







芯东西(公众号:aichip001)
编译 | 程茜
编辑 | Panken
芯东西2月26日消息,2月15日-19日,在被业界誉为“芯片设计国际奥林匹克会议”的国际固态电路大会(ISSCC 2026)上,清华大学、华为、字节跳动等大学与公司的研究人员发表论文,首次提出一款基于HYDAR框架的28nm混合存内计算(CiR)芯片的推荐系统(RecSys)加速器。

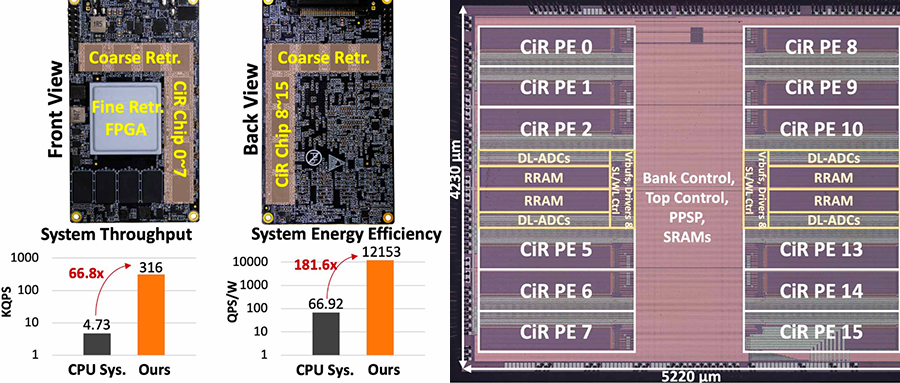
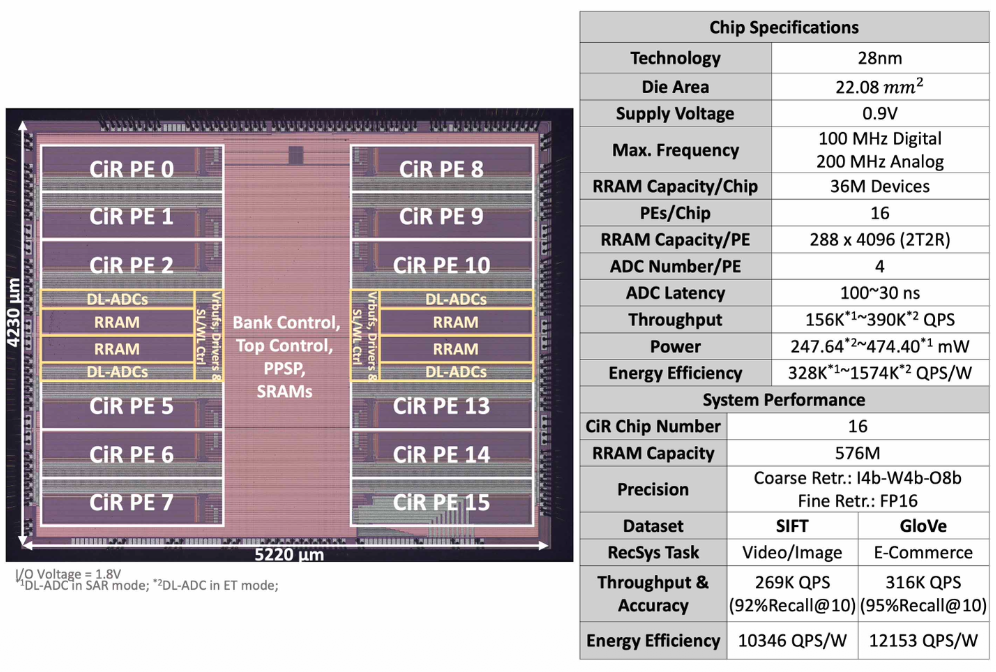
这款36M RRAM CiR芯片能实现390K QPS的吞吐率与1574K QPS/W能效比。其构建的多芯片系统可实现百万级实时端到端推荐系统(RecSys)。
▲芯片显微照片与系统概述
在实际推荐系统任务中,CiR通过扩展至576M规模的多芯片系统,QPS提升了66倍,QPS/W提升181倍,准确率与CPU相当。
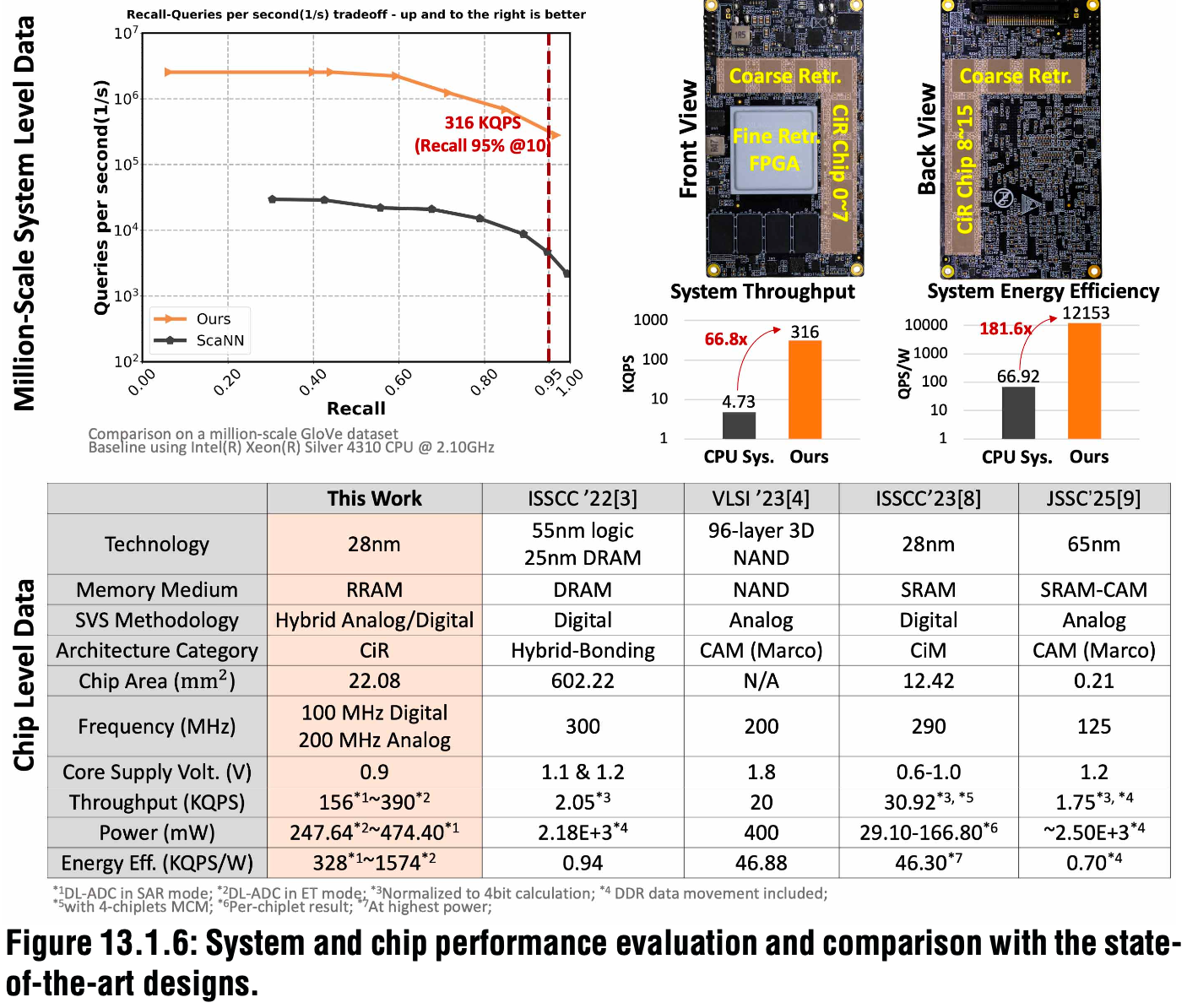
▲芯片性能与当前顶尖设计的对比
