








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西6月1日报道,刚刚,英特尔在Computex 2026台北国际电脑展期间发布采用Intel 18制程的新一代数据中心CPU至强6+(代号Clearwater Forest),推出全新以太网解决方案E835,并展示了面向AI推理的英特尔数据中心GPU(代号Crescent Island)。

这是首款基于Intel 18A制程(1.8nm级)生产、采用Foveros Direct 3D先进封装技术的数据中心CPU。
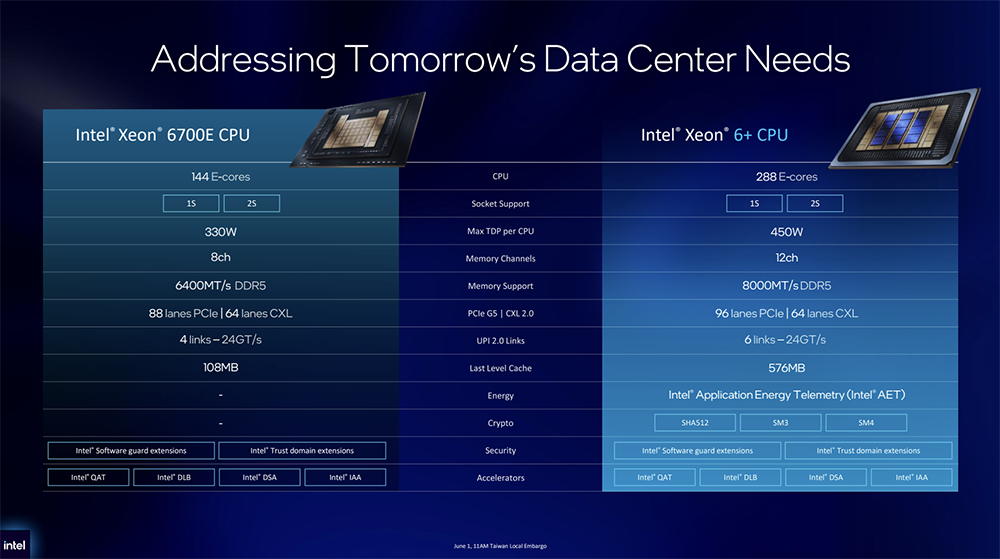
至强6+拥有288个E-core(能效核),配备96条PCIe Gen5通道,支持8000MT/s 12通道DDR5内存、576MB末级缓存(LLC),搭载英特尔软件防护扩展(SGX)、英特尔可信域扩展(TDX)、英特尔应用能耗遥测(AET)等技术,TDP范围为330-450W,支持单路和双路平台配置。

与上一代Sierra Forest及AP型号相比,至强6+的单路核心数量翻倍,同时提升了内存通道数与内存速率,内存带宽显著增长,还增加了PCIe通道数,并完整搭载业界熟知的全套安全特性、可管理特性与硬件加速能力。
与竞品相比,至强6+每线程性能提升高达30%。与上一代相比,至强6+每瓦性能提升达55%。
如果当前客户基础设施当前部署的是第二代至强,升级到至强6+,则可实现9:1的服务器整合比,即减少79%的数据中心物理占用空间,同时能效水平、电力、冷却需求以及持续运营成本也得到优化。

下一代数据中心CPU P-core(性能核)产品是Diamond Rapids,将于2027年发布,基于Intel 18A-P制程,有翻倍的内存带宽、更多PCIe通道和更多的核心数量。

英特尔正在提供不同的解决方案来应对智能体部署需求。至强CPU集成了矩阵引擎和向量引擎,在机架中部署越来越多的核心,内置机密计算、软件加速和压缩技术等特性,并通过AI软件栈帮助企业顺畅地运行框架及模型。

一、至强6+:288核、Intel 18A、3D封装,能效显著提升
至强6+基于Intel 18A制程,提供业界最高的内核密度,单Socket拥有多达288个E-core(能效核),配备96条PCIe Gen 5通道,支持8000MT/s 12通道DDR5内存,以及高达576MB的末级缓存(缓存容量是上一代产品的超过5倍),同时支持单路和双路平台配置。

至强6+引入3D封装技术Foveros Direct 3D,将基于Intel 18A制程的计算Tile堆叠在基于Intel 3制程的底层Tile之上,仍由EMIB封装技术完成互联;I/O Tile基于Intel 7制程。

英特尔采用4个基于Intel 18A工艺的晶片构建了至强6+,每个晶片包含了24个核。这些晶片堆叠在3颗基底晶片上方,基底晶片集成了片上网状互联架构、末级缓存与内存子系统。

