








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西5月8日报道,今日,Imagination Technologies推出兼顾边缘AI计算和图形渲染需求的全新E系列GPU IP。E系列(E-Series)凭借其高效的并行处理架构,INT8/FP8算力可在2到200 TOPS之间扩展,为边缘应用提供了一种通用且可编程的解决方案。
该GPU IP适用于图形渲染、桌面应用、智能手机上的自然语言处理、工业计算机视觉以及自动驾驶等领域。首款E系列GPU IP将于2025年秋季正式上市,目前已完成授权。汽车、消费电子、桌面及移动版本亦在同步开发中。
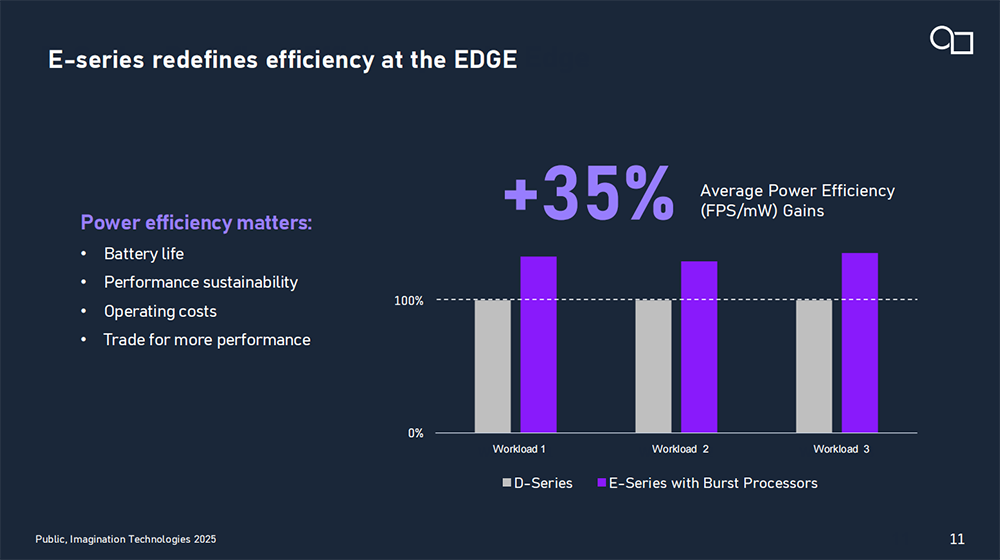
Imagination的PowerVR GPU架构以能效著称,已在功耗受限设备中应用近二十年。E系列进一步引入全新的爆发式处理器(Burst Processors) 技术,在AI推理、游戏和用户界面等工作负载下平均功耗效率再提升35%。
Imagination创新与工程负责人Tim Mamtora谈道:“E系列将GPU放在图形与边缘AI系统的核心位置。对需要同时运行图形与计算任务的系统设计者而言,E系列GPU提供了一种高度灵活的解决方案,既无需依赖额外的向量处理器或固定功能AI加速器,又能在降低整体系统设计成本的同时,实现面向未来的可扩展性。”
在媒体沟通会上,Imagination中国区董事长兼亚太总裁白农告诉芯东西等媒体,这款新产品是Imagination在图形和计算领域多年来累积的又一个里程碑,它不仅在性能、功耗和面积方面实现了全面的优化,更在架构设计上实现了从传统渲染将通用计算的深度拓展,具备高度的灵活性和可扩展性。