该芯片的核心优势包括:采用DL-ADC实现非Top-K计算的早期终止;基于预测的预取调度流水线(PPSP)数据流提升不规则工作负载的吞吐量;由粗到细的检索架构(coarse-to-fine)在保证系统召回精度的同时,可扩展至大规模应用。
一、引入CiR,实现高吞吐、高能效、高精度相似向量检索
推荐系统中的核心运算单元是相似向量检索(SVS),该方式通过计算查询向量与大规模向量库之间的距离,检索出Top‑K最邻近向量。
SVS会占据推荐系统绝大部分的计算时间与功耗,主要原因是外部存储器访问(EMA)开销。其中,采用混合键合技术的DRAM加速器成本高昂,基于NAND TCAM的加速器存在读取延迟高、数据与距离表示精度有限等问题。
针对上述痛点,研究人员提出一种基于RRAM的数模混合存内计算加速器HYDAR,可实现高吞吐量、高能效、高精度的SVS。
基于RRAM的存内计算(Compute-in-RRAM,CiR)因能最大限度减少数据移动、存储密度高、并行度极大,已被公认为深度学习加速的极具前景的技术路线。但将CiR应用于SVS仍会带来额外挑战,如能耗与延迟急剧增加、降低PE利用率与吞吐量、精度降低等。
