








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
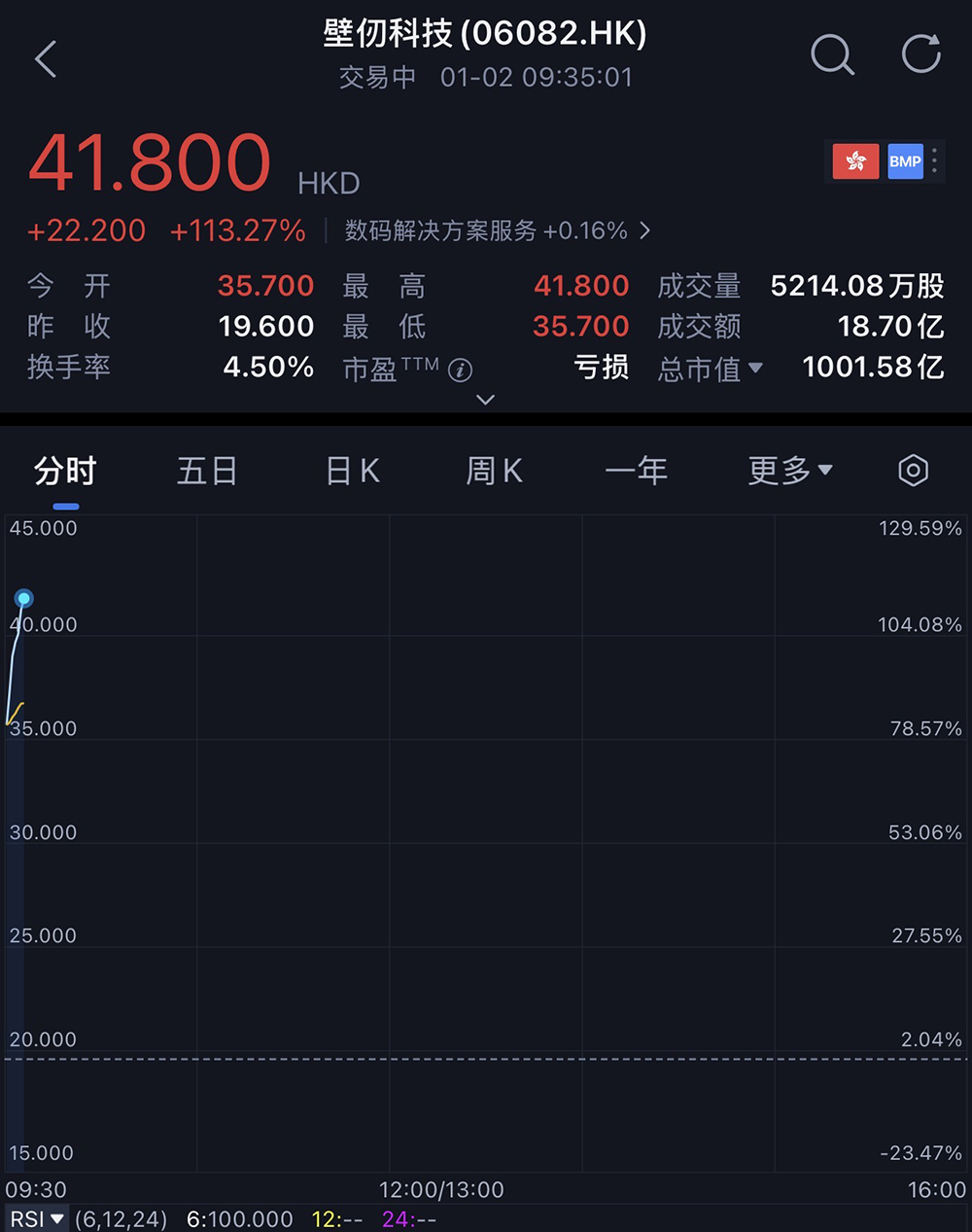
芯东西1月2日报道,刚刚,上海GPU龙头企业壁仞科技在港交所挂牌上市,成为港股“国产GPU第一股”,也是2026年港股市场首只上市新股。
其发行价为每股19.60港元(约合人民币17.60元),开盘价上涨82.14%至每股35.70港元(约合人民币32.05元),市值为855.42亿港元(约合人民币768亿元)。
截至9点35分,壁仞科技股价为每股41.80港元(约合人民币37.52元),最新市值为1002亿港元(约合人民币899亿元)。
这家创立于2019年的国产AI芯片代表公司,在2022年收入为49.9万元,2024年增至3.37亿元,年复合增长率达2500%。截至2025年12月15日,其在手销售订单约12.41亿元,将转化为未来收入。
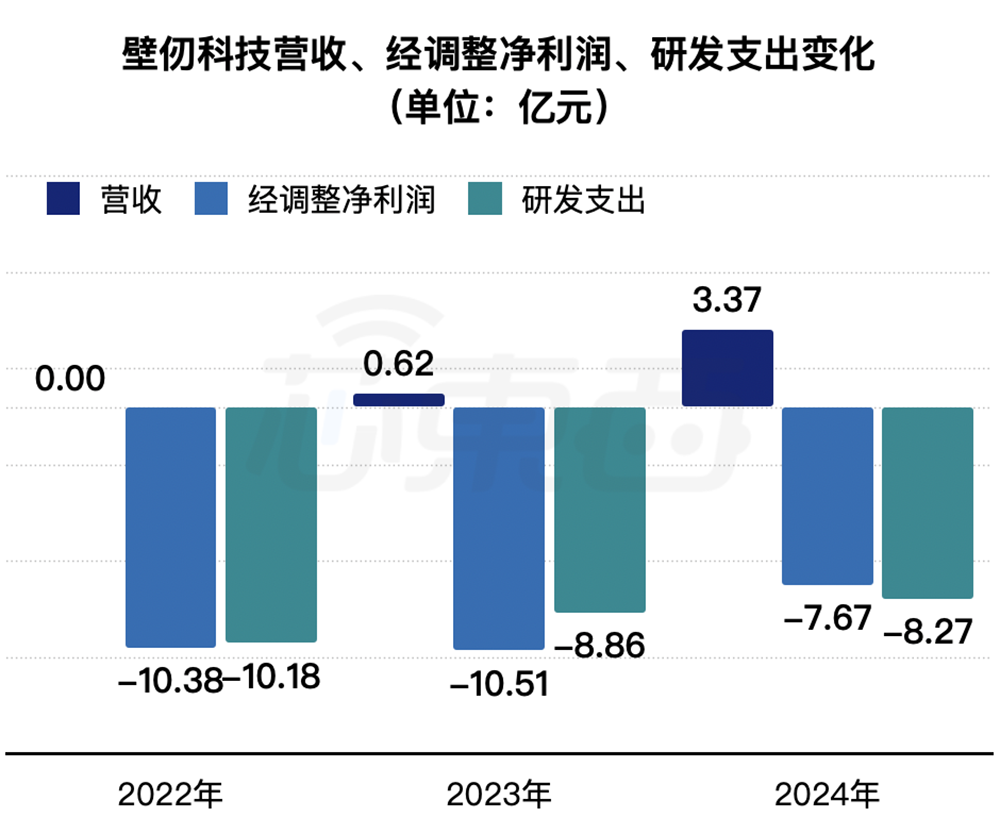
▲2022年~2024年壁仞科技营收、经调整净利润、研发支出变化(芯东西制图)
这些数字对应的,是一家中国AI芯片公司持续投入、持续交付、持续增收的状态。
