








智东西(公众号:zhidxcom)
文 | Lina
3月15日,由智东西主办,AWE和极果联合主办的AI芯片创新峰会,在上海成功举办!本次峰会报名参会的观众覆盖了近4500家企业,到会观众极为专业,其中总监以上级别占比超过62%,现场实际到会人数超过1800位。
大会现场,20位人工智能及AI芯片业界翘楚共聚一堂,系统的探讨了AI芯片在架构创新、生态构建、场景落地等方面的技术前景和产业趋势。

▲中国半导体行业协会IC设计分会理事长、清华大学微电子所所长 魏少军
魏少军教授是国内集成电路产业的领军人物,是清华大学微电子所所长、中国半导体行业协会IC设计分会理事长,并曾主导编写了《人工智能芯片技术白皮书(2018)》,从定义、脉络、标准以及发展趋势等方面对AI芯片进行了深入而专业的研究,填补了国内空白。
现场,魏少军教授带来了主题为《AI Chip 2.0 的愿景和实现路径》的开场演讲。
一、终端AI成未来市场主导
魏少军教授认为,目前大部分AI服务都在云端,原因是云端已经存在大量AI应用,比如智慧家庭、图像认知、智慧医疗、AI翻译等。
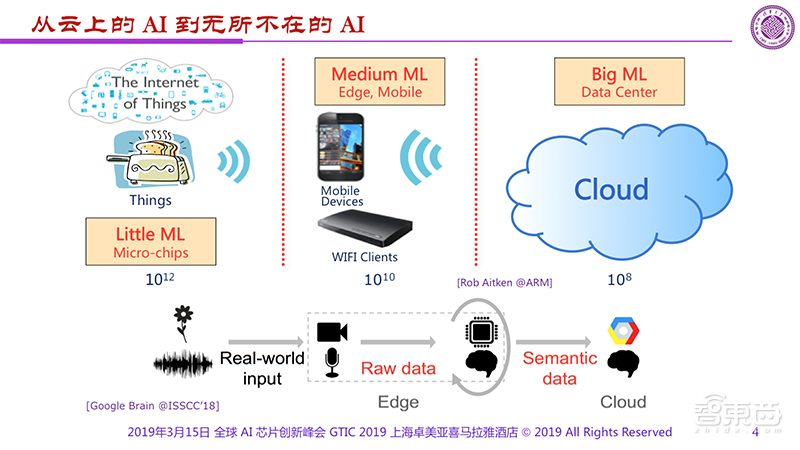
但是,终端侧的应用是更大的潜在市场,AI从“云”走向“端”是必然。展望未来几年的发展,终端应用将会占据AI市场的主导地位。
而对于终端应用来说,功耗限制将会是AI芯片所面临的一个大挑战。
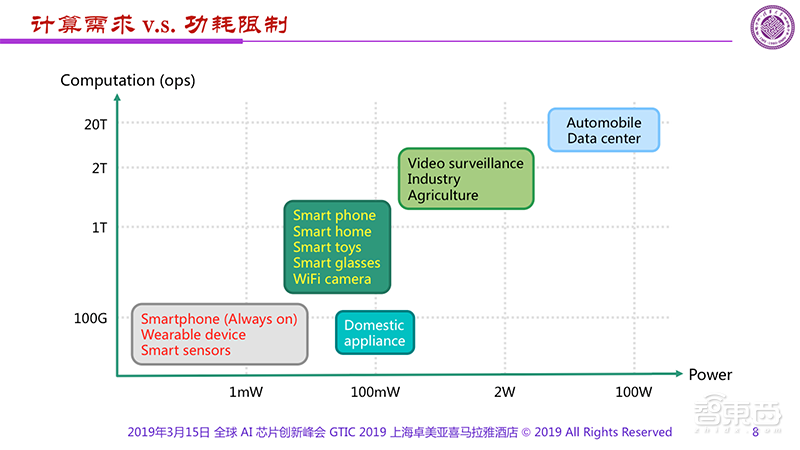