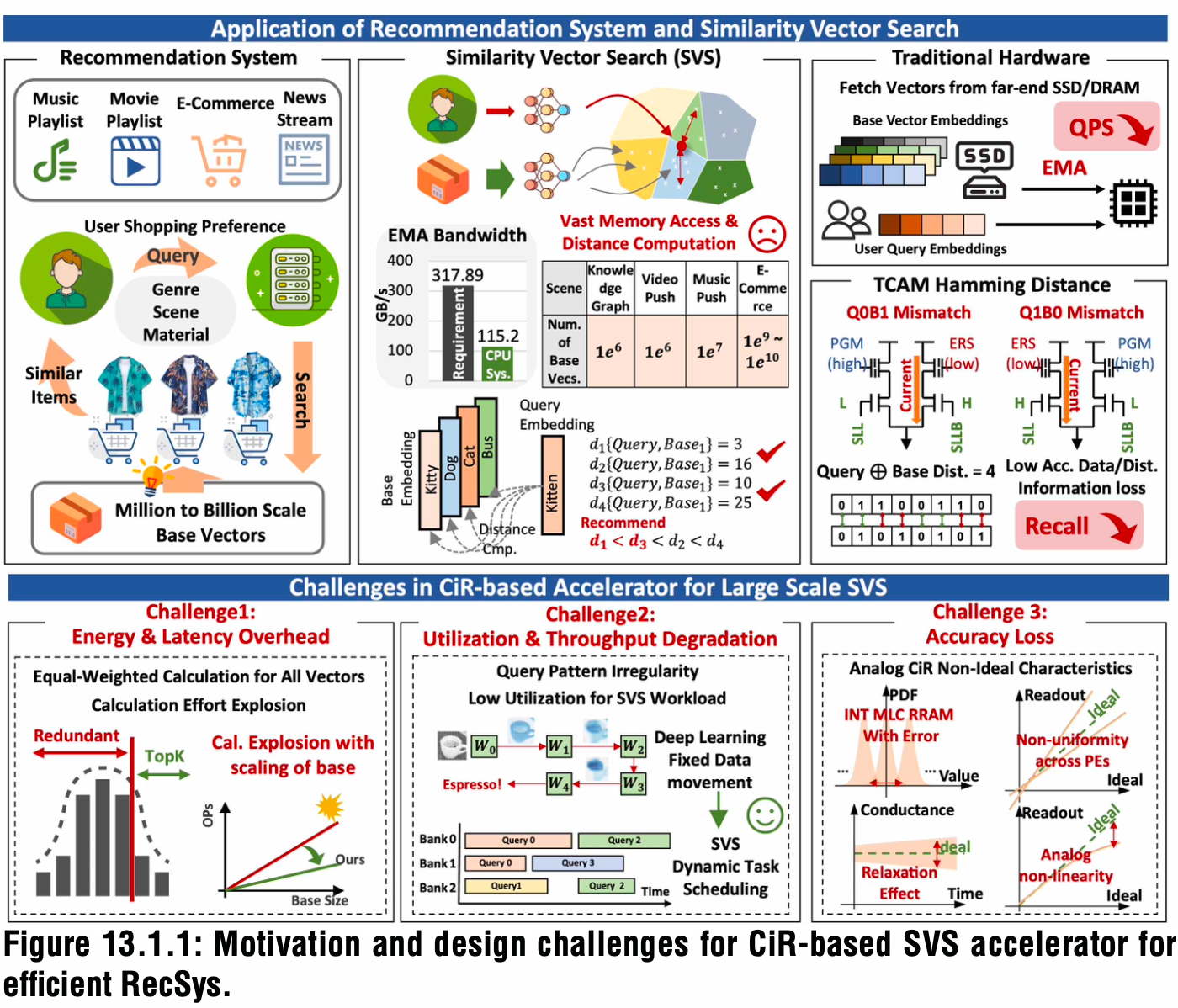
▲面向高效推荐系统的、基于CiR的SVS加速器的研究动机与设计挑战
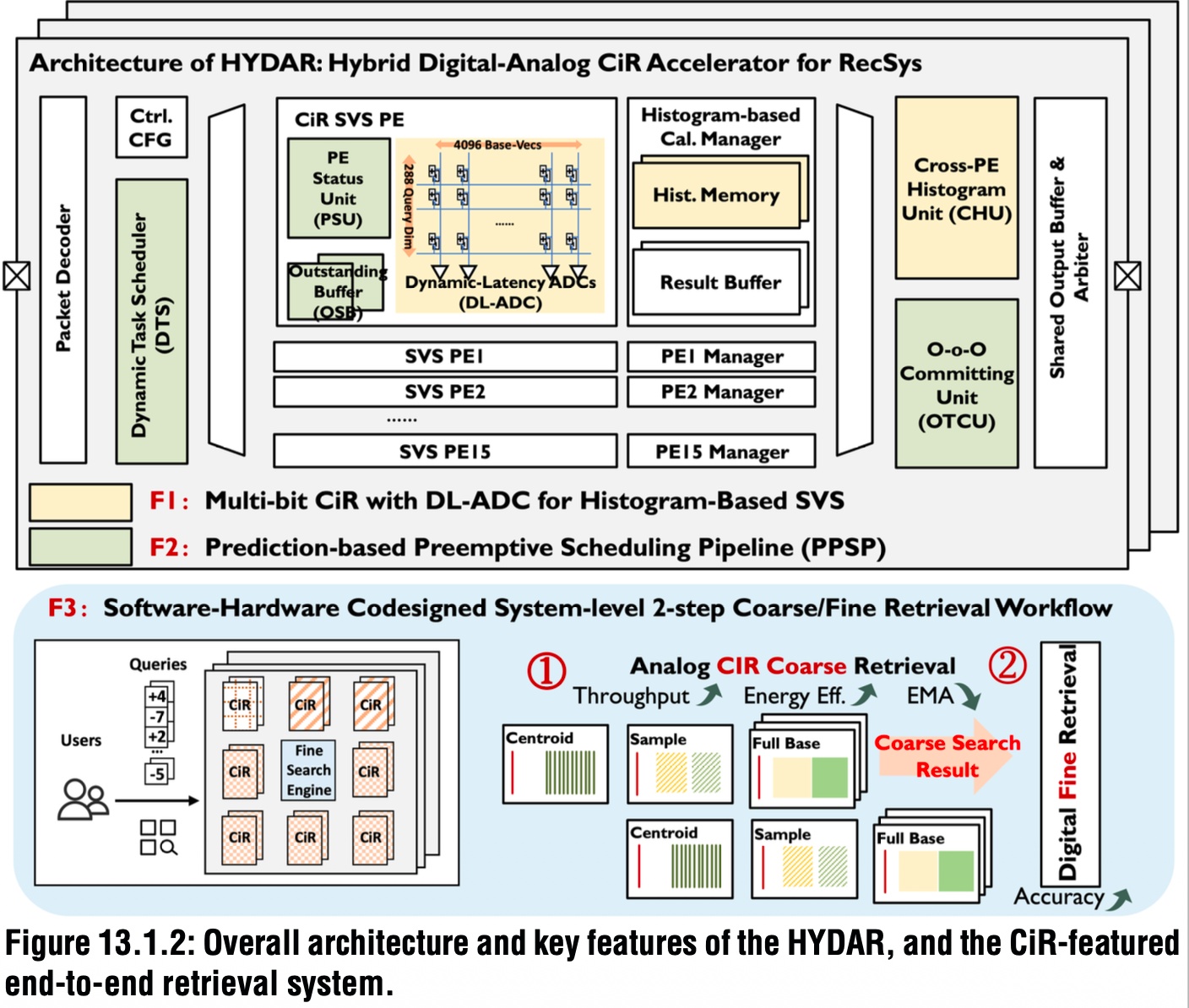
HYDAR通过CiR PE(存内计算处理单元)、混合芯片设计与多芯片系统架构协同优化,解决了上述挑战:
首先是带动态延迟ADC(DL‑ADC)的CiR PE,其通过多位模拟CiR PE集成DL‑ADC,用于基于直方图的相似向量检索,可提前将距离与检索阈值比较,并跳过非Top‑K向量,从而降低延迟与功耗。
其次是基于预测的抢占式调度流水线(PPSP),通过这种混合芯片机制,预测每个PE的运行时间、中断不平衡任务、插入短任务来平衡负载,以适应动态SVS工作流,提升利用率与吞吐量。
最后是两步由粗到精的检索架构,其软硬件协同设计框架,先在CiR PE上进行粗粒度检索以保证高吞吐量,再在数字SVS引擎上进行精粒度检索,在保证召回精度的同时最大化吞吐量。
