








智东西(公众号:zhidxcom)
作者 | 刘煜
编辑 | 陈骏达
智东西5月29日报道,今日,面壁智能联合清华大学、OpenBMB开源社区联合发布并开源两大最新数据集:Ultra-FineWeb-L3与UltraData-SFT-2605。这两大数据集均基于面壁智能的UltraData数据分级治理体系构建。
Ultra-FineWeb-L3是中英文网页合成数据集,总量突破6000亿个Token,英文Token数达4000亿个以上,中文则超2000亿个,它同时是目前最大规模的开源中文预训练合成数据集。
UltraData-SFT-2605则是国内首次开源的千万级、同时包含深思考与非思考标注的SFT数据集。
据面壁智能介绍,Ultra-FineWeb-L3能够缓解中文高质量预训练数据长期偏少、分布不均的问题。而UltraData-SFT-2605的关键作用,在于增强模型精准执行指令和分步推理的能力。
目前,这两大数据集已全面上线UltraData网站以及集模型库、数据集、应用部署于一体的AI开发平台Hugging Face等,面向全球开发者免费开放。
UltraData网站:
https://ultradata.openbmb.cn
Hugging Face地址:
https://huggingface.co/collections/openbmb/ultradata
Ultra-FineWeb-L3链接:
https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3
UltraData-SFT-2605链接:
https://huggingface.co/datasets/openbmb/UltraData-SFT-2605
一、五级数据精细化治理,模型性能提升效果平均提高1.49个百分点
以前研发人员做AI训练主要靠堆数据量,但当下大模型技术框架愈发接近,优质公开训练数据也日渐短缺,单纯依靠增加数据总量来提升大模型性能的做法,已经不大适用。
因此,为提升模型性能,面壁智能联合清华和OpenBMB推出全球首个L0-L4五级数据分级治理方案,以系统化提升数据质量。整套流程分为五步:从最原始的数据(L0)开始,依次做基础过滤(L1)、精筛数据(L2)、数据合成与增强(L3),最后得到可用于编排的数据(L4)。
这套方案把原始数据分步逐层筛选、优化,每个环节都有对应的处理规则和使用场景,相关测试显示,按等级使用数据训练模型,模型性能提升效果比混用数据平均提升1.49个百分点。
