








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西2月25日报道,2月24日,由两位前谷歌工程师创办的美国AI芯片创企MatX宣布完成5亿美元(约合人民币34亿元)B轮融资,其大模型芯片MatX One预计一年内完成流片。
据外媒报道,MatX透露其目前的估值已达数十亿美元,也就是已跻身独角兽行列。
MatX宣称MatX One能实现远超其他芯片的吞吐量,同时延迟也最低。这款芯片基于可分割的脉动阵列,兼具大型脉动阵列出色的能效和面积效率,同时在小型矩阵上也能实现高利用率。
据MatX披露,该芯片结合了SRAM优先设计的低延迟和HBM的长上下文支持。这些特性加上对数值计算的新诠释,使其在大语言模型上的吞吐量高于任何已发布的系统,同时延迟与SRAM优先设计相当。
MatX的测试表明,根据每平方毫米的计算性能指标,其规划芯片的性能可以超越英伟达即将推出的Rubin Ultra。
2022年,MatX由Reiner Pope和Mike Gunter创办,目标打造一款最适合大语言模型的芯片。
Reiner Pope曾为谷歌的芯片和AI模型开发软件,Mike Gunter曾是谷歌TPU的硬件工程师。
如今,MatX的团队规模已发展到约100人。
由前OpenAI研究员Leopold Aschenbrenner创立的投资公司Situational Awareness与Jane Street领投了MatX的B轮融资。
在Aschenbrenner看来,MatX的芯片非常适合处理预训练和强化学习,“它很有可能成为这一代最重要的AI芯片公司。”
前特斯拉AI总监、OpenAI联合创始人Andrej Karpathy,以及Alchip、Marvell等供应链上的投资者也参与了本轮融资。
Andrej Karpathy在社交平台上分享了他参投MatX的想法。
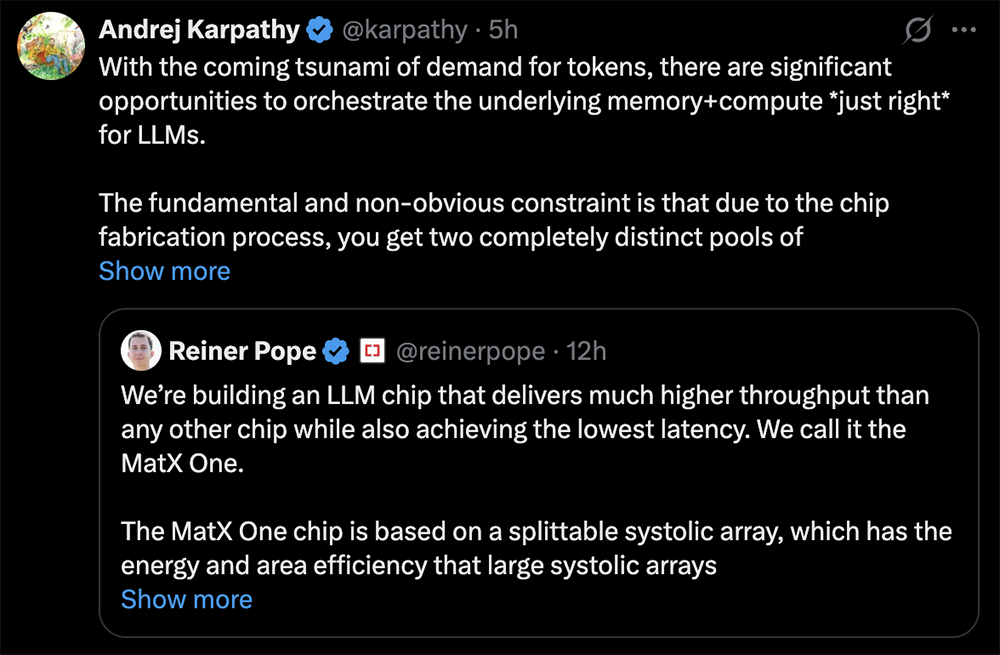
他认为,token需求激增,为大语言模型的底层内存和计算资源的合理配置提供了绝佳机会。一个根本且不易察觉的限制是,受限于芯片制造工艺,内存池会分为两个完全不同的池(物理实现方式也不同):1)紧邻计算单元的片上SRAM,速度极快但容量极低;2)片外DRAM容量很大,但内容难获取。
此外,还有许多架构细节(例如脉动阵列)、数值计算等因素需要考虑。如何设计最优的物理基础架构,并在大语言模型的核心工作流程(推理预填充/解码、训练/微调等)中合理配置内存和计算资源,以实现最佳吞吐量/延迟/成本比,这或许是当今最具吸引力且回报最高的智力难题之一。
“这一切都是为了快速、低成本地获取大量token。可以说,最重要的工作流程(在紧凑的智能体循环中对长token上下文进行推理解码)是目前两种阵营(HBM优先的英伟达阵营和SRAM优先的Cerebras阵营)最难同时实现的。”Karpathy写道。
官网显示,对于大型100层MoE模型,MatX的AI芯片每秒可输出超过2000个token,其横向扩展互连能力可支持包含数十万张芯片的集群。

当前,英伟达和谷歌的AI芯片都主要依赖HBM来处理训练AI模型所需的大量计算。还有一些芯片公司采用静态随机存取存储器(SRAM)来更快地处理单个用的查询,以满足日益增长的推理需求。
“我们的立场是,实际上可以在同一个产品中同时实现这两点,而且这样会得到一个更好的产品。”MatX创始人兼CEO Reiner Pope谈道。
他在社交平台X上回复网友说:“与其他HBM厂商不同,我们拥有足够的SRAM和互连带宽,足以支持将权重存储在SRAM中。HBM中的key值对不会增加延迟,因为密集读取可以预取,而稀疏读取的数据量很小。除了内存系统之外,我们还拥有最高的FLOPS/mm2。”
据外媒报道,MatX预计在今年完成芯片的最终设计,并希望在2027年开始出货。该公司计划与台积电合作生产该产品。