在此基础上,基于HYDAR框架,研究人员采用28nm工艺流片实现了一款CiR原型芯片,包含36M RRAM单元,分为16个并行PE,每个PE包含一个288×4096阵列
二、采用基于DL‑ADC的SVS高效过滤机制,降低60%延时、71%功耗
具体来看基于模拟存内计算单元(CiR PE)的直方图相似向量检索(SVS)实现,以及支持计算提前终止的DL‑ADC设计。
其通过查询向量与基础向量之间的距离分布直方图来确定Top‑K检索的截断阈值(CK)。在欧氏距离框架下,距离超过CK的基础向量由双模DL‑ADC过滤,该ADC可动态监测比较结果,实现非Top‑K向量的计算提前终止。
欧氏距离计算可在288×4096的CiR阵列上完成,其中每个2T2R单元表示一个4位维度,每一列代表一个256维基础向量及32维偏置。
本设计中,CiR PE在计算过程中将直方图存入本地直方图存储器,随后同步至跨PE直方图单元(CHU),合并分布式结果以生成CK。该论文设计了三条定制指令来执行该流程。
在DL‑ADC方面,基于逐次逼近寄存器(SAR)的结构支持提前终止模式(ET),将预生成的CK作为输入,与每个周期生成的SAR码一同送入按位比较器。