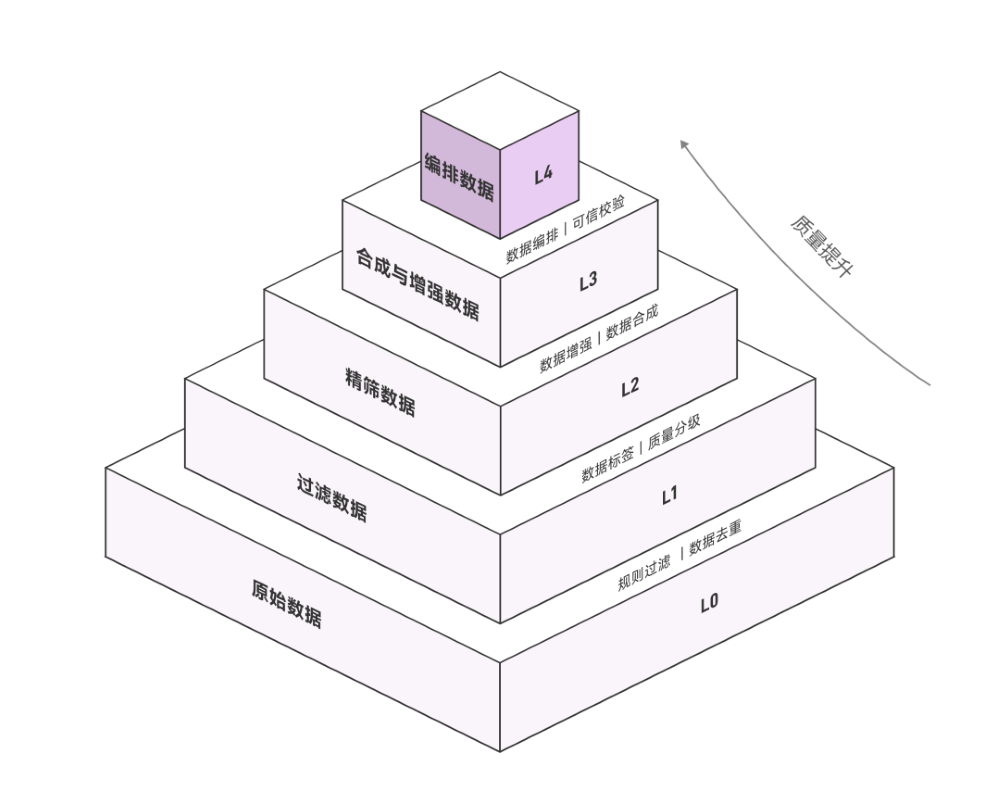
▲L0-L4数据分级治理体系概念图(图源:面壁智能公众号)
今日面壁智能联合推出的Ultra-FineWeb-L3数据集,正是用L3精炼方法从通用网页中合成的大规模数据集。
相关团队先对网页数据做L2级精筛,产出Ultra-FineWeb数据集。后续再以此为基础打造Ultra-FineWeb-L3,借助生成问答对、多风格文本改写,将普通网页内容优化为结构规整、信息浓度更高、更适配大模型学习的训练数据。
如下图所示,相同训练量下,Ultra-FineWeb-L3在多个中英文任务上的表现都超过了FineWeb-edu、FinePhrase等其他数据集,而且训练越往后优势越明显。
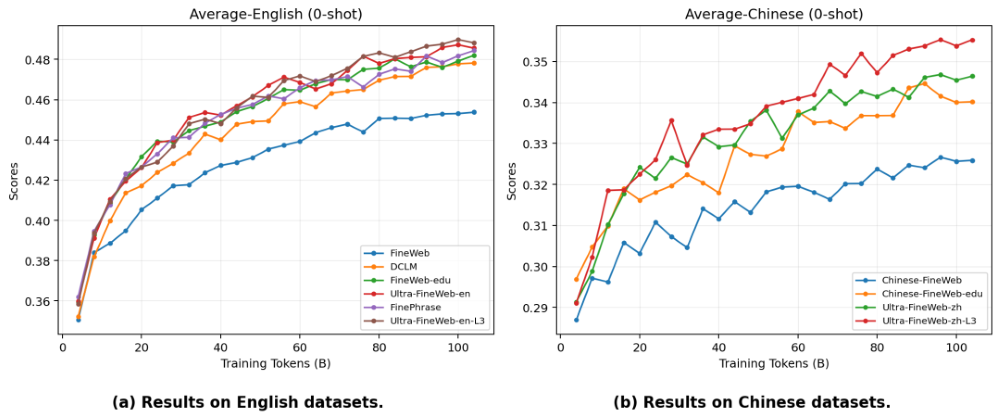
▲不同训练数据对模型性能的影响(图源:面壁智能公众号)
除此之外,Ultra-FineWeb-L3数据集还被用于MiniCPM5-1B模型退火阶段的核心训练,助力该模型在训练后期进一步完成了整体能力提升。
二、双类型标注兼顾快答与深度推理,数据处理全程可溯源
面壁智能联合推出的另一个数据集UltraData-SFT-2605是给大模型用的思考题集和快速问答题集,同时覆盖数学、代码、知识、指令遵循等多个领域。如果说预训练是为模型储备知识,那么SFT就是帮助模型打磨理解指令、拆解复杂难题的核心能力。
以前很多开源SFT数据要么规模小,要么只有最终答案,没有模型一步步推理的过程。这就导致训练出来的模型遇到复杂问题(比如数学、逻辑推理)容易瞎猜,给不出有条理的步骤。
针对这一痛点,UltraData-SFT-2605划分出两类数据,分别适配不同使用场景:一类是非思考数据,用来训练模型快速给出直接答案,适合日常问答;另一类是深思考数据,附带完整思考过程,专门锻炼模型拆解问题、一步步推理的能力。像解数学题、写代码这类复杂任务都能用它训练。
但是,就算是同一级别(L3)的数据,质量也会存在参差不齐的情况。比如会出现题目质量差、回答逻辑乱、或是混入测试题等问题。这些脏数据如果喂给模型,训练效果会打折扣。
针对这些问题,UltraData-SFT-2605设置了一整套筛选流程:先筛选优质提问,再把控回答内容,还专门清理干扰数据、完成效果核验,最大程度保证用来训练的数据靠谱且实用。
