








智东西(公众号:zhidxcom)
编译 | 杨京丽
编辑 | 李水青
智东西6月16日消息,今天,蚂蚁百灵团队发布Ling-2.6-flash、Ling-2.6-1T 和 Ring-2.6-1T三款模型的Ling & Ring 2.6技术报告,系统公开百灵2.6系列模型在架构、预训练、后训练与推理基础设施等方面的技术细节。
此前,百灵已陆续开源Ling-2.6-flash、Ling-2.6-1T和Ring-2.6-1T。三个模型面向不同场景:Ling-2.6-flash主打低延迟、高吞吐和高频调用,适合信息抽取、格式转换、批处理、长输出,以及Agent工作流中的轻量执行节点;Ling-2.6-1T面向更高能力密度和更强通用能力,重点提升即时响应场景下单位输出token的信息量;Ring-2.6-1T则面向复杂推理和Agent任务,强调长链路规划、工具调用、代码执行、搜索和环境交互能力。
▲百灵大模型地址(图源:Hugging Face)
随着大模型逐步进入Agent、Coding、科研分析和企业工作流等复杂任务场景,模型需要具备可靠推理和稳定使用工具的能力,还需要在成本和延迟可控的前提下持续执行任务。
围绕这一目标,报告重点展示了百灵2.6系列的技术路径:架构方面,百灵2.6系列模型采用混合线性注意力(Hybrid Linear Attention),将闪电注意力(Lightning Attention)与多头潜在注意力(MLA)按7:1比例结合,降低长上下文训练、解码和键值缓存(KV Cache)成本。
预训练上,团队在Ling-2.0基础上进行架构迁移和继续预训练,将上下文窗口扩展至256K;后训练上,Ling-2.6围绕token效率压缩冗余推理,Ring-2.6则面向长程Agent任务强化工具调用、搜索和代码执行能力;基础设施上,团队通过长上下文训练优化、异步Agentic RL和推理侧算子融合,支撑万亿参数模型在真实工作流中的训练与部署。