比如,可穿戴设备功耗需要限制在mW级别;视频监控、工农业应用需要限制在W级别;而自动驾驶、数据中心等AI芯片的功耗则可以到百W级。计算需求对应功耗的限制一直是非常难以解决的问题。
与此同时,正如魏少军教授在2018年GTIC AI芯片峰会上提出的,另一个挑战则是目前AI芯片所面临的两个问题:
1、算法仍在不断演进,新算法层出不穷。而做芯片的人最怕算法变,变了就要重新开始。
2、一种算法对应一种应用,没有统一的AI算法。多个AI功能需要多颗AI芯片放在一起。
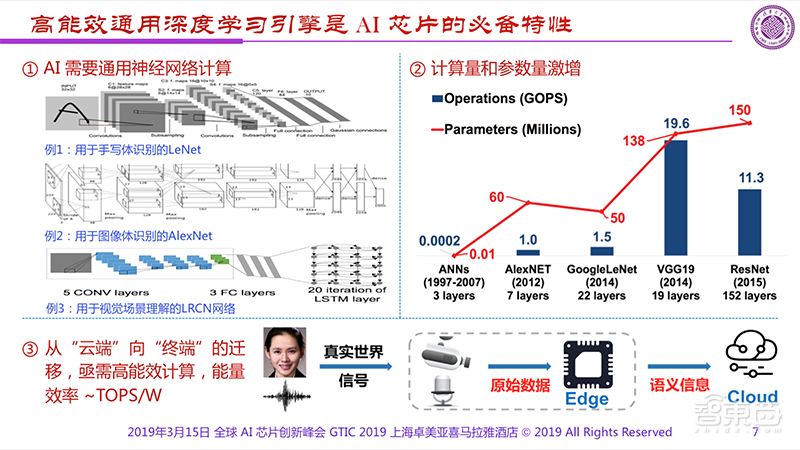
因此,高效能通用深度学习引擎是AI芯片的必备特性。对于终端AI芯片来说,这个引擎最重要的特点就是高能效,必须同时具备高计算力与低功耗两个优势。
二、AI芯片需要1000倍以上的能量效益
下图是是Kunle Olukotun在去年的ISCA演讲中的PPT,他将芯片分成三部分,第一部分是可以更多编程的如CPU,第二部分是少量编程的如GPU,第三部分是不能编程的如专用芯片。
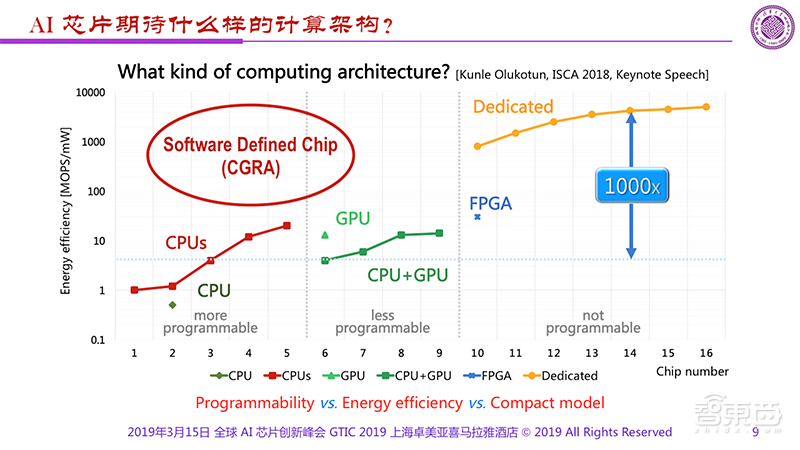
它们间的重要差别除了可编程性外就是能效的不同。从专用芯片到GPU之间有1000倍的能效差距。而1000倍是一个很重要的分界线,如果我们的AI芯片做不到比GPU高1000倍的能效,就不能满足人们在终端侧的需求。
对于终极AI芯片来说,人们希望它既具备高能量效率、同时也具备很好的可编程性,比如图中红色圈的位置。那这样的东西是什么呢?