在国内AI芯片赛道,壁仞科技取得了许多技术实绩:是中国首家采用2.5D芯粒(Chiplet)技术封装双AI计算裸晶的公司,在业内率先支持先进互连规范,产品支持DeepSeek、Qwen、Llama等主流开源大模型,在万亿参数大语言模型和多模态模型训练及推理等重点场景下展现了技术成熟度。
其代表性投资方,有上海国投先导基金、上海人工智能产业投资基金、广州产投、知识城集团等国资平台,启明创投、华登、高瓴创投等创新科技及半导体投资基金,以及平安集团、珠海格力等产业投资方。
基于自研GPGPU架构,壁仞科技完成了从芯片设计、软件平台到系统级交付的闭环,正在跑通一条可持续的自主高端算力路线。
一、研发占比高达83%,发明专利申请数为中国GPGPU公司第一
在GPU行业,高研发占比并不少见。
壁仞科技的一个财报亮点是“三高”:研发人员比例高达83%,研发费用占比超过70%,发明专利申请数量在国内GPGPU公司中排名第一。
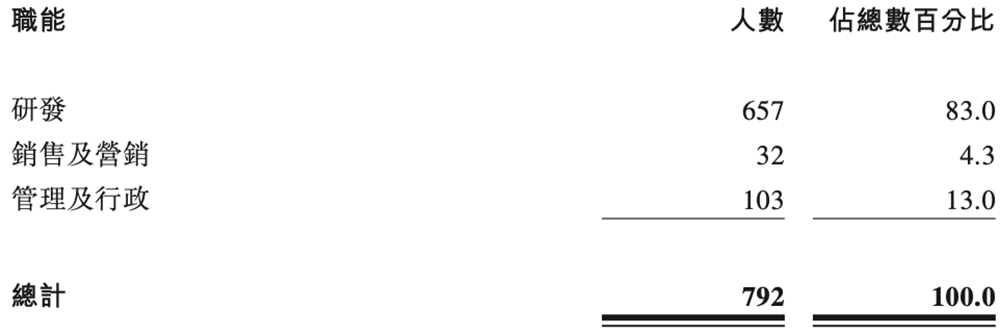
截至2025年12月15日,壁仞科技在全球多个国家和地区累计申请专利1500余项,位列中国GPGPU公司第一;获得专利授权600余项,位列中国GPGPU公司前列;发明专利授权率达100%,位列国内企业发明专利授权率榜首。