评测结果显示,Ling-2.6-1T在Artificial Analysis Intelligence Index中以约16M输出tokens取得约34分,接近GPT-5.4 Non-reasoning,并高于DeepSeek V3.2和上一代Ling-1T,体现出较高token效率。
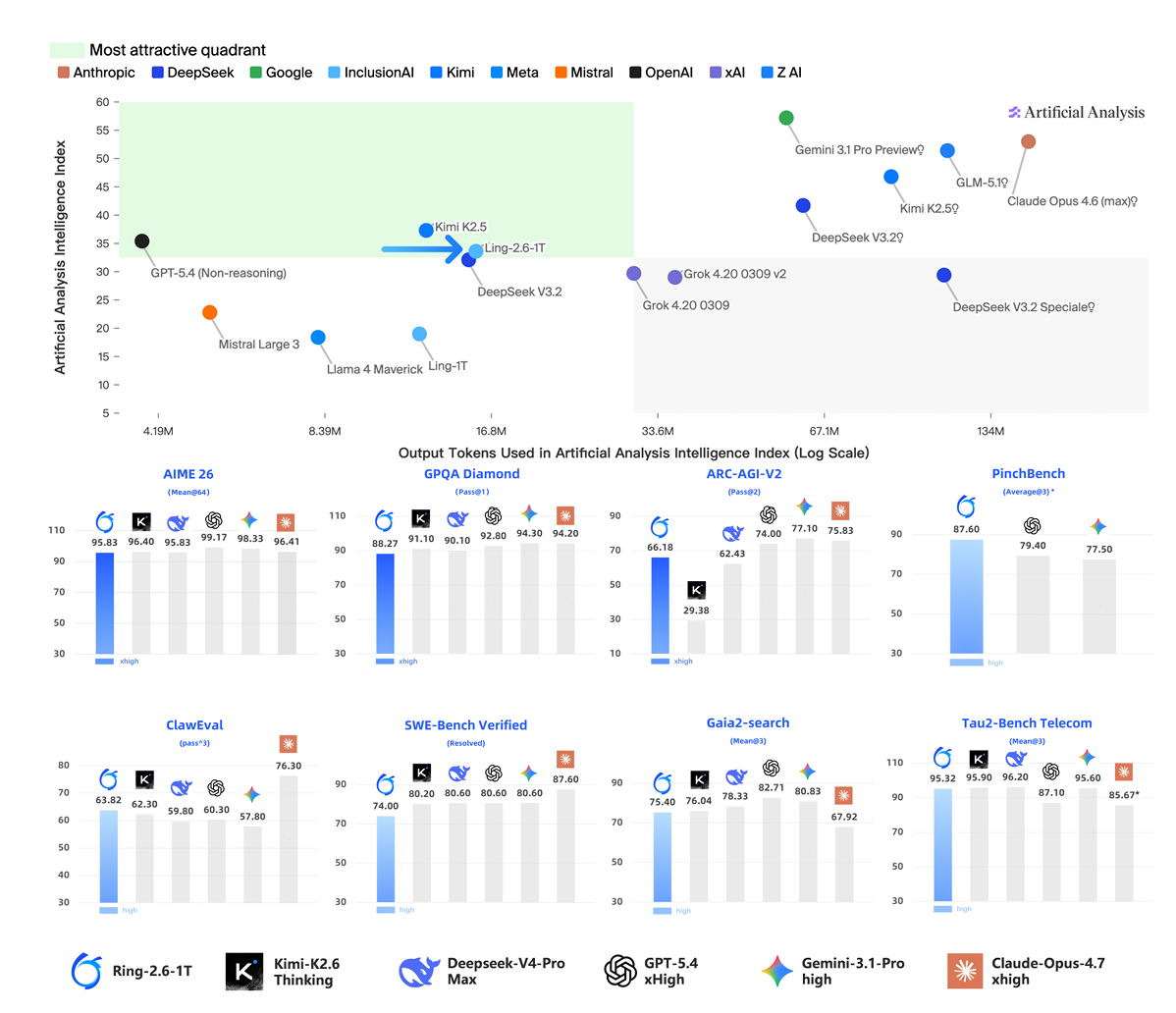
▲Ling-2.6-1T与Ring-2.6-1T评测结果
Ring-2.6-1T则在部分复杂推理和Agent任务中表现突出:其xhigh配置在ARC-AGI-V2上取得66.18,高于Kimi-K2.6 Thinking和DeepSeek-V4-Pro Max;high配置在PinchBench上取得87.60,高于GPT-5.4和Gemini-3.1-Pro,在ClawEval上取得63.82,高于Kimi-K2.6 Thinking、DeepSeek-V4-Pro Max、GPT-5.4和Gemini-3.1-Pro。

技术报告地址:https://arxiv.org/abs/2606.15079
Ling-2.6-flash开源地址:https://huggingface.co/inclusionAI/Ling-2.6-flash
Ling-2.6-1T开源地址:https://huggingface.co/inclusionAI/Ling-2.6-1T
Ring-2.6-1T开源地址:https://huggingface.co/inclusionAI/Ring-2.6-1T
一、三大重点:长上下文效率、token密度、原生Agent训练
为保证模型在万亿参数规模和真实Agent工作流下,仍能够保持长上下文处理效率、输出质量与工具调用稳定性,百灵2.6主要围绕以下三方面进行了系统优化。
