










智东西(公众号:zhidxcom)
作者 | 王涵
编辑 | 心缘
智东西2月3日报道,近期,英伟达宣布其全新3D通用模型论文将发表于2026国际3D视觉会议,论文的预印本已于去年7月发表。这篇论文构建出了一种建构3D世界的新范式,验证了“AI生成的3D合成数据”可规模化替代人工标注数据,能够大幅降低视觉模型预训练的成本。
论文的主要成果为3D-GENERALIST模型,该模型使用统一化框架,将3D环境生成的四大核心要素即布局、材质、光照、资产等统一到序贯决策框架中。研究团队还提出了基于CLIP评分的自改进微调策略,可以让模型在下一轮生成中能自主修正前序错误。
这篇论文的作者有8位华人,第一二作者都是中国留学生,清华“姚班”出身的斯坦福大学助理教授吴佳俊也名列其中。
CES 2025上,英伟达正式推出世界基础模型平台Cosmos。在CES 2026的演讲中,黄仁勋依旧将“Physical AI”作为了整场发布的核心灵魂,正式将Cosmos定位为Physical AI的“底层代码”与“世界模拟器”。此外,黄仁勋还发布了Cosmos Reason 2,让AI不仅生成世界,还能用自然语言进行链式因果推理。
3D-GENERALIST这一技术会给英伟达的Cosmos补全哪块拼图?又是如何实现技术突破的?我们试图从论文中寻找答案。
论文链接:https://arxiv.org/abs/2507.06484
一、现有痛点:只是在生成3D图像,杯子水杯不能独立交互
当前可交互3D环境的创建仍面临诸多痛点。
例如,现有技术往往聚焦于3D生成的单一环节,仅优化布局或合成纹理,难以实现全要素的协同优化。