“中国一直是我们全球最重要的战略市场之一,”白农谈道,“未来,我们将持续加大对中国市场的投入,不仅为加大本土技术支持团队的建设,还将升华与本土生态伙伴的合作,帮助客户抓住新一轮AI浪潮带来的市场机遇。”
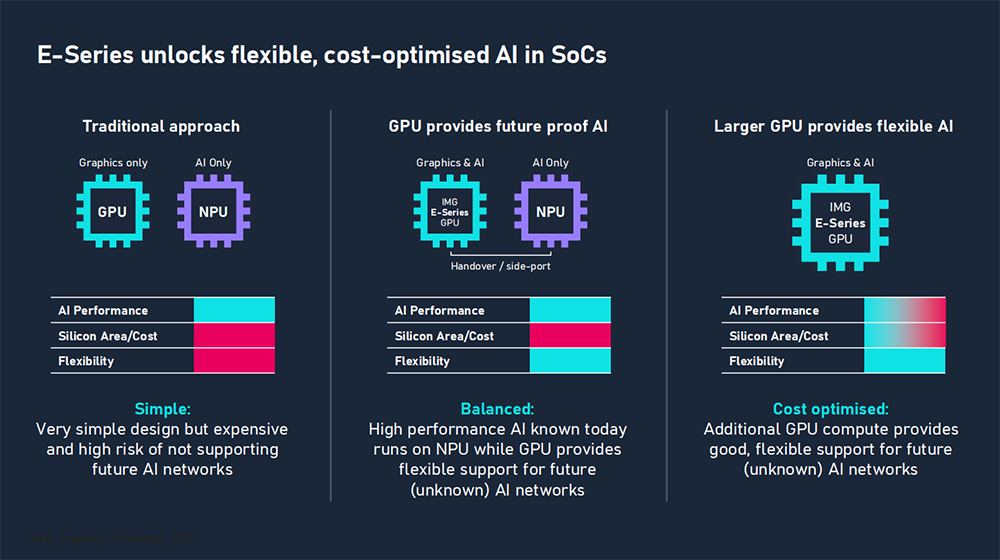
一、两大核心创新,AI算力可扩展至200TOPS
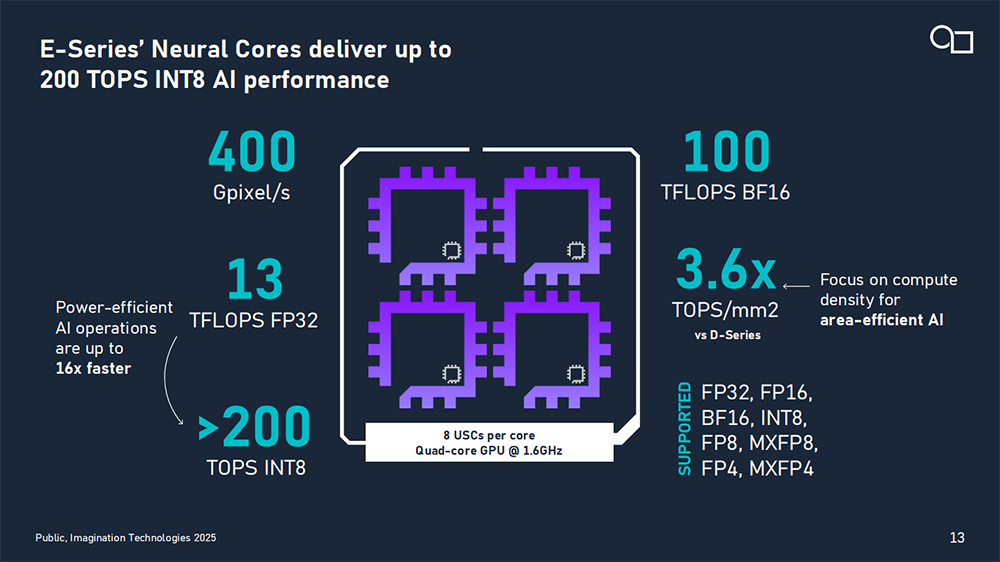
Imagination E系列GPU IP的每个GPU核深度集成低精度、高能效AI加速能力。小核在1GHz频率下有8Gpixel/s的像素填充率、0.25TFLOPS浮点算力、2TOPS INT8算力,可满足轻量级应用需求。4核配置在1.6GHz频率下可提供400Gpixel/s的像素填充率、12.8TFLOPS浮点算力(FP32)、超过200TOPS的INT8算力。
E系列有两项核心创新:Neural Cores(神经核)与Burst Processors(爆发式处理器)。
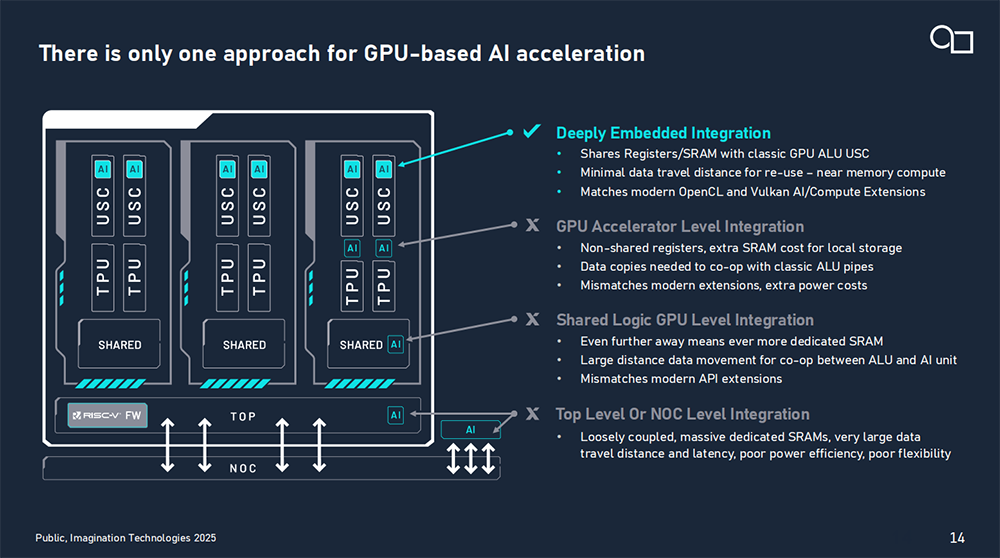
神经核计算密度高,AI性能可扩展至200 TOPS INT8 ,较前代D系列提升高达400%。它支持FP32、FP16、BF16、INT8、FP8、MXFP8、FP4、MXFP4等多种主流AI数值格式,能够满足不同精度、性能与功耗需求。其AI友好的内存架构在计算时优先使用本地内存,大幅降低了访问外部内存所消耗的功耗和性能成本。
爆发式处理器拥有创新的架构设计,使边缘应用中平均功耗效率提升35%。该技术深度集成于GPU中,改变了GPU原有指令调度方式,通过缩短流水线深度、减少数据在GPU内部的移动等方式,实现尽可能多的数据重复使用和共享,从而减少很多不必要的计算开销,提升能效。