至强6+还搭载了最新的机密计算能力:英特尔软件防护扩展(SGX)可实现最小信任边界;英特尔可信域扩展(TDX)则在虚拟机层级实现数据隐私防护,帮助客户进一步强化对数据中心数据的管控能力。这些技术可在多实例、多租户高密度场景下保障数据隐私。

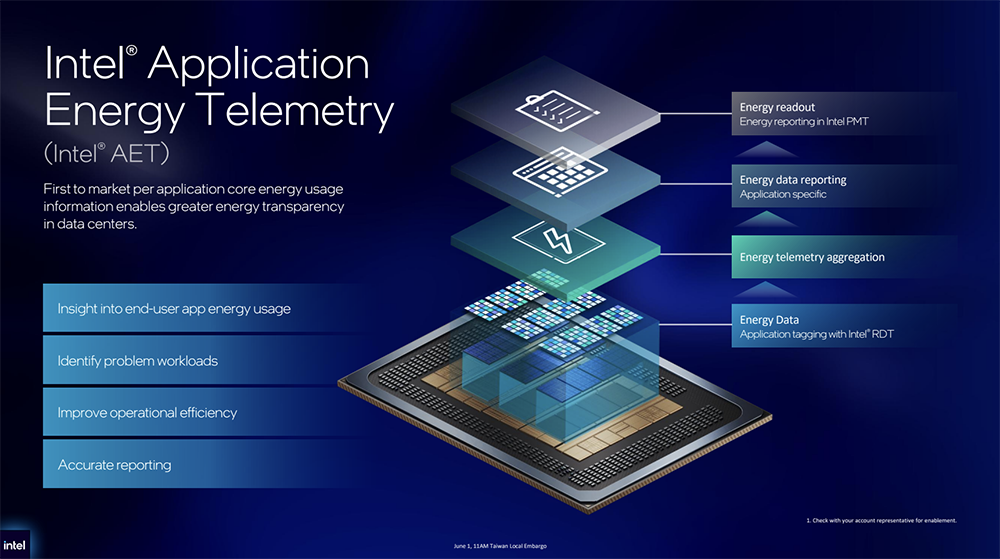
针对功耗控制,英特尔在至强6+中新增了一项硬件功能——英特尔应用能耗遥测技术(AET)。该技术可在工作负载层级实时监测CPU功耗与运行状态,进而实现能效更优的资源编排、精准成本分摊,并针对负载优化应用落地能效激励机制,提升企业对数据中心业务负载的能耗管控能力。
至强6+针对网络基础设施、媒体业务、Web及微服务、存储等关键基础工作负载进行了优化。
对比上一代产品,至强6+在数据中心各类主流工作负载下,整体性能最高提升至2.26倍,每瓦性能最高提升至1.55倍。

与主流竞品对比,至强6+的每线程性能达到1.3倍,每线程每瓦性能同样高达1.3倍(虚拟化数据中心工作负载的核心评估依据)。

至强6+还引入了全新的密码学指令集,与上一代相比,工作负载性能提升多达15倍,可达到主要竞品的6倍之多。

至强6+的能效优势覆盖了当今数据中心所有负载利用率区间,不仅能在峰值负载下保持高效运行,在更为常见的低负载状态下,也能在整个性能频谱上提供1.3倍的每瓦性能。

关于至强6+的更多架构细节,可参见芯东西去年10月的《1.8nm制程、288核!英特尔CPU大招挤爆牙膏,豪赌3D封装》文章。
二、以太网解决方案E835: 200Gbps带宽、丰富端口配置、大幅提升能效比
要发挥至强6+的潜力,还需先进的网络技术。
英特尔今日推出全新的以太网解决方案E835,通过专注于性能、可靠性、灵活性、效率四个关键领域来提供优化的网络。