且现有技术生成的场景缺乏可分离、可操作的物体和表面,即便借助大语言模型或扩散模型的方法,现有成果也难以通过扩展计算资源提升生成质量。生成的数据也不适合需要精准标注的合成数据应用或机器人交互仿真场景,与下游任务对3D环境的质量要求存在差距。
简单来说,现有技术只是在生成一个整体的3D图像,虚拟世界中的杯子、书本没办法独立交互。
而3D-GENERALIST就是来解决这些痛点的。
二、研究方法:引入自改进机制,让扩散模型画图、VLM指挥、API执行
斯坦福和英伟达研究团队的核心思路就是将一个“设计师”扩展为一个“建筑师团队”,把搭房子的工作细化,每个步骤交给专门的人去做。
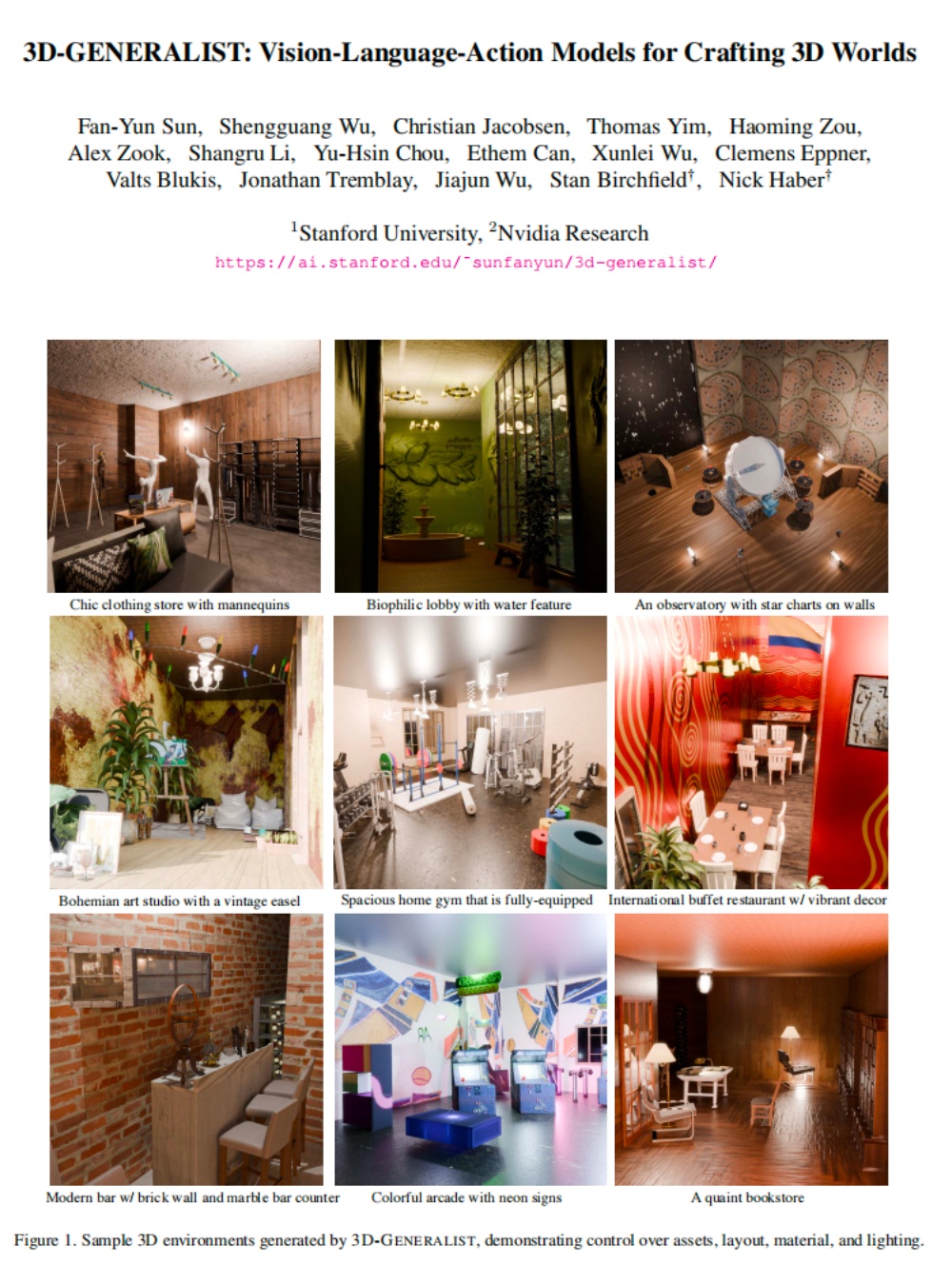
具体来讲,研究团队首先通过全景扩散模型生成360°引导图像,这一步就相当于先画了一张户型图,之后的建设都要按照这一图像来。
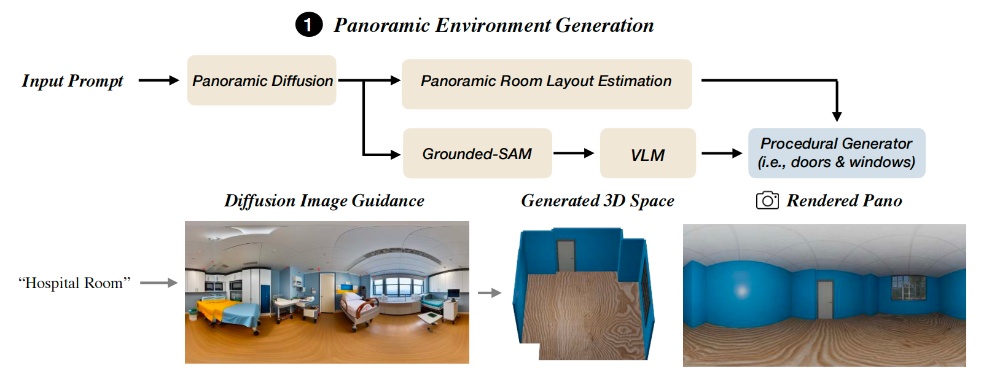
然后,研究团队提出了“场景性策略”,一共分为三步:
首先利用HorizonNet提取房间基础结构,搭好房梁结构,后通过Grounded-SAM技术,在识别好的墙体上,分割出门和窗户的具体区域。最后再由GPT-4o等VLM(视觉语言模型)标注门窗类型与材质,通过程序化生成构建带基础构件的3D房间。
搭好毛坯房后,研究团队以VLM作为决策“大脑”,向其输入含坐标标记、资产名称标记的多视角场景渲染图和文本提示。
