








机器人前瞻(公众号:robot_pro)
作者 | 江宇
编辑 | 漠影
机器人前瞻12月2日报道,今日,字节跳动Seed具身智能团队发布最新成果强化训练模型GR-RL,首次在真机条件下完成“整只鞋连续穿鞋带”任务,并在这一精细操控场景中将成功率从45.7%提升至83.3%,减少了近70%的失败情况。

▲ByteMini-v2完成“穿鞋带”任务
与此前主要依靠模仿学习的路线不同,该成果采用了真机强化学习(Real-world Reinforcement Learning)的方式,通过多阶段训练框架提升机器人在长程任务中的稳定表现。

值得注意的是,今年7月22日,Seed团队曾发布了通用机器人模型GR-3及双臂移动机器人ByteMini,展示了其在泛化、新环境适应及柔性物体操作方面的能力。
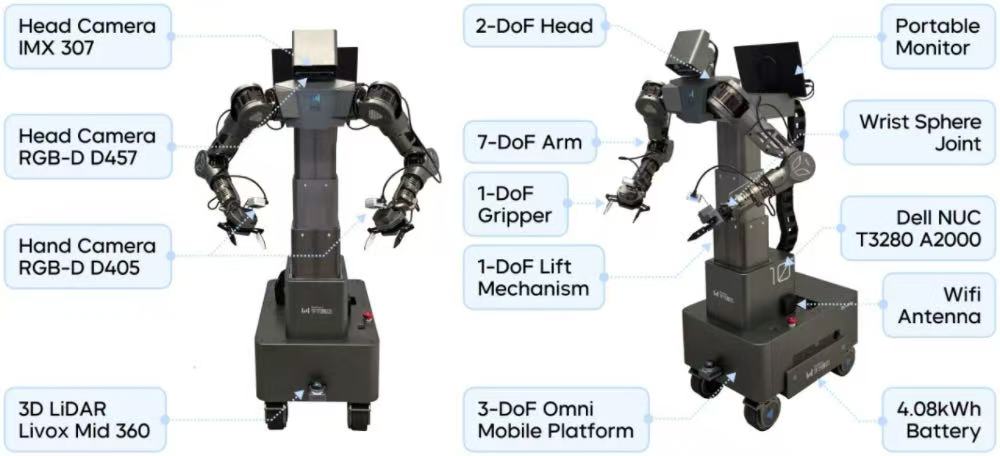
本次研究则在长时程精细灵巧操作方向进一步推进,新一代双臂轮式机器人ByteMini-v2也同步亮相。

