








芯东西(公众号:aichip001)
编译 | ZeR0
编辑 | 漠影
芯东西3月12日消息,3月11日,Meta发文宣布面向数十亿用户在2026年-2027年两年推出4款AI芯片MTIA 300、400、450、500,并对每款芯片设计的核心亮点悉数道来。
Meta致力于构建多元化的芯片产品组合,并充分利用内部和外部的最佳解决方案。
同时,Meta与博通紧密合作开发的自研AI芯片系列Meta训练与推理加速器(MTIA),一直是并将继续是Meta AI基础设施战略的重要组成部分。
MTIA系列包括:
- MTIA 300:最初针对R&R模型进行了优化,其构建模块为后续针对GenAI模型优化的芯片奠定了基础。它已投入生产用于R&R(排名&推荐)训练。
- MTIA 400:随着GenAI的蓬勃发展,MTIA 300升级为MTIA 400,旨在更好地支持GenAI模型,同时保持对R&R工作负载的支持能力。MTIA 400拥有72个加速器的扩展域,可提供与领先的商业产品相媲美的高性能。MTIA 400已在实验室完成测试,正在数据中心进行部署。
- MTIA 450:为了应对GenAI推理需求的增长,MTIA 400升级为MTIA 450,并针对GenAI推理进行了专门优化,HBM带宽从MTIA 400提升了1倍,使其远高于现有领先的商用产品。Meta还引入了专为推理工作负载设计的低精度数据类型。MTIA 450计划于2027年初大规模部署。
- MTIA 500:MTIA 500继续专注于GenAI推理,与MTIA 450相比,HBM带宽提高了50%,并在低精度数据类型方面引入了更多创新。MTIA 500计划于2027年大规模部署。
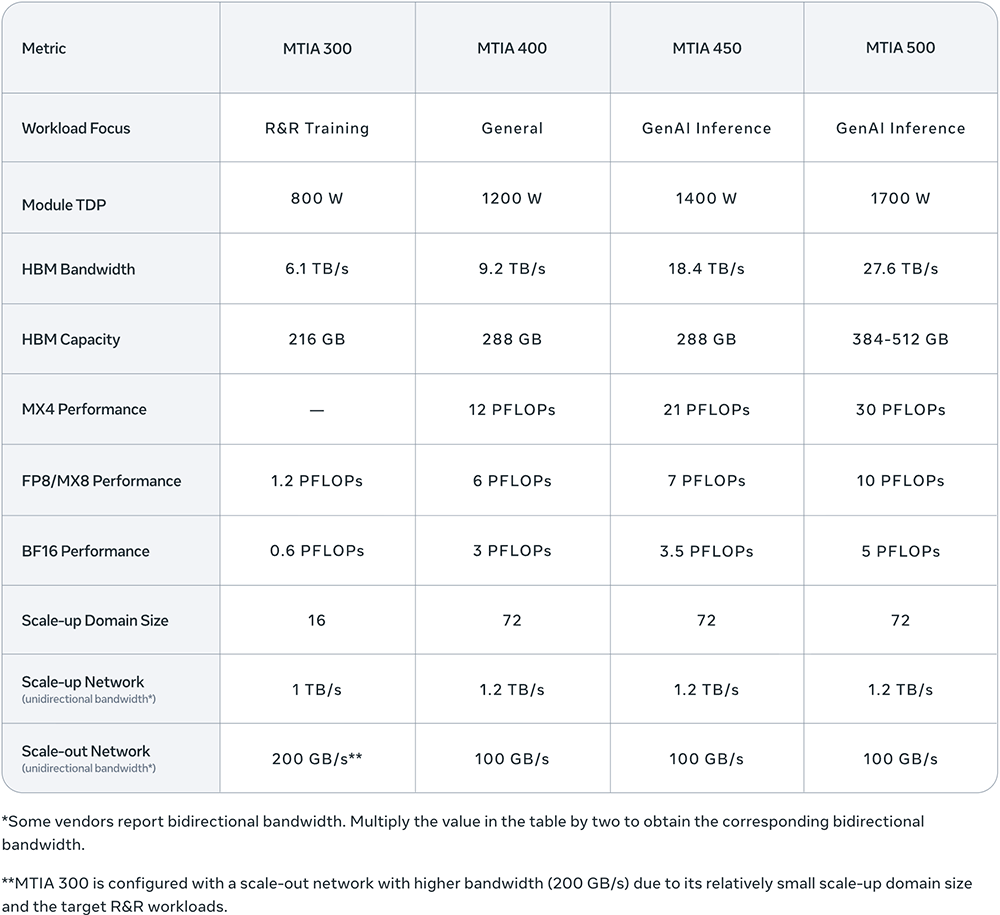
从MTIA 300到MTIA 500,HBM带宽提升至4.5倍,计算FLOPS提升至25倍(从MTIA 300的MX8提升到MTIA 500的MX4),如下方芯片规格所示。
一、两年4款AI芯片,MTIA如何进化?
