








智东西(公众号:zhidxcom)
编 | 董温淑
智东西1月12日消息,谷歌旗下人工智能公司DeepMind开发出史上最智能的代理Agent57。该代理在街机学习环境中表现良好,在57款雅达利游戏中的表现超过人类平均水平。
目前,这项研究已经发表在学术网站arXiv上,论文题目为《Agent57:性能超过雅达利人类基准(Agent57:Outperforming the Atari Human Benchmark)》
论文链接:https://arxiv.org/abs/2003.13350
一、怎样的代理才算是“智能”?
在维基百科上,智能代理被解释为“一个可以观察周遭环境并做出行动以达到目标的自主实体”,具有深度强化学习(reinforcement learning)能力。通常来说,智能代理的形态是软件程序。而要衡量代理的深度强化学习能力,就需要一套普适的测试流程与划分标准。
1、游戏环境是绝佳测试场地
研究人员认为,游戏是测试自适应算法的绝佳选择。原因有:
首先,游戏环境提供了丰富的任务。玩家必须采用复杂的策略来应对。
其次,游戏环境也提供了一个简单的进度度量标准:游戏分数。这就方便了研究人员进一步对智能代理进行优化。
一般来说,研究人员会把人类玩家的平均游戏得分(human normalized scores)作为基准,以此标定代理的深度强化学习能力。例如,如果代理在游戏中表现随机,其得分就为0%;反之,如果代理在游戏中的表现与人类玩家相当或优于人类玩家,得分就为100%。
随着参与的游戏越来越多,代理会不断进行深度强化学习,最终得到高分。