随后VLM会直接输出代码形式的具体动作指令,比如添加资产、调整光照、更换材质等,这些代码指令会对接3D环境的工具API,API自动执行指令,实时更新整个3D房间。
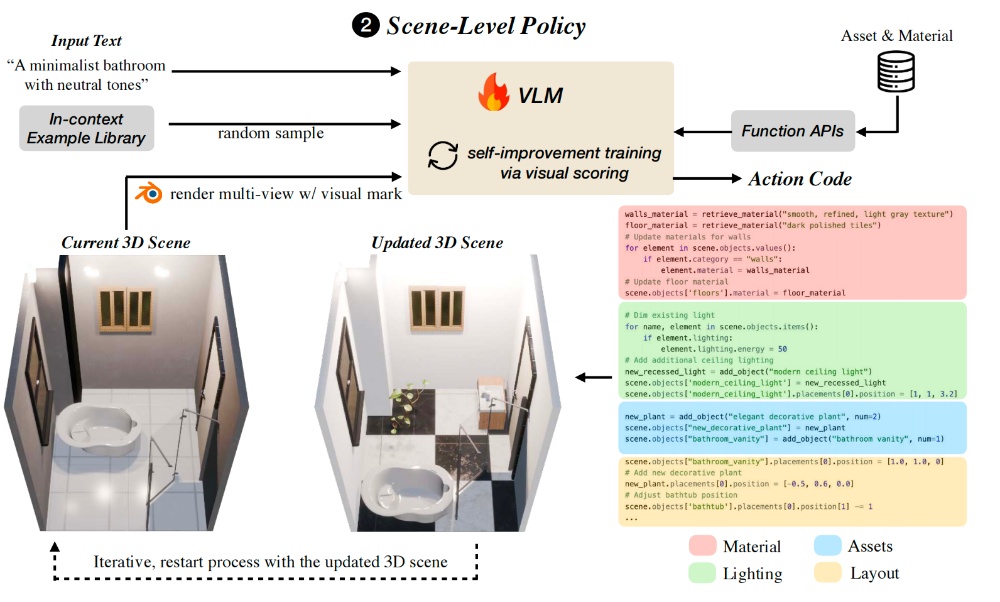
为了让虚拟场景中的每一个物体都能实现独立交互,研究团队还针对性设计了一套资产级优化策略。
具体来看,团队先借助GPT-4o识别出场景中可承载小物件的容器类资产,例如桌子、书架等载体,再通过基于网格的表面检测技术,精准定位这些载体上适合放置物品的有效区域。
随后,团队引入擅长像素级精细推理的视觉语言模型Molmo-7B,进一步确定小物体的具体放置像素点,并通过3D射线转换,将像素位置换算为高精度的3D空间坐标。
结合碰撞检测技术,3D-GENERALIST最终实现如把书摆到桌上、把笔放在书上这类贴合现实逻辑的交互效果。
此外,3D-GENERALIST背后还有3大关键技术做支撑:
首先研究团队引入了自改进微调机制,模型在每轮微调中会生成多个候选动作序列,通过CLIP评分筛选出与文本提示最对齐的最优动作,再用该最优动作对VLM进行监督微调,以此提升模型自我修正能力。
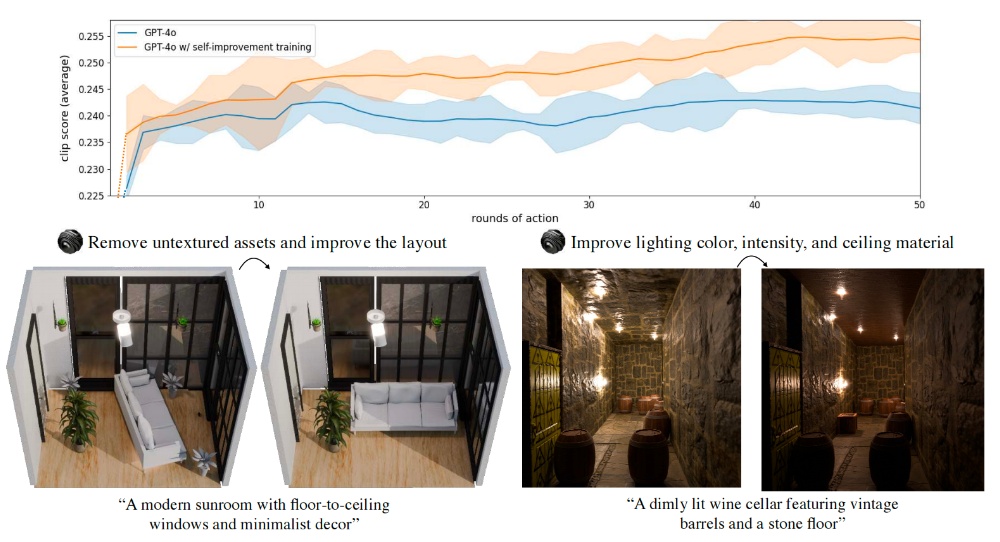
其次,研究团队还规范了场景领域特定语言,定义了类别、放置位置、材质、光照等核心描述符,规范VLM输出的动作指令格式,确保其与工具API兼容。
研究团队使用的上下文库收录能显著提升CLIP对齐分数的动作代码片段,生成时随机采样作为示例,提升动作序列的多样性和有效性。
三、成绩验证:物理合理性99%,合成数据训练效果接近真实数据