凭借200GbE以太网吞吐量、RDMA以及动态设备个性化(DDP)技术,E835架构设计上提高了每个核心的带宽,专为至强6+等高核心数平台而打造。
基于包括控制器、OCP 3.0以及PCIe网络适配器(含宽温版型号)在内的完整产品阵容,E835产品系列可提供高达200G的吞吐量,配置选项包括2×25G、4×25G、2×100G、1×200G,并支持利用EPCT(以太网端口配置工具)功能进一步自定义。在完成首次验证后,用户只需简单的两个步骤,即可根据需要重新配置端口数量和速率。
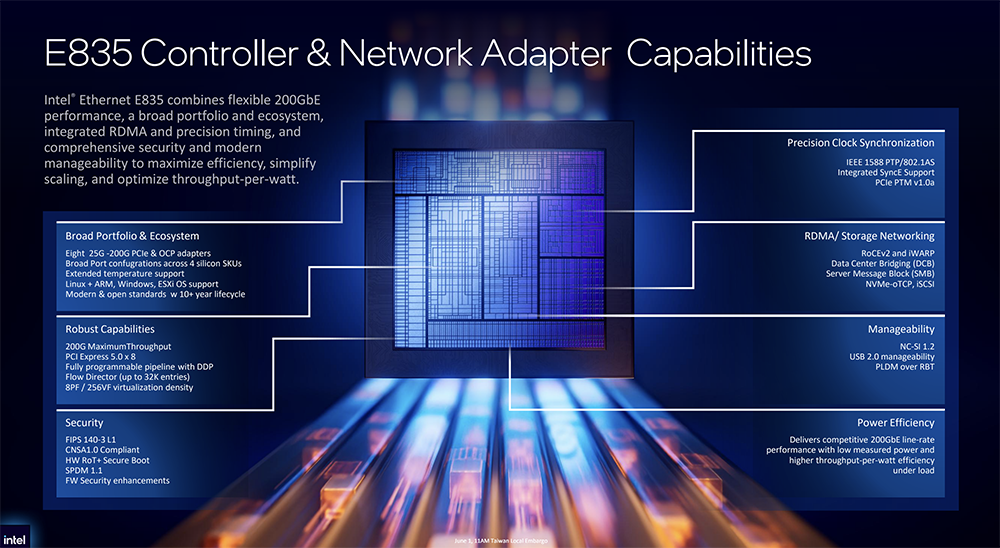
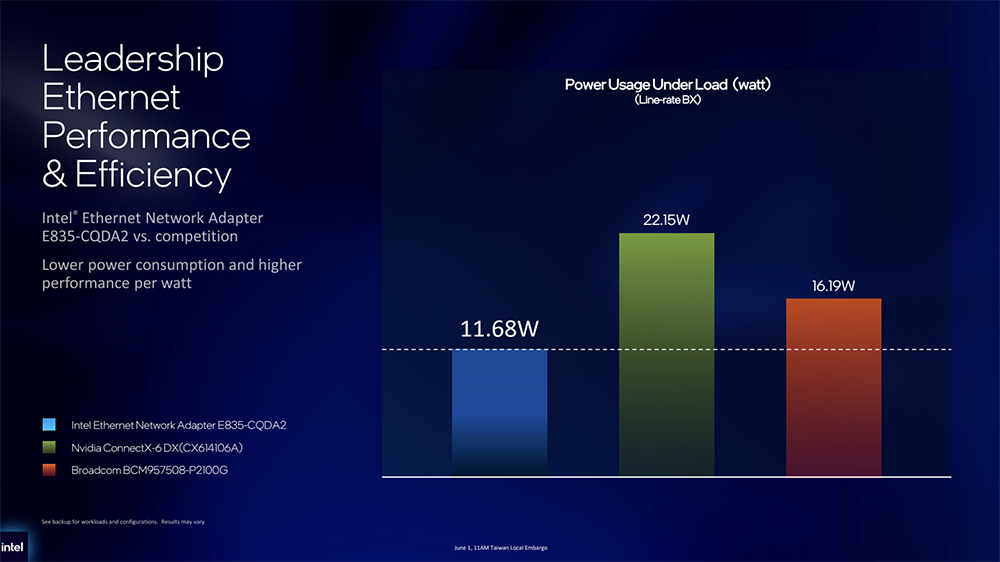
E835专为高每瓦性能(高能效比)而设计,当以全双向200G线速运行时,功耗比同类产品低28%~47%,在满载工作负载条件下,每瓦性能(能效比)达到1.4-1.9倍,并具备超过10年的产品生命周期。
E835通过硅芯片信任根、带签名的安全协议与数据模型SPDM(Security Protocol and Data Model)以及设备和固件证明提供了强健的可靠保障,从而实现硬件级的身份验证和弹性保护。它还支持广泛的可管理性协议,包括兼容NC-SI 1.2标准,以提升运营效率。
三、数据中心GPU:基于Xe3P架构,配置480GB大内存
推理和智能体AI正呈爆发式增长,已成为AI领域增长最快的细分市场。当前挑战在于,如何以合适的成本、大规模且高效地交付Token。
系统内部存在着持续的交互:GPU负责进行推理、思考、代码生成和优化,CPU负责编排、模拟、调度和执行。
基础设施设计正在不断演进,以优先考虑计算、内存、带宽、网络和I/O的合理配比。因此,编排变得日益关键,需要正确的AI模型、预填充、解码、编排、高效的键值缓存(KV Cache)管理,以及在跨网络、软件和异构计算的执行中选择最合适的CPU。
英特尔提供广泛的加速器产品组合(集成显卡、独立显卡、数据中心GPU、SambaNova AI芯片),以支持智能体AI的不同需求:通过高算力进行预填充,通过大容量内存和高带宽进行解码,通过数据流架构实现高用户交互和规模化下的低延迟。
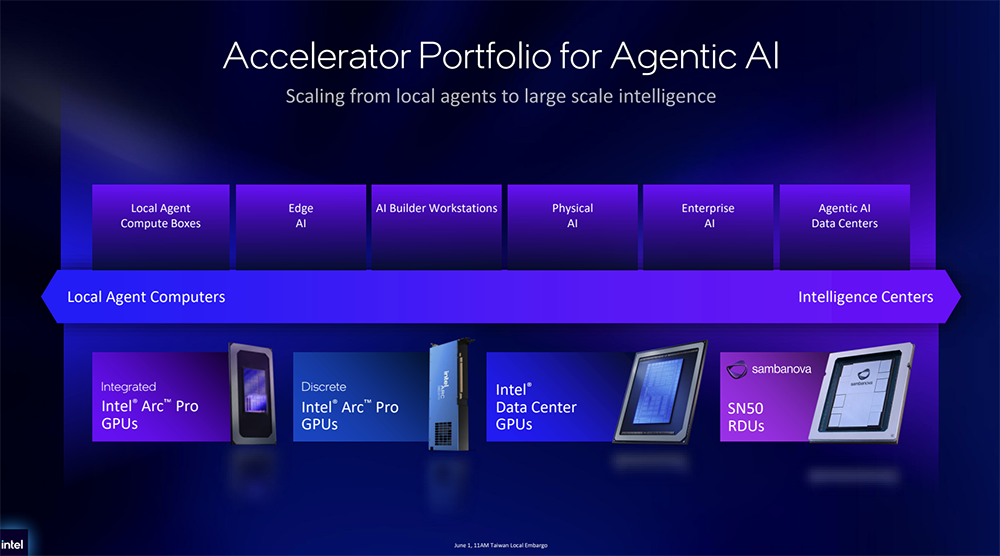
英特尔已在数百万个客户端处理器中出货并应用了Xe GPU,构建了可扩展的计算架构,并在酷睿Ultra系列3处理器中引入Xe3架构及灵活的编程模型,通过增强的内存处理能力,优化了大型工作负载的资源利用率和AI性能。即将推出的Xe3P扩展了对AI运算的支持,并改进了内存和可扩展性。