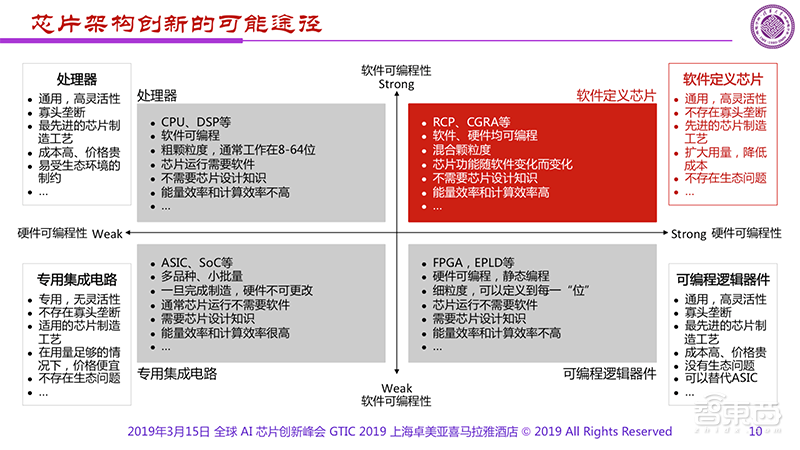
去年魏少军教授团队提出了“软件定义芯片”,而无独有偶,上图的作者提出了“粗颗粒度可重构阵列(CGRA)”的思路,与“软件定义芯片”不谋而合。这样的发展方向告诉我们,如果要解决能量效率的问题,软件定义芯片可能是最适合的一种架构。
对于这种AI芯片来说,不仅仅要注意软件的可编程性,更重要的是硬件的可编程性。
三、AI芯片2.0:终极智慧芯片
最后,魏少军教授还给出了他对AI芯片发展的四个阶段的看法:
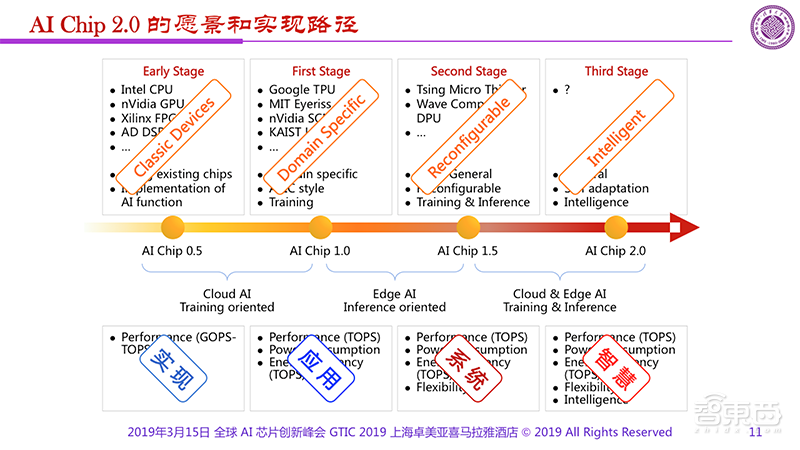
1、AI Chip 0.5阶段。这是非常早期的阶段,人们利用CPU、GPU等已经存在的芯片尝试实现AI的功能。
2、AI Chip 1.0阶段。这一阶段不论是Google的TPU、MIT的Eyeriss、NVIDIA的SCNN等都是专门为AI设计的,其主要是用来做AI训练、我们有了为AI专门设计的芯片。
3、AI Chip 1.5阶段。AI Chip1.5阶段已经开始探索所谓的通用性,所以像Tsing Micro的Thinker、Wave Computing的DPU都属于1.5阶段,它们是半通用的,是可重构、可配置的。
4、AI Chip 2.0阶段。2.0是什么?我们到今天为止还没有答案。但我们可以畅想一下,2.0应该是通用的、自适应的、具备智慧化的架构和芯片。我们正在向着一颗通用的AI处理器方向努力,但这将非常艰难。
AI 0.5和1.0主要还是围绕着云端的AI,以训练作为主题,因为主要玩家是大的互联网公司,所以他们很自然地聚焦到训练层面。从AI1.0到1.5的时候开始出现变化,更多在聚焦边缘、终端,在1.5到2.0的时候云与端可能会结合在一起。
同时,0.5和1.0阶段我们关注算力和功耗,1.5阶段我们关注性能、能效的同时还关注灵活性,而到了2.0,智慧化将会是主流。
对于芯片设计者来说,如何让芯片智能化是一个重要心结。
现在芯片要想在竞争中胜出最重要的是差异化,但差异化太难了。通常芯片设计者会花六个月时间定义一颗芯片,花六个月的时间制造一颗芯片,又卖了六个月,好不容易卖出去后,发现市场上有和你差不多的东西,所以不得不推倒重来。
芯片制造者在定义—设计—销售—再定义—再设计—再销售的迭代中循环往复,差异化随着时间的推进在逐渐缩小。
因此,我们能不能让芯片通过教育、学习的方式使得自己变得差异化——正如我们每个人从婴儿逐渐长大成人的过程?能不能让芯片越用就越有价值?在市场上越用越好?这个问题正是我们一直追求的目标。
附魏少军教授演讲实录
魏少军:大家上午好!感谢主办方再次邀请我来做开场报告,在开始前我有一个小小的请求。这个请求就是:请在座的自媒体朋友们不要照一张相下面加一句话就把我的讲演放到了网上,这让我有一种被“阉割”的感觉。大家要写的话一定要反映我想说的精髓。我知道大家抢新闻有点着急,但还是希望能报道的比较完整,不要出现断章取义的现象,引起误解,特别是不要让听众误解。
今天我只有14张PPT,其中还有3张是去年讲过的。过去一年中我思考了很多,但真正浓缩起来用两张就可以讲完,所以我想今天会很快讲完,不会占用很多时间。
