








智东西AI前瞻(公众号:zhidxcomAI)
作者 | 江宇
编辑 | 漠影
智东西AI前瞻7月2日报道,今日,百度团队发布自研视频生成模型MuseSteamer及配套创作平台“绘想”。
与传统AIGC视频依赖“画面生成+后期配音”流程不同,MuseSteamer实现了画面、音效与人声台词的协同生成,成为全球首个具备中文音视频一体化生成能力的视频模型。MuseSteamer还在业内评测集VBench I2V中获得89.38%总分,登顶全球第一。
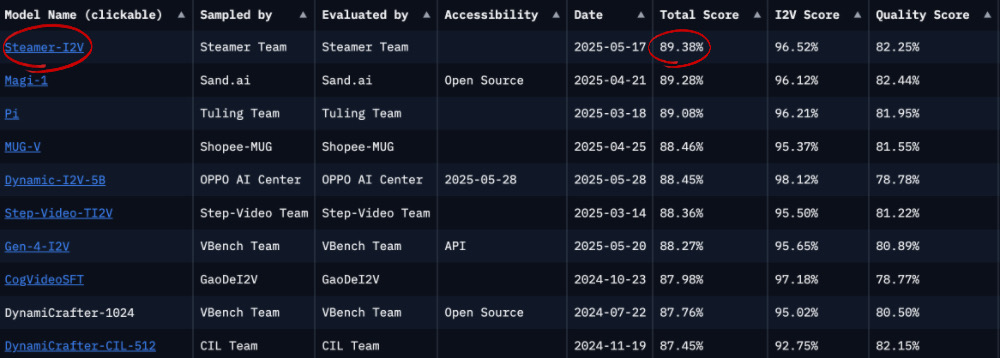
▲图源:VBench-12V榜单
MuseSteamer模型家族包括Turbo、Lite、Pro及多种有声版本,覆盖从普通用户到专业制作团队的不同应用场景。
其中,Turbo和Lite版支持720P分辨率,Pro版为1080P高清画质。
三者在生成速度与画质上各具侧重:Turbo版定位全能型,可在约2分钟内生成5至10秒视频;Lite版主打极速模式,生成同规格视频约需30秒;Pro版强调画质表现,生成时间相对较长,约为20分钟。

据介绍,MuseSteamer模型背后依托亿级中文多模态数据清洗、精细化视频结构语言与多目标强化学习等底层优化,具备以下核心能力:
- 支持一张图生成10秒1080p视频,画质接近电影水准;
- 人物微表情与运镜衔接自然,表现接近专业影视团队制作。
目前,模型家族中的Turbo版已在“绘想”平台上线,并开启限时公测,其他版本计划于8月逐步开放。智东西第一时间在“绘想”平台,对该版本进行了初步体验。
体验指路:https://huixiang.baidu.com/
用户可上传任意一张图片(≥300×300,支持 JPG/PNG/WEBP 格式)作为首帧图,并输入文本提示,系统即可生成视频。平台亦提供提示词库供用户快速选用镜头语言。
1、体验1:“等待戈多”+「镜头向右」(提示词+提示词库中的镜头选择)

▲图片为AI生成。
画面中人物的服饰在动作变化中呈现出较自然的动态效果,背景人物与建筑细节也具备一定的真实感。此外,镜面元素中还呈现了对应的反射画面,增强了整体的空间感与真实度。

2、体验2:“黑袍杀手”+「镜头拉近」

▲图片为AI生成。
尽管画面中的人物保持静止状态,随着镜头缓慢推进,墙面纹理和废弃物堆的细节逐渐显现,整体镜头语言呈现出一定的电影质感。

3、体验3:“魔法古堡”+「镜头向上」

▲图片为AI生成。

该模型在照片中对动物的识别和还原较为准确,对多对象的远近关系与体积比例处理也相对合理。
结语:多模态协同提速,AI视频走进深水区
自今年以来,AI视频生成领域已进入高频更新节奏:6月初,豆包Seedance 1.0 Pro发布,在测评榜单Artificial Analysis中,力压谷歌Veo3和可灵2.0等多模态模型;6月中旬,Midjourney发布其首个视频模型V1;随后,海螺AI也推出更新版本,支持生成1080P画质的10秒视频。
目前,各家产品在输入方式(文本/图像/混合)、输出时长与分辨率、镜头调度与音频生成等维度各有侧重。
整体来看,AI视频正在从“能生成”迈向“懂语义、可控音画”的阶段转变。未来,多模态协同将是AI视频发展的关键方向。
