







智东西(公众号:zhidxcom)
作者 | 陈骏达
编辑 | 心缘
智东西10月11日报道,昨晚,快手Kwaipilot团队开源了最新一代编程模型KAT-Dev-72B-Exp,这一模型在软件开发能力评测基准SWE-Bench Verified上取得74.6%的成绩,超越Qwen3-Coder、DeepSeek-V3.1、Kimi-K2和GLM-4.6等多款模型,成为开源模型之最。

KAT-Dev-72B-Exp是KAT-Coder模型强化学习的实验版本,由快手自研的SeamlessFlow强化学习框架提供技术支撑。该框架实现了训练逻辑与智能体的完全解耦,能够灵活支持多智能体和在线强化学习等复杂场景。
针对复杂Agent场景,Kwaipilot团队引入了Trie Packing机制,并对训练引擎进行了重构优化,使模型能够高效地在共享前缀轨迹上开展训练,还通过难度感知的策略优化,实现了探索与利用的平衡。
值得注意的是,快手发布KAT-Dev-72B-Exp模型开源消息的账号归属为溪流湖科技,企查查信息显示这是一家快手的关联企业。在溪流湖科技的官网上,还能看到一款名为“CodeFlicker”AI IDE产品已经进入预约阶段,其产品界面与Cursor类似。
目前,KAT-Dev-72B-Exp已被上传至开源平台Hugging Face,用户也可在溪流湖科技的官网限时领取KAT-Coder的2000万个专属token。
▲KAT-Dev-72B-Exp开源项目
Hugging Face项目地址:
https://huggingface.co/Kwaipilot/KAT-Dev-72B-Exp
KAT-Coder免费体验链接:
https://www.streamlake.ai/product/kat-coder
一、双管齐下给强化学习提效,整体训练速度平均提升150%
在KAT-Dev-72B-Exp的强化学习训练中,Kwaipilot推出了一套融合树形轨迹训练优化(Trie Packing)与熵感知优势缩放的新方法,显著提升了强化学习训练的吞吐量与策略探索能力。