这为其长期发展垒起了一面坚固的专利墙。
相比ASIC、FPGA等路线,GPGPU具有更高的通用性和灵活性,占据AI芯片主流市场。

为了提升AI计算速度,GPGPU引入了专门硬件单元,并持续升级内存大小、带宽、互连、通用灵活性及能效。
壁仞科技则是中国首批在商业化产品中使用PCIe 5.0、CXL、高性能DRAM、双裸晶芯粒(Chiplet)等设计的GPGPU公司之一,同时亦专注于3D堆叠技术、CPO(共封装光学)等先进技术的研发,以增强AI计算系统性能及可扩展性,降低大模型训练及部署成本。
该公司是首家也是唯一一家受邀在国际顶级芯片设计会议Hot Chips上发言的中国GPGPU公司,并且是中国最早实现千卡集群商用的GPGPU公司之一、中国首家在单一服务器中实现8块GPU卡点对点全网状拓扑的GPGPU公司,还两度摘得世界人工智能大会最高荣誉SAIL奖(卓越人工智能引领者奖)。
在MLPerf Inference 2.1的封闭组别竞赛中语言处理模型BERT及图像分类模型ResNet50成绩方面,壁仞科技GPGPU芯片及搭载该芯片的服务器均获得量产芯片组别中的第一名。
壁仞科技CTO洪洲负责监督及制定产品技术发展方向,亦是壁仞科技GPGPU芯片的首席架构师。
