








智东西(公众号:zhidxcom)
作者 | 陈佳
编辑 | 程茜
智东西4月15日报道,今日,百度文心大模型团队正式开源文生图模型ERNIE-Image,其参数规模仅8B,可在显存24GB的消费级GPU上运行。该模型在GenEval、OneIG等多项国际基准上综合得分位居开源模型第一,尤其在文字渲染能力上,与Nano Banana等商业闭源模型同处第一梯队。
同步开源的还有ERNIE-Image-Turbo版本,其推理步数从标准版的50步压缩至8步。
两款模型的权重与推理代码已全部上传至Hugging Face,遵循Apache 2.0协议,ComfyUI工作流模板也已同步上线,开源量化方案由模型加速工具链Unsloth合作提供GGUF格式支持。
ERNIE-Image采用单流DiT架构,并内置提示词增强(Prompt Enhancer)模块,可将简短输入自动扩展为结构化描述再进行生成,提升指令理解与细节控制能力。
▲百度ERNIE-Image开源代码仓库页面,并已获得78颗星(图源:GitHub)
智东西用六组提示词对该模型Turbo版本进行了实测,从实际体验来看,ERNIE-Image-Turbo在处理复杂画面时表现稳定,比如多物体按照提示词要求摆放、图表生成、光影效果这些的任务基本都能做到位,但涉及复杂文字、多语言内容或人物关系这种更精细的要求,就容易出现写错字或理解偏差的问题。
技术Blog:https://ernie.baidu.com/blog/zh/posts/ernie-image/
体验平台:https://aistudio.baidu.com/ernieimage
Hugging Face:
https://huggingface.co/baidu/ERNIE-Image
https://huggingface.co/baidu/ERNIE-Image-Turbo
一、六组高难Prompt实测,多主体与图表生成表现良好