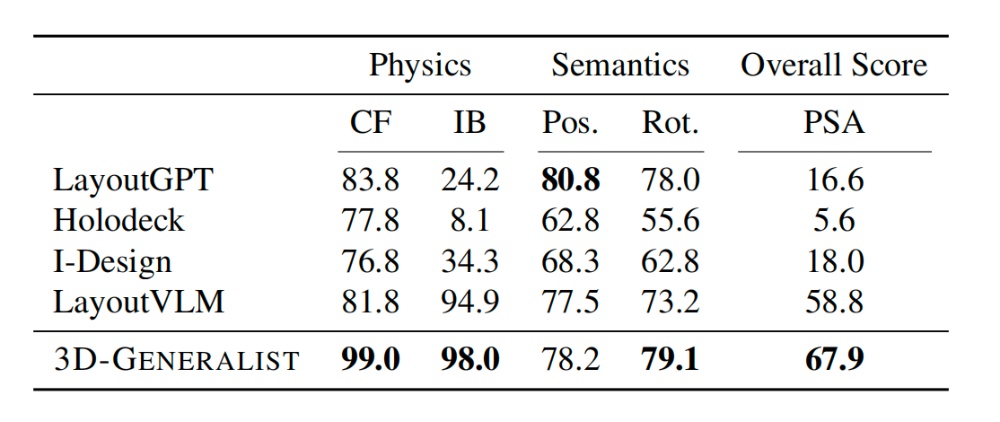
在模拟就绪3D环境生成任务中,3D-GENERALIST的3D环境生成质量层级全面超越LayoutGPT、Holodeck、LayoutVLM等基线方法。
物理合理性方面,3D-GENERALIST的无碰撞分数达99.0,边界内分数达98.0。语义一致性方面,其位置连贯性和旋转连贯性的分数分别为78.2和79.1,综合物理语义对齐分数达67.9,远高于基线最高值58.8。
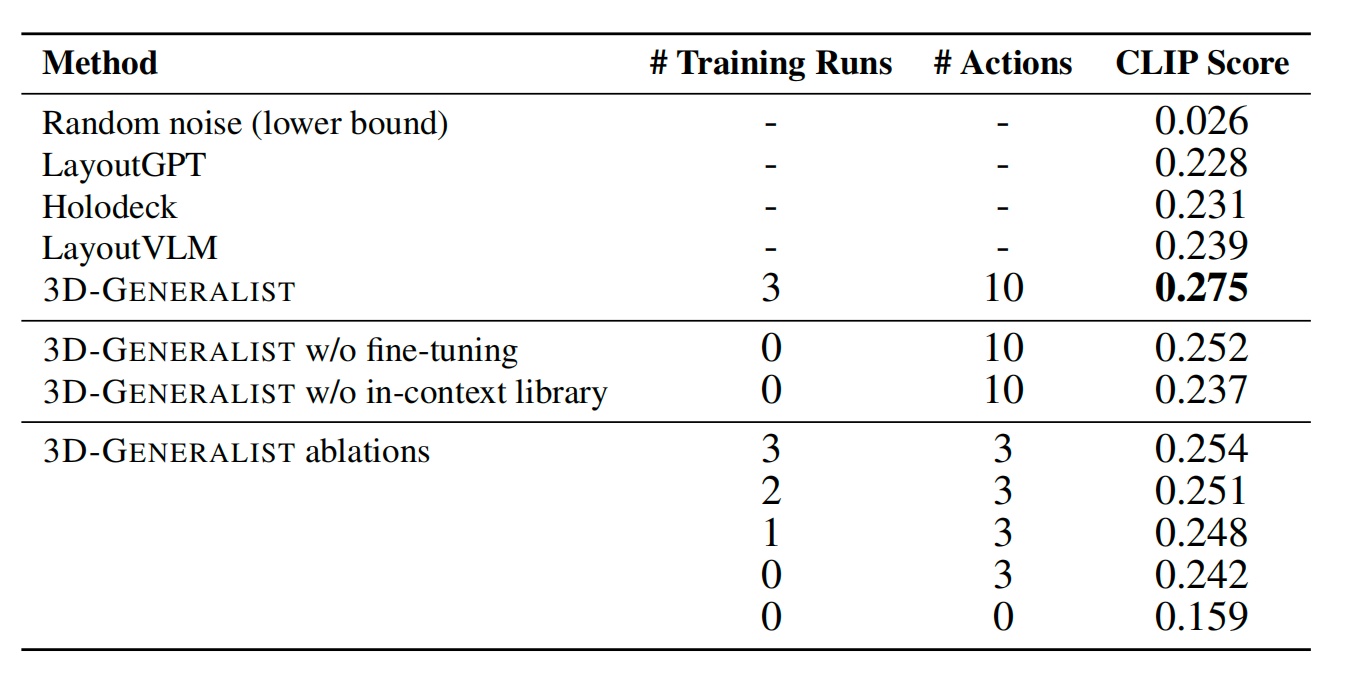
经3轮自改进微调后,3D-GENERALIST的CLIP分数达0.275,显著高于无微调版本和无上下文库版本,且能迭代修正场景缺陷。
资产级策略生成的场景平均CLIP分数达0.282,高于基线方法的0.269,可自然实现小物体的语义对齐和物理合理放置,避免物体重叠。
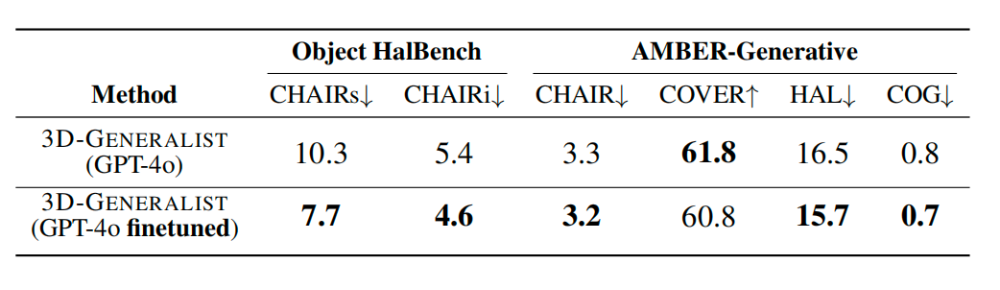
自改进微调技术的引入还降低了VLM的视觉幻觉率,在Object HalBench和AMBER基准测试中,微调后模型的幻觉相关指标均优于原始GPT-4o。
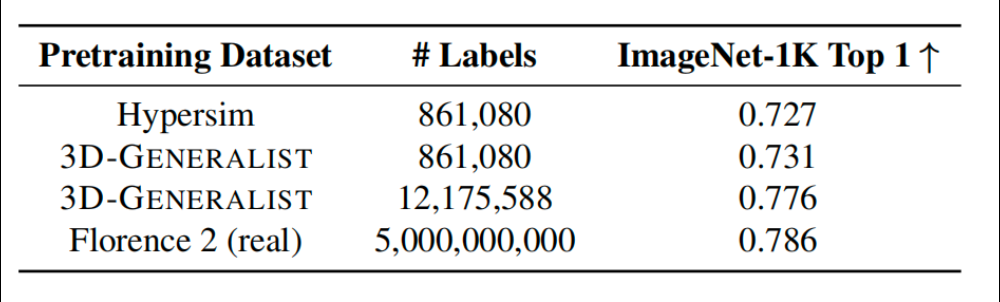
基于3D-GENERALIST生成的合成数据预训练视觉模型ImageNet-1K Top-1,使用86万条标签训练时,准确率达0.731,超过基于人工构建的HyperSim数据集。
当标签量扩展至1217万条时,ImageNet-1K Top-1准确率提升至0.776,接近基于50亿真实数据训练的模型效果,验证了其在合成数据规模化生成上的优势。
