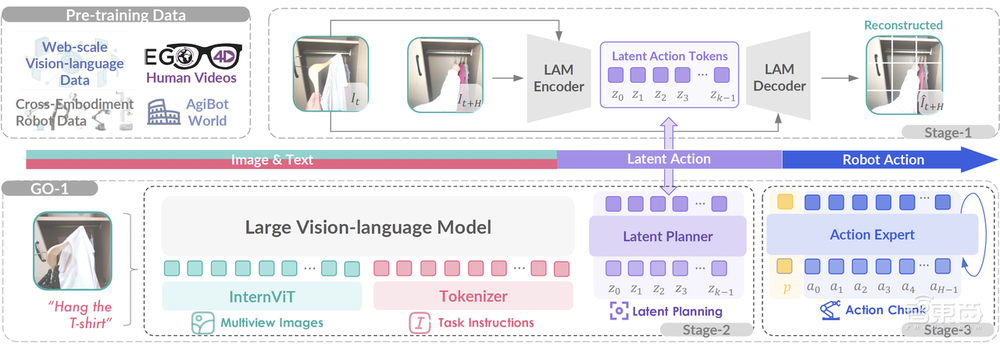
机器人前瞻3月10日报道,今天,智元机器人发布首个通用具身基座模型——智元启元大模型Genie Operator-1(GO-1)。该模型提出了Vision-Language-Latent-Action(ViLLA)框架,该框架由VLM(多模态大模型)+MoE(混合专家)组成,具有采训推一体,小样本快速泛化、“一脑多形”的跨本体应用、持续进化、人类视频学习等突出优势。
另外,智元还预告了,未来几个月会推出基于强化学习的仿真模型,新的人形机器人也即将亮相。
一、小样本快速泛化,快速适配不同本体
ViLLA框架包含了VLM(多模态大模型)+MoE(混合专家)。
具体来说,VLM作为通用具身基座大模型的主干网络,继承开源多模态大模型5-2B的权重,利用互联网大规模纯文本和图文数据,让智元机器人的Genie Operator-1(GO-1)具备了通用的场景感知和理解能力。
MoE中的隐动作专家模型是整个大模型中隐式的规划器,作为第一个专家模型,它利用到了互联网上的大规模人类操作和跨本体操作视频,让模型具备动作的理解能力。
MoE中作为动作预测器的动作专家模型,利用高质量的仿真数据、真机数据,让模型具备了动作的精细执行能力。
Genie Operator-1有五大方面特点:
- 采训推一体:搭配智元软硬件一体化框架,可以实现数据采集、模型训练、模型推理的无缝衔接。
- 小样本快速泛化:具有强大的泛化能力,使得后训练成本非常低,能够在极少数据甚至零样本下泛化到新场景、新任务。
- 一脑多形:是一个通用机器人策略模型,能够在不同机器人形态之间迁移,快速适配到不同本体。
- 持续进化:搭配智元一整套数据回流系统,可以从实际执行遇到的问题数据中持续进化学习。
- 人类视频学习:可以结合互联网视频和真实人类示范进行学习,增强模型对人类行为的理解。
二、吸纳海量知识数据,一句语言指令让机器人直接执行任务
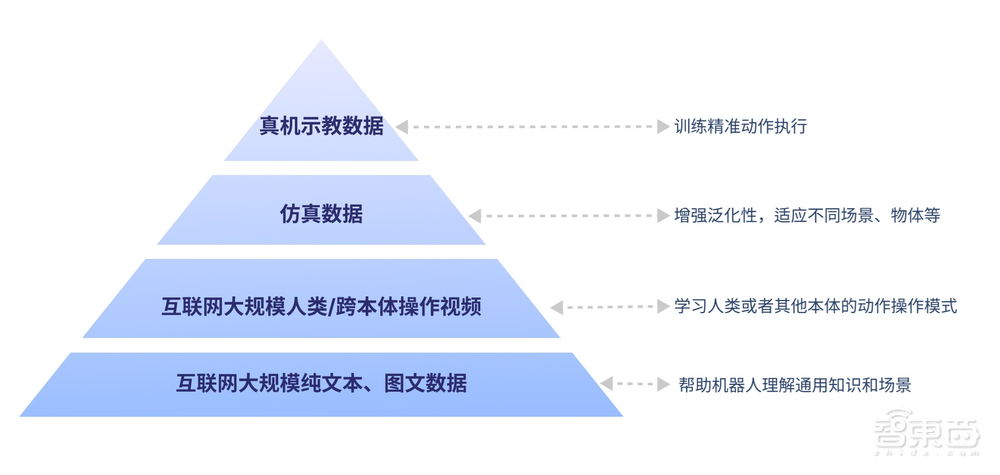
智元机器人的Genie Operator-1(GO-1),基于具身领域的数字金字塔所构建:
底层是互联网的大规模纯文本与图文数据,可以帮助机器人理解通用知识和场景。
在这之上是互联网的大规模人类操作/跨本体视频,可以帮助机器人学习人类或者其他本体的动作操作模式。