他在GPGPU的设计及工程方案有近30年经验,拥有北京大学理学学士学位、清华大学工程学硕士学位、美国纽约州立大学水牛城分校理学硕士学位,曾担任S3工程总监、英伟达主架构师、S3 Graphics硬件架构副总裁、华为美国研究中心Futurewei Technologies首席架构师。
壁仞科技COO张凌岚负责壁仞科技产品的项目管理及生产与质量控制。
他在半导体行业拥有超过23年经验,拥有浙江大学电气工程学士学位、美国南加州大学电机工程硕士学位、美国加州大学伯克利分校工商管理硕士学位,曾担任AMD GPU SoC架构师、三星电子美国研发中心高级研发经理、Higon Austin R&D Center Corporation深度运算副总裁。
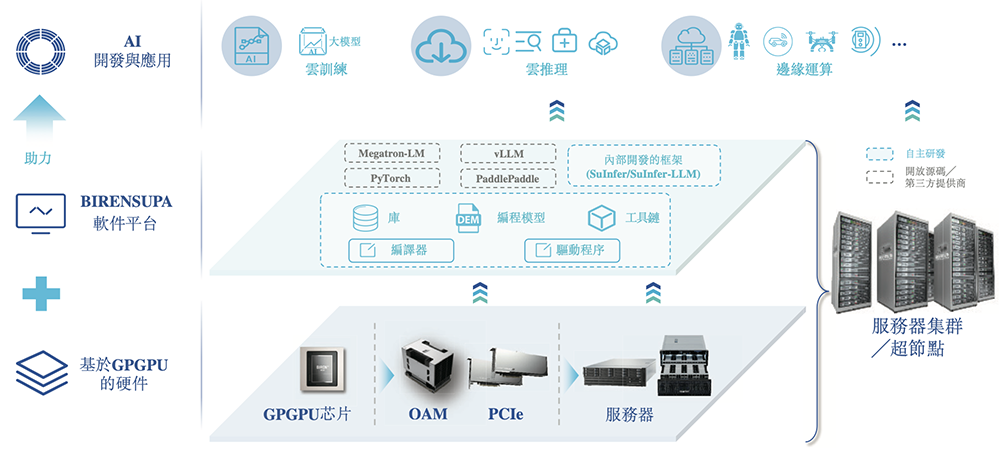
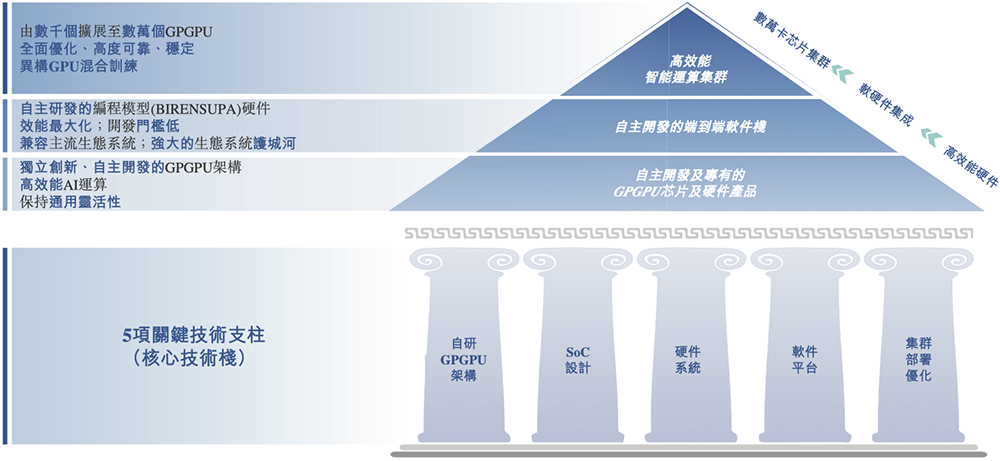
在他们的带领下,壁仞科技持续完善其智能计算整体解决方案的五大支柱:自研GPGPU架构、SoC设计、硬件系统、软件平台、集群部署优化。
二、自研GPGPU架构引入多项创新,下一代芯片将支持FP8、FP4精度
从架构、封装到系统设计,壁仞科技的技术选择始终围绕一个前提展开:
在既定工艺条件下,算力还能如何继续放大?
