








机器人前瞻(公众号:robot_pro)
作者|葛文婷
编辑|漠影
机器人前瞻4月16日报道,昨天,BeingBeyond(智在无界)正式发布了其第三代旗舰模型Being-H0.7。
该模型使用了20万小时的人类行为视频进行训练,并提出了一种全新的范式——基于潜空间推理的世界模型。
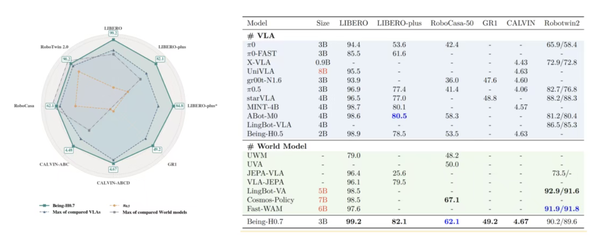
在6项国际权威评测中,H0.7斩获综合全球第一,其中4项任务登顶榜首。
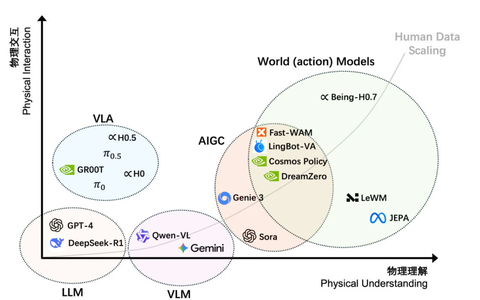
同时,H0.7也是全球首个覆盖跨本体、跨场景、连续动态、流体、柔性物体、物理规律与上下文推理七大关键维度的通用世界模型。
智在无界2025年5月成立于北京,是一家专注于具身智能基础模型研发的公司,由北京大学计算机学院长聘副教授卢宗青创立。该公司的核心目标是打造一个能够跨平台、跨本体的通用“机器人大脑”,并通过大规模人类行为数据预训练,让机器人获得理解物理世界并执行复杂任务的能力。
该公司认为,一个理想的世界模型应同时具备物理世界理解与物理交互两项核心能力。
主页链接:https://research.beingbeyond.com/being-h07
论文链接:https://research.beingbeyond.com/projects/being-h07/being-h07.pdf