更上一层则是仿真数据,用于增强泛化性,让机器人适应不同场景、物体等。金字塔的顶层,则是高质量的真机示教数据,用于训练精准动作执行。
在此基础上,机器人就可以成全面的“基础教育”和“能力培训”,天然能适应新的场景,可以轻松面对多种多样的环境和物体,快速学习新的操作。
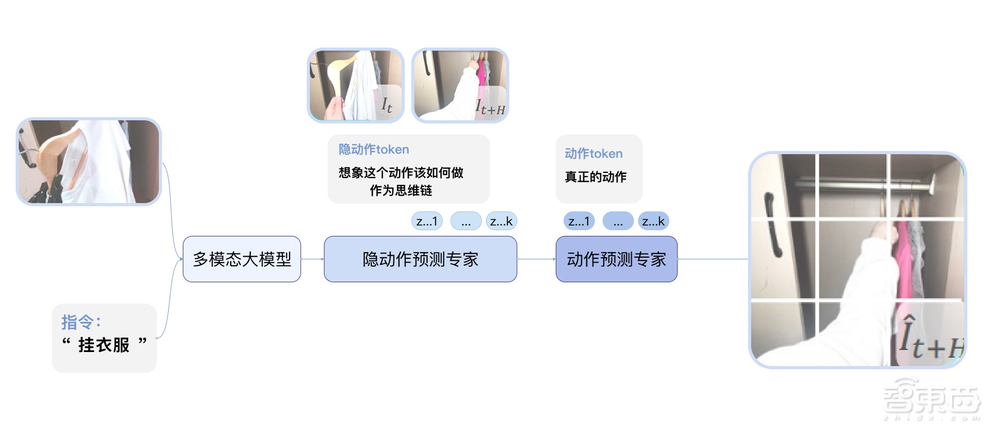
GO-1所采用的由VLM+MoE组成的ViLLA框架,可以将输入的多相机的视觉信号和人类语言指令,直接输出机器人的动作执行。和与Vision-Language-Action(VLA)模型相比,ViLLA通过预测Latent Action Tokens(隐式动作标记),弥合了图像-文本输入与机器人执行动作之间的鸿沟。
比如,用户用平常讲话的方式告诉机器人要做的事情,比如“挂衣服”,模型就可以拆解成一些几个步骤来处理:
首先,模型可以根据看到的画面,以及所学习过互联网的大规模纯文本和图文数据,能理解“挂衣服”在此情此景下的含义和要求;
其次,模型学习过互联网的人类操作视频和其他机器人的各种操作视频,所以能知道挂衣服这件事通常包括哪些环节;
然后,模型学习过仿真的不同衣服、不同衣柜、不同房间,模拟过挂衣服的操作,所以能理解环节中对应的物体和环境并打通整个任务过程;
最后,因为学习过真机的示教视频,机器人就能精准完成整个任务的操作。
GO-1可以让机器人应用到更多的场景中。早上刚起床,机器人会帮忙倒上一杯水、烤下吐司,还可以去一些活动现场,负责检票、发放物料的活。


在商务会议中,面对人类发出的“帮我拿一瓶饮料”“帮我拿一个苹果”的语音指令,GO-1可以让机器人快速相应。


值得一提的是,GO-1还可以通过数据回流,持续进化:比如,机器人做咖啡的时候不小心把杯子放歪了,后续就可以从遇到这个问题数据中持续进化学习,直到成功完成任务。

结语:具身智能加速迈向通用化、开放化与智能化
一直以来,具身智能面临着场景和物体泛化能力不足、缺乏语言理解能力做不到指令的泛化、无法快速学习新技能、实现跨本体的部署等问题。
GO-1的出现,为机器人代替人类完成工作生活中的各种事情,提供了强大的脑力支持。从准备餐食、收拾桌面这样的家庭场景任务,到接待访客、发放物品这类办公和商业场景的常见工作,再到工业等更多场景的其他操作任务,通用具身基座大模型都可以快速实现。这也意味着具身智能从单一任务到多种任务、从封闭环境到开放世界、从预设程序到指令泛化加速迈进,让机器人走向更多不同场景、适应多变的真实世界。