百灵2.6首先解决的是长上下文效率问题。报告提到,此前模型基于GQA(分组查询注意力)架构,当上下文长度超过32K tokens后,注意力计算会成为主要瓶颈。为此,Ling/Ring2.6采用混合线性注意力(Hybrid Linear Attention)架构,将闪电注意力(Lightning Attention)与多头潜在注意力(MLA)按7:1比例结合,即每8层中约7层采用Lightning Attention、1层采用MLA。
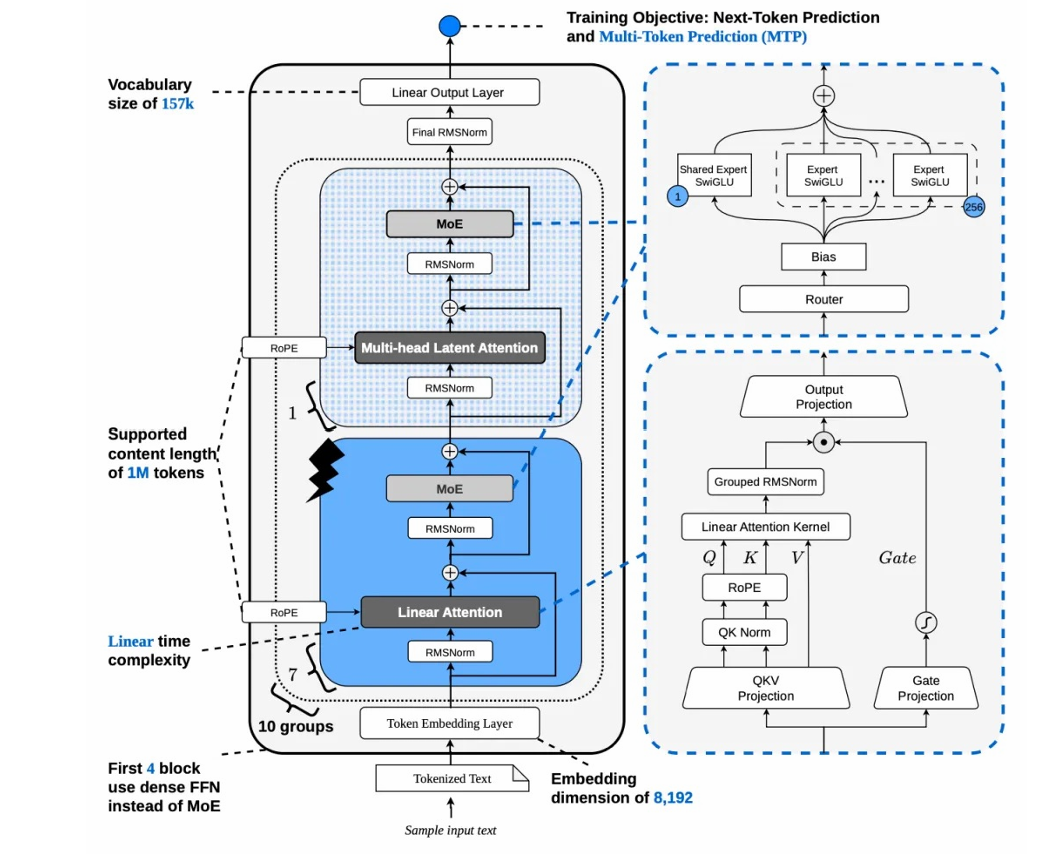
▲Ling-2.6-1T-base整体架构
Lightning Attention将序列维度上的计算复杂度从O(n²)降到O(n),MLA则通过低秩隐空间压缩KV Cache。二者结合后,模型更适合长上下文训练、长输出和长链路Agent任务。
第二个重点则是提升token能力密度。Ling-2.6在后训练阶段结合演化式思维链(Evolutionary Chain of Thought,Evo-CoT)、语言单元策略优化(Linguistic Unit Policy Optimization,LPO)、双向偏好对齐和最短正确回答蒸馏等方法,提升模型对有效推理步骤的选择能力,减少重复、循环和低信息密度输出。
在Artificial Analysis Intelligence Index榜单上,Ling-2.6-1T使用约16M输出tokens取得34分。报告称,这相比Ling-2.0-1T在reasoning workloads上实现约4倍token效率提升。
第三个重点是Agent能力的原生优化。百灵2.6系列的Agent能力不是从普通对话数据中间接迁移而来,而是作为直接训练目标优化。团队构建了覆盖工具调用、代码、搜索、工作流执行和多轮交互的大规模Agentic Corpus(智能体语料库),并将其与可验证任务、结构化工具轨迹和环境反馈结合。
在Ring-2.6上,团队进一步提出KPop,用对称二元KL散度替代IcePop中的固定比例约束,以更稳定地进行MoE模型的Agentic RL训练。同时,团队还采用异步RL,将rollout采集与参数更新解耦,使编码、搜索、工具调用和工作流执行等长链路任务,能够在万亿参数规模下进行更高效训练。