▲上为ByteMini,下为ByteMini-v2
论文链接:https://arxiv.org/abs/2512.01801
项目主页:https://seed.bytedance.com/gr_rl
一、从“看得懂”到“做得准”,穿鞋带是通用模型失效的典型场景
Seed团队将穿鞋带设为验证任务,是因为它集中体现了真实环境中的三类难点:柔性物体的不确定性、毫米级的穿孔精度、以及多步骤连续执行的稳定性。
鞋带会随牵引和摩擦即时改变状态,孔径较小,对抓取角度要求严格,机器人需要在持续的视觉反馈中调整动作。而整个过程可能持续数分钟,每一次滑落、偏移或姿态变化,都可能影响后续动作。
Seed团队发现,基于模仿学习、具有较强泛化能力的通用模型GR-3在这一任务上的表现也不稳定,他们将这种情况归因于模仿学习的结构性限制。
一是人类演示数据存在“次优片段”,人类演示包含放慢、犹豫、尝试与回退等片段,模型在学习过程中会一并吸收,从而产生“动作保守”“执行停顿”等行为;
二是训练与推理存在“执行错位”,训练阶段学到的是预测动作,而部署时执行的动作经过推理平滑、轨迹整形等处理,这种训练与执行之间的偏移,在毫米级任务中会被放大。
这将导致:模型即使“理解”人类动作,而是在关键节点上缺乏连续性与决断性,难以把任务高效完成。
二、GR-RL的核心思路:从筛掉“坏动作”开始,再让机器人自己积累经验
GR-RL并非简单增加数据量或延长训练时间,而是在结构上引入了一个额外的判别器网络(Critic Transformer),用于判断每一个动作片段的价值,对动作序列中每个时刻的动作都进行一次打分。
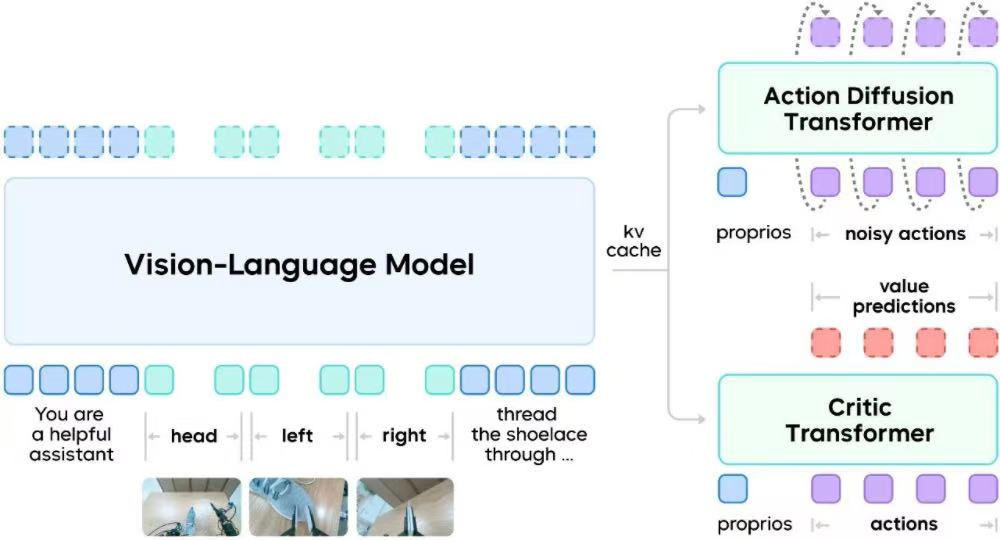
▲GR-RL的模型架构
Seed团队在离线数据中标记出“演示重新开始”的关键帧,将其之前的片段视为负样本,用于补足失败数据来源。这样做的目的,是让模型在监督学习前先学会辨别哪些行为在后续执行中会导致失败。
在此基础上,Seed团队使用时序差分方法训练评估网络,以动作后果作为回报信号,过滤掉质量较低的轨迹片段,保留较稳定的演示数据作为基础策略。
▲评估模型评判采集轨迹片段的好坏
由于穿鞋带涉及空间关系和左右协同动作,Seed团队对图像、机器人状态及动作轨迹进行镜像增强,使模型在双臂协作中获得对称性理解,从而减少对单一演示路径的依赖。
