








智东西(公众号:zhidxcom)
文 | CJ
3月9日,由智东西主办的GTIC 2018全球AI芯片创新峰会在上海召开,大会邀请到32名重磅嘉宾到场分享,超过一万名观众报名,会场内座无虚席,会场外甚至还有大量来晚的观众直接选择就地观看直播。

在这次大会中,触景无限CEO肖洪波以“前端智能为安防产生新的数据价值”为题做了精彩的演讲。对于安防中越来越重要的前端智能,触景无限有着许多不同的看法, 以下是智东西整理的演讲干货。
一、传统监控技术无法满足现有需求
触景无限创立于2010年,一直专注做智能感知,在2016年,触景无限开始步入安防领域,致力于为安防摄像头以及无人机等提供智能感知能力。

随着技术的提升和市场的发展,如今的安防已经和以前完全不同。首先,大量的安防数据对传统安防系统提出挑战。摄像头的传感器每天都会产生大量的数据,单个高清摄像头就需要10Mb/s的带宽,2亿摄像头需要2Pb/s的存储空间。安防数据体量非常大,大到需要5000个YouTube才能存储所有摄像头的视频数据。
其次,传统监控技术无法满足现有需求。在很多场景下,很多时候的监控是存储后,靠人力来做筛查,或者是摄像头的数据传输到云端,然后通过云端来做计算分析。因此,传统监控技术的实时性不够好。
想象一个无人机在飞行过程中要做周围物体识别,通过双目摄像头判断周围距离做避障,如果我们需要把数据传到云端,云端有可能要排队,如果附近的无人机同时也在往云端上传数据,两边的数据得不到及时的处理,这样就可能会导致“撞机”。
此外,由于安防的发展,用在家庭里的摄像头也越来越多了,在如家庭的场景中,传统的服务器处理需要把这样的非常隐私的数据联网传输到云端进行分析计算,所以传统监控技术也无法保障一些场景下视频数据的隐私性。
与此同时,和传统的对视频编码进行有损压缩不同,在前端很容易能获取原始数据,可以直接在原始数据上进行处理,并且处理结果可以重新回馈到传感器底层,可以利用智能分析的结果对底层SP( Subspace Pursuit,子空间追踪)算法做优化,从而获取更好的数据质量。
二、多维度感知真实世界
因此,前端智能凭着实时性、隐私性、降低后端压力和提升后端效率和质量等优势成为了安防的升级趋势之一。在会后接受智东西专访时,肖洪波也提到,未来5年会有越来越多的带有前端感知能力的电子产品进入市场。如何利用传感器的感知能力挖掘更多有价值的数据,将是一个重要的课题。

除了图片、视频外,前端智能还可以通过多个数据维度来感知自身所处的真实世界,比如声音、测距、地理位置、激光测距、气压、高度等。触景无限希望在前端把传感器的数据融合在一起,提供多维的数据,在数据的基础之上再做人工智能的分析。
因为真实世界中,人所观察到的数据本身就是有关联的而不是割裂的。人会结合多种信息综合分析,比如把一些距离信息和图象信息做融合,或者说把热感信息和图象做融合,而当我们有多维度数据再分析的时候,往往可以分析出更有价值的信息。
比如说声音的信息,前端智能让摄像头可以通过耳机阵列判断声音传来的方向和角度,可以把现场发来的呼救、枪声、玻璃破碎的声音和摄像头来进行联动。这样的话,当发生突发事件的时候,摄像头可以通过声音的信息调节摄像头拍下合适的图片、视频。
在前端获取数据后,前端需要提供比较微观的数据可测量用于未来对前端设备的预测。所谓的微观主要是在时间的维度,在毫秒级维度对数据进行测量。以火车站场景为例,当距离很远的时候人脸是非常小的,甚至小到无法做人脸识别,这样的数据没有价值。而在距离很近的时候,人脸角度可能因为光照的条件而变得不适合抓拍。因此,前端所要做的就是确定在哪一帧、哪一个点做合适的抓拍,这就需要前端摄像头能根据周围的场景不断地做调整。
三、“在螺丝里做道场”:前端智能面临三大挑战