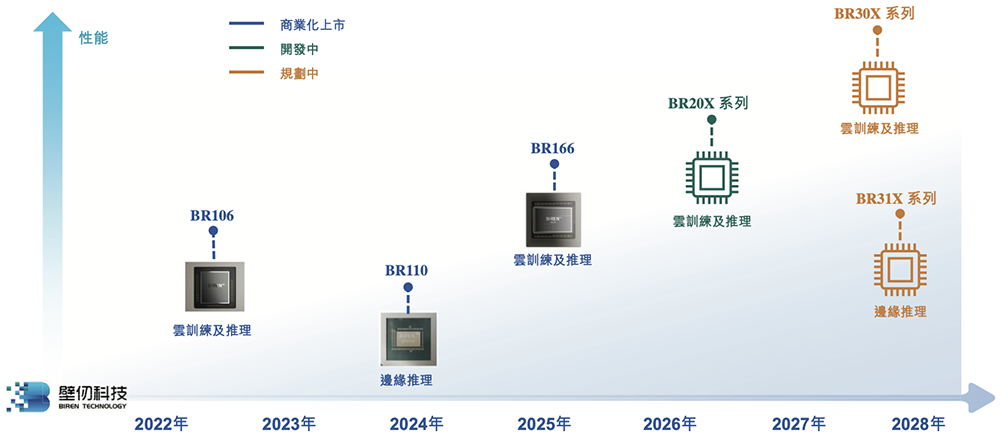
自2019年启动第一代GPGPU架构研发以来,壁仞科技已推出BR106、BR166、BR110等多款芯片,覆盖云端训练、云端推理、边缘推理场景。
后续,BR20X系列计划在2026年商业化上市,将增强对FP8、FP4等数据格式的支持;BR30X和BR31X系列计划在2028年商业化上市。
这些均基于壁仞科技自主研发的统一GPGPU架构。
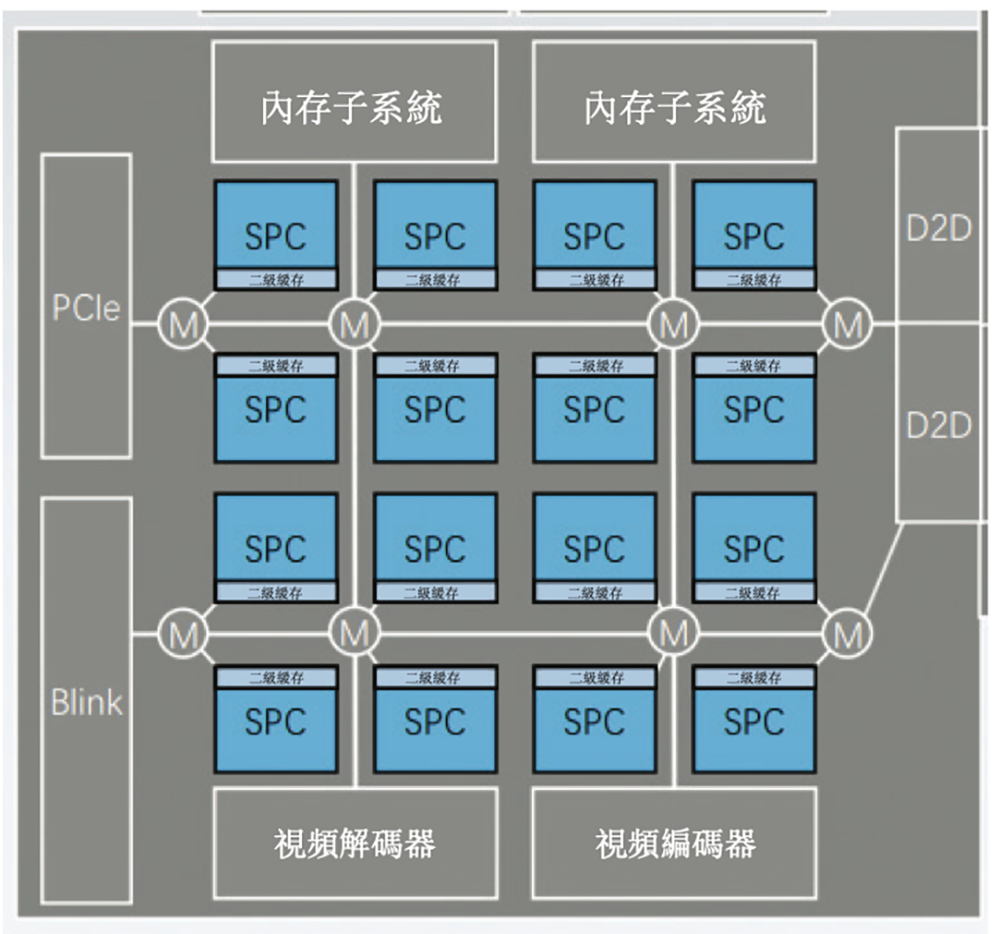
▲壁仞科技GPGPU架构设计
在制程条件受限的情况下,壁仞科技选择通过“双裸晶 + 2.5D封装”来扩展算力规模,探索出一条持续提升单卡性能的可行之路。
例如,通过共封装2个BR106芯片裸晶和4个DRAM,壁仞科技利用芯粒技术和裸晶间互连技术,推出性能更高的BR166芯片产品,其性能达到BR106的2倍,两颗裸晶之间的D2D双向带宽达896GB/s。
壁仞科技在GPGPU架构里加入了很多创新:
(1)通用灵活性及AI加速性均表现出色:使用经典的单指令多线程(SIMT)架构,高效处理复杂的并行计算。
(2)先进的张量核架构:专用张量引擎T-core采用特殊设计,可大幅降低矩阵运算过程中从DRAM中重复检索数据的频率,支持数据循环,降低AI矩阵计算的带宽需求,从而大大提高能效及计算效率。
(3)带组播的异步数据传输:组播技术允许从DRAM读取一次数据,然后同时将其提供给不同的计算内核,可显著提高大型矩阵计算速度,同时降低能耗。
(4)近内存计算:芯片融合了NUMA、UMA、L2 Reduction等存储技术,能将数据自动靠近计算核心存储,并通过L2实现归约计算,减少从远程DRAM获取数据的需要,从而提高数据检索效率。