在传统的大模型Agent训练中,由于模型在执行任务时会产生包含分支与回溯的树状token轨迹,业界普遍采用拆分为多条线性序列的简化训练方案。然而,这种方法忽略了轨迹之间的共享结构,容易造成计算冗余。
Kwaipilot的工程团队重新设计了训练引擎与注意力内核(attention kernel),并通过树形梯度修复权重机制,将共享前缀的正反向计算合并,实现了在树形轨迹上的高效训练。
实测数据显示,这一技术方案令整体训练速度平均提升至原来的2.5倍,大幅提高了强化学习训练阶段的吞吐效率。
强化学习的优化核心在于策略梯度,而优势函数(Advantage Function)直接决定了每个样本在参数更新中的影响力。传统的GRPO算法仅基于组内收益计算优势值,忽视了策略的探索性,容易使模型过早收敛到局部最优。
针对这一问题,Kwaipilot团队提出了基于熵的优势缩放方法。该方法在每个rollout样本中引入策略熵(Policy Entropy)作为权重调节因子,对高熵样本(探索性强)放大优势,对低熵样本(确定性强)适度抑制。
通过这一机制,模型在保持收敛效率的同时,显著增强了探索能力,实现了更优的探索—利用平衡。
二、自研工业级强化学习框架,吞吐量提升超50%
在训练KAT-Dev-72B-Exp的过程中,快手还使用了自研的SeamlessFlow工业级强化学习框架,以支持复杂的强化学习场景。
快手Kwaipilot团队曾于今年8月发布SeamlessFlow的技术报告。具体来看,SeamlessFlow共有两大创新点。
首先,SeamlessFlow引入了独立的数据平面层,彻底解耦了RL训练和智能体实现。数据平面的核心是轨迹管理器(Trajectory Manager)。
轨迹管理器在智能体与语言模型服务之间静默记录所有交互细节,包括输入输出及多轮对话的分支结构,从而构建完整的轨迹树。这一设计不仅避免重复计算、提升存储效率,还支持精确的在线与离线策略区分。
SeamlessFlow的另一组件是推理管理器(Rollout Manager),它实现了对模型更新与资源调度的无感控制,使得智能体无需适配训练框架即可实现任务的无缝暂停与恢复,大幅提升了系统灵活性与训练效率。