一、不再显式生成未来画面,而是提炼真正影响未来行动的关键信息
智在无界认为,Being-H0.7应该学习一种类似“直觉”的快速判断机制。
因此,Being-H0.7选择了一条不同路径:模型不需要像画图一样,把未来的场景一笔一笔画出来,而是去提炼那些真正影响未来行动的关键信息。
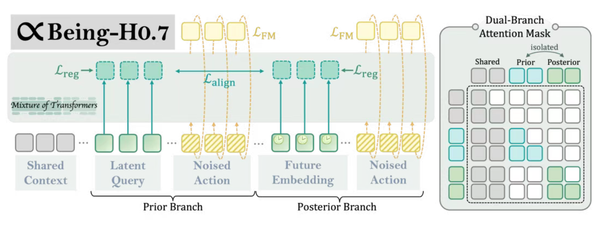
Being-H0.7在模型内部设置了一组可自主学习的中间变量作为预留的“思考空间”。在运行时,模型会把当前观察到的场景、任务目标以及对未来发展趋势的判断统一压缩到这一空间中进行整合推理,再据此生成最终的执行动作。
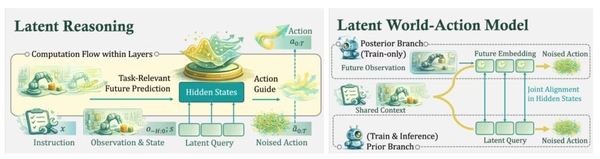
但这个“思考空间”本身并不能直接预判未来。为此,Being-H0.7采用了双路径结构:
- 一条路径在已知未来结果的情况下训练,帮模型学会哪些判断对决策真正有用;
- 另一条路径则模拟真实场景,在看不到未来的前提下,仅依靠当前观察做出判断。
不同于其他模型简单地把未来信息直接灌给系统,H0.7选择让两条路径共享核心信息,并让这两种视角不断对齐、互相约束:一条提供未来的参考标准,另一条严格遵守现实信息。
通过持续学习,模型能够慢慢在“思考空间”里学会根据当前的情况,自动推理出对后续行动最有价值的信息。而这种能力,其实就是智在无界想要打造的、类似人类直觉的能力。
此外,智在无界还构建了一个长达20万小时的人类行为视频数据集,并以此训练Being-H0.7,让Being-H0.7具备“常识”,从而能够真正理解世界和在真实世界中发挥作用。
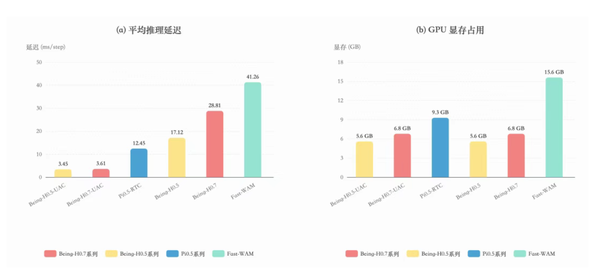
对比Cosmos Policy这类依赖视频生成的世界模型,H0.7的训练成本不到其1%,推理速度却达到了Fast-WAM的11倍,比imagine-then-execute这类生成式世界模型快了40多倍。
凭借这种快速的推理能力,它能快速感知外界动态,完成此前多数模型难以实现的任务,比如预判滑落小球的轨迹、高速流水线包装、精准倾倒液体等。
二、全球六项权威评测登顶,具备复杂协作与高精度物理交互能力
在评测方面,Being-H0.7在全球6项权威评测榜单上综合排名世界第一,是目前覆盖范围最广的具身世界模型。
在跨本体、跨场景、连续动态、流体、柔性物体、物理规律与上下文推理七大关键维度上,Being-H0.7均展现出领先的物理理解与泛化能力,它能够完成复杂的多物体协作、长时序规划与精细物理交互任务。
为直观展现Being-H0.7“思考空间”里的有效信息,研究人员把机器人当前“看到”的画面,和模型内部已经学到的常识相融合,通过视频模型对任务的后续状态进行了可视化呈现。
虽然Being-H0.7在实际运行时不会像放电影那样,一帧一帧地、精确地把未来每一秒的画面都生成出来,但它脑子里已经“隐约知道”接下来会发生什么,这正 “隐式具身世界模型”的核心特点。
依托这套世界模型架构,Being-H0.7实现了更精准的空间感知、物理规则理解与运动逻辑推理能力,具体体现在以下几类物理交互与理解能力上:
1、动态轨迹预测:在高速动态场景下,Being-H0.7借助物理世界知识和快速推理,能够预测物体轨迹并精准完成物理世界交互。

2、物理规律理解:Being-H0.7通过大规模预训练构建了丰富的世界知识,能够准确理解流体物理规律并完成复杂任务指令。

3、运动推理能力:Being-H0.7具备物理世界下的动力学推理能力,能够准确推理物体交互后的空间方位并规划好动作。

基于以上3种能力,Being-H0.7能够完成高速运动物体追踪和接取、精细流体控制、柔性物体交互等高难度任务。

结语:模型不能只学会理解世界,还要会改变世界
图灵奖得主LeCun曾提出:“打造能理解真实世界的智能系统。”这一行业愿景。
对此,BeingBeyond的创始人卢宗青给出了更为深刻的延伸:理解世界不够,必须学会改变世界。
在他看来,物理世界的理解与交互本就不可分割,若一个模型只专注于学习“世界会变成什么样”,却忽略了“采取什么行动会导致这种变化”,那它本质上仍只是一个被动的观察者,终究会陷入“缸中之脑”的局限,难以真正成为能与世界互动的智能体。
这并非对LeCun愿景的否定,而是对其的补充,尽管“如何让模型真正内化人类物理直觉”等行业命题仍需探索,但是BeingBeyond的这次探索,已然为具身智能的前行点亮了一盏实践的明灯。
