








机器人前瞻(公众号:robot_pro)
作者 | 王涵
编辑 | 漠影
机器人前瞻7月2日报道,今天,地瓜机器人算法团队发布世界模型Uranus,该模型是一个基于视频扩散模型、工作在帧级闭环模式下的交互式世界模型。
Uranus的核心思想就是,给定几帧参考图像、机器人关节状态、相机参数和一句文本描述,模型就能自回归地生成多相机视角下连续、可控的未来视频流,模拟机器人与环境的交互过程。

▲Uranus模型架构:模型在参考帧和历史帧约束下,根据输入的动作通过flow matching生成下一帧
该模型以预训练Wan 2.1视频DiT骨干为基础,采用一阶段训练方案,能够直接产出分钟级可交互视频。
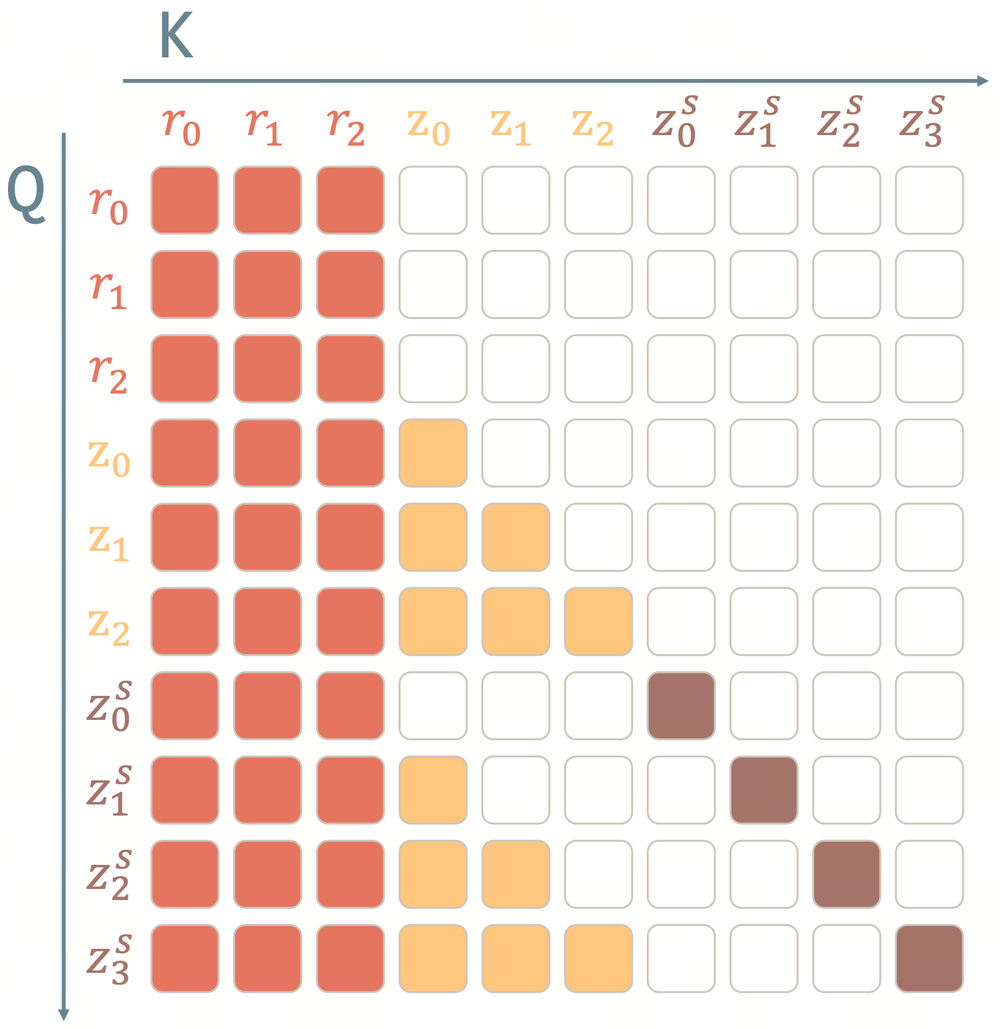
▲Uranus训练过程使用的Causal Mask
Uranus提供1.3B和14B两个版本,分别适用于快速实验和高保真闭环生成场景。
以下演示展示了Uranus在帧级闭环模式下,对两种不同机器人、不同轨迹的交互仿真效果:
G1机器人在不同场景下执行多种操作轨迹,Uranus可以在多相机视角下实时生成连续的交互画面:
▲G1机器人完成商品条码扫描,三路相机视角同步输出,帧级闭环连续rollout。
Franka机械臂在不同环境和轨迹下的操作效果,Uranus具备跨具身泛化能力,并且能够对复杂末端轨迹的精确响应:
▲Franka机械臂完成物品抓放,展示闭环模式下对末端执行器姿态、夹爪开合的精确控制。
一、首创逐帧闭环仿真,可以随时改指令、即时出反馈
开发一台能自主完成复杂任务的机器人,离不开大量的测试与验证。然而,真实世界的测试昂贵、耗时且难以复现,一台机械臂很难在真实环境中试错成千上万次。
传统仿真器,如Isaac Sim、MuJoCo等,提供了一种替代方案:在虚拟环境中验证算法,再迁移到真实世界。但这条路同样崎岖,因为手工构建仿真场景本身就是一项浩大的工程。3D建模、材质设定、物理参数调校……每一个新环境都需要数天甚至数周的搭建。
有没有一种方法,能像生成图片和视频一样“生成”一个仿真环境?更进一步,能不能像真正的仿真器那样,做到逐帧交互、逐帧闭环?