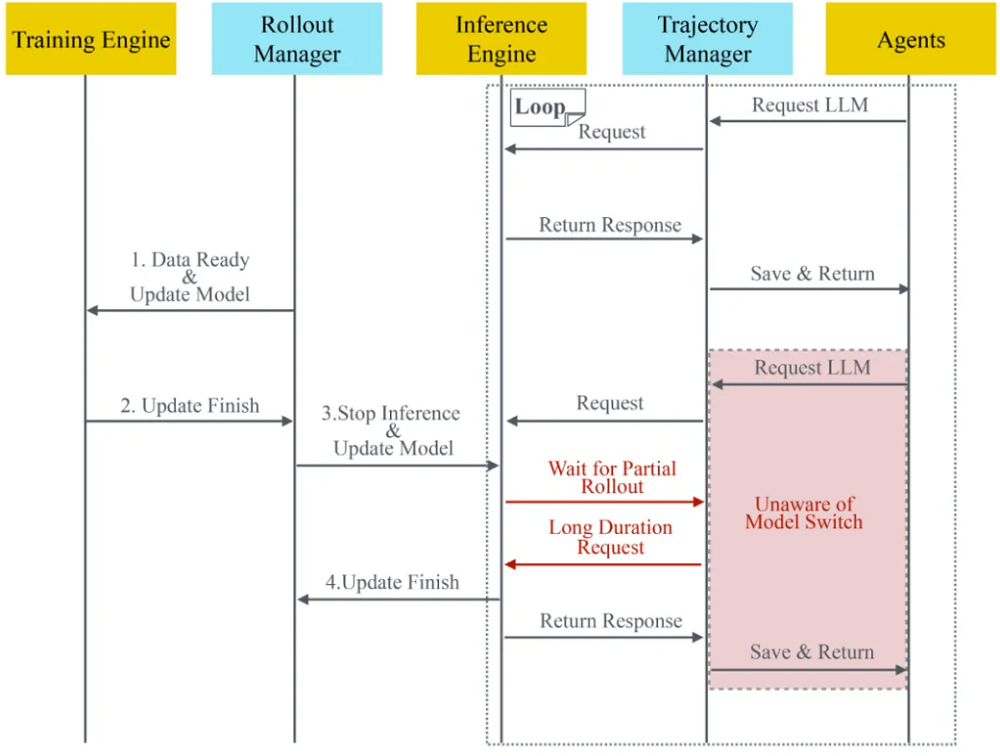
▲数据平面的序列图(图源:Kwaipilot)
SeamlessFlow的另一关键创新是标签驱动的资源调度范式,通过为计算资源赋予如“训练”或“推理”等能力标签,统一了集中式(Colocated)与分布式架构(Disaggregated)的资源管理模式。
该系统支持时空复用机制,使得具备多标签的机器可根据任务需求动态切换角色,从而将GPU闲置率降至5%以下,彻底缓解了传统架构中的流水线空闲问题。
在实际工业场景的验证中,SeamlessFlow在多项任务中实现了显著的吞吐量提升与扩展性优势。
使用32张H800 GPU进行的对比测试显示,相比主流的VERL框架,SeamlessFlow在单轮RL任务(8k token上下文)中实现了100%的吞吐量提升,整体训练时间减少62%。这个提升主要来自于数据平面的流式设计和计算资源空闲期的消除。
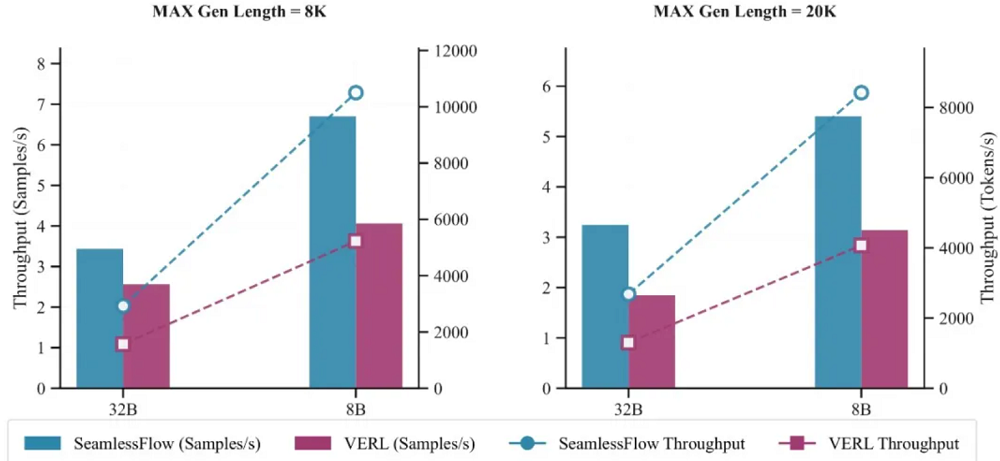
在更复杂的智能体RL场景中,SeamlessFlow的优势更加明显。在最大生成长度64K token的代码任务中,SeamlessFlow的吞吐量提升平均提升至原来的1.55倍。
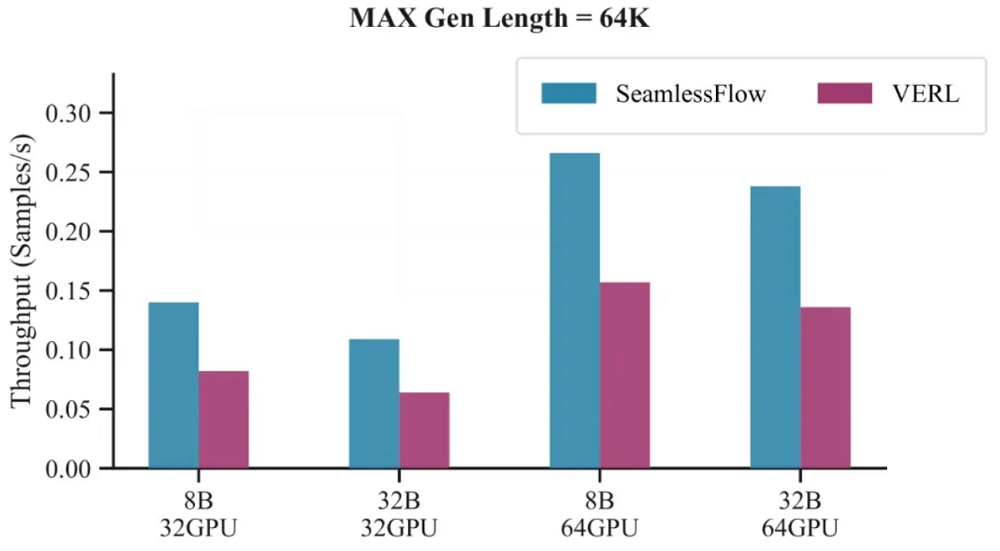
特别值得注意的是,当集群规模从32块GPU扩展到64块时,SeamlessFlow的性能优势进一步扩大,展现出了可扩展性。
结语:快手持续加码开源模型
在快手今年的多场财报电话会议中,AI已经成为了绕不开的话题。过去数月内,除了不断更新视频生成模型可灵之外,快手还开源了多款覆盖推理、编程、Embedding等领域的模型,并打造了能根据问题难度自动切换思考模式的KAT-V1自动思考(AutoThink)大模型。
Kwaipilot团队透露,除了算法与架构优化,Kwaipilot还在构建一套大规模数据环境管理系统,彻底解耦训练数据、训练沙盒与训练框架。这样的模块化设计,有望实现数据源的独立扩展、沙盒环境的安全隔离和训练框架的灵活切换。未来,这一团队或将交付更多值得期待的项目。
