








智东西(公众号:zhidxcom)
编译 | 王欣逸
编辑 | 程茜
智东西12月19日消息,12月11日,苹果发表论文介绍了3D生成模型SHARP,宣称在标准GPU上,该模型能够以不到1秒的时间将单张图像重建为逼真的3D场景。目前,该模型已开源。
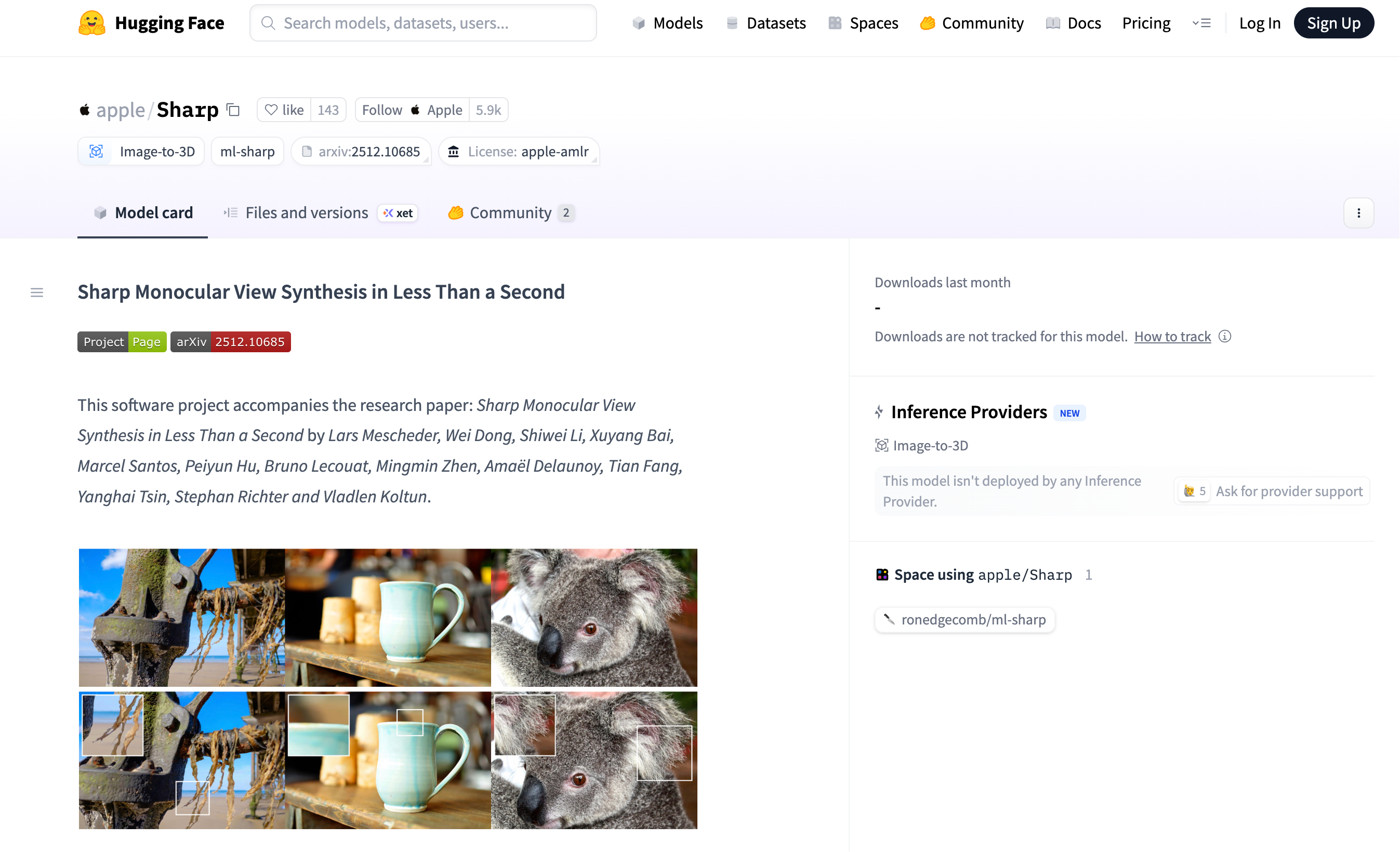
用户仅需输入一张普通照片,该模型即可通过神经网络一次性预测出整个场景的3D高斯表示参数,整个生成过程在标准GPU上完成仅需不足一秒,随后还能实时渲染出高分辨率、照片级真实感的相邻视角图像。此外,SHARP生成的3D场景具有绝对尺度的度量特性,能够支持精确的相机位移操作。
定量评估显示,SHARP在不同数据集上展现出强大的零样本泛化能力,在多个数据集上实现了新的技术突破,与现有最佳模型相比,LPIPS指标(感知相似性)降低了25-34%,DISTS指标(结构相似性)降低了21-43%,还将合成时间缩短了三个数量级,并支持以每秒100帧高分辨率渲染邻近视图的3D表征。
不少开发者对该模型进行了体验。其中,有网友将其置于Vision Pro内使用,仅需单张图片就实现了身临其境的效果,生成画面的精细度也比较高。

还有网友上传了一张油画,该模型最终生成了一个位置关系准确、画面完整的3D场景。

其他网友评价称,该模型无法生成场景中不可见的部分,不过它的最大优势在于生成速度,“MacBook Pro 只需几秒钟(就能完成生成)……”。