这些设计使其架构能适应不断扩展的模型规模、参数量与复杂度,提供高性能、通用灵活性、能效与可扩展性,最终帮助客户降低总拥有成本(TCO)。
三、不仅拼高性能,还要拼稳定多元交付
要让芯片运行成功,离不开一套完备的SoC设计方法论。
壁仞科技在SoC架构、内存系统、多GPU互连、SoC测试、SoC设计流程及芯片封装设计方面均有技术积累,亦是业内支持先进互连规格的领先者,目标指向量产稳定性和持续交付能力。
例如,壁仞科技SoC架构可根据芯片的AI应用场景及目标细分市场,灵活配置不同数量具备各类异构计算模块的SPC核,并据此界定内存系统及互连结构;内存系统能提高AI应用程序的有效带宽访问,并减少内存访问的延迟;多级分区技术和模块复用技术在布局和布线方面简化了复杂模块的物理设计,提高了芯片设计的规模。
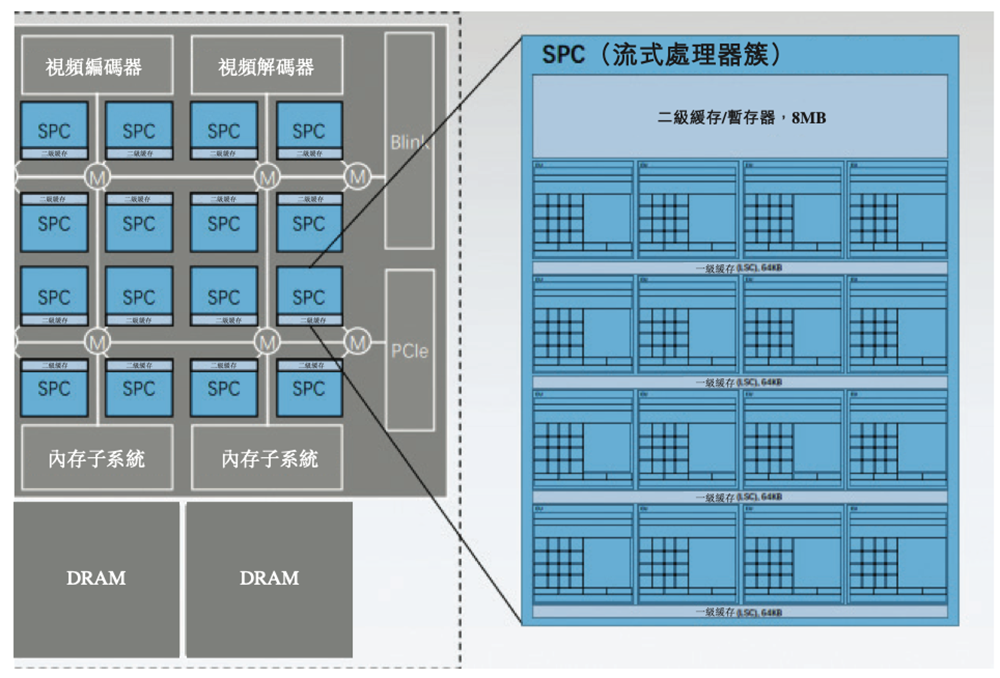
▲壁仞科技SPC结构图
在互连方面,自研BLink技术可实现GPU卡之间的连接,最大双向数据传输速率高达每通道64GB/s,共4至8条通道;率先在中国推出商用GPU光互连技术,推动全光网络及共封装光学技术发展。
面向交付,壁仞科技提供PCIe(外围组件高速互连)板卡、OAM(开放式加速器模组)、服务器等多种产品形态,是中国首批成功开发、原型验证及量产高性能OAM及通用底板的GPGPU公司之一。

PCIe适合需要平衡性能和成本的客户,OAM适用于需要最高性能的客户,服务器则是即用型算力。服务器可互连为超节点,并进一步扩展为服务器集群。
其下一代产品会升级到700W风冷和1000W液冷,UBB可使用内部P2P接口连接8张具有多种拓扑的OAM卡,还将设计更灵活、更强大的SerDes连接,以纵向扩展系统。
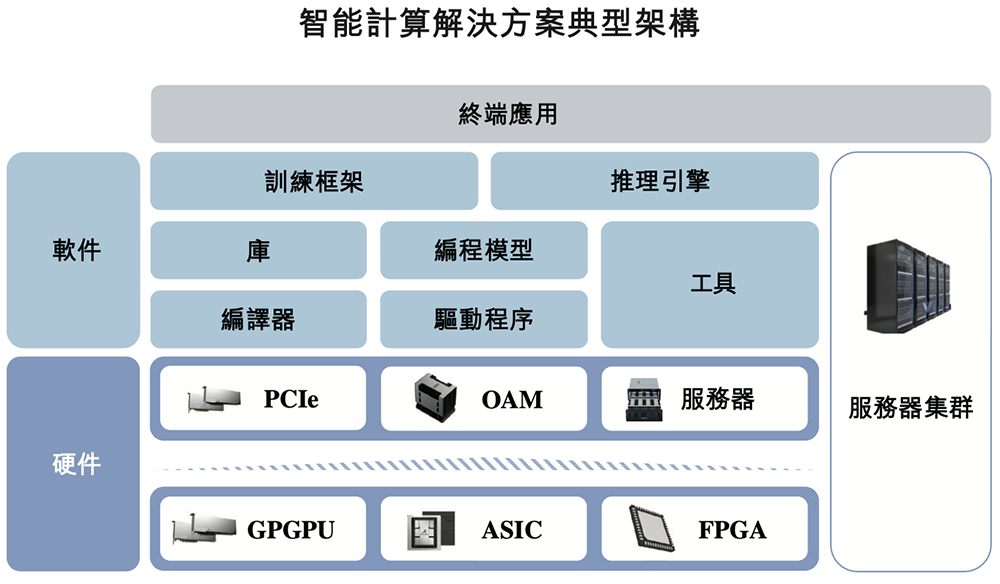