此外,开发者还能查看每一条数据的完整处理记录,对每条数据进行溯源,能够自行确认这些数据靠不靠谱。
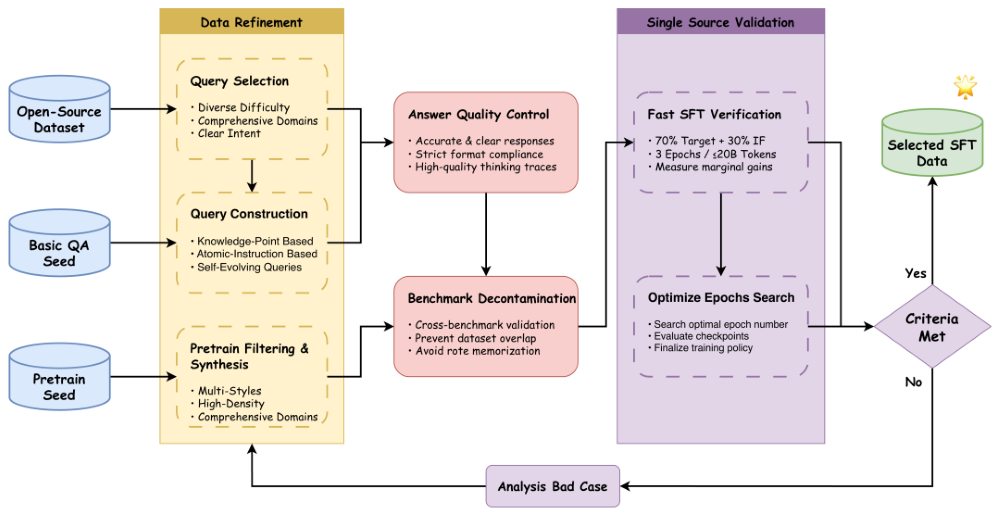
▲SFT数据构造和验证流程示意图(图源:面壁智能公众号)
三、L3数据优化训练效率,UltraData系列开源方案能缩短端侧模型研发周期
对于端侧厂商而言,训练数据一直是个绕不开的难题。如果自己从网页合成数据、再做SFT清洗,这样一来制作成本高并且周期长。UltraData系列数据集的这次开源,相当于帮厂商省掉了这一步骤。面壁智能称,厂商直接使用开源的UltraData,还能复现MiniCPM5-1B级别的模型能力。
具体来说,这批L3高质量数据让1B模型在数学、代码、推理等任务上,表现能接近更大的模型。
另外,数据质量高了,训练时不需要那么多Token就能达到同样效果,算力和内存也更省。而这对端侧大模型从“能做”到“规模化用起来”来说,非常关键。
在推出Ultra-FineWeb-L3与UltraData-SFT-2605数据集之前,相关团队在其开放社区网站整理了UltraChat、UltraFeedback等数据集的前期工作,并开源了总计2.4万亿个Token的训练数据,以及4款数据处理工具,为本次新数据集的推出筑牢了基础。
其中,数学领域数据集UltraData-Math总Token量超2900亿个,完成了多等级数据搭建,仅L3数学合成数据就有880亿个Token,是目前开源平台里体量最大的数学训练数据。
而网页数据集Ultra-FineWeb也曾连续两周登上Hugging Face热门榜第一,累计下载量超50万次。
面壁智能称,接下来UltraData还会陆续开放更多数据,包括更多预训练阶段的数据(L1、L2、L3各层级)、更强的通用SFT数据、专门用于智能体训练的SFT数据以及强化学习(RL)数据。同时,相关的数据治理算法和模型也会持续开源。
结语:开源数据集补齐行业短板,数据与模型协同发展迎来新助力
此次两大新数据集的开源,在一定程度上能够缓解行业内优质训练数据不足、数据质量参差不齐等问题,同时也为开发者和终端厂商提供了一套低成本、可复用的数据解决方案,降低端侧小模型的训练门槛。
随着后续更多类型数据、算法与模型逐步开放,面壁智能这套数据治理体系也将持续迭代,进一步推动数据与模型协同发展,助力AI技术在更多场景落地应用。当然,这两套数据集在模型实际训练中的具体效果,还有待开发者亲自上手验证。