爆发式处理器主要优势包括:对特定指令进行调度,最小化控制器开销,不会牺牲很多的延迟;重新设计ALU流水线,对流水线级数做缩减,实现了更高效的利用率,从而降低整体延迟和功耗;大量重复利用来自本地存储的数据,这也给功耗降低提供助力。
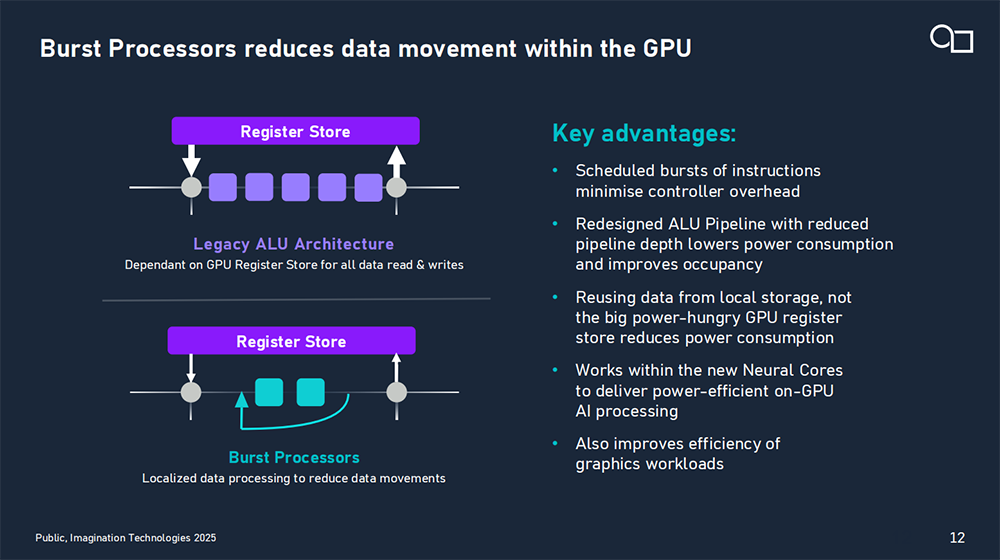
E系列GPU上的创新建立在原有硬件资源的基础上,并不会显著增加芯片的面积,还可以对能效进行持续改进。
例如其一项重要架构设计是在每一个计算单元都有将近0.5Mb的寄存器空间,能在芯片上高效保留需处理的数据。这些资源是GPU进行图形处理时就存在的,现在又增加了AI相关的高效处理流水线,本质上没有额外增加芯片面积。
图形处理和其他计算之间的灵活性取决于两者之间的负载平衡,而Imagination实现了一种具有高灵活性的解决方案,可以对几何像素和传统计算进行负载平衡,还有基于优先级的一些MCU调度机制。另一个优势是,GPU需要对多种不同纹理类型格式进行处理,本身就支持非常广泛的数据类型,如今又拓展了数据转换流水线来支持AI数据类型。
二、软硬件充分协同,在GPU上可编程地开发AI模型
GPU作为可编程处理器,通过面向未来的架构设计,使设备能够持续应对AI、计算和图形工作负载的演进。
E系列延续了Imagination GPU的出色图形处理能力,支持光线追踪。通过在GPU内部深度集成AI加速能力,其神经核与更广泛的GPU及异构计算软件生态实现无缝协同,有助于降低开发门槛。
Imagination也投入了大量的时间和工程资源,在更底层上确保认不同的AI工具和接口能够与其硬件形成一种经优化的配合流程。