二、预训练:在Ling-2.0基础上,扩展至256K上下文
百灵2.6没有从零训练万亿参数模型,而是在Ling-2.0基础上进行架构迁移、继续完成预训练和后训练。报告称,Ling-2.0-1T此前已有约20T tokens训练投入,直接重新训练成本较高,因此团队选择在已有checkpoint上完成架构升级。
架构迁移分为四个阶段:第一阶段是闪电注意力转换(Lightning Attention Conversion),将部分原有GQA层替换为Lightning Attention,以降低长上下文计算成本;第二阶段是线性预热(Linear Warmup),主要用于对新增参数进行训练和对齐,使模型逐步适应新结构;第三阶段是MLA转换(MLA Conversion),包括去除QK归一化(QK Norm removal)和适配部分旋转位置编码(Partial RoPE adaptation),为后续KV Cache压缩和高效推理做准备;最后是MLA预热(MLA Warmup),通过小规模继续训练将loss恢复到迁移前水平。整个迁移阶段约使用400B tokens。
完成架构迁移后,模型继续进行大规模全参数训练。报告中提到,Ling-2.6预训练总计处理约9.6T tokens,分为迁移预训练(Migration Pre-Training)、继续预训练(Continue Pre-Training)和中期训练(Mid-Training)几个阶段。其中迁移预训练约 400B tokens,用于完成架构迁移;继续预训练约8T tokens,使用4K上下文窗口;中期训练约1.2T tokens,将上下文窗口逐步扩展到32K,再扩展到256K。
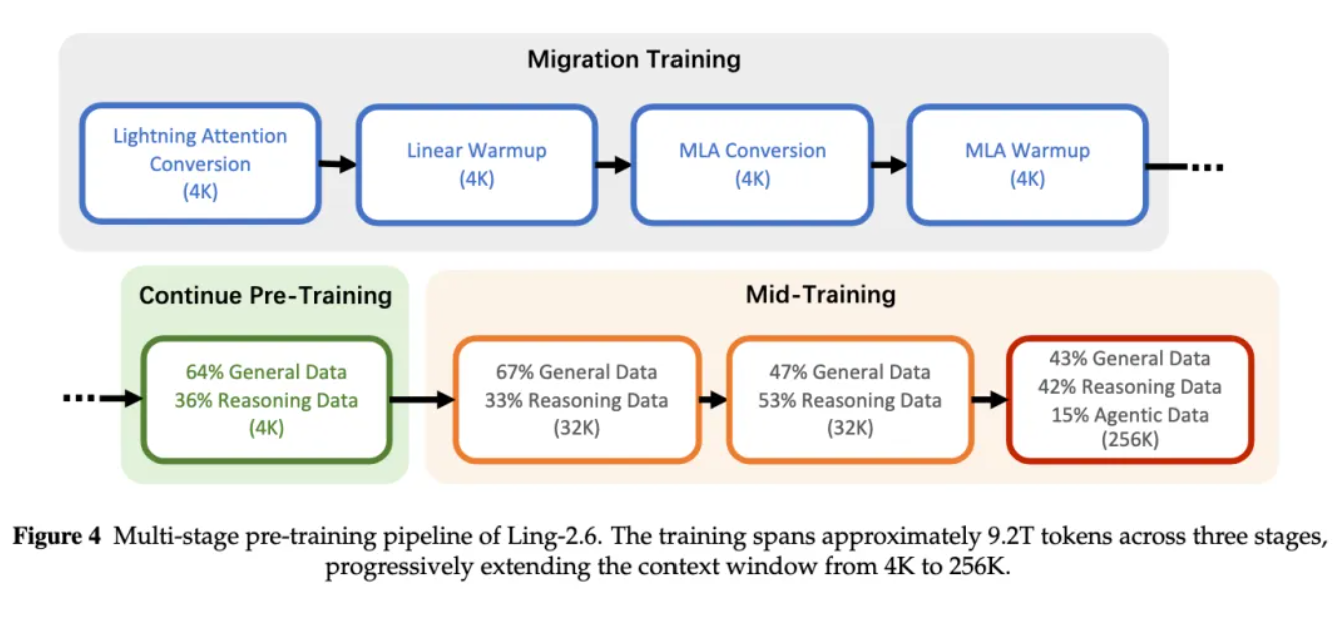
▲Ling-2.6多阶段预训练流程