这是我去年最后一张PPT给出的题目:我们是否会出现像CPU那样通用的AI处理器?如果真是这样的话那今天的AI芯片将会怎么走?当然我也提了一个问题,未来的AI芯片很可能会遭遇一些挫折。事实情况是有的说中了,有的我不希望说中的也说中了,所以很遗憾。
不管怎么样,我们可以看到今天的AI服务基本都在云上,很少出现在其他地方。原因是什么呢?原因还是先驱者们在云上做了大量工作,包括智慧家庭、图像认知、智慧医疗、AI翻译等。但是我们说从“云”走向“边”,从Cloud到Edge是大趋势。其实,不同区域的用户数量差异很大,有100量级的差异。如果我们在Cloud有10的8次方,到了IoT就有10的12次方。
Google在2018年峰会上也提出了很有意思的系统框架。不管是什么样的AI,都要从现实社会中获取数据,把原始数据转化成语义化的数据,最后让Cloud来处理,这是一种必然。
在AI走向边缘的过程中,现在看起来还是主要以“通用”作为主要驱动力,但是看未来几年的发展,恐怕终端应用将会占有主导地位,特别是到2025年,以家电为主要应用场景的专用集成电路、专用AI芯片会起重要的引领作用,这也是我们看中的未来发展的重要方向。
当然,我们谈到芯片的时候一定会遇到我去年讲过的PPT内提到的两个问题:一是算法仍然不断地演进不断在变化。我们做芯片的人最怕算法在变,变了就跟不上了;二是我们依然缺少放之四海而皆准的算法。把多个AI功能集合到一起的时候一定会出现要使用多颗AI芯片,还做不到一颗全解决。当然我们希望能够出现对各种算法都有效的芯片,能够找到全新的统一的解决方案,但是非常难。
既然如此,我们就在考虑需要有一个所谓通用的深度学习引擎,如果把它往边缘上推的话就会发现这个引擎最重要的特点就必须是高能效。在高的计算能力和低的功耗两者驱动下,要获得好的芯片显然需要认真地思考用什么样的方式才能做。
分析一下具体的引用场景,可以发现像:可穿戴设备、智能传感器等功耗限制为1mW;家电的等将近100mW;视频监控、工业和农业应用大概是W,但要2T的运算能力;而Automobile、DataCenter可以100W,但至少20T的运算能力。计算需求对应功耗的限制是我们一直面临的、非常难以解决的问题。
我们希望了解什么样的架构才能满足不同的需求呢?如图是Kunle Olukotun在去年的ISCA演讲中讲的。横轴用了1、2、3、4一直到16,我一直看不懂他为什么要用这个,后来我问了一下,据说是芯片的编号而非代表用了多少芯片。这个地方容易产生误解。但是它很清楚地告诉我们可以把芯片分成三部分,第一部分是可以有比较多编程的,第二部分是少量编程的,第三部分是不需编程的。
显然,可以有比较多编程的像CPU,有一定编程能力的是GPU,不需编程的就是专用芯片。可以看到这几者间有重要的差距就是能量效率的差距,如果我们仔细看一看的话可以看到从Dedicated到GPU蓝线之间有1000倍的差距,而1000倍是一个很重要的分界线,如果芯片做不到这一点,显然就达不到目的。
那我们希望最后做的芯片到底出在哪个区域呢?显然希望在红色区域,这个区域具有很高的能量效率以及很好的可编程性。但处于这部分的东西是什么?