GR-RL训练的第二阶段发生在真实机器人上。Seed团队采用导向强化学习方法,通过调整模型生成动作的隐空间噪声,使其在实际探索中逐渐靠近更高回报的策略,而不是在关节层面随机扰动。
▲ByteMini-v2机器人
为了防止模型“遗忘先前策略”或短期偏移,他们引入“双缓冲池”策略,将历史轨迹与最新轨迹分开存储,训练时按固定比例抽取,保证探索与稳定并行。
这种训练方式的核心是在“允许模型犯错”的前提下,让它逐步形成适应真实环境的动作序列。
三、ByteMini-v2真机完成验证,成功率阶梯式提升
GR-RL的验证是在双臂轮式机器人ByteMini-v2上完成的。与初代相比,该机型保留了多自由度结构,并通过球形腕部关节获得更灵活的局部动作空间,适合在狭窄区域完成旋转与穿孔操作。
实验使用稀疏奖励策略,即任务完全完成才计分,其余情况均为0。这一设定避免了模型对局部中间状态的过度依赖,也提高了对整体策略的约束。
实验中,基线模型GR-3的成功率为45.7%。在离线数据过滤后,成功率提升至61.6%,加入镜像增强后达到72.7%。
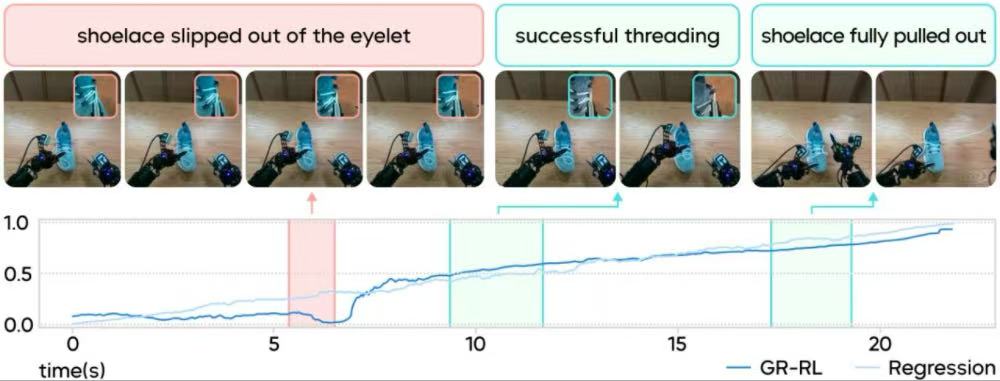
在此基础上进行约150条真机探索后,最终成功率提升至83.3%。这种结果呈现出明显的“阶梯式”变化,与训练流程中每一阶段的作用对应。
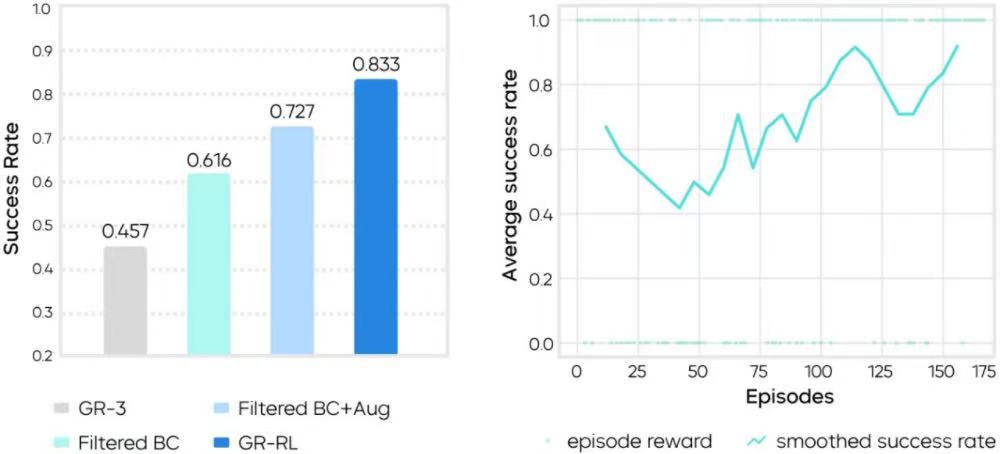
▲左图:多阶段训练实现阶梯式成功率提升;右图:在线强化学习的成功率变化曲线
在多轮实验中,Seed团队还观察到任务执行过程中的行为变化。当鞋带在穿孔过程中滑落时,模型会重新进行抓取或调整角度。当初始摆放夹带阻碍时,模型会改变状态再继续执行任务。



▲面对失误情况能自发重试,摆放位置别扭时会主动调整。
这些行为并非额外编码,而是强化阶段逐渐形成的策略表现。它们呈现为一种连续执行能力,而非记忆某一条“正确答案”。
结语:从实验室到人类家庭,精细操作依然是具身智能的“门槛”
在数据驱动和模型扩大的推动下,具身智能已经能完成越来越多看得懂、能上手的任务。
但当机器人离开实验室,走进真实家庭,面对穿鞋带这种看似普通、却涉及柔性物体、连续动作和高精度控制的任务时,通用模型的能力边界就会暴露出来。
机器人不仅要看得清,还要在不断的反馈中稳定执行任务,这一环节目前仍是最难被可靠解决的部分。