我们用六组提示词对ERNIE-Image-Turbo做了测试,覆盖高密度多语言文字渲染、多语言混排、漫画分镜叙事、数据图表生成、多主体空间控制和光影人像六个维度。六组全部单次生成,未经重试筛选,所有图均为原图直出。
整体感受是,该模型多主体空间关系控制、数据图表生成和光影细节还原这几项能力表现不错,但碰到高复杂度文字渲染,踩坑比预期要明显。
1、生僻汉字渲染,“鬱”字没能过关
第一组想看的是,这个模型能不能在图像里准确写出笔画复杂的生僻字,尤其是形近字。
该模型在宣纸水墨背景、楷体风格与红色 “文心” 印章这些视觉氛围营造上均还原到位。
但在文字精确生成上存在明显失误,我们指定的第一行是“鬱鬱蔥蔥”(yù yù cōng cōng),生成出来变成了“糲糲萬蕙”,完全不是同一个字。第三行的生僻字“赢麟龑靐”(yíng lín yǎn bìng),生成结果是“赢麟頃䫧”,“龑”和“靐”这两个高复杂度字直接被换掉了。三行里只有第二行“薛蟠贾雨村”字形结构没有问题。

2、中英日韩四语混排,英文丢了个字母
中英日韩四语混排测试里,整体呈现和提示词要求基本对得上,版式、风格没什么大问题。但仔细看会发现,第二行的“Knowledge”明显少写了一个字母“e”,第四行的韩文也和指定的“지식에는 경계가 없다”有出入。

我们随后加大了难度,要求该模型把四种语言以极小字号清晰呈现、笔画无锯齿、严格网格对齐。结果图里出现了乱码、字符变形和内容篡改,多处文字直接无法识别,指定的技术参数和评测数据没有一个完整还原出来。

3、漫画分镜实测,角色搞反了
这一组测试同时考三件事:多面板布局、角色跨格一致性、气泡里的文字渲染。
生成图片的布局和风格表现不错,两行三列的均等分镜结构完整,格间分隔清晰,角色外观在六格之间保持了一致性。但剧情出了岔子,第二格设定的是学生举手提问,气泡内容是“老师,这是什么意思?”,生成出来变成了教授举手,气泡也跟着配在了教授身上,互动主体完全反了。该模型在语义上出了理解偏差。

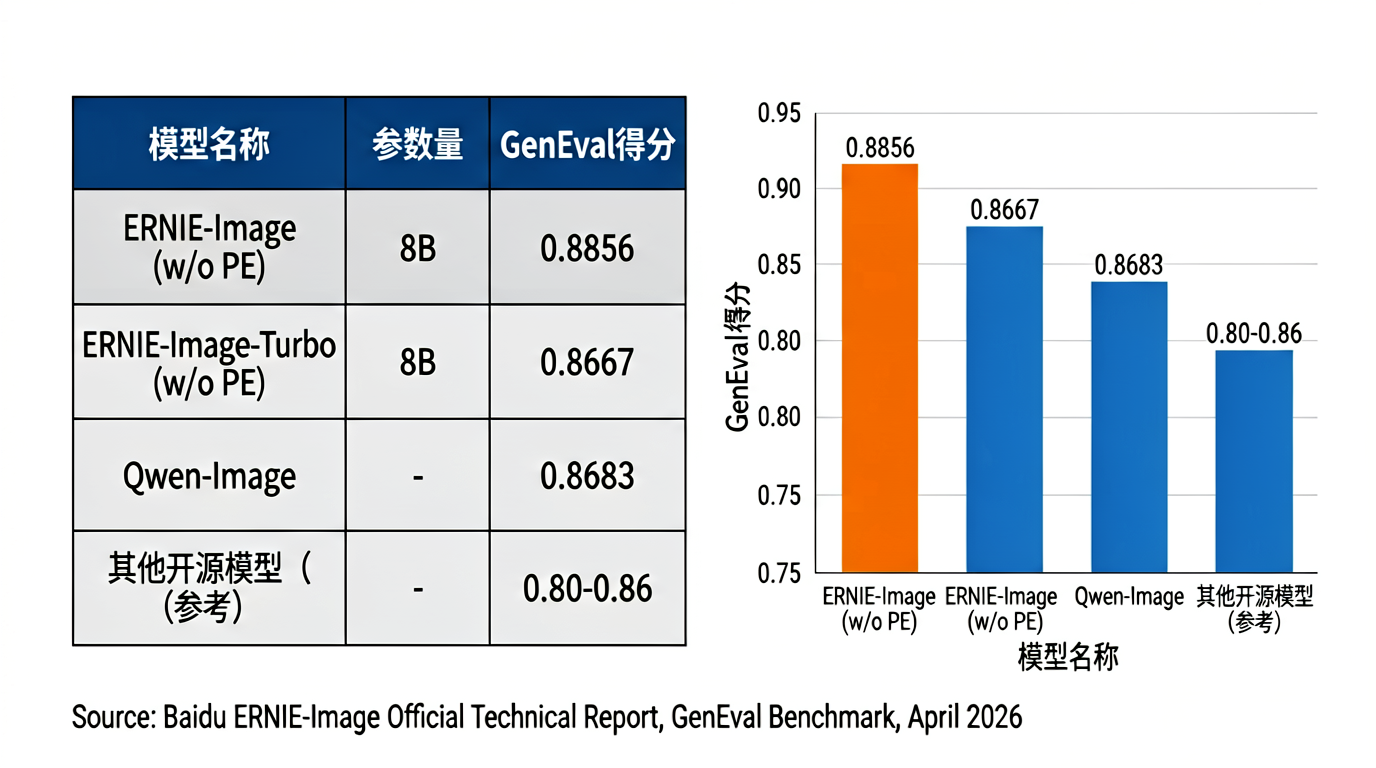