2012年,研究人员提出用雅达利(Atari)2600游戏专门作为街机学习环境(the Arcade Learning environment)。从那以后,这套游戏就成为了对智能代理进行测试的首选工具。该环境共包含57款雅达利2600游戏,也被称为Atari57。
2、Atari57有局限性,智能代理止步不前
测试时,研究人员会记录代理在Atari57游戏中的平均表现(如取所有游戏得分的平均分或中位数),以此反映代理的智能程度。随着时间推移、训练增多,其平均表现会更优秀。
作为受到普遍认同的测试标准,但Atari57也有一些局限性。
平均表现并不能反映出代理在哪些游戏中完成得好、在哪些游戏中完成得差。因此,它也就无法全面反映代理的水平。
另外,从12年至今,街机学习环境包含的游戏数量并未增加。即使代理的平均表现愈加优秀,也只是相对有限的任务数量而言。
举例来说,假设由20个游戏组成一个学习环境。代理a在其中8个游戏中得分500%、4个游戏中得分200%,剩余8个游戏得分为0%,则其平均得分为240%、中位得分为200%。代理b在所有游戏中得分为150%,则b平均得分为150%。
仅看二者的平均表现,代理a比b更智能。但实际上,代理b的能力分布更平均。
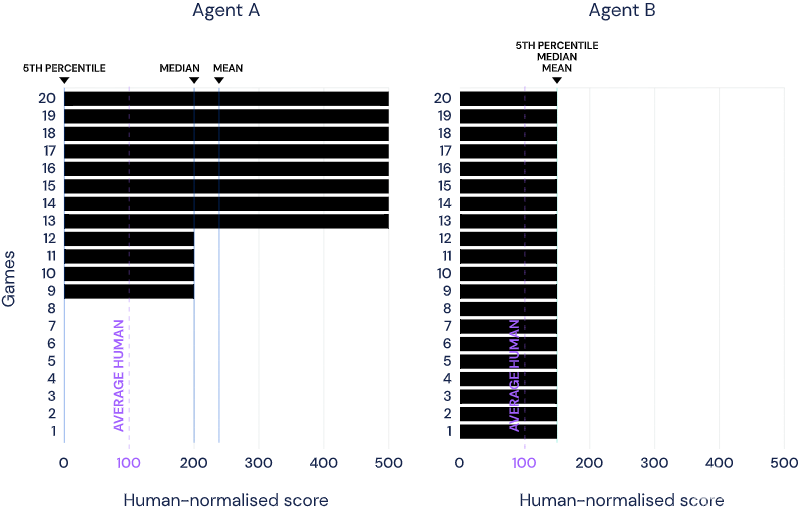
如果任务难易程度不均,这个问题就会加剧:可能代理a只能完成简单任务,而代理b在难易任务上的表现都不错。
在这种情况下,中位表现就会更靠谱。但在测量一般性时,特别是在任务量变大的情况下,尾部表现的相关性又会增加。例如,代理在难度正序排名第五的游戏中的表现更能反映其实际能力。