四、研究团队:8个华人,创企CEO、清华姚班天才,还有Qwen实习生
除了研究本身,论文的作者栏也十分引人瞩目。
该篇论文的第一作者Fan-Yun Sun是斯坦福大学AI实验室(SAIL)的计算机科学博士生,隶属于Autonomous Agents Lab和斯坦福视觉与学习实验室(SVL)。
在读博期间,他也深度参与了英伟达研究院的工作,曾效力于学习与感知研究组、Metropolis深度学习(Omniverse)以及自动驾驶汽车研究组。
他的研究兴趣主要在于生成具身环境与数据,用于训练机器人和强化学习策略,致力于推动具身、多模态基础模型及其推理能力的发展。
此外,他还创办了AI游戏公司Moonlake,是一家专注于交互式世界构建的前沿人工智能实验室,融合了多模态推理和世界建模。
该创企此前已从Threshold Ventures、AIX Ventures和NVentureS(NVIDIA的风险投资部门)筹集了2800万美元(约合人民币1.95亿元)的种子资金。

第二作者Shengguang Wu目前是斯坦福大学计算机科学系的博士生,在北京大学获得硕士学位。
他此前曾在Qwen团队担任研究实习生,并且参与了Qwen 1的研究工作。

吴佳俊是斯坦福大学计算机科学和心理学的助理教授。2014年他从清华大学交叉信息研究院“姚班”本科毕业,师从屠卓文(Zhuowen Tu)教授。在校期间,他曾三年都是年级名次第一,还担任了世界顶级的计算机视觉会议CVPR审稿人。
