








机器人前瞻(公众号:robot_pro)
作者 | 江宇
编辑 | 漠影
机器人前瞻1月14日报道,昨日,OpenAI投资的挪威人形机器人公司1X发布了一款全新世界模型“1X World Model(1XWM)”,用于赋予机器人通识行为能力,并提升其对物理世界的理解与推理能力。
1XWM是一种在推理阶段可通过文字和初始画面生成未来视频、再从中推理出机器人动作的世界模型,训练时借助了网页视频和少量机器人数据。
其主要应用对象为1X正在量产的人形机器人Neo,这是一款“穿着瑜伽服、表情呆萌”的陪伴型机器人,主打家庭使用场景。

1X创始人兼CEO Bernt Børnich称:“Neo如今能够将任意指令转化为新动作,即便此前从未执行过类似任务。这标志着其通往‘自我学习’能力的起点,未来几乎可以掌握人类所能想到的任何技能。”

▲1X创始人兼CEO Bernt Børnich
不过,官方也澄清称,当前模型仍需经过视频与动作的双重建模过程,尚未实现真正“零样本即执行”。
一、利用视频推理世界,1XWM跳出“图像到动作”的旧思路
不同于多数以图文输入直接预测动作的VLA(视觉语言动作)模型路线,1XWM通过“文字指导的视频生成”推理机器人应执行的动作路径。
其核心由两个部分构成:一是基于14B视频生成模型训练的主干World Model(WM),用于预测场景的未来状态;二是Inverse Dynamics Model(IDM),将视频帧序列转化为实际可执行的机器人动作轨迹。
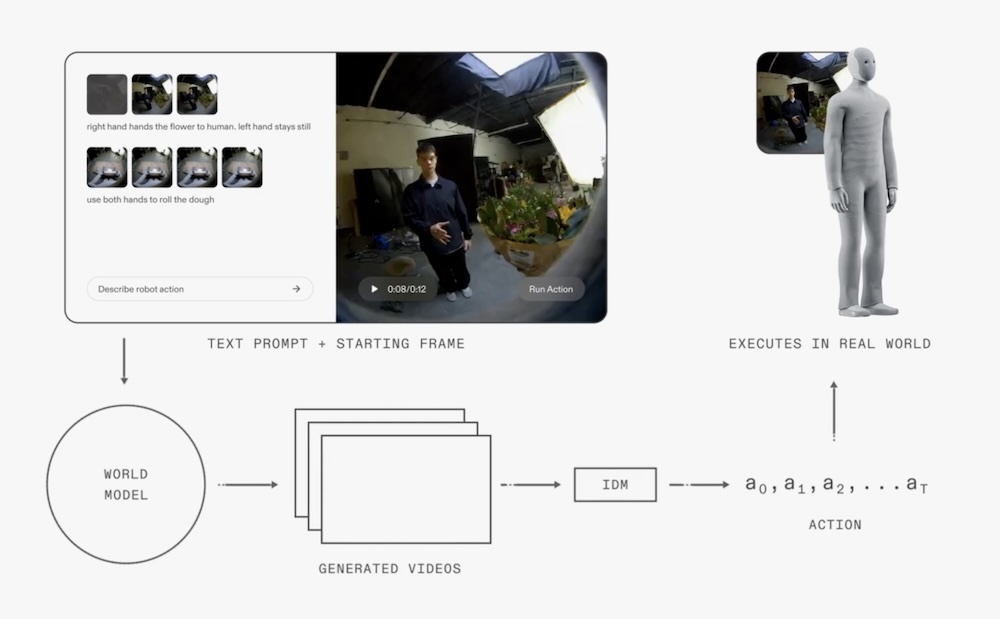
▲图源:1X World Model技术博客
这一流程可简单概括为:接收文字指令与起始视频帧,WM生成未来的视频片段,IDM提取控制动作,Neo执行任务。得益于NEO与人类动态结构的高度拟合,模型在物理互动(如摩擦、惯性、接触)等方面能实现更真实的转译。
整体架构在设计上强调了将人形结构视作模型泛化的前提。
该模型无需大规模真实机器人数据,仅通过900小时第一视角人类视频中训练出的操控直觉,结合70小时Neo特定数据进行微调,即可在视觉-空间-物理层面展现出较强泛化能力。
这一训练策略显著提升了模型对“从未见过的物体与动作”的适应力,使得Neo能完成双手配合、与人交互等未曾直接训练过的复杂任务。
二、视频质量可预估任务成功率,模型探索“自我改进飞轮”
为了量化1XWM在真实世界中的能力,1X进行了多轮测试,包括厨房、衣物处理等实际任务。