Meta在ISCA’23和ISCA’25会议上发表了研究论文,详细介绍了前两代MTIA芯片:MTIA 100和MTIA 200(以前称为MTIA 1和MTIA 2i)。
该公司已在生产环境中部署了数十万颗MTIA芯片,并集成了众多内部生产模型,还使用Llama等大语言模型对MTIA进行了测试。
之后,Meta加速开发MTIA 300、400、450和500,这些新芯片要么已经部署,要么计划在2026年或2027年部署,将工作负载覆盖范围从排名和推荐(R&R)推理扩展到R&R训练、通用GenAI工作负载以及具有针对性优化的GenAI推理。
Meta采取迭代式方法:每一代MTIA都基于上一代产品,采用模块化芯片组,融合最新的AI工作负载洞察和硬件技术,并以更短的周期进行部署。
这种更紧密的迭代周期,使其硬件能够更好地适应不断发展的模型,同时也能更快地采用新技术。
MTIA 300最初是针对R&R训练进行优化的。与前几代产品相比,其显著特点包括内置网卡芯片、用于卸载通信任务的专用消息引擎、用于归约任务的近内存计算。这些低延迟、高带宽的通信组件为后续MTIA芯片中高效的GenAI推理和训练奠定了基础。
MTIA 300由1个计算芯片、2个网络芯片和多个HBM内存堆栈组成。每个计算芯片包含一个处理单元(PE)网格,其中一些PE具有冗余以提高良率。
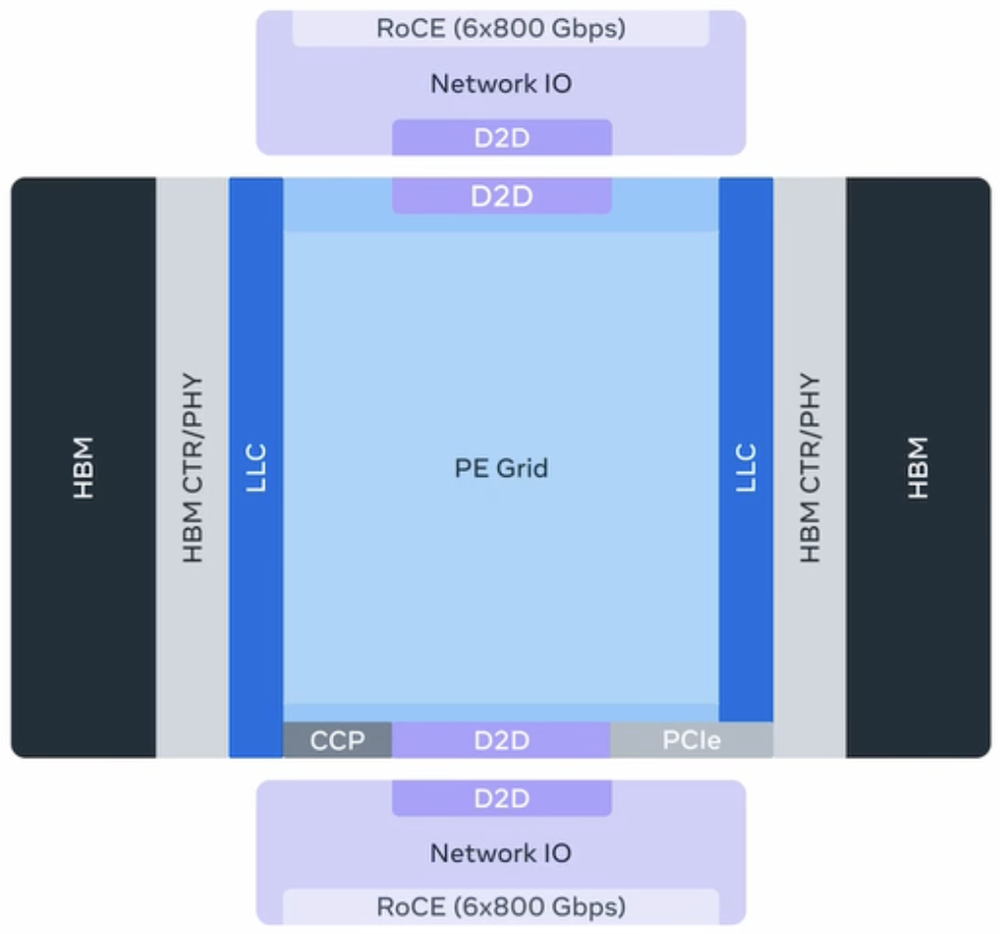
每个PE包含:
- 两个RISC-V向量核心。
- 用于矩阵乘法的点积引擎。
- 用于激活和元素级操作的特殊功能单元。
- 用于累积和PE间通信的缩减引擎。
- DMA引擎用于本地暂存内存的数据进出。
MTIA 300主打经济高效,MTIA 400则是首款旨在不仅降低成本,而且提供与领先商用产品相媲美的原始性能的MTIA芯片。
MTIA 400的设计是为了更好地支持GenAI工作负载及R&R工作负载,相较于MTIA 300提升显著,其FP8 FLOPS性能提升了400%,HBM带宽提升了51%。

MTIA 400集成了两个计算芯片组,使计算密度翻倍,还支持对高效GenAI推理至关重要的增强版MX8和MX4两种低精度格式。
一个机架包含72个MTIA 400设备,通过交换式背板连接,即可构成一个单一的扩展域。这套机架级系统包含72颗MTIA 400芯片,部署在一个独立的扩展域内,并配备相关的网络设备和空气辅助液冷(AALC)机架。MTIA 400芯片本身也支持机房液冷,AALC技术则能够实现传统数据中心的快速部署。

MTIA 450通过在以下4个方面进行改进,更适合GenAI推理:
- 将HBM带宽比上一版本提高1倍,以加快解码速度。
- 将MX4 FLOPS提高75%,以加快混合专家(MoE)前馈网络(FFN)的计算速度。
- 引入硬件加速,使注意力机制和FFN计算更加高效(例如,通过缓解Softmax和FlashAttention的瓶颈)。
- 低精度数据类型的创新。

MTIA 450超越了FP8/MX8,其MX4 FLOPS是FP16/BF16的6倍,并支持混合低精度计算,而无需承担数据类型转换带来的软件开销。它还引入了Meta自研的数据类型创新,在保证模型质量的同时提升FLOPS,且对芯片面积的影响极小。
MTIA 500以更具成本效益的方式支持GenAI推理。其HBM带宽提升了50%,HBM容量提升了高达80%,MX4 FLOPS提升了43%。

该芯片进一步强化了模块化理念,采用2×2的小型计算芯片组配置,周围环绕着多个HBM堆栈和两个网络芯片组,以及一个提供PCIe连接以连接主机CPU和横向扩展网卡的SoC芯片组。
与MTIA 450一样,MTIA 500也引入了额外的硬件加速和数据类型创新,以解决GenAI推理中遇到的瓶颈问题。
二、Meta的策略:高速、推理优先、原生PyTorch
在AI芯片领域,Meta的MTIA策略基于三大支柱:1)高速迭代芯片开发;2)以推理为先导;3)通过基于PyTorch等行业标准进行原生构建,实现无缝采用。
1、高速
Meta已具备大约每6个月推出一款新芯片的能力,快速研发速度带来了两个优势:
- 快速适应不断发展的AI技术:随着新的模型架构、低精度数据类型和服务技术的出现,Meta可针对这些进步优化最新芯片,为重要操作引入硬件加速,并解决计算、内存和I/O之间的瓶颈转移。
- 快速采用最新硬件技术:例如最新的工艺节点、HBM和封装技术。
Meta通过贯穿所有层面的可重用模块化设计实现高速发展:从芯片组、机箱、机架到网络基础设施。
该公司将加速器架构为芯片组系统——独立的、可重用的计算、I/O和网络构建模块。由于每个芯片组都可以单独升级,Meta能在数月内而非数年内完成改进。
此外,不同的芯片组可以在不同的工艺节点上制造,从而在满足性能和功耗要求的同时,最大限度地降低成本。
在系统层面,MTIA 400、450、500均采用相同的机箱、机架和网络基础设施。每一代新芯片都可以安装在相同的物理空间内,从而加快从芯片设计到生产部署的过渡。
Meta模块化、可复用的设计也最大限度地减少了开发和部署多代芯片所需的资源,而这些高度优化的芯片所带来的优势足以抵消开发和部署所消耗的资源。
2、推理优先