不同于传统开环生成方案需要提前录入完整动作序列、一次性输出全部视频片段,Uranus用了仿真器式的逐帧运行架构,交互逻辑实现全面升级。
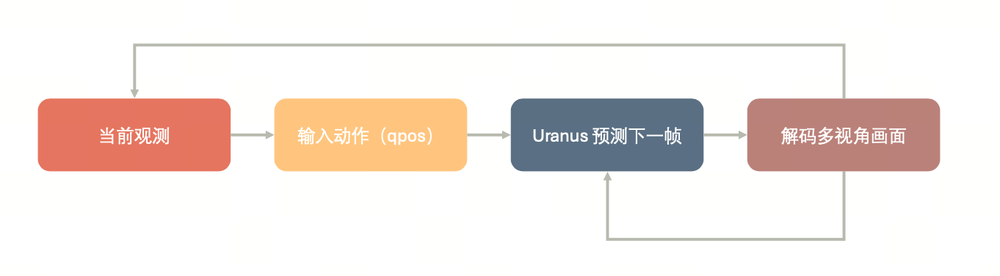
整套系统采用分步逐帧生成机制:模型结合参考图像、历史画面以及实时动作指令,推算出机器人下一时刻多机位相机对应的视觉画面。每一帧生成完成后,画面会即时存入历史上下文窗口,作为后续帧推理的输入依据,形成完整闭环。
依托逐帧推理的底层设计,用户能够随时更改动作指令,模型可即时做出对应视觉反馈,实现动态操控。
使用者仅需上传初始场景画面与机器人模型文件,就能在虚拟视觉环境中像操控实体机器人一样完成各类调试操作,全程无需人工搭建三维模型,大幅简化机器人仿真测试流程。
二、四大技术亮点,破解长时序闭环难题
Uranus背后主要有四大技术亮点:
1、跨具身零样本泛化
传统方案需要针对不同机器人单独训练专属模型,而Uranus依靠一套统一骨架渲染管线,实现机器人本体结构与模型输入完全解耦。
用户仅需上传URDF、MJCF格式机器人描述文件,并输入关节位置数据,系统就能通过前向运动学算法算出三维关节坐标,再投射至相机平面生成骨架图像。依靠这套机制,单一模型可同时适配G1人形机器人、Franka协作机械臂、双臂机器人以及移动机器人平台等多类设备。
这套能力对闭环交互流程有着关键作用:闭环运行逻辑中,模型会持续将上一帧输出预测作为下一帧输入。若模型仅适配单一机器人,切换设备就必须重新训练,闭环体系根本不具备通用适配能力。
而Uranus这套统一骨架渲染管线,能够把各类机器人的运动动作转化为统一的图像表征,实现跨机型通用。
2、分钟级闭环稳定生成
帧级闭环运行最大难题在于误差累积:模型每一步产生的细微预测偏差,都会作为前置数据输入下一阶段,持续迭代数十帧后极易出现画面失真崩坏。
多数视频生成模型仅能生成数秒开环画面,根源便是未能攻克该痛点。Uranus依靠三项核心设计,打通长时序闭环推演瓶颈:
因果注意力掩码(Causal Mask):限定单帧仅能读取过往时序信息,严格匹配自回归闭环的因果逻辑;
帧相对位置编码(Frame-Relative RoPE):模型仅用短片段完成训练,推理阶段却可适配任意时长的闭环连续推演;
参考帧注意力汇(Reference Sink):依托Transformer原生注意力汇聚特性,把初始基准帧长期留存于上下文窗口充当视觉参照。即便闭环持续运行大量步数,模型始终保有清晰原始画面作为参照,大幅缓解画面偏移失真问题。