英特尔数据中心GPU(代号Crescent Island)将是首款基于Xe3P架构打造的产品,专为AI推理和智能体工作负载、适用于长上下文模型的大内存容量、高效率和更低的功耗、优化的TCO进行了优化,内存容量提升到480GB,支持广泛的AI数据类型,同时支持原生FP64。

Crescent Island采用LPDDR内存以及高密度的背面通道,拥有增强的内存带宽、大容量内存,并针对云和企业级推理工作负载进行了性能调优,同时拥有更低的总拥有成本(TCO)。LPDDR的功耗显著降低,使GPU热设计功耗(TDP)控制在350W,可在现有风冷数据中心中运行。
英特尔提供开箱即用的广泛模型软件支持,围绕开放、规模化性能、优秀的用户体验、支持异构基础设施四个原则构建统一的Xe软件栈。它提供了一个用于协同调度分布式推理状态的平台,有助于解决在CPU和GPU之间进行调度、路由和解决推理工作负载时的运营复杂性。

已有超过20家OEM和ODM厂商以及多个合作伙伴,正在针对Crescent Island产品进行开发并准备发布。
英特尔后续将分享更多细节。
此外,英特尔正与美国AI芯片公司SambaNova在软件和工作负载上进行合作,为客户在扩展经济高效的大规模智能体推理需求中提供更多选择。

结语:Agentic AI时代需要新的CPU和AI加速器组合
当前大多数云计算企业都在数据中心广泛部署至强处理器。英特尔正在竭力抓住Agentic AI时代的CPU机遇,并扩大自身产品在数据中心市场的优势。

英特尔的数据中心战略核心在于在所有工作负载之间进行扩展。如今,这一版图已经覆盖以太网、IPU、CPU、GPU、SambaNova AI芯片等产品。这将为下一阶段的AI基础设施提供更灵活和丰富的选择。
