








智东西(公众号:zhidxcom)
作者 | 江宇
编辑 | 漠影
大厂AI战局升温,转型几乎成为共识。模型在进化,Agent在落地,但成本高、落地难、数据不够,行业还在补课。
而京东在AI上的布局已然聚焦清晰:围绕供应链优势,推进具身智能,让AI真正进入物理世界。此次推出的一体化图像模型——JoyAI-Image-Edit,高度适用于生成电商、具身智能训练图片。
近日,京东开源图像模型JoyAI-Image-Edit,将空间智能纳入图像理解与编辑,让AI开始处理真实世界中的空间关系,让模型真正“理解空间,编辑空间”。
简单解释,这是一个以空间智能为核心的图像生成与编辑模型,让AI真正“看懂”三维空间,从而让生成更合理、编辑更精准。

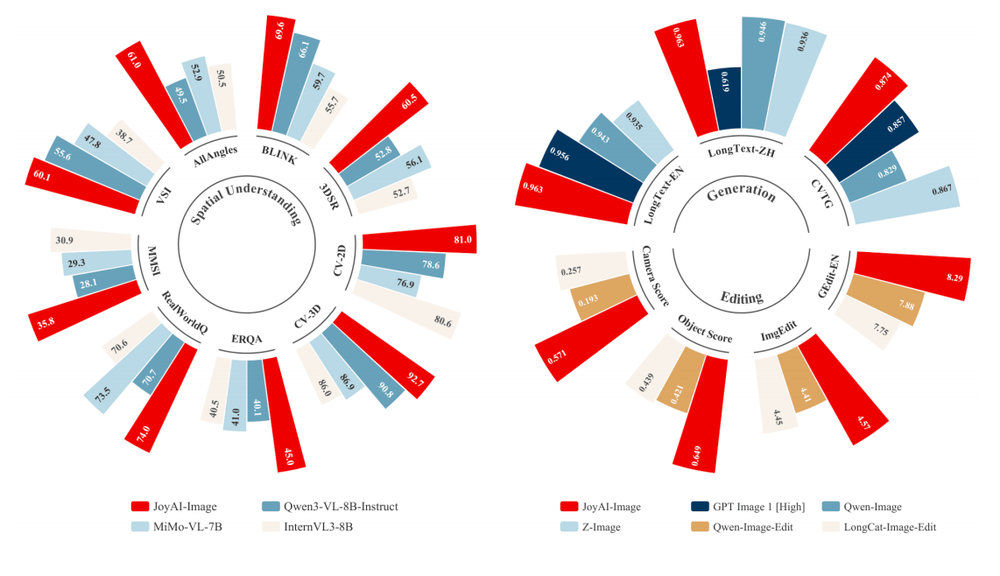
从公开评测来看,JoyAI-Image-Edit各项指标显著领先,迈进了国际第一梯队:空间理解刷新同量级开源模型SOTA,达到世界一流水平,大部分指标媲美或超越闭源模型 Gemini 2.5 Pro。长文本生成中英文双语领先,图像编辑能力全面覆盖,空间编辑精度甚至超过部分视频世界模型。
智东西也实测了一番,在物体位置调整这类场景中,模型能够稳定保持结构一致性。
值得注意的是,此番调整的物体在画幅中仅占据很小比例,且原物体并非形状规则,为毛绒材质,并带有手部细节。即便如此,模型在移动或旋转时仍能有效减少透视错乱与遮挡问题,画面整体保持自然。