4、生成数据图表,细节基本准确到位
这一组测的是能不能该模型按指令生成结构严谨的表格和可视化图,数字和标签准不准。
这组表现比预期好。表头“模型名称”“参数量”“GenEval得分”清晰无误,填入的模型名称、8B参数量,以及0.8856、0.8667等具体得分都没有遗漏或改错。右栏条形图的配色规则也严格执行了,橙色高亮ERNIE-Image (w/o PE),蓝色呈现其余模型,Y轴的0.75到0.95区间准确,条形顶部数值标注和表格完全一致。唯一的小瑕疵是X轴第二个模型名称漏掉了“Turbo”。
5、七件物品测多主体空间控制,位置关系对得很准
这组测试要求该模型严格控制七个物品的位置、尺寸、遮挡关系,在一张写实俯拍桌面照里把它们放对地方。
这是六组里最让人满意的一组,七个指定物品全部按要求出现,且核心位置关系没有乱:翻开的精装书在画面正中,左页手写批注“此处存疑”、右页英文印刷句都清晰可读;黑色细框眼镜压在书本左上角;白色陶瓷咖啡杯在书本右侧,心形拉花形态自然;一元人民币硬币在咖啡杯右侧;黄色便利贴贴于书本正下方,手写“deadline:4月20日”内容准确;钢笔放在桌面左下角,笔尖朝向书本,全程无人物入镜。空间逻辑自洽,没有出现物品叠错或位置串行的情况。

6、伦勃朗布光,光影执行到位
最后一组想测的是,在给出高度具体的光影、材质和色彩指令后,该模型会不会自行简化内容。
结果是,该模型严格执行了指令:画面采用伦勃朗布光,主光来自左上方45度角,右侧脸颊的三角形光斑清晰可辨,轮廓规整;右侧完全无补光,仅靠少量环境反光勾出轮廓;背景纯黑,无纹理;肤质写实,毛孔可见,无磨皮痕迹;深色高领毛衣领口处的编织纹理也还原出来了。
二、国际基准评测成绩单,文字渲染在开源模型里拿第一
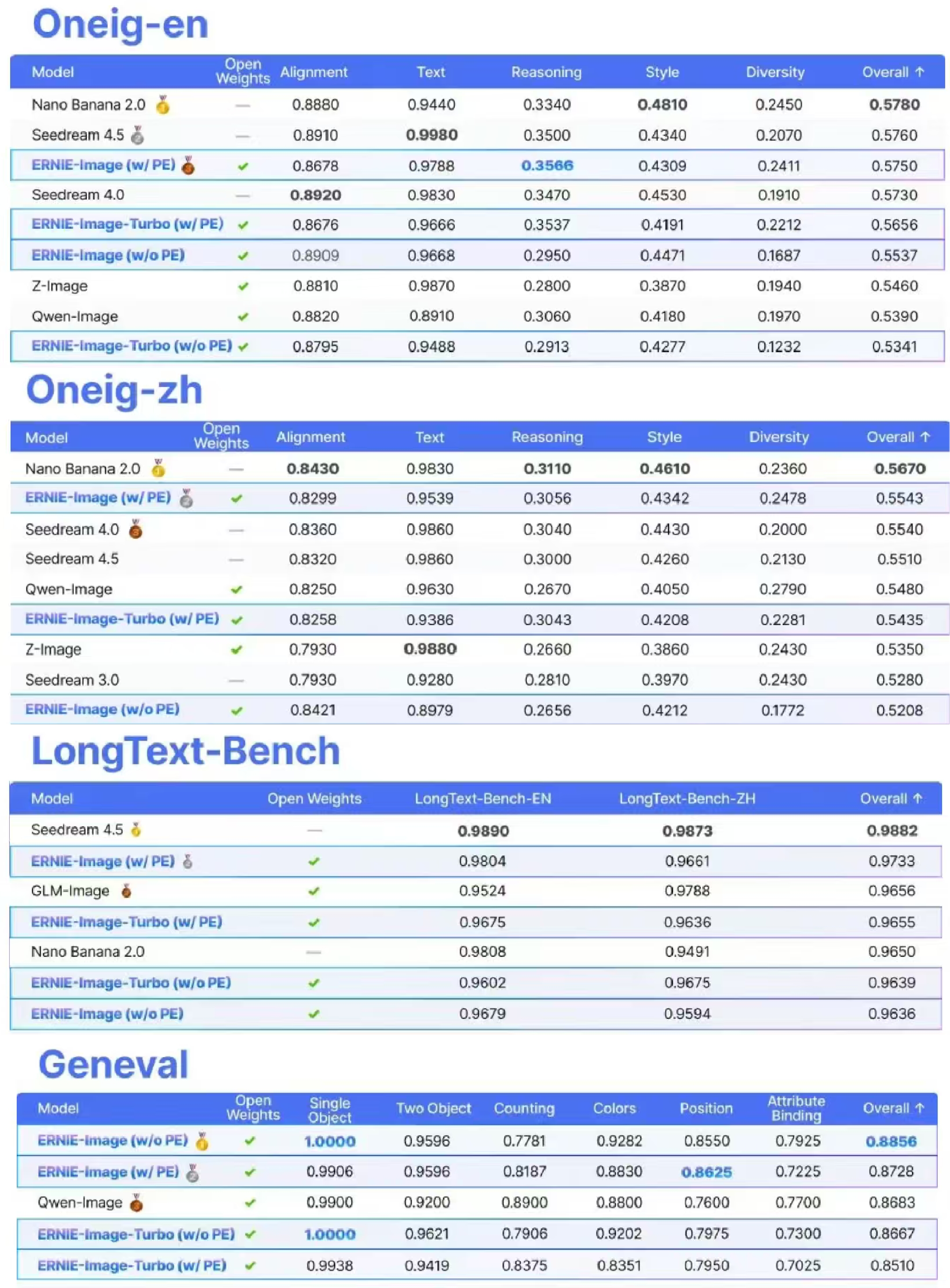
百度在三个国际公开基准上对ERNIE-Image进行了系统评测,分别是衡量通用图像生成能力的GenEval、覆盖中英文双语场景的OneIG,以及专门测试高密度文字渲染的LongText-Bench。
