








智东西(公众号:zhidxcom)
文 | 白鸽
3月9日,由智东西主办,极果和AWE联合举办的中国首场AI芯片峰会在上海浦东成功举办。本次大会共吸引近万名观众参加,到场人数比预计翻了3倍。即使是下午场,依然爆满,有的观众宁愿站着也要听完全场。在大会现场,近40位人工智能及AI芯片业界翘楚共聚一堂,系统地探讨了AI芯片在2018年的技术前景和产业趋势。

在特邀演讲嘉宾中,英特尔中国研究院认知计算实验室主任陈玉荣博士以《发掘AI芯片能力 提升认知计算新高度》为主题进行演讲,系统阐述英特尔在认知计算、情感识别、人脸分析技术以及软硬件结合等方面的成果。以下是由智东西为您整理的陈玉荣博士大会演讲干货。
一、认知计算
开场,陈玉荣博士就详细的阐述了何为认知计算。他表示,认知计算是一套计算机技术,用以模拟人类感知、智能和解决问题的能力。

认知计算如金字塔结构一样,具有多个层次。其最底层则是用过各种传感器进行感知,如麦克风、摄像头以及其它传感器等,然后基于对感知数据的识别,包括对声音、语音等音频信号的识别;对物体、手势、人脸等视觉的识别;以及其他的传感信号,如位置、生物特征等的识别。
在识别基础上就是对多模态语义的理解,包括对各种结构化和非结构化数据的理解,如文本、语音、视觉、情感等。最后,到最顶层才是基于理解的认知,包括对上下文语境的认知,以及对自然人机交互、计划与行动、类人记忆、适应用户的需求和愿望等的认知。
事实上,认知计算的发展和应用是一个过程,它是机器学习算法和传统知识工程扩展结合的结果,其总体目标是提高个人和组织的生产力、创造力。
二、深度学习的部署难题及解决方案
近年来,认知计算所取得的突破仍停留在识别的层次上。得益于深度学习的快速发展,目前计算机已经能够在图像识别,语音识别等领域达到或超过人的平均水平。
深度学习也被广泛应用到其他的领域,如医疗诊断里的肿瘤监测、投资分析里面的文档分类、智能交互的语音助手、工业应用里的产品缺陷监测、生物工程当中的基因测序等。但深度学习也存在挑战,如需要用大量标注数据、计算资源来进行训练,这是深度学习的训练挑战,但陈玉荣博士所要阐述的则是深度学习的部署挑战。
以视觉识别为例,为了提高识别准确率,目前主流的设计方法有两种,其一是将卷积神经网络设计的越来越深。其二,卷积神经网络可以设计的不那么深,但一定要足够宽。使用这两种方法就会带来一个问题,即目前主流的模型参数通常是上千万、上亿甚至更多,这就导致计算空间、存储空间的复杂性非常大,这样就很难将其部署在计算和存储资源受限的嵌入式、边缘设备上。
为了解决上述挑战,除了进行有针对性的高效网络设计以外,另一个主要的办法就是进行DNN模型压缩。
英特尔在此方向上提出了一套低精度的深度压缩解决方案,它可以将DNN的权重参数和激活值表述成低精度的二进制表示,并且,可以实现百倍级的无损压缩,这样就为深度学习推断在硬件和软件上的加速奠定了基础。
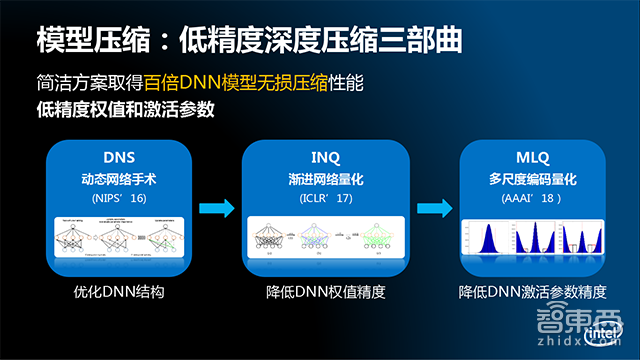
该解决方案共包括了三个关键模块:
1、优化DNN结构的动态网络手术算法DNS。它可以将任意的DNN模型变成疏松的DNN模型,但是不会损失模型的识别准确率。
2.渐进网络量化技术INQ,它可以将给定的DNN模型权重参数变成低精度的二进制表示,同样保证不会降低模型的识别准确率。
3.多尺度的编码量化MLQ,它可以把DNN模型的激活值变成给定位框的低精度表示,同样不会降低模型的识别准确率。
通过把这三个技术结合起来,就形成了一套完整的、低精度的深度压缩解决方案。
接下来,陈玉荣博士详细阐述了INQ技术原理。他表示,INQ技术通过三个创新的操作,即参数划分、分组量化、重训练,从而使得整个量化过程变成一个渐进式的操作过程,同时保证不会降低模型的识别准确率。INQ是第一个无损的DNN量化压缩的解决方案,它没有对任何网络模型类型进行假设,这意味着,它不仅可以用在卷积网络模型CNN上,也还可以用在其他网络模型上。
此外,因其是二进制表示,所以通过INQ技术与量化的模型可以使大部分的乘法操作变成简单的一位操作,同时采用专门的硬件就可以实现很高的加速。另外,量化技术是基于预训练模型的,也就是说不需要从头开始训练,那么这样量化的效率很高。
通过对主流的DNN模型进行实验,在5比特量化的结果显示其量化模型的准确率不但没有降低反而有所增加,在超低精度,也就是在2/3比特的量化结果也显示其识别准确率非常接近全精度的参考模型。
三、促进深度学习推断硬件加速
针对深度学习,英特尔提供了多种技术解决方案,涵盖了从数据中心到边缘端的训练和推断。