数据中心GPU最终落地拼得不是单卡性能,而是为集群扩展性设计,这也是芯片公司能否跨越商业化拐点的关键。
壁仞科技通过将自有的硬件系统及软件平台与合作伙伴提供的服务器、存储及网络设备等其他硬件基础设施相集成,开发了大规模智能计算集群的全面解决方案。
四、为开发者兜底,软件和集群才是真正的壁垒
算力系统的稳定性,在实际落地中会被放大。对于一家GPU企业,自研软件平台既是充分发挥计算及通信能力的关键,又是扩大生态城池的基础。
壁仞科技选择的软件路径,是兼顾降低迁移成本与保留自主演进空间。
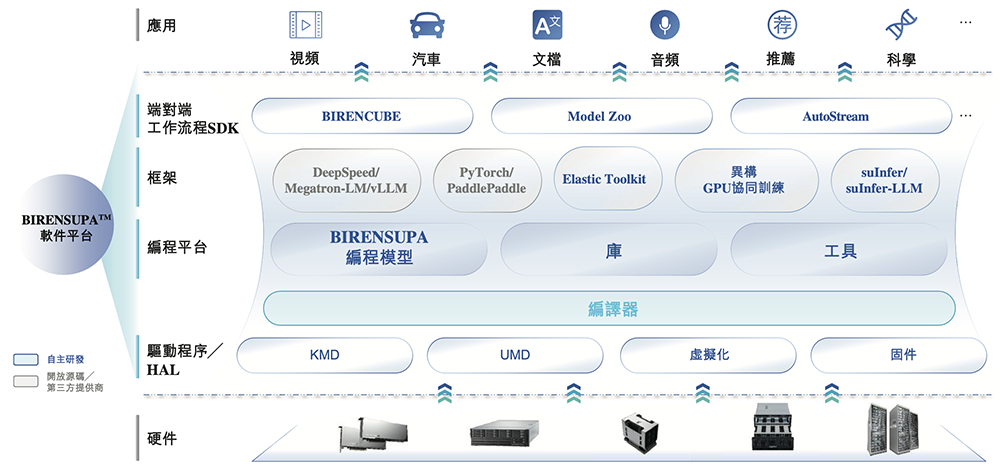
其自研计算软件平台BIRENSUPA提供编程接口、算法库、训练与推理框架及完整工具链,并兼容第三方GPGPU计算软件平台,使迁移至壁仞科技GPGPU产品的成本显著降低。
BIRENSUPA编程模型兼容业界主流GPGPU编程模型,自研GPGPU编译器通过将高级代码转换为壁仞科技专有指令集来优化资源利用率并提高效率,还有一系列自研库,可加速不同应用领域。
在模型层面,壁仞科技对DeepSeek、Qwen、Llama等主流开源模型进行原生优化,可简化AI解决方案的开发与部署流程。其Model Zoo托管针对BIRENSUPA进行原生优化的AI模型,支持客户部署预训练模型或根据参考实现开发自身模型。
同时,壁仞科技正在与清华大学、复旦大学、上海交通大学、浙江大学等知名高校开展了超过30项联合项目,持续培育本土GPU开发者生态。
在集群层面,壁仞科技BIRENCUBE集群管理平台旨在管理广泛的AI硬件基础设施,将自有硬件、软件与服务器、存储和网络设备整合,形成端到端解决方案,能够帮助客户构建包含成千上万块GPGPU芯片的GPU集群系统。
其智能计算集群解决方案在可靠性及性能、通用灵活性及兼容性上领先:
- 千卡集群训练30天以上无中断,5天以上无故障;