在迭代调整IDAC以逼近ADC输入电流的过程中,任何一位不匹配都表明计算结果与CK存在差异,触发提前终止,停止计算并输出2位向量掩码(vMask)。
最后,通过将DL‑ADC设置为ET模式,距离计算与过滤可同时执行。
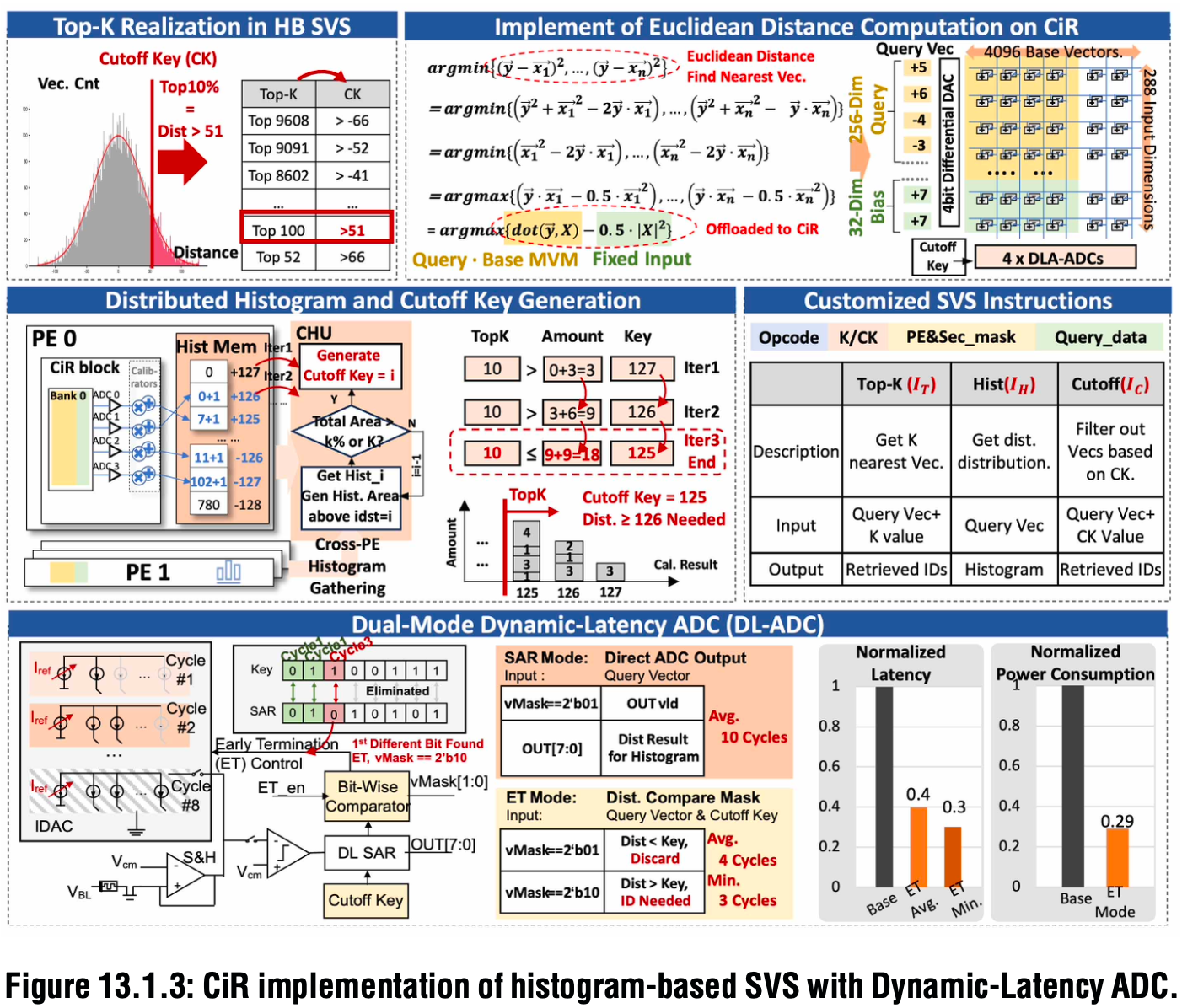
▲基于动态延迟ADC(DL‑ADC)的直方图式SVS的CiR实现
该ET机制在数据库规模扩大时效果显著,平均减少60%的计算时间和71%的功耗,宏单元面积开销增加7%。
三、预测抢占式调度,利用率提升至91%、平均查询延迟降低30%
其次是面向SVS负载提出的基于预测的抢占式调度流水线(PPSP)。
查询在不同PE间并行计算,而每个PE参与计算的基础向量数量通常不同,这会造成计算周期差异与PE间同步开销,进而引发调度停顿与流水线气泡。
PPSP采用连续抢占式调度与动态任务调度器(DTS)解决了这一问题。