前端智能和云端相比,虽然具有很多优点,但是同时也面临三大挑战:模型参数大、实时要求高、运算能力弱。
对此,肖洪波表示,前端智能是“在螺丝里做道场”,前端运算力有限、功耗也很低,所以需要把散热、功耗做的非常低。在运算力有限的情况下,需要做模型压缩、优化,这些最后会转化成数学上的优化问题,从而对整个模型进行优化。所以,前端嵌入式的人工智能研究是很多底层的优化工作。
而对于这三大挑战,触景无限认为除了感知数据以外,还需引入时间维度的数据。通过带时间维度的视频数据,可以实现多摄像头之间的联动,在前端获得更多信息,这样的加入时间维度的多摄像头场景叫做前端摄像头的感知阵列。
肖洪波说,通常的模型都是基于卷积神经网络,用图象处理的方式来处理视频。实际前端处理过程当中,会碰到大量的视频数据,而视频数据本身是带有时间维度的,只是以前处理的时候被忽略了。
因此通过这样的多摄像头的联动,可以判断一个人在多摄像头里的身份,实现轨迹追踪。这样可以对未来进行预测,通过时间维度预测以后,实现在前端处理人工智能AI模型的优化处理,获得更好的处理性能。
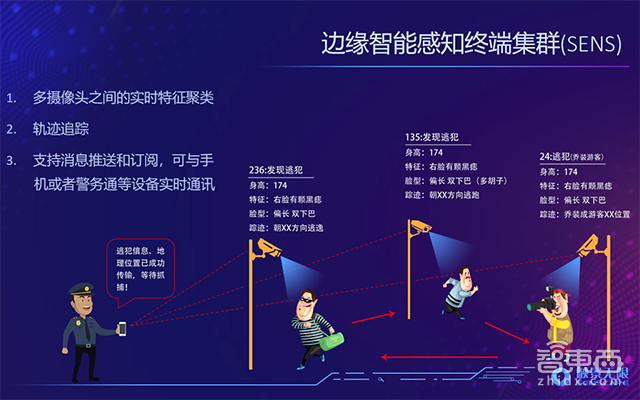
触景无限通过边缘智能感知终端集群(SENS)可以实现多摄像头的联动,这是一个智能感知的模组,体积很小,大概和一块钱人民币硬币一样大,通过这个模组,可以实现扩摄像头追踪、识别,从而形成局部的前端感知阵列。
除了多摄像头联动外,感知数据的优化也非常重要。比如,在一个非常逆光的场景,人脸的后面有一个非常亮的灯,人脸处于逆光环境,呈现在镜头前其实是黑的,而通过算法处理以后可以把人的脸拍的非常清楚,在非常强逆光的情况下也可以获得非常清晰的图象。
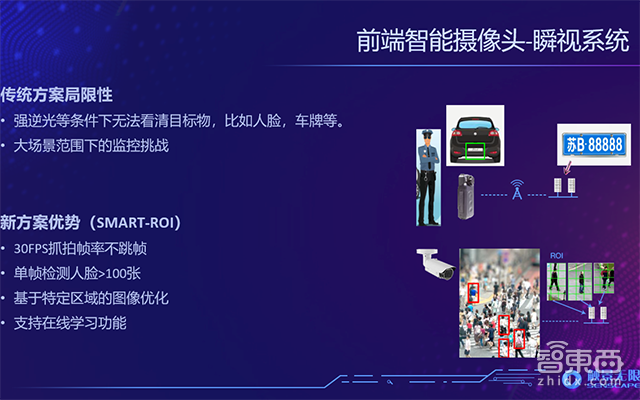
在前端,触景无限实现了算法模型优化工厂,提供嵌入式DPU、FPGA,帮助安防厂商的产品(例如摄像头)获得前端的感知能力。在2017年,触景无限推出了前端抓拍系统瞬视,基于英特尔Movidius芯片打造,可以在前端实现不跳桢的人脸抓拍,单帧图像可实现100张人脸抓拍,并且可以针对特定区域进行图象的优化(比如强逆光)。
结语:安防的前端智能不止人脸识别
提到安防,总会第一个想到人脸识别,大家经常会看到不同新闻中的人脸识别的算法准确度将近100%的数据,但是当思考如何将AI落地安防这个问题时,要想的绝不仅仅只有狭义的人脸识别而已。
人脸识别前的数据采集如何优化,如何抓拍到高质量的图片,采集后如何将多种数据智能结合分析挖掘其背后更大的价值,这些问题都非常值得思考。