吴佳俊博士毕业于麻省理工学院,导师是Bill Freeman和Josh Tenenbaum。在加入斯坦福大学之前,他曾是谷歌Research的客座研究员,和Noah Snavely一起工作。
目前,他的团队致力于物理场景理解研究——即构建能够观察、推理并与物理世界互动的智能机器,以及以下方面:
1、基于视觉、听觉与触觉信号的多模态感知(如物体文件夹、真实影响力项目)
2、四维物理世界的视觉生成(如三维生成对抗网络、π生成对抗网络、点体素扩散模型、SDEdit图像编辑、奇幻世界)
3、通过物理概念基底的视觉推理(常采用神经符号化方法,如神经符号视觉问答、形状程序、动态视觉推理数据集、逻辑视觉推理框架)
4、运用习得物理场景表征的机器人学与具身人工智能(如机器人厨师、行为模拟平台)。
Shangru Li目前是英伟达公司的高级系统软件工程师,之前曾在腾讯有过工作经历。
他2019年本科毕业于广东外语外贸大学的计算机软件工程专业,在大三的时候,其曾在腾讯实习。2021年,Shangru Li于美国宾夕法尼亚大学的计算机图形学和游戏技术专业硕士毕业,此后便一直在英伟达工作。

此外,还有4位华人研究员参与其中,分别为Haoming Zou、Yu-Hsin Chou、Ethem Can以及Xunlei Wu。
结语:模型与机器人训练成本或将进一步降低
3D-GENERALIST将传统分离的建模、布局、材质、光照等环节整合为统一的决策序列,并通过自改进机制赋予AI自我改错的能力。
这不仅显著提升了复杂3D场景的构建效率与物理合理性,更关键的是,其验证了高质量合成数据规模化替代人工标注的可行性,将有望降低下游视觉与机器人模型训练的成本门槛。