▲输入图与指令(左)、输出图(右)
进一步看,这类能力的主要落点,在电商内容生产与具身智能训练这两类场景尤为适配,进而也能延展到建筑设计、游戏开发和影视制作等场景。电商和具身,恰好与京东现有的AI布局形成了直接呼应。
一、把“空间智能”写进模型:从“会改图”到“会动空间”,图像编辑能力开始分层
传统图像编辑模型的短板集中在空间层。语义能跟上,但空间关系容易崩,例如替换物体、修改姿态时,常出现比例失真、遮挡错误、光影不一致等问题,本质是缺乏几何层面的理解能力。
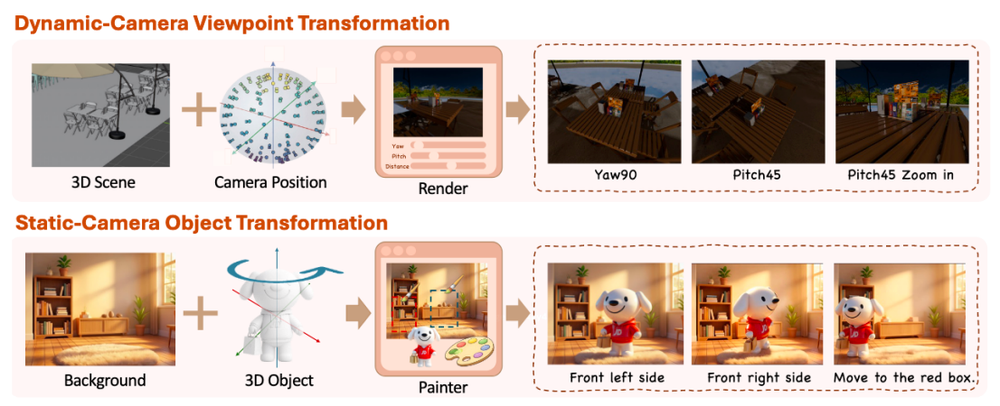
JoyAI-Image-Edit则把“空间编辑”单独拉出来做能力核心。模型在支持15类通用编辑任务之外,进一步支持物体移动、旋转、视角变换等空间级操作,并可理解“移动0.3米”“旋转45度”等具备明确几何参数的指令,让编辑过程具备“可控性”。
在能力结构上,模型还采用MLLM+VAE+扩散模型(MMDiT)的统一架构。
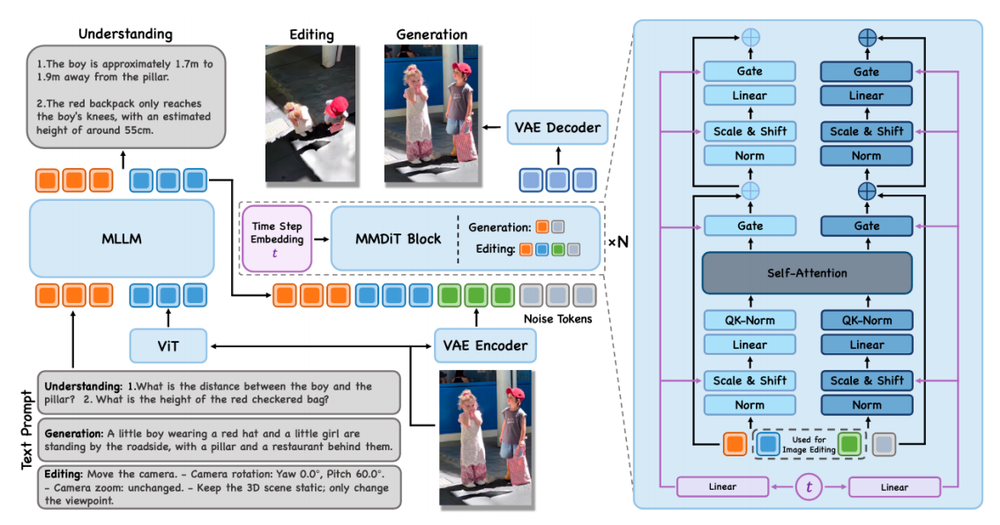
具体来说,MLLM负责空间理解与语义建模,扩散模型执行生成与编辑,空间信息直接参与生成过程,形成“理解—生成—再理解”的循环。
空间能力是怎么提升起来的?答案在于数据体系的重构——包括300万规模的OpenSpatial-3M数据集、多视角生成数据,以及可记录精确位姿参数的空间编辑数据。这些数据引导模型在训练阶段学习真实几何关系。
