








芯东西(公众号:aichip001)
作者 | 陈骏达
编辑 | 漠影
过去一年,国内GPU赛道风起云涌,多家创企相继登陆资本市场。步入2026年初,随着年报季正式开启,这些备受瞩目的企业陆续交出上市后的首份业绩报告。核心技术积累如何,业绩能否兑现,双重考验摆在眼前。
作为国内通用GPU赛道的重要玩家,天数智芯于今天披露了2025年业绩报告。财报显示,天数智芯全年营收达10.34亿元,同比增长91.6%;主营业务通用GPU产生的营收更是达到9.23亿元,同比增长149.6%。
天数智芯不仅在做大规模,更在改善经营质量。该公司去年录得5.58亿元毛利,同比增长110.5%,超过营收增速。其经调整净亏损收窄至4.38亿元,同比收窄32.1%。
在AI算力需求爆发的背景下,天数智芯这份成绩单意味着什么?我们可以通过拆解核心数据,看看这份财报的真实成色。
一、毛利增速超营收增速,产品已实现逾千项部署及应用
在天数智芯2025年的财务数据中,有一组数据尤其值得关注——营收增速达91.6%,毛利增速达110.5%,毛利的增速明显高于营收增速。
在资本市场中,这通常被解读为产品竞争力、定价能力增强,以及增长质量、业务健康度提升的信号。
那么,天数智芯猛增的营收、毛利,究竟从哪来?
首先值得关注的是通用GPU业务的整体增长。2024年,这块业务贡献营收约3.70亿元,到2025年已飙升至9.23亿元,同比大涨149.6%,占总营收近九成。通用GPU已经成为驱动天数智芯增长的绝对核心。
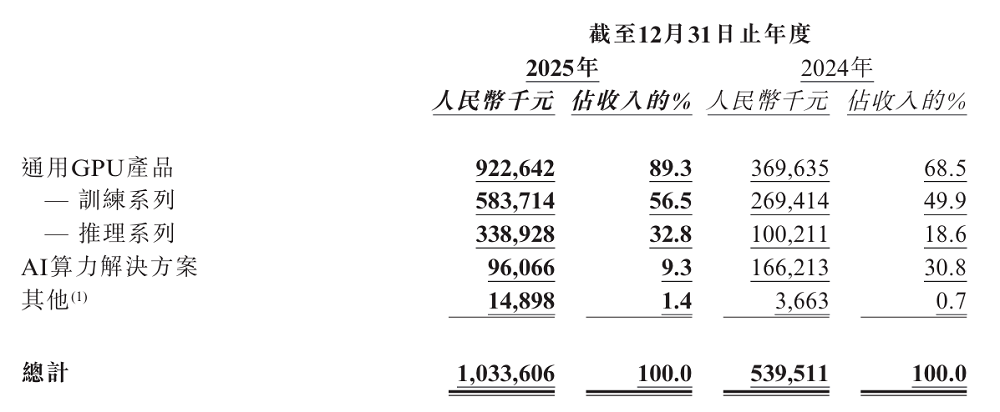
在通用GPU产品内部的细分营收也有分析价值。
在训练系列产品上,天数智芯录得5.84亿元营收,同比增长116.7%,证明了该系列产品在训练算力市场中已经形成一定的竞争优势。
在推理系列产品上,天数智芯实现了更高的增长。2025年,推理系列产品录得营收3.39亿元,同比飙升238.2%,对天数智芯总营收的贡献占比从18.6%大幅增长至32.8%。
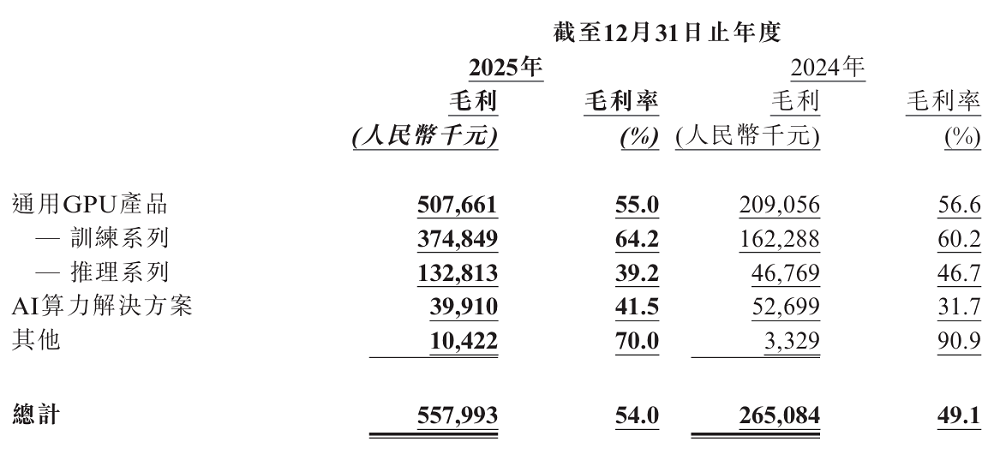
这组数据背后,是AI算力市场从训练向推理的重心转移。随着大模型应用落地加速,推理需求开始放量。天数智芯的推理产品能承接住这一波爆发式增长,说明他们已经提前卡位推理算力起飞的关键节点。
过去1年,天数智芯的商业化规模和市场认可度实现了明显提升。截至2025年底,天数智芯已累计服务超过340家来自不同行业的客户,其产品及解决方案已实现了逾1000项部署及应用,其中来自互联网、大模型、科研、金融、医疗保健、教育及运输等主要行业客户的项目数量持续增长。
天数智芯计划在2026年深化与领先互联网企业、AI模型公司、科研机构及行业标杆客户的合作,推动通用GPU产品及AI算力解决方案在更多关键场景的大规模应用。
他们还将切入更多垂直领域,扩展产品在智能驾驶、工业制造、泛智能终端、智慧农业等领域的应用。
这种“在已有领域做深、向新领域拓宽”的扩张策略,正助力天数智芯全面挖掘万亿级AI算力市场的增长潜力。
二、构建云、边、端一体化布局,软硬协同优化释放硬件潜能
业绩的增长与应用场景的拓展,离不开天数智芯在技术层面的长期积累。
2025年,天数智芯已构建起覆盖“训练+推理+端侧”的全产品矩阵,形成云、边、端一体化布局,是国内少数具备完整通用算力系统全方案能力的厂商。
训练侧,天数智芯已实现天垓系列两款产品——天垓Gen 1与天垓Gen 2的量产与销售,并发布了第三款产品天垓Gen 3,预计于今年第一季度量产。天垓系列搭载高性能计算核心与优化的内存配置,专为大规模模型训练设计,具备持续迭代的计算密度与内存带宽能力。
推理侧,天数智芯已推出智铠Gen 1及Gen 1X两款产品,下一代智铠产品的研发亦在稳步推进,后者将进一步扩大对低精度数据类型及混合精度计算的支持,契合当前AI行业从“堆参数、堆算力”向“效率驱动”转型的趋势。