在衡量通用图像生成能力的GenEval测试中,ERNIE-Image(不启用PE)综合得分为0.8856,在所有参测模型中排名第一,超过Qwen-Image(0.8683)和FLUX.2-klein-9B(0.8481)。
 ▲GenEval专业文生图模型评测基准(图源:百度ERNIE-Image技术报告)
▲GenEval专业文生图模型评测基准(图源:百度ERNIE-Image技术报告)
OneIG英文榜上,ERNIE-Image开启PE后综合得分0.5750,仅次于Nano Banana 2.0(0.5780)和Seedream 4.5(0.5760),位列第三,同时在推理维度单项排名第一(0.3566)。
 ▲OneIG-EN,评估文生图模型在英文提示词场景下综合生成能力的量化评测体系(图源:百度ERNIE-Image技术报告)
▲OneIG-EN,评估文生图模型在英文提示词场景下综合生成能力的量化评测体系(图源:百度ERNIE-Image技术报告)
中文榜上,ERNIE-Image开启PE的综合得分为0.5543,同样位列前两名仅次于Nano Banana 2.0,还在多样性维度上跑出了0.2478的最高分。
 ▲OneIG-ZW,评估文生图模型在中文提示词场景下综合生成能力的量化评测体系(图源:百度ERNIE-Image技术报告)
▲OneIG-ZW,评估文生图模型在中文提示词场景下综合生成能力的量化评测体系(图源:百度ERNIE-Image技术报告)
文字渲染专项LongText-Bench是最能体现ERNIE-Image差异化能力的榜单。英文维度上,ERNIE-Image开启PE得分0.9804,中文维度0.9661,综合均分0.9733,在所有开源模型中排名第一。对比来看,Nano Banana 2.0综合均分0.9650,Qwen-Image为0.9445,Z-Image为0.9355。
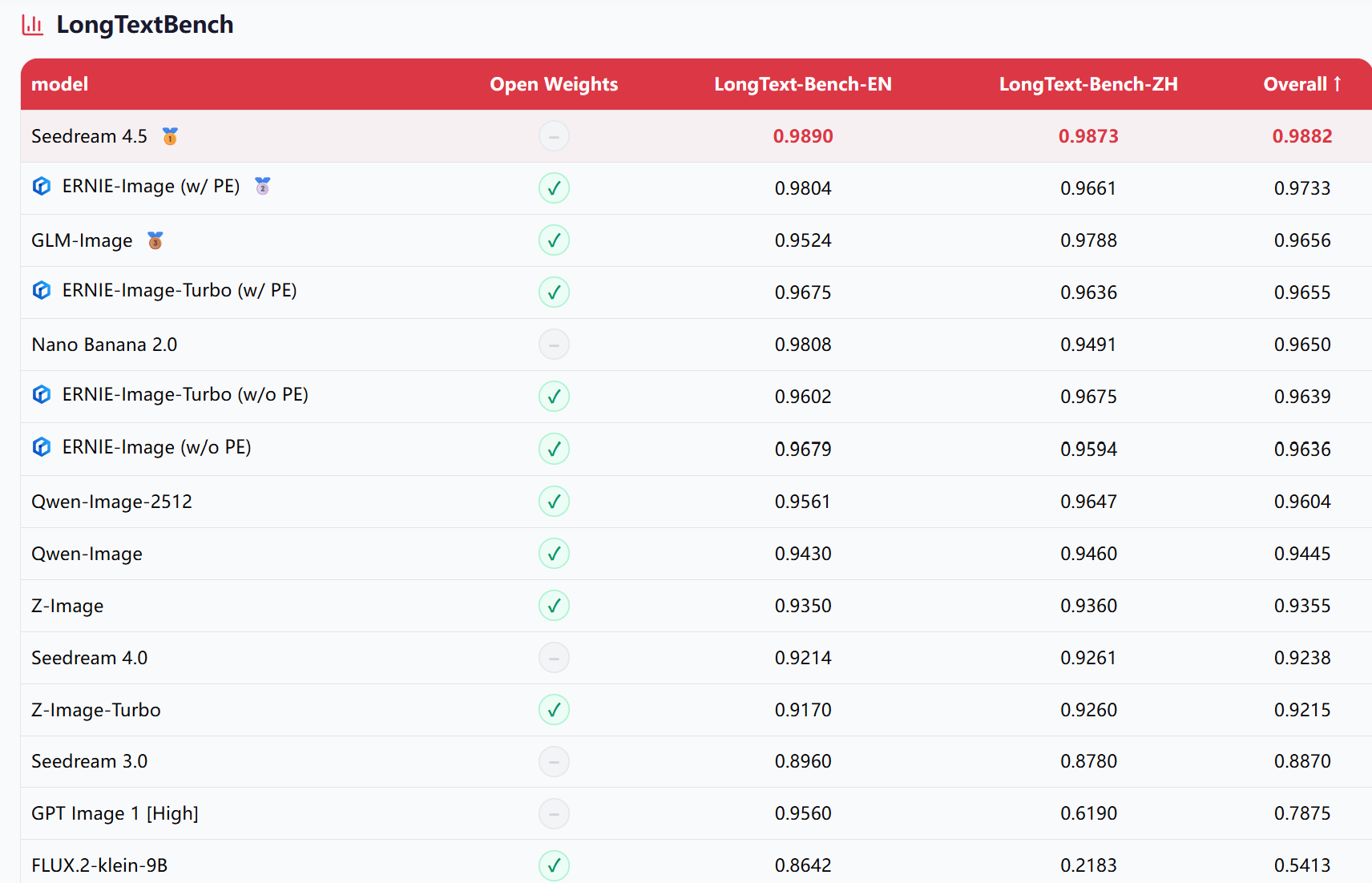