去年我们提出“可重构芯片”,或叫“软件定义芯片”可能是一个比较好的架构,很巧的是这位作者提出了“粗颗粒度可重构阵列(CGRA)”的思路,与我们不谋而合。如果能解决能量效率的问题,“软件定义芯片”可能是目前最好的一种架构。
我们要去找的这个“软件定义芯片”架构具备是什么样的呢?我们把软件和硬件的可编程性作为两个轴,构成了四个象限。可以看出传统的CPU、DSP一定处在第二象限;而我们所知的专用集成电路处在第三象限,它具有比较差的软件和硬件可编程性,好处是具有很高的能量效率;我们所知的FPGA和EPLD一定处在第四象限。
如果把已知的芯片都放到了二、三、四这三个象限后,一定很奇怪第一个象限中的是什么?第一个象限对应的芯片应该有很好的软件可编程性,同时有很好的硬件可编程性。如果这两者都成立的话,恰恰就是刚才所讲的“软件定义芯片”,不仅软件可编程,更重要的是硬件也可编程。
有了“软件定义芯片”的志向,我们现在可以讲一下AI Chip 2.0的愿景和实现路径,什么是AI Chip 2.0?我们拉一个横轴,从AI Chip 0.5、1.0、1.5到2.0进行相应的展开。
1、AI Chip 0.5阶段。可以看到AI Chip 0.5是非常早期的阶段,主要是像Intl的CPU、Nvidia的GPU、AD的DSP等。这些芯片都不是为AI而出现的,而是早就存在了。我们只是利用已经存在的芯片尝试实现AI的功能,这个时候我们成为AI Chip 0.5。
2、AI Chip 1.0阶段。在这一阶段,不论是Google的TPU、MIT的Eyeriss、nVidia的SCNN还是KAIST的UNPU,已经是专门为AI设计的了。我称它们为AI Chip 1.0。它们的主要工作是用来做Training,我们可以认为它们是一种领域专用的东西,也可以认为是某种拓展。AI Chip 1.0是真正为AI专门设计的芯片。
3、AI Chip 1.5阶段。AI Chip 1.5就发展很有意思。我认为AI Chip 1.5已经开始探索所谓的通用性,所以像Tsing Micro的Thinker、Wave Computing的DPU都属于AI Chip 1.5。它们是半通用的,是可重构、可配置的,兼顾了两个训练和推理两个方面的内容。
4、当然,我们希望最终能够走到AI Chip 2.0。什么是AI Chip 2.0?今天还没有答案。不过,我们可以畅想一下。首先它应该是通用的,然后它应该是自适应的,最重要的它应该是智慧化的。如果我们真的找到这样的一个芯片架构,这就回答了我去年的问题:到底存不存在一颗通用的AI处理器?我们正在向这个方向努力。显然它非常难。
如果说我们在AI Chip 0.5的时候采用的是一些传统器件,到了AI Chip 1.0已经做到了领域专用,而AI Chip 1.5做到可重构、可配置,AI Chip 2.0就应该是智慧化。
AI Chip 0.5和1.0主要还是围绕着云端应用,以训练为主。由于主要是大的互联网公司在主导,所以他们很自然地聚焦到训练层面。从AI Chip 1.0到1.5,情况开始出现变化,更多聚焦到边缘、即EDGE。可以设想,AI Chip 1.5到2.0的时候训练和推理需要结合在一起。