- 业界首创三级异步检查点,提高可靠性,减少存取开销;
- 千卡集群5分钟内将千亿参数模型恢复至最后检查点,速度行业领先;
- 损失函数在多次连续训练后实现零误差,并在1个月的训练周期后持续下降;
- 支持主流大模型、性能领先、千卡集群线性加速比达到95%;
- 大模型的自动化并行优化、具有业界首创的异步卸载以克服内存瓶颈;
- 全面的模型支持,与上下游合作伙伴共同构建支持50余种大模型的生态系统;
- 开放生态,兼容三类异构软件加速平台;
- 通过直连光互连、光电路交换等多种互连方式,支持具有高扩展性及灵活拓扑结构的超节点,可更高效地运行大模型。
2024年,壁仞科技深化与战略客户的合作,赢得了商业化AIDC千卡GPU集群等里程碑项目,并将其GPGPU集群部署于5G新通话及其他应用场景,与中国三大电信运营商均建立合作伙伴关系,在大规模应用场景中持续验证其可靠性与竞争力。
截至2025年6月22日,壁仞科技已服务9家财富中国500强企业,其中有5家上榜财富世界500强,已战略性拓展AI数据中心、电信、AI解决方案、能源及公用事业、金融科技及互联网等关键行业。
结语:国产GPU走向规模化落地
与国际巨头相比,国产GPU在生态成熟度、开发者规模、软件工具链成熟度等方面存在客观差距,但随着海外GPU供给不再稳定,下游行业开始接受CUDA非唯一解,国产GPU也从可用走向可规模化。
在资本市场中,真正同时具备GPGPU架构、自研软件平台和系统级交付能力的公司并不多。壁仞科技在较早阶段就将架构、封装、软件、系统并行推进,这为其大规模集群和长期演进奠定基础。
相较于全球竞争对手,这些技术积累加上在中国的本地化专业知识及实地客户支持能力,使壁仞科技能够与重点行业的大型客户建立战略合作关系,深入理解并满足独特需求。
上市之后,市场看到的,将是这些工程选择在更长周期内的表现。