E系列GPU IP的算力可通过OpenCL等主流API直接调用,开发者借助oneAPI、Apache TVM或LiteRT等开放标准工具,能轻松将工作负载迁移至神经核。Imagination的计算库与高度优化的图形编译器,可提高硬件利用率,进一步释放GPU的潜能。
当代设备日益复杂,处理器需同时支持图形与AI多项工作负载。为保障用户体验,实现高质量服务(QoS)和清晰划分任务优先级至关重要。E系列在前代产品的多任务处理能力基础上实现了增强,将Imagination GPU支持的、具备硬件加速且零开销的虚拟机数量从8个翻倍至16个,并提供了先进的QoS支持。
E系列GPU IP的多核版本可利用额外的核心来提升性能或增强灵活性。这些GPU能够同时处理多种图形工作负载、多种AI工作负载,或图形与AI工作负载的组合。
结语:可集成到各类SoC设计中,在任意设备上灵活部署新算法
IDC研究总监Phil Solis认为:“各类设备上的AI功能正在迅速演进,但AI系统设计者依然面临性能、效率与灵活性的多重挑战。Imagination凭借其长期深耕低功耗GPU的经验,成功实现了GPU架构对图形与AI的灵活支持。E系列结合了GPU的可编程性与AI性能的飞跃,为边缘AI系统开发者带来了极具吸引力的解决方案。”
在行业分析师看来,要实现终端智能的真正潜力,边缘AI的软硬件必须协同演进。E系列便做到了各类开发者都能在任意设备上灵活部署最新算法。
由于Imagination提供的是一个软IP解决方案,客户可将其GPU IP集成到几乎任何种类的SoC设计中。无论是想要开发用于智能手机或者其他系统的传统SoC芯片,还是打造带有自家显存控制和PCIe总线的独立GPU芯片、然后把它设计成一块完整显卡,都可以通过选用Imagination IP解决方案来实现。