AI Chip 0.5的时候我们关注的是Performance,希望它的计算能力足够强;AI Chip 1.0的时候不仅要关注算力,也要关注功耗;AI Chip 1.5的时候,在关注性能、能效的同时还要关注灵活性;而到了AI Chip 2.0,我相信智慧化会是主旋律。
可以看出,上面每个阶段所关注的重点是不太一样的。早期更多是实现,只要做出来就好;而到了AI Chip 1.0,应用成为关键;AI Chip 1.5的时候关注的是系统;而AI Chip 2.0的时候关注的是智慧化。
尽管现在我们提出这样的AI芯片发展阶段大家也许不同意,但是我们觉得这是一种不错的方式来总结或者归纳现有AI芯片的整体发展方向。
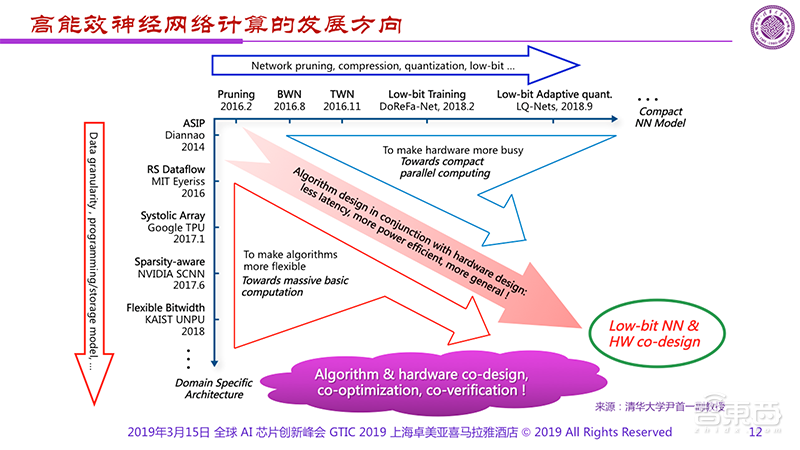
另外,我的同事做了一张高能效神经网络发展方向的图,纵轴是架构在不断创新往下走,而横轴所表现的是不同神经网络模型,中间是通过算法设计和硬件设计的结合去产生更小延迟、更高能效和更通用的产品。
当然,右上角展示的是希望让硬件更“忙碌”以向终端应用提供紧凑型的并行计算;而左下则更多是面向云端的发展,通过让算法(架构)更灵活以提供大规模的并行计算。几种不同的方式通过这样一张图可以显示出相应的发展方向和“路线图”。这张图还可以进一步优化,进一步思考。如果这张图得到大家认同的话,很可能对未来有重要的指导意义。
去年一年我们想了很多,特别是怎么能够把芯片的未来发展给出大家认同的方向。我们为什么要做AI芯片?其实做芯片的人对AI除了应用外内心还有一个心结——要让芯片智能化。在座有不少做芯片的人,大家都有一种感觉,要想在竞争中胜出最重要的是差异化,但差异化太难了。
我们花了六个月时间定义了一颗芯片,花了六个月的时间制造了一颗芯片,又卖了六个月,前后十八个月,好不容易卖出去却发现市场上有差不多相同的东西了,老板马上就会和你急了:对不起,你怎么做的,马上重新来。我们又开始新一轮迭代。所以我们在定义—设计—销售—再定义—再设计—再销售的怪圈中不断迭代,因为产品的差异化随着时间的推移在逐渐缩小。
但是在座各位大家有没有想过,我们出生的时候都是48到52厘米,都是小屁孩,吃喝拉撒等都差不多。为什么20、30年以后每个人变的和另外一个人都不一样。这是为什么?我们越变差异越大。这里面的关键点在于我们是通过接受教育和自我学习使自己变的和其他人不一样。
问题来了,我们能不能让芯片也通过这样的方式变的跟别人的芯片有差异化?假如我们做到这一点是不是我们的芯片越用就越有价值而非越用越没有价值?如果做到越用越有价值是不是就可以在市场上越用越好而非越用越差?这个问题是我们希望解决的,能让芯片成为智慧的芯片是我们追求的目标。我希望通过这个图的解释让大家了解我和我的团队目前正在思考的问题。
谢谢大家!
每日一头条
趋势·深度·犀利·干货,最专业的行业解读
深喉爆料、投稿:guoren@zhidx.com