主流GPU通常是为最苛刻的工作负载大规模GenAI预训练而设计的,然后才被应用于其他工作负载,例如GenAI推理,而后者往往成本效益较低。
Meta采用不同的方法:MTIA 450和500首先针对GenAI推理进行优化,然后可根据需要用于支持其他工作负载,包括R&R训练和推理,以及GenAI训练。这使得MTIA能够很好地适应预期中GenAI推理需求的增长。
3、无摩擦采用
MTIA从一开始就基于行业标准的软硬件生态系统,如PyTorch、vLLM、Triton和开放计算项目(OCP),原生构建,而非将兼容性和可移植性视为事后考虑。
由于PyTorch起源于Meta,并已成为应用最广泛的机器学习框架,MTIA自然而然地采用了PyTorch原生架构。
PyTorch、vLLM和Triton共同为开发者提供了一套熟悉的软件栈,支持开源社区资源的复用,并简化了模型迁移。
除了行业标准的软件之外,MTIA的系统和机架解决方案也符合OCP标准,从而能够无缝部署到数据中心。
三、MTIA软件栈:一种基于PyTorch的原生方法
MTIA软件栈在所有芯片代际中都能提供一致的编程体验。它采用PyTorch原生架构,为开发者提供了一个熟悉且完整的生态系统。

该软件栈的关键属性包括:无缝模型部署、编译器、内核编写、通信与传输、运行时和固件、vLLM支持、生产工具。
Meta还构建了智能体AI系统来实现内核生成的自动化。
MTIA的通信库Hoot Collective Communications Library(HCCL)利用MTIA芯片内置的网络芯片实现高效通信,将集体操作卸载到专用消息引擎,并使用近内存计算来加速需要大量归约的集体操作。
为了确保数十万颗MTIA芯片在生产环境中可靠运行,MTIA提供与主流GPU同类产品相媲美的生产级监控、性能分析和调试工具,同时还提供跨主机和设备的全栈式、大规模可观测性,涵盖软件、固件和硬件层面等独特功能。
更多软件栈优化详情,可参见Meta博客原文。
指路:https://ai.meta.com/blog/meta-mtia-scale-ai-chips-for-billions/
结语:与时俱进,拓展AI推理边界
Meta预计最新的四代产品,包括近期发布或计划于2026年或2027年发布的产品,将进一步拓展GenAI推理的边界,实现R&R训练,并为未来的GenAI训练奠定基础。
每一代MTIA芯片都汲取了前代产品的经验,与Meta的软件栈协同设计,并以未来AI模型的发展轨迹为指导。
其模块化、多芯片设计和垂直整合的协同设计方法,能够在保持系统级兼容性的同时,实现快速且持续的性能提升。
来源:Meta