得益于这种设计,在2D语义感知、3D空间理解、4D时空推理三个层级共13项Benchmark上,JoyAI-Image-Edit在9项空间理解Benchmark上均取得显著提升,平均分达到64.4,追平闭源的Gemini-2.5-Pro。
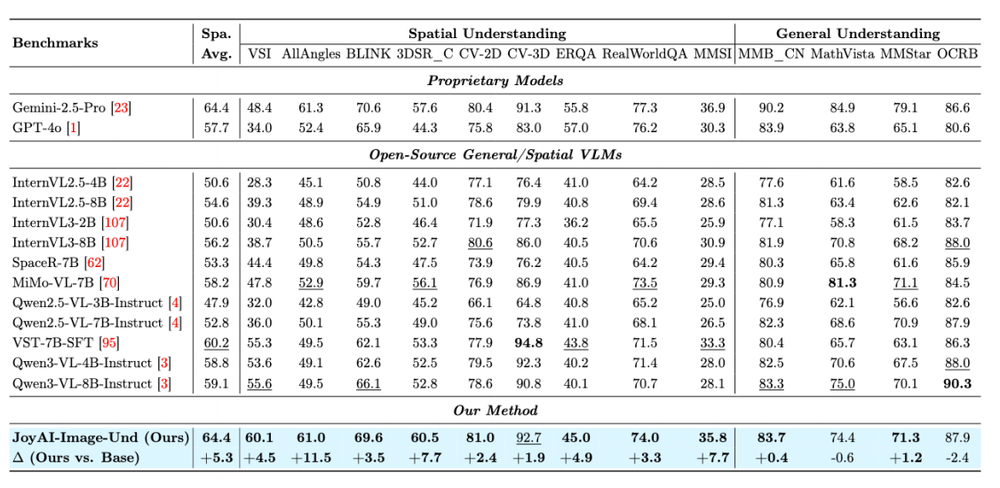
在SpatialEdit-Bench上,JoyAI-Image-Edit的空间编辑能力表现尤为突出:Object Overall Score为0.649、Camera Overall Score为0.571,大幅领先所有图像编辑模型,空间编辑精度超越Veo3.1、ViduQ2-Turbo和Kling等视频世界模型。
与此同时,在业界权威的榜单GEdit(偏向中文指令评测和真实用户需求)和ImgEdit(偏向全面覆盖的能力评测,强调推理和精细化编辑能力)上,JoyAI-Image-Edit得分分别为8.27和4.57,刷新开源图像编辑模型SOTA。
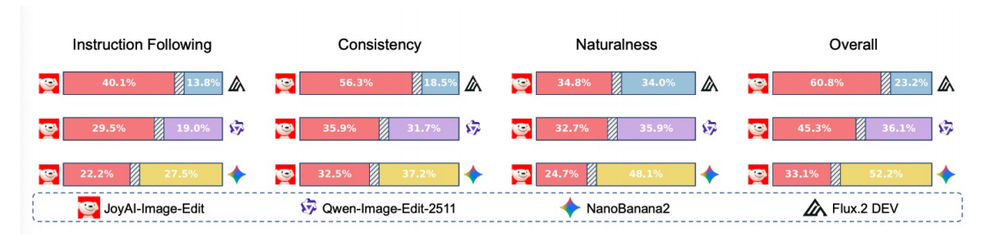
▲在249道评测集黑盒人工评测成绩:JoyAI-Image-Edit表现优于Qwen-Image-Edit-2511以及Flux2.Dev