通过将低精度深度压缩技术与英特尔的低功耗硬件结合,就可以为雾计算、边缘计算提供深度学习推断的硬件加速能力。例如,通过采用FPGA(现场可编程门列)友好的DNN设计,并结合低精度深度压缩技术,就可以在雾计算应用场景提供更快的速度、更近的延迟和能耗以及更高的吞吐量。
英特尔最新的Movidius超级功耗视觉处理单元Myriad X VPU已经具备了神经网络计算加速的引擎——NCE,将来把它与压缩技术结合,就可以实现低精度的DNN计算。这样,就可以进一步提高在边缘计算上DNN的计算速度和吞吐量。
此外,英特尔还研发出其他芯片,能够支持数据中心和边缘端的各种AI计算。如英特尔凌动、酷睿和至强处理器就可以对诸如机器学习、认知推理等通用AI的算法进行计算,如果算力不够,还可以用FPGA进行灵活加速。
在每种CPU的基础之上,英特尔还会提供广泛的加速器组合,以便满足不同用户的需求。如英特尔的Nervana神经网络处理器,就是专门针对深度学习设计,它可以对高强度的深度学习训练和推断进行加速。另外针对视觉、语音、音频以及自动驾驶等方面的处理,还有专门的英特尔的Movidius VPU、GNA以及Mobileye EyeQ芯片来进行专门加速。
然而,光有芯片是不够的,为此,英特尔还提供了端到端的AI全栈解决方案。其中包括多种计算、存储网络硬件平台;多种软件工具、函数库;优化的开源框架以及各种人工智能平台。
未来,英特尔研究院也在进行其他领域的研究,包括先进算法、神经拟态芯片、自主系统、量子计算。在今年的CES上,英特尔研究院发布了代号Loihi神经拟态芯片,以及代号为Tangle Lake的具有49个量子比特的超导量子测试芯片。
四、软硬协同提升对“人”的认知
英特尔人脸分析研究始于2011年,其中共经历了三个阶段。早期采用比较传统的算法实现了人脸检测识别、微笑检测、性别年龄识别等简单功能。之后结合英特尔架构进行软硬件协同设计,采用更高效的人脸检测识别算法,实现更完整的功能,包括人脸关键点检测跟踪、动态人脸表情识别等。目前,英特尔最新人脸分析技术则是利用了基于深度学习的高效网络结构设计。在实际应用场景中,其功耗很低。
此外,英特尔还实现了三维人脸分析,包括三维人脸建模和增强。陈玉荣博士介绍,他们研发的先进的2D人脸技术已经被集成到英特尔软硬件当中,如英特尔的集成显卡、实感技术SDK等,进一步提高了英特尔用户的视觉体验。
在基于2D人脸分析技术上,英特尔还开发了一套3D人脸分析技术,通过该技术,使用普通的笔记本电脑就可以实现实时的三维人脸建模、跟踪和增强。在会上,陈玉荣博士演示了用参数化表示的三维人脸形变模型,它可以用来模拟任何人的相貌、脸形、表情变化等。这项技术可以广泛用在虚拟现实、游戏场景当中,从而进一步提升用户的沉浸式体验。
除对人脸分析之外,对情感的计算也是认知计算的重要方面。
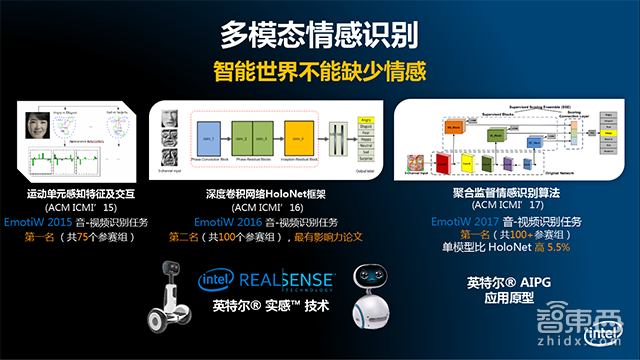
对于人类来说,声音、表情是表达情感的最主要的方式。英特尔通过对情感识别算法的研究,在2015年就提出了基于人工定义特征的人脸表情识别算法,并基于算法研发出了一套音视频情感解决方案。该方案在2015年举办的非受限的音视频情感识别挑战赛EmotiW2015中获得第一名。
2016年,英特尔研发出了全新的深度神经网络算法HoloNet,其速度很快,在普通的CPU上运行速度可达百帧每秒。这样可以满足机器人、智能家居、在线教育应用场景的使用需求。2017年,英特尔又提出了全新聚合监督的情感识别算法,该算法取得了单模型比HoloNet高5.5%的识别率,通过多模型的融合在去年比赛当中再次获得第一名。