该模型的详细信息已发布在arXiv上,题为《SHARP:不到一秒的单图像视角合成(Sharp Monocular View Synthesis in Less Than a Second)》。

论文地址:https://arxiv.org/abs/2512.10685
开源地址:
GitHub:https://github.com/apple/ml-sharp
Hugging Face:https://huggingface.co/apple/Sharp
一、保真度提高约20%-40%,合成时间缩短三个数量级
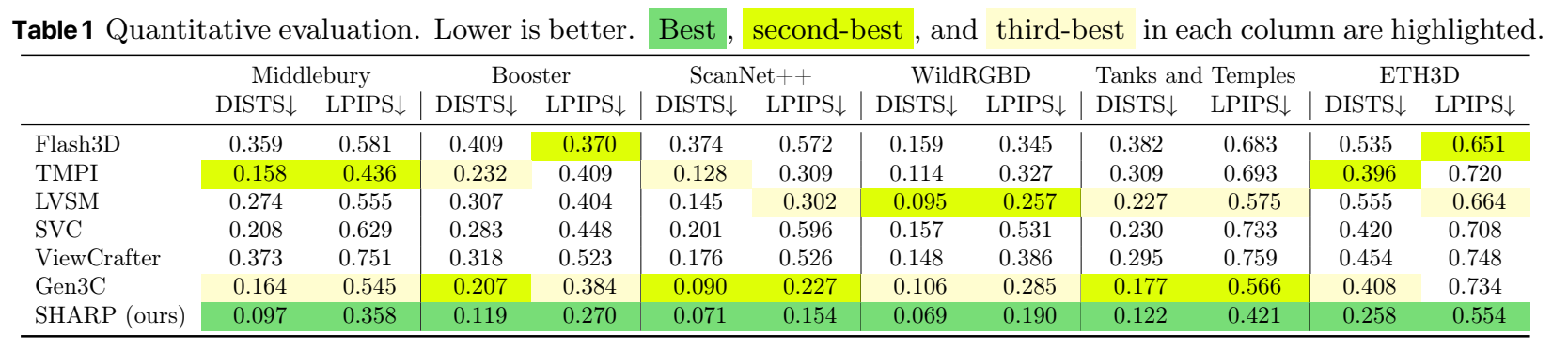
研究人员用多个数据集对SHARP模型进行评估,主要关注模型的两个指标:LPIPS和DISTS,以考察模型的合成图像与真实图像之间的结构相似性,符合人主观感受的程度。这两个数据越小,性能越优。
在基线模型上,研究人员选取了一些现有的前沿模型,分别为:基于3D高斯分布的Flash 3D模型;使用多平面图像的TMPI模型;基于图像回归的LVSM模型;采用扩散模型的稳定虚拟相机(SVC)、ViewCrafter和Gen3C。
定量评估显示,SHARP在所有数据集中的表现均为最佳,打败所有模型。相较现有最佳模型,SHARP的LPIPS指标降低了25-34%,DISTS指标降低了21-43%。
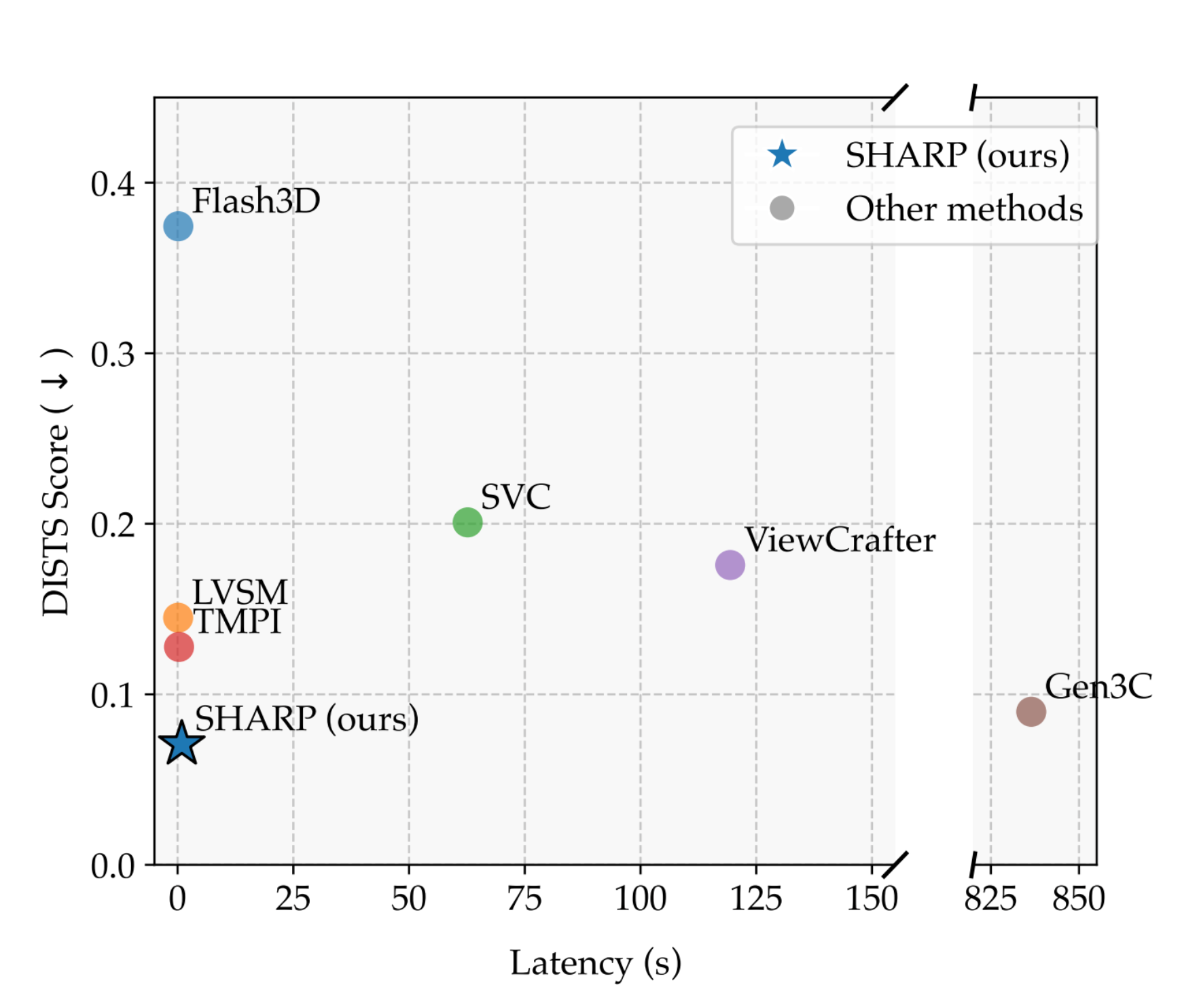