▲LongText-Bench,专业文生图长文本评测基准(图源:百度ERNIE-Image技术报告)
三、架构轻量、部署门槛低,8B参数跑进商用模型射程
ERNIE-Image的核心架构是单流Diffusion Transformer(DiT),并内置一个轻量级提示词增强器Prompt Enhancer(PE)模块,负责将用户的简短文字输入自动扩展为更丰富、结构化的详细描述,再送入DiT主干生成图像。
该模型的参数规模仅8B,这在开源文生图领域属于中小体量,但百度称在参数效率优化上做了大量工作,使运行门槛降至24GB显存的消费级GPU,显著低于此前同精度水平模型的部署要求。对照部分大参数开源模型的运行需求,ERNIE-Image这一设计的意义在于,个人创作者和中小团队无需购置专业工作站即可本地部署。
两个模型版本在调用方式上有所区别:标准版ERNIE-Image推理步数为50步,CFG(分类器自由引导)值为4.0;Turbo版由DMD和强化学习联合优化,推理步数降至8步,CFG降至1.0,牺牲少量精度换取速度提升。
在工程部署上,百度同时提供了两种集成方案。第一种是通过Hugging Face的diffusers库直接调用,只需几行Python代码即可完成推理;第二种是通过推理框架SGLang部署服务端,并支持将PE模块单独剥离,用vLLM单独运行以加快提示词扩展速度,DiT主干与PE各占独立端口,适合对延迟敏感的线上场景。此外,AI-Toolkit已支持对ERNIE-Image进行微调训练,为有个性化需求的开发者提供了完整的训练-推理链路。
结语:文生图再进阶,从“能出图”走向“可控生成”
如果把文生图模型的发展拆开看,过去一段时间的进步主要集中在“画得更像”,但在复杂结构控制、规则执行和文本表达上一直不稳定。
此次ERNIE-Image的实测结果显示,多主体位置关系、图表结构、分镜布局和光影条件这类“强约束任务”已经可以较稳定完成。未来,谁能先解决文本与语义一致性问题,谁才更有可能真正进入设计、内容生产等高要求场景。