DTS会对各PE上查询执行的完成时间戳进行监测与预测。该论文提出的抢占式调度机制允许新任务抢占那些即将完成的正在运行任务,这可以消除流水线气泡、让任务更早完成、PE更快释放,以服务后续查询。
在接收到指令时,任务会占用一个DTS槽位,并将其PE/段掩码存入任务表,然后作为子任务路由到目标PE的两个待处理缓冲区之一。
DTS同时监控每个任务的预测关键结束时间(PCET),其定义为所有子任务PET的最大值。其中的仲裁器检查PE与正在运行任务的重叠情况,如果新任务的PET可以降低且不影响正在运行任务的PCET,则切换待处理缓冲区以抢占式调度新任务,从而提升吞吐量、降低延迟。
此外,在查询调度期间,DTS会在后端内存分配器中为每个查询预分配地址空间,使得PE可以直接将结果写入输出缓冲区,无需PE间同步,从而实现PE快速释放以处理新查询。
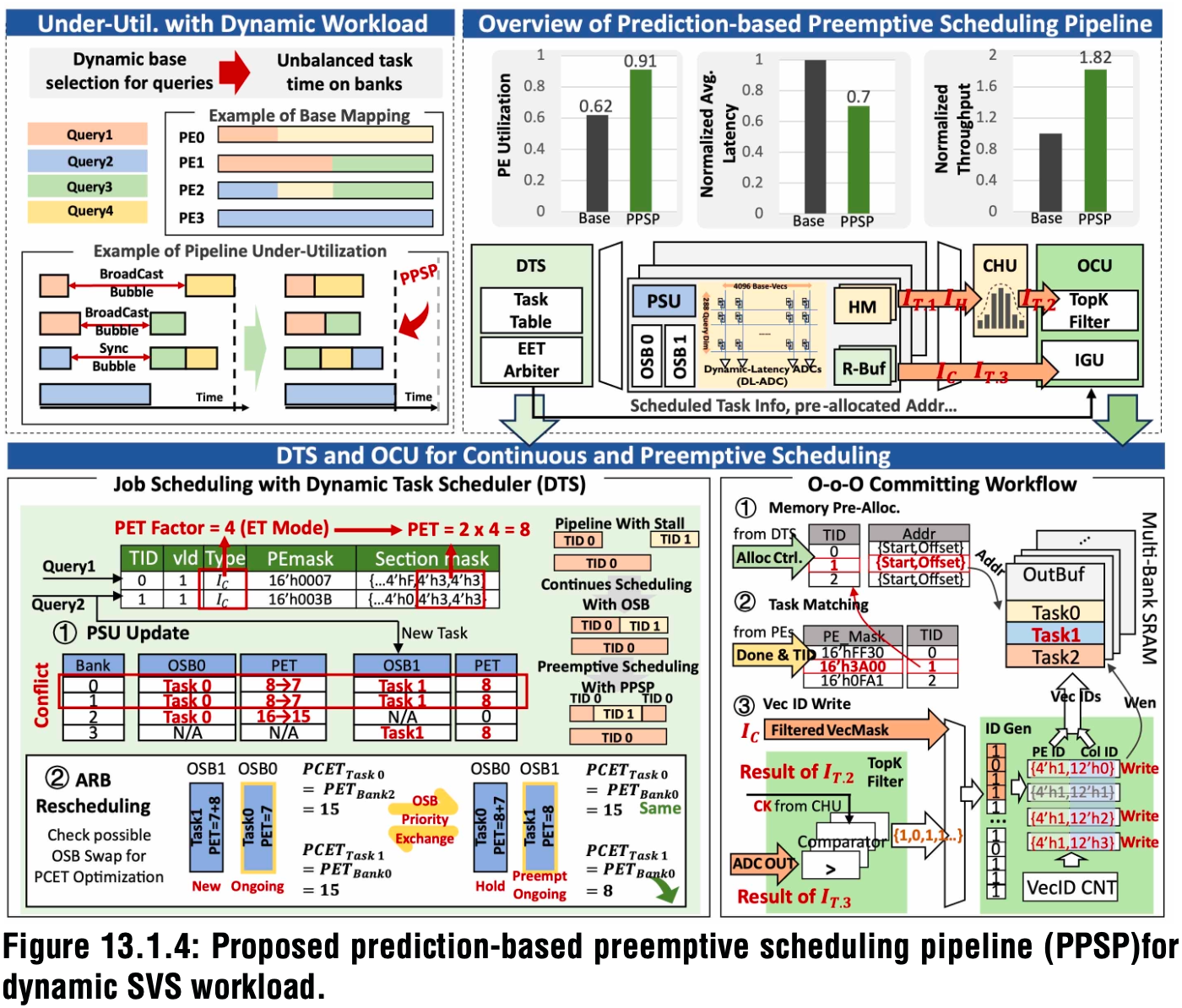
▲面向动态SVS负载的、所提出的基于预测的抢占式调度流水线(PPSP)
通过以上优化,PPSP将PE利用率提升至91%,平均查询延迟降低30%,QPS吞吐量提升1.82倍。
四、由粗到细两步检索,实现系统级四级流水线并行