同时,天数智芯还紧跟设备端AI开发趋势,引入了面向机器人及智能终端的彤央系列端侧计算产品。该系列产品在计算机视觉、自然语言处理等任务上,其测得性能达到国际领先产品的两倍。
然而,光有硬件并不足以构建完整的算力基础设施。为了让算力真正好用、易用,天数智芯通过软硬协同优化,将硬件潜力转化为实际业务价值。
以当下备受关注的PD分离技术为例,这一技术正凭借算力资源解耦、按需配比、优化总体拥有成本的优势,获得不少企业青睐。
在这一背景下,天数智芯在GPU中设计了专门的IX并行任务处理模块,使计算任务与通信任务(如KV缓存传输、多路多流等)可并行执行而不互相冲突。
这一设计直击PD分离架构的核心痛点,也就是Prefill与Decode节点间的KV缓存的传输开销控制问题。
类似的创新还体现在多个维度。
天数智芯搭载无损量化技术的大模型加速工具包,可在不损失精度的前提下,实现长文本处理效率提升50%、算力利用率提升60%。
针对MoE大模型并行训练,自研通信库使跨节点通信效率提升30%,为大规模模型训练提供了更好的扩展性。
天数智芯推出的全新软件开发平台原生兼容主流GPU编程模型,代码迁移效率提升80%以上,算子适配可在几分钟内完成,大幅降低用户使用国内算力的门槛。
正是这些软硬件层面的系统性创新,让天数智芯在算力效率、部署成本、应用体验等关键维度上构筑起差异化优势。
三、“造出芯片”之后,国内GPU如何“长出生态”?
对于国内GPU厂商们来说,除了不断迭代技术之外,另一条重要的核心战线就是打造生态。
过去一年,国内大模型层出不穷,不少国内GPU厂商纷纷开启“竞速模式”,强调对新模型、新算子的“Day0”适配。这种紧迫感恰恰说明,生态兼容性已成为衡量芯片商业价值的核心指标之一。
天数智芯在适配国内AI生态方面,已形成两条清晰的主线。
一方面,天数智芯充分利用开源AI的活力,依托DeepSpark开源社区,已成功适配超过610个主流算法模型,具备新模型Day0原生支持能力,逐步构建起覆盖AI与通用计算多领域的模型适配体系。
未来,天数智芯还计划持续加大全维度开源生态与开发者体系建设投入,推动“百大应用开放平台”升级,加速应用规模化落地。
另一方面,天数智芯不断深化与产业链上下游的协同合作,与CPU厂商、服务器整机厂商、行业ISV以及云服务提供商展开深度联动,通过项目共建整合产业资源。
这些生态布局的意义,不仅在于适配更多模型,更在于构建长期竞争壁垒。
生态建设本身是一项系统性、长期性的工程,涵盖算子优化、框架兼容、工具链完善以及开发者社区运营等多个层面,难以一蹴而就。但一旦形成规模与体系,就能够帮助企业建立起“硬件+软件+生态”的全栈能力,显著提升客户粘性与迁移成本,从而形成可持续的竞争优势。
更重要的是,在国内技术生态持续完善的背景下,这种生态能力已不再只是企业层面的竞争筹码,也正逐步成为推动国内通用算力体系高质量发展的关键基础设施,有助于降低对海外技术栈的依赖,增强产业链整体的自主可控能力。
随着AI行业迈入推理需求飞涨、Agent等新应用形态加速落地的新周期,市场对低延迟、高并发计算能力的需求正快速提升,催生万亿级别的市场空间。
在这一轮产业演进中,兼具训练与推理能力的通用GPU拥有广阔的应用场景。而天数智芯作为国内首家实现通用GPU量产的厂商之一,已在该方向完成前瞻布局,有望吃到行业爆发式增长的红利。
结语:长期主义者,逐渐步入收获期
在首份年报中,天数智芯披露了未来的技术规划。在训练产品线上,公司将提升产品的计算密度、内存带宽和集群扩展性,以应对大规模训练需求;推理产品则将针对从边缘到云端的多元推理场景,着重优化成本性能效率、延迟及吞吐量。
可以预见,随着AI应用的全面爆发与国内算力体系的不断成熟,具备全栈能力与生态优势的厂商将在新一轮竞争中占据更有利的位置。而天数智芯过去十余年在通用GPU赛道的长期投入,也有望在行业加速发展的过程中,逐步转化为实际的市场回报。