▲抽纸巾

▲摆放椅子

▲比耶
测试数据显示,该模型在大部分任务上表现稳定,尽管在如“倒牛奶”和“画笑脸”等更精细的操作中仍有挑战。
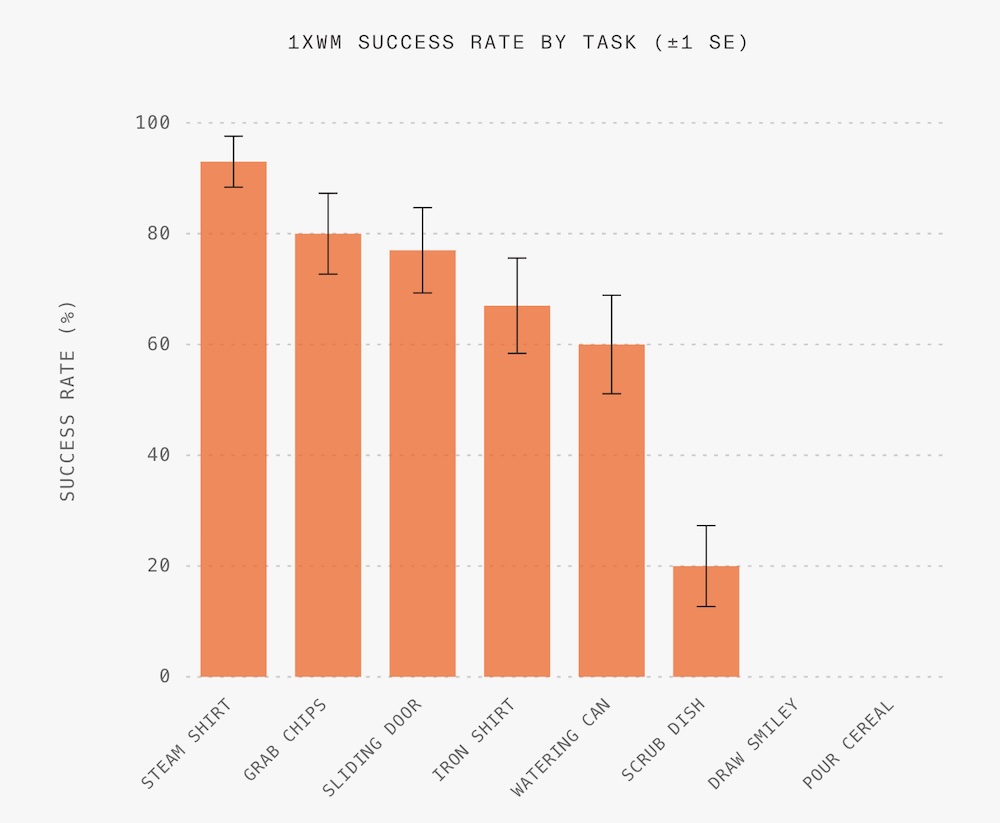
▲1XWM在不同家务任务上的成功率
研究团队还发现:生成视频的物理真实性与动作成功率呈正相关。若生成的视频动作存在物理逻辑错误(如物体漂浮、深度错位),实际机器人执行几乎为0%成功率。
基于这一观察,团队测试了“多版本生成、优选最佳”的策略,并发现将单次生成扩展为8次并挑选最优者,可显著提升任务成功率。
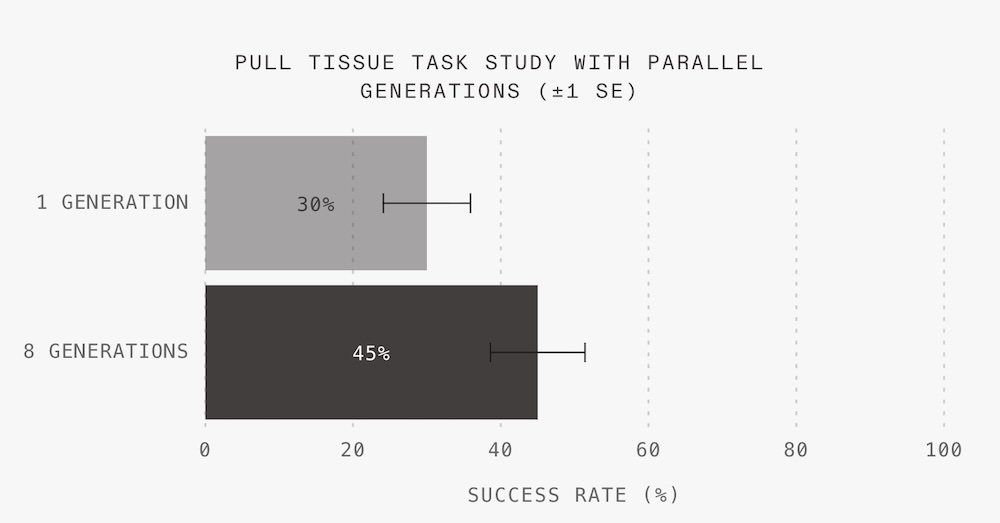
▲抽纸巾任务中,不同生成次数对执行成功率的影响(“拉纸巾”任务成功率从30%提升至45%)
在提升视频质量方面,1X团队使用了“文字说明增强”策略,即用VLM模型扩写训练视频的任务描述文字,以更好对齐视频生成模型的文字理解能力。
另一个关键是加入了第一视角人类操作视频的训练阶段,这一做法显著提升了模型在新任务和新环境上的泛化质量。

▲洗碗
1XWM当前每轮推理需约11秒,能生成5秒真实世界可执行的动作视频,并已与Verda团队合作优化GPU推理。
下一步,1X计划加速模型响应速度,并探索长时任务的闭环重规划机制,逐步迈向机器人“通识行动力”与“自我提升闭环”的目标。
1X团队称,1XWM已经具备“由机器人自身经验驱动探索、评估与策略优化”的机制,只需保持任务覆盖的非零成功率,就有望持续推进性能提升与任务泛化,进入真正意义上的“自我改进飞轮”。
结语:生成视频,推理动作,再到执行
1XWM尚未实现真正意义上的“零样本即执行”,但它提供了一种新思路:机器人不再直接从数据中学动作,而是先生成一段对未来的“视频想象”,再从中推理出可执行的动作路径。
在这种架构下,视频成为连接任务场景、推理与行动的中间环节。当模型能够基于当前场景主动生成对未来的预测,并据此推理出下一步动作时,具身智能或许正迈向更高层次的泛化能力。