数据构成上,团队增强了数学、代码、Agentic Data、长上下文语料和多语言语料。Agentic Corpus覆盖500多个真实MCP环境、3000多个工具,以及多种coding、bash、web QA和软件仓库任务;Long-Context Corpus覆盖数学、复杂网页解析、长文档摘要、RAG融合和多跳推理等任务。
在base model评测中,团队使用覆盖数学、代码、通用推理、语言理解、世界知识和长上下文理解的31个benchmark,对Ling-2.6-flash-base、Ling-2.6-1T-base与2.0代模型进行对比。
整体来看,Ling-2.6-1T-base在世界知识、长上下文建模和推理能力上取得较稳定提升,同时保持了数学和代码能力。尤其是在SimpleQA、C-SimpleQA、MMMLU、LongBenchv2等知识和长上下文任务上,提升较为明显。
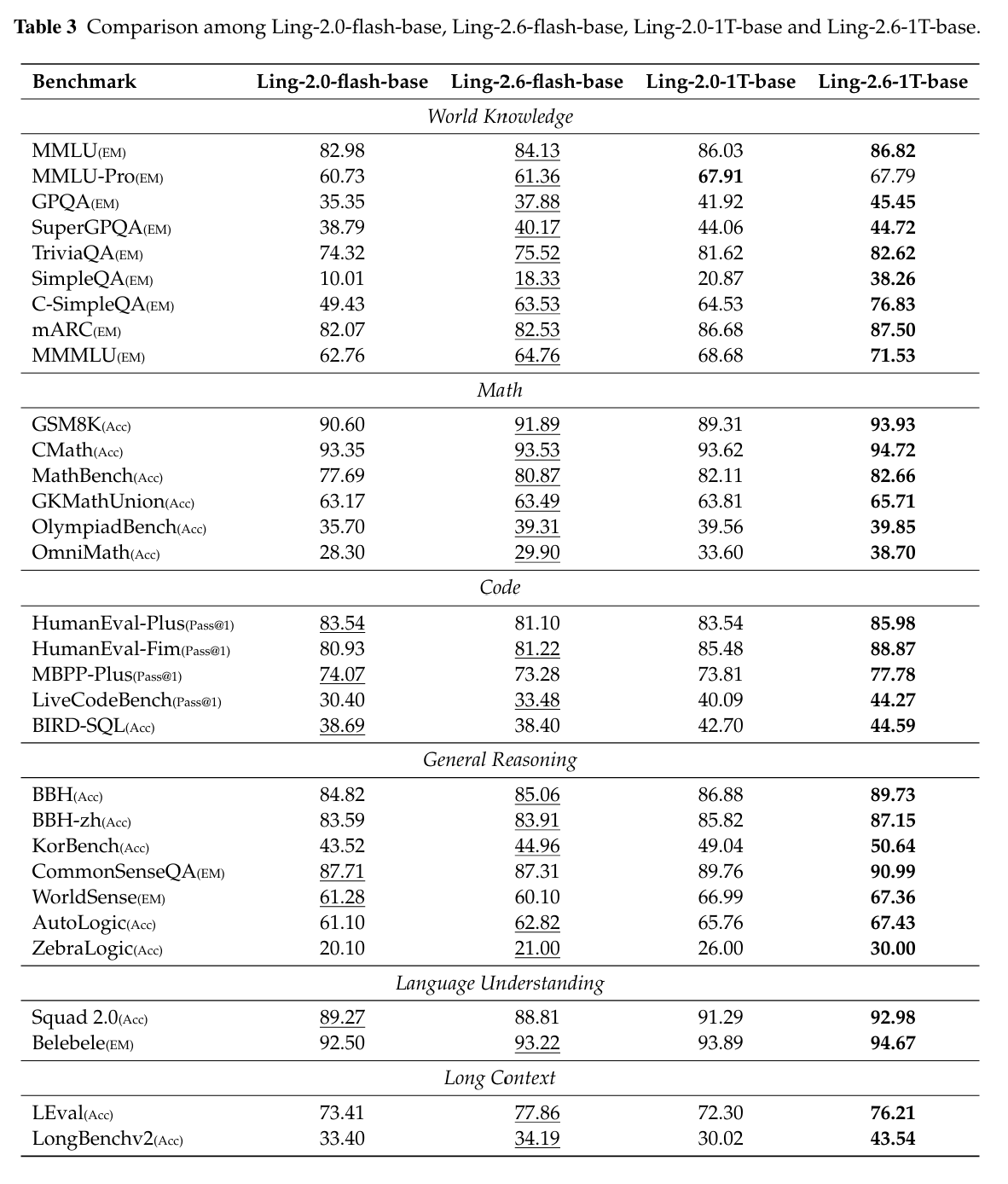
▲Ling-2.6-base与Ling-2.0-base在多类基准测试中的对比
三、Ling-2.6后训练:用更少token完成高质量即时响应
Ling-2.6的后训练,围绕即时响应和高频调用两方面展开。团队重点关注模型能否在更少输出token内,给出更高质量的回答。
为此,Ling-2.6没有沿用Ling-2.0中相对统一的后训练流程,而是采用专家驱动的训练路线。模型先进行cold-start SFT打底,再进行推理和Agent任务方向的专家化训练;随后,通过强化学习进一步优化专家模型,最后将这些专家能力蒸馏回统一的Ling-2.6模型中。
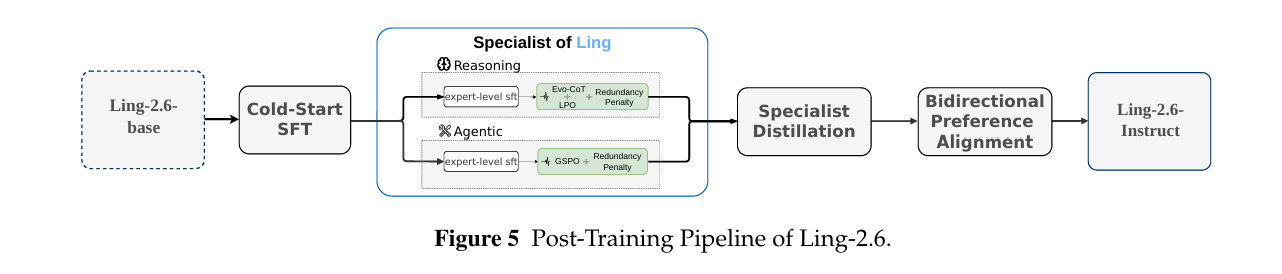
▲Ling-2.6后训练流程
在推理数据处理上,团队先让专家模型生成多个候选答案,再筛选出最短的正确回答。同时,对于“答对后还在反思”的片段,团队进一步用LLM judge进行裁剪。报告称,数据层面的处理,让模型平均输出长度减少约200到300个token。