研究人员对该模型的单图像合成任务性能进行了评估,结果显示,在单个GPU上,SHARP在保持高图像保真度的同时,合成时间也位列第一梯队。相较于同等质量的模型,SHARP模型的合成时间缩短了三个数量级,这体现了其在效率和效果上的优势。
在不到1秒的时间里,该模型不仅能生成3D内容,还能以每秒100帧以上的速度渲染高分辨率的局部视图。从结果来看,SHARP细节处理清晰,结构精细,第一张图的主体和背景分离处理得很干净,第二张图颜色和形状稳定性比较出色,第三张图动物的毛发根根分明。

二、能实时渲染、预测高分辨3D表征,无法生成不可见部分
视角合成研究经历了从早期基于多图像几何建模的经典方法,到深度学习时代以神经辐射场为代表的隐式表示突破,再到近年来显式高效渲染技术(如3D高斯泼溅)的发展历程。
此前,大多数高斯泼溅方法需要从不同视角拍摄同一场景的数十甚至数百张图像,SHARP模型则专注于单张图片的3D场景生成,它仅通过神经网络的一次前向传播,就能从单张照片预测出完整的3D高斯场景表征。
SHARP模型的训练过程包括合成数据训练和自监督微调两个阶段:在第一阶段,研究人员使用具有完美图像和深度真实标签的合成数据对模型进行训练,学习3D重建的基本原理。在第二阶段,研究人员让该模型在没有视差合成真实标签的真实图像上进行自监督微调,通过生成伪真实标签来适应真实图像,提高模型在真实世界图像上的性能。
研究团队对SHARP模型做出了三点创新:第一点是一种可进行端到端训练的架构,这一架构可预测高分辨率3D表征;第二是推出了鲁棒高效的损失函数配置,研究人员精心选取了一系列损失函数,在保障训练稳定性、抑制常见视觉伪影的同时,将视角合成质量作为优化重点;第三是引入一个简洁的深度对齐模块,这一模块能够有效解决训练过程中的深度歧义问题。