由此可见,将空间理解、生成和编辑整合在同一体系,可以使模型不仅知道“画什么”,还知道“物体在什么位置、如何变化、是否合理”。
当图像可以被真正“操作”,而不只是简单修改时,图像模型的能力边界也随之被重新定义。
二、电商+具身场景高可用,空间能力开始直接“变现”
空间能力成立以后,最先吃到红利的,就是最依赖“真实世界”的场景。
在电商领域,商品多视角生成、虚拟试衣、商品摆位调整等任务对空间一致性要求极高。
JoyAI-Image-Edit的空间编辑能力——可以移动物体、旋转角度、调整视角,并理解具体几何参数——在电商场景下带来了非常直观的应用价值。
比如服饰和鞋类商品,经常需要展示不同角度、姿态或搭配组合。使用该模型,可以在原始图片基础上一键调整衣服折叠角度、鞋子摆放方向或包包手持位置,生成多角度素材,同时保持整体比例、光影和背景一致。

▲输入图(左)、输出图(右)、指令:Rotate the sneaker to show the front view
类似地,对于家电、家具或小型电子产品,空间编辑可让商品在不同场景下“自动换位”或旋转展示,如沙发在不同房间角度、咖啡机在不同台面布局,无需重拍,就能生成多角度素材。

结合模型的通用编辑能力,还可以同时进行文字标注、色彩微调和背景修饰等“一键精修”式功能,实现一次操作完成多种需求。

这样,电商团队能够快速产出多角度、精修、高可用的商品图,大幅降低拍摄成本,同时保证展示效果的统一。
在具身智能训练中,这些能力同样适用。
机器人依赖大量真实世界数据,但采集成本高、周期长。该模型可以生成具备空间一致性的高质量图像数据,用于补充训练数据,与真实采集数据形成互补,从而提高训练效率和模型效果,辅助解决具身行业的数据难题。
此外,通过生成新视角辅助空间推理(Thinking with Novel Views),模型不仅用于内容生产,也能反向提升空间理解能力,为机器人“看懂世界”提供支持。
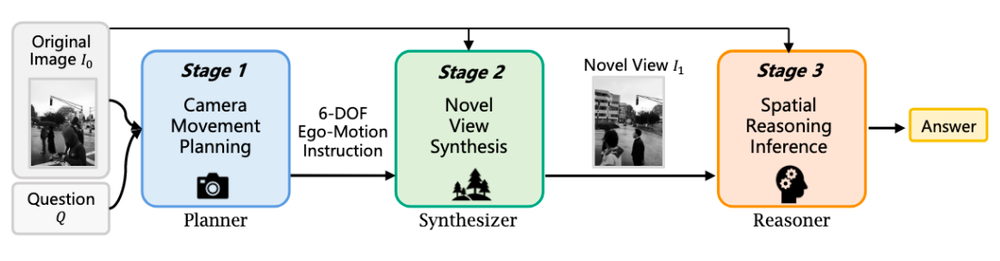
由此可见,无论是电商还是具身智能,本质都依赖空间理解能力,而JoyAI-Image-Edit正是最直接落地的工具。
三、开源模型亮相,AI全景布局浮现端倪
这次开源JoyAI-Image-Edit显然是京东聚焦于走向实体世界这一宏大AI布局的一部分,但通过观察可以发现,开源并不是它唯一的动作。
除了这一模型,京东不久前还开源了JoyAI-LLM Flash模型,能力上在同等参数规模下显著提升了性能与效率,降低开发者使用门槛,避免单纯的参数规模竞争。
与此同时,京东在供应链和线下场景中的动作也在悄然推进:一方面,建设全球最大的具身智能数据采集中心,结合模型生成能力进行训练,为数据难题提供了新的解法;另一方面,通过JoyInside将AI能力嵌入家电、机器人、AI玩具终端,让模型直接落地真实环境,和用户产生大量深度交互。
从开源模型的应用和这些场景动作结合来看,可以明显感受到京东在模型、数据和终端之间尝试形成闭环。
开源或许只是早期的一步,而京东在产业场景中不断深挖AI实践与价值,则让我们得以观察到其AI能力的潜在落地路径。
结语:京东一手开源,一手落地
从JoyAI-Image-Edit这次开源动作可以看到,京东在AI上的选择很明确:一手开源,一手落地。
在模型侧,持续开放能力,把门槛降下来,让更多开发者可以直接用起来;在场景侧,把AI嵌入供应链、物理世界、真实产业场景,从数据、模型到终端形成闭环,让能力在真实环境中跑通。
可见,京东的AI战略更为务实。
供应链是京东最硬的一张牌。在AI时代,这张牌的价值进一步放大——模型可以嵌入商品、物流与设备,数据可以持续回流,能力可以不断迭代。
在今天,AI有望成为京东的另一张“增长引擎牌”。
注:文中部分输入图来源于Arena