进入强化学习阶段后,Ling-2.6在Evo-CoT基础上加入动态长度惩罚和语义冗余惩罚。动态长度惩罚允许模型在难题上,保留必要推理空间,压缩简单任务中的过长输出;语义冗余惩罚则用于抑制循环、重复和低价值反思。
四、Ring-2.6后训练:面向长程Agent任务,强化工具使用
Ring-2.6的后训练目标则偏向复杂、长程、工具密集型Agent任务。它以Ling-2.6-1T Base为基础,经过cold-start SFT,再进入由KPop算法驱动的推理与Agent专家训练阶段,随后进行专家能力蒸馏,并最终形成high和xhigh两种推理配置。
工具使用数据上,Ring-2.6重点覆盖三类场景:仓库级代码任务、移动端/网页搜索任务,以及需要多步规划和错误恢复的通用工具工作流。以Coding Agent为例,团队从GitHub中大规模挖掘PR-Issue pairs,并设置了较严格的筛选条件:仓库star数超过100、PR已合并且关联closed issue,同时PR中必须包含test patch以便验证。经过筛选后,团队得到约300K raw pairs。
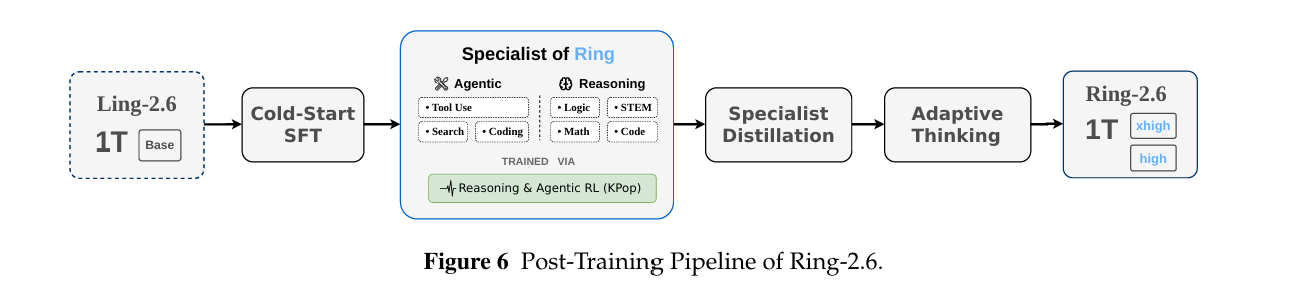
▲Ring-2.6后训练流程
在Agentic RL阶段,团队构建轻量级Agent框架,并提供execute_bash、search_replace和task_done三类核心工具。训练期间最大对话长度为200 turns,评估期间最大对话长度为500 turns。针对SWE类长程任务,最终训练数据集包含约2500个实例,来自1550个仓库,覆盖Python、Java、C、Rust、JavaScript等30多种编程语言。
五、基础设施:长上下文训练、异步RL与推理部署协同优化