最后是面向SVS、基于CiR的两步检索架构。
为提升系统精度,该架构集成了数字精检索引擎,在高吞吐粗检索结果中精确筛选向量。这使得即使在模拟CiR存在噪声与低精度处理的情况下,仍能保持高召回精度。
该架构还通过多CiR芯片并行扩展了向量库容量,并支持更广泛的并行粗检索,同时采用Thresh‑IVF流程与系统流水线,进一步提升吞吐量。
CiR PE分为三类:质心PE(CPE)存储聚类中心坐标,采样PE(SPE)存储从每个聚类中采样的少量向量,用于表征分布并生成CK;全量库PE(FPE)存储所有基础向量,并全程运行在高能效的DL‑ADC提前终止(ET)模式下,在整个流程中占据92.7%的向量存储。
CiR专用的Thresh‑IVF工作流程包括查询首先送入CPE,通过IT运算计算查询与聚类中心的距离,识别最近的聚类;系统将查询路由到所选聚类的SPE,通过IH在多芯片间生成直方图,进而生成CK;CK被路由到步骤1所确定聚类的所有FPE,通过IC完成粗检索ID生成。
这种系统级基于阈值的粗检索,最小化了每个芯片输出的过滤结果数量,避免了在各芯片上执行相同Top‑K计算带来的冗余ID过滤。最后,少量候选ID被送入数字引擎,以FP16格式进行精检索,使系统级存储带宽需求降低97.44%。
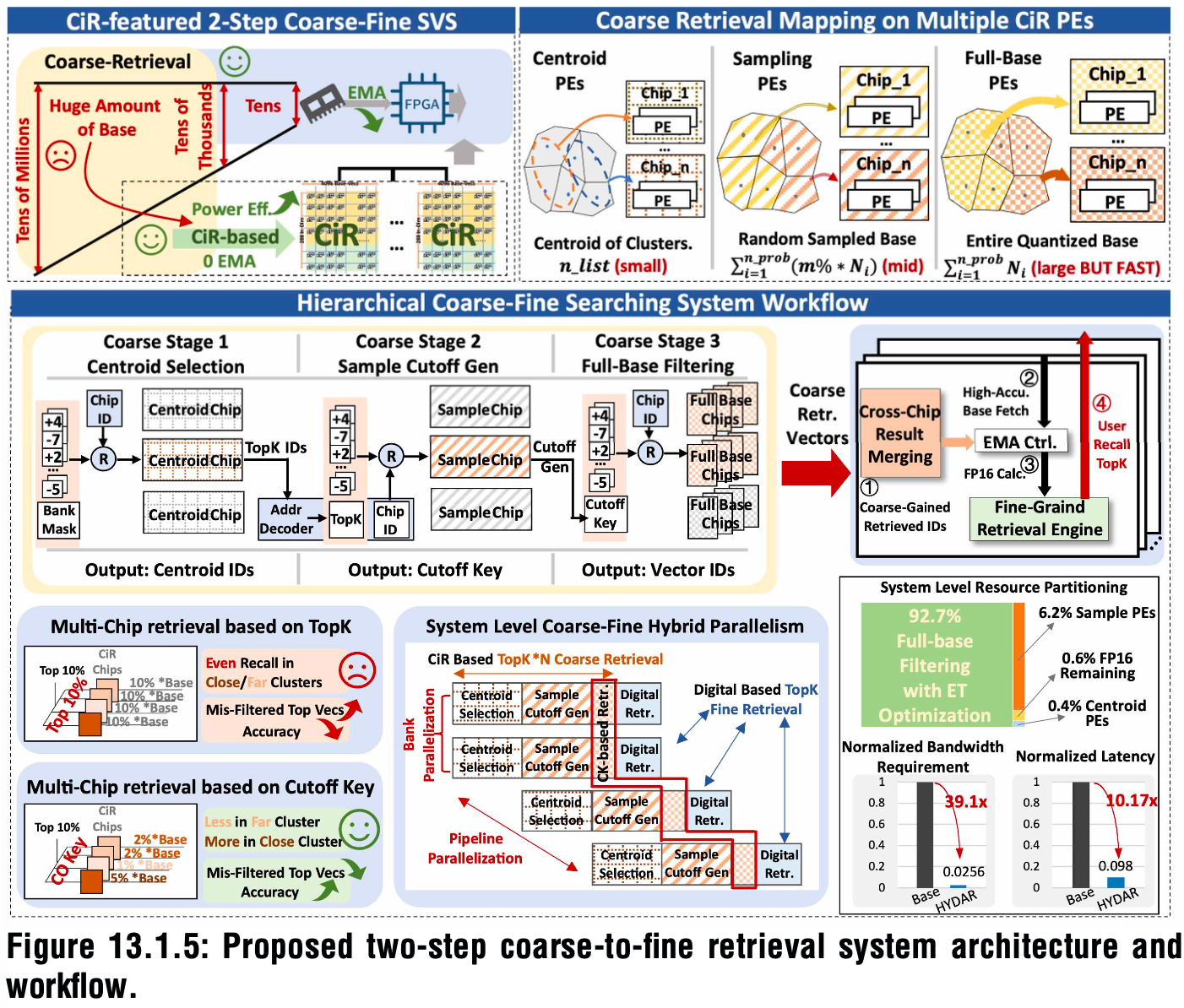
▲两步由粗到精检索系统架构与工作流程
该设计实现了系统级四级流水线并行;同时芯片内不同PE也可并行处理不同任务。相较于传统基于CPU的IVF方案,这种多芯片层级流水线可将延迟降低90.17%。
结语:兼顾精度与效率,推荐系统算力成本骤降
推荐系统在连接用户与海量内容和服务方面发挥着至关重要的作用,已广泛部署于电商和流媒体平台,但作为其核心运算单元相似向量检索占据了推荐系统绝大部分的计算时间和功耗。
其中采用混合键合技术的DRAM加速器提升了带宽以缓解EMA问题,但其成本高昂,且仍受限于DRAM与逻辑单元之间的数据传输瓶颈;基于NAND TCAM的加速器将计算集成到存储阵列中以减少EMA,但存在读取延迟高、数据和距离表示精度有限的问题。
基于此,这篇最新研究提出了一款高效的SVS加速器,能在保证高吞吐量检索的同时,不牺牲召回精度,进一步降低推荐系统的功耗。