3、多视图空间一致
机器人一般搭载多套摄像设备,包含手部相机与环境外置相机等不同机位。Uranus可同步渲染三路及以上相机画面,且多视角画面能够维持统一空间几何关系。算法团队为此设计交替时空注意力架构:
- 空间计算模式:同步帧下各相机视图互通特征信息,保障多视角空间逻辑统一;
- 时间计算模式:单台相机沿时间维度建模运动变化,闭环推演阶段仅该模块生成KVCache缓存,降低算力开销。
两种计算模式在模型的DiT网络层级交替运行,平衡图像生成效果与运算效率。
4、精确的相机轨迹控制
Uranus借助普吕克射线嵌入技术,将每一帧相机的内参、外参转化为逐像素稠密几何特征。这套表征完全依托相机标定参数生成,不需要模型额外学习。
落地到闭环交互场景,该特性带来一大优势,即用户可像操作常规仿真工具一样,随时调整相机位姿;模型会依据更新后的相机参数,在下一帧同步输出匹配新机位的画面。
三、引入KV-Cache缓存,算力开销恒定可控
帧级闭环推演对模型的工程性能提出了极高挑战。模型每生成一帧画面,都要完成一轮完整的去噪扩散流程,若每一步都从零计算注意力特征,计算开销将随序列长度呈平方级暴涨,严重限制长时序闭环运行能力。
针对这一性能瓶颈,算法团队为Uranus引入KV-Cache缓存与滑动窗口机制,大幅压缩推理成本。
在预填充阶段,系统会提前计算并缓存。与此同时,平台通过滑动窗口淘汰机制,动态管理时序数据。当历史帧数量超出窗口阈值时,系统会自动舍弃最早的帧数据,始终保持单步推理开销稳定可控。
在训练层面,算法团队融合HSDP、序列并行与VAE分块并行的混合训练策略,模型可支撑64卡大规模集群训练,高效完成长时序模型迭代。
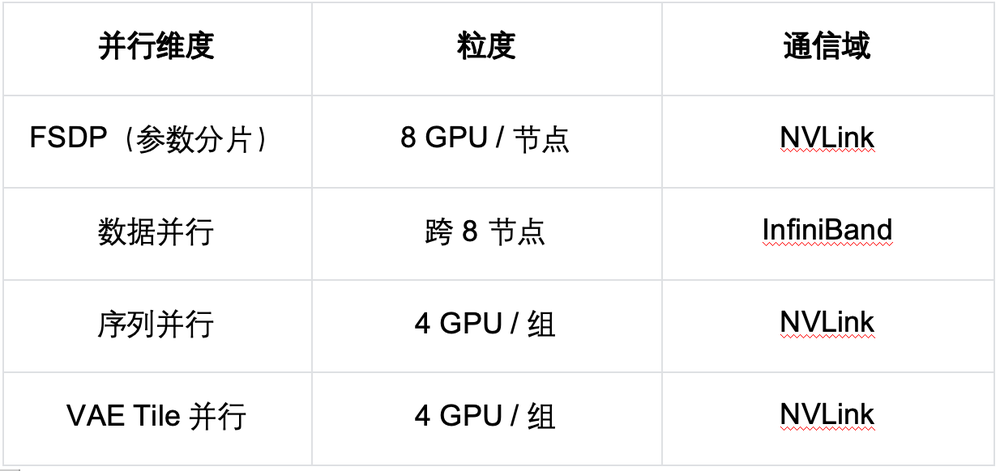
推理阶段,模型则依托KV-Cache、滑动窗口淘汰与序列并行三重优化,实现恒定层级的单步延迟与显存占用。无论闭环生成多少帧画面,模型算力开销始终保持稳定,能够稳定支撑多环境并行实时推演。
结语:地瓜机器人让机器人自主学习环境交互
帧级闭环是Uranus相较普通视频生成模型最核心的差异化能力。该框架能够逐帧接收操控指令、逐帧输出视觉画面,并把生成画面回输作为下一帧的输入条件,也正因这套闭环逻辑,它得以成为具备实操价值的交互式仿真工具
地瓜机器人的算法团队的整套方案以数据驱动为核心,让机器人依托虚拟视觉推演,完成与环境交互的自主学习。