基础设施方面,百灵2.6的优化主要围绕长上下文训练、大规模异步Agentic RL和推理serving展开。团队提出AllGather-based CP,使Lightning Attention能够更高效地进行超长上下文训练,在256K上下文长度下带来约68%的端到端加速。RL基础设施ASystem和ARouter则面向长序列rollout调度,报告称在长序列场景下带来超过80%的端到端性能提升。
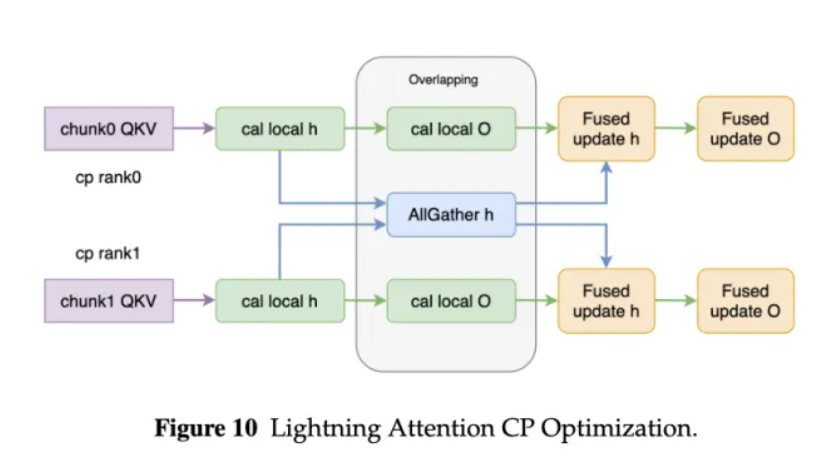
▲Lightning Attention的上下文并行优化
推理侧,团队将训练阶段积累的融合算子(fused kernels)适配到真实部署场景,并尽可能保持训练与推理阶段的数值行为一致。这不仅提升推理效率,也有助于减少强化学习采样(RL rollout)中的训练-推理差异。推理侧kernels能力已通过高性能算子库linghe开源。
▲linghe开源地址:https://github.com/inclusionAI/linghe
结合算子融合(kernel fusion)、前缀缓存(prefix caching)与多token生成(multi-token generation),linghe优化提升了整体吞吐、单用户每秒生成token数和交互稳定性。
结语:国产开源模型,公开更多技术细节
这份报告较完整地公开了百灵团队在万亿参数模型上的技术细节。从结果看,Ling/Ring2.6在部分复杂推理、工具调用和Agent任务上已有较强表现,但与国际顶尖模型相比仍有追赶空间。
报告也提到,Ling-2.6-flash在高复杂任务中的推理深度和工具调用可靠性仍受思考预算限制;长程Agent在持续变化的工具状态和异构执行环境中,可靠性仍可能下降。下一阶段,百灵团队计划继续沿着架构、系统、低精度训练推理、KV Cache管理和多模态Agent方向推进。
对开源生态来说,模型开源和技术报告公开本身值得认可。它让外界能够了解背后的数据构建、训练方法、系统优化等,期待更多国产大模型团队持续开放模型、工具与技术细节,推动开源生态在真实应用能力上继续向前。