SHARP模型包含四个可学习模块:一个用于特征提取的预训练编码器、一个生成两个独立深度层的深度解码器、一个深度调整模块以及一个优化所有高斯属性的高斯解码器。可微分高斯初始化器和组合器为最终的3D表示组装高斯元素,预测出的高斯被渲染至输入视图和新颖视图,以进行损失计算。
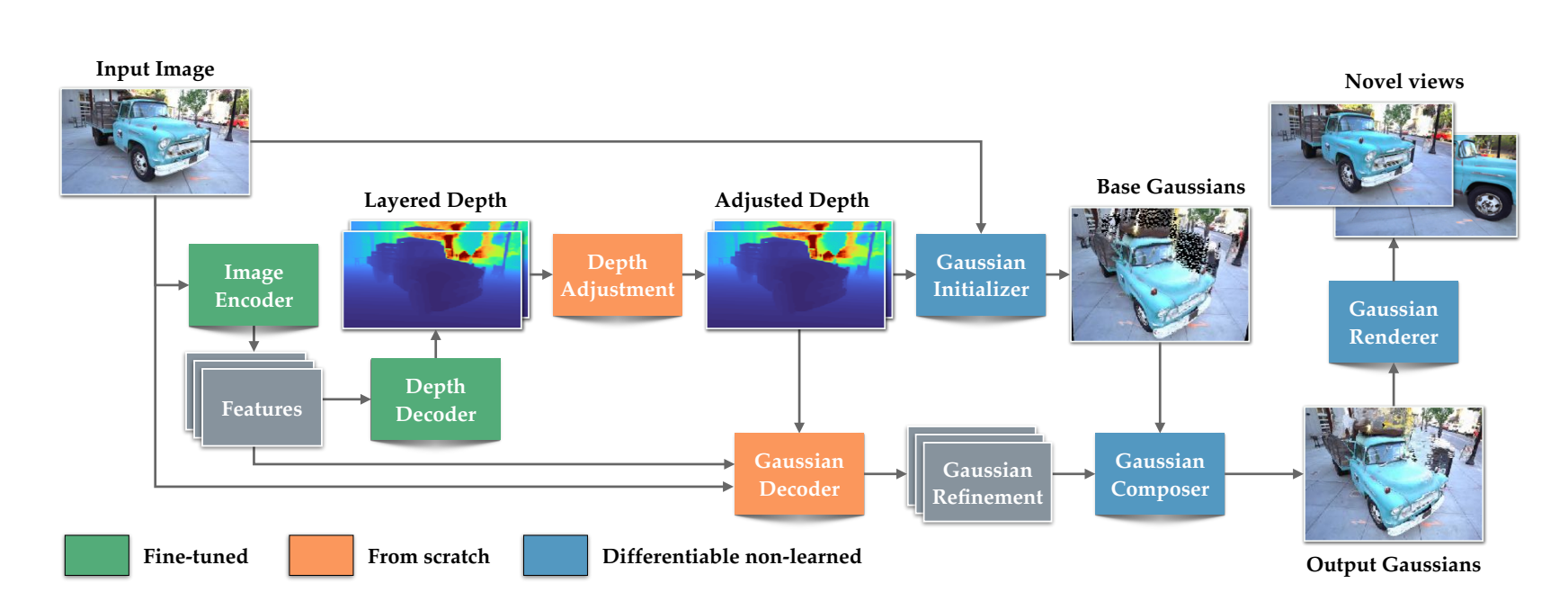
在优化和评估过程中,SHARP模型使用了多种损失函数来优化合成视图的质量,包括渲染损失、深度损失和正则化损失等。通过这些损失函数的组合,模型能够生成高质量的3D表示,并支持实时渲染。
基于以上技术,SHARP模型实现了无需依赖多张图像或耗时的逐场景优化过程,即可重建出可信的3D场景。不过该方法存在一定的权衡:SHARP能精确渲染邻近视角,但无法合成场景中完全不可见的部分。这意味着用户不能过度偏离原照片的拍摄机位。
结语:3D场景生成门槛再降
SHARP模型在单图像视点合成领域取得了显著进展,该模型在单次前向传播的同时,完成了从2D图片理解、3D几何重建到细节优化的全过程,最终输出一个能实时渲染的3D场景模型。
在应用上,通过实时渲染高保真的3D场景,SHARP模型或将为VR/AR应用提供更加沉浸式的体验,为游戏、电影、建筑等行业提供更多可能性。研究团队称,他们还将拓展现有方法论,通过结合扩散模型等方法,支持更远距离视点的合成。