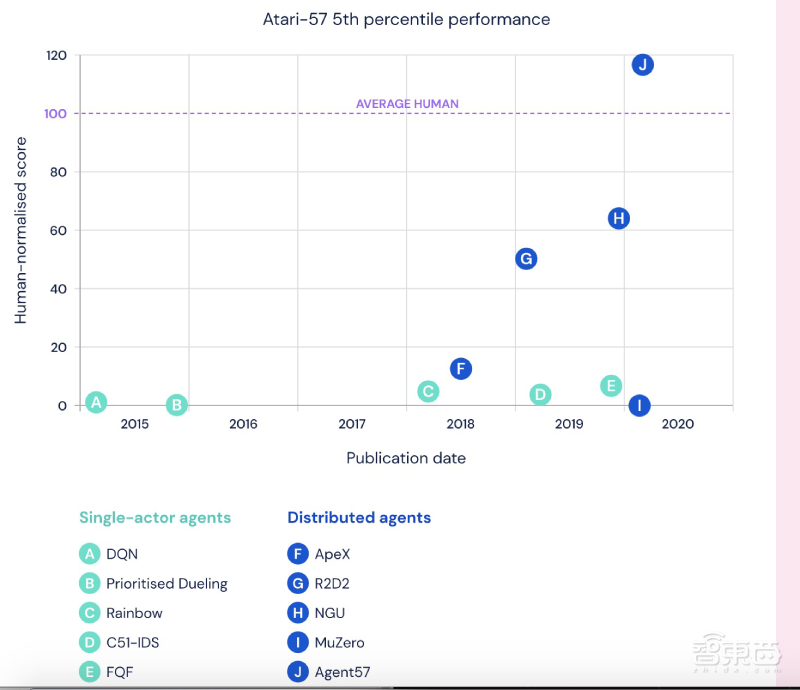
从Atari57基准问世以来,智能代理的平均表现有明显提高。但如果按照平均表现对代理排名,会发现排在倒数的5%代理并没有明显的进步。同几年前一样,它们仍旧在几款难度高的游戏中表现不佳。
二、智能代理迭代发展
为解决这些问题,DeepMind进行了长期探索,开发了几代模型。
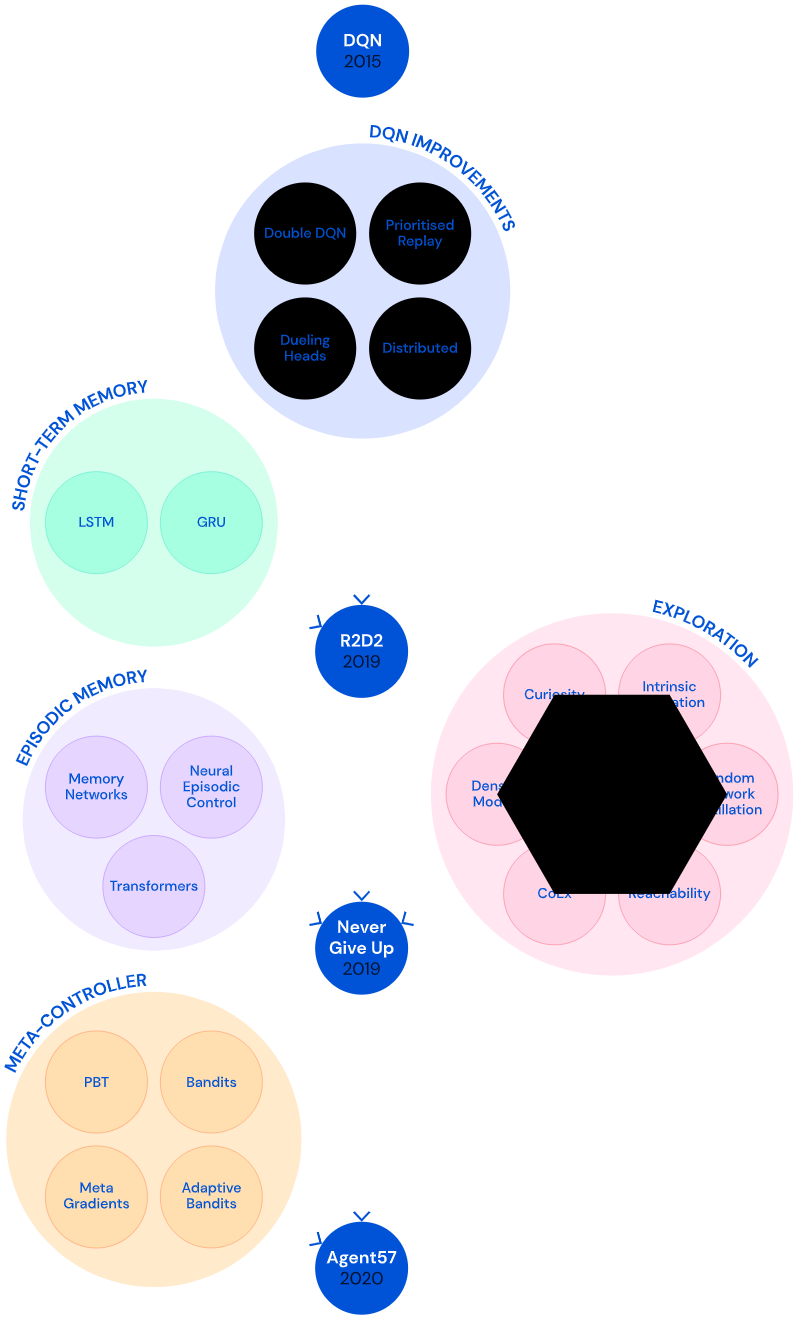
1、初始版本:智能代理DQN
在2015年,DeepMind开发了DNQ算法代理(Deep Q-network agent),这是第一个能在大多数Atari57游戏中达到人类基准的算法。
测试时,DQN在两类游戏中表现不佳。
一种以《索拉里斯(Solaris)》、《滑雪(Skiiing)》为代表。这类游戏的规则是要求代理尽可能快地通过所有游戏关卡,游戏奖励与通关时间成正比。每错过一个门,通关就会被延迟5秒钟。在游戏早期,代理要经过长期的学习来理解“错过了门”这一行为与“通关延迟”间的关系。
另一种以《蒙特祖马的复仇(Montezuma’s Revenge)》、《陷阱(Pitfall)》为代表,是探索类游戏。在这类游戏中,代理要进行大量的尝试(可能是数百个动作)才能通过关卡。
在这两种游戏中,DQN普遍得分较低。为了解决这一问题,研究人员做了一些改进。
2、R2D2:深度分布式RL代理+短期记忆+异策略学习
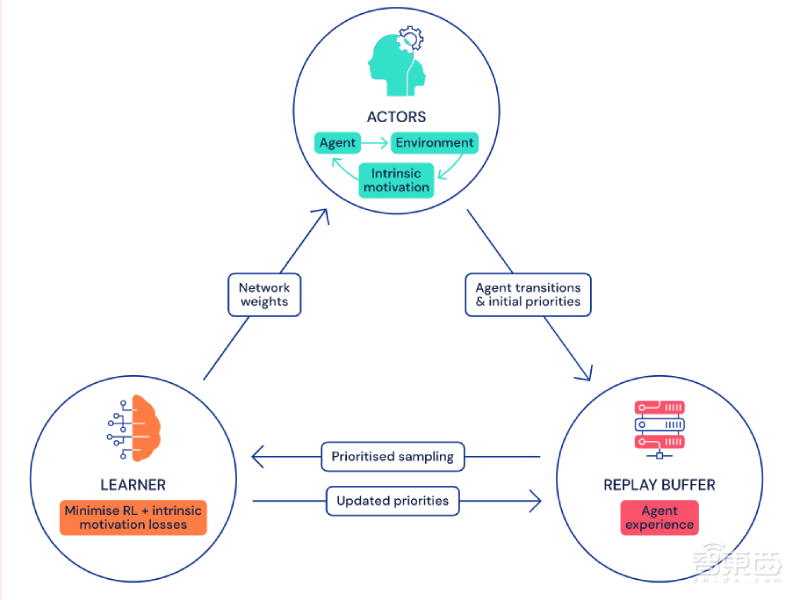
所谓“分布式”,就是将数据收集与学习过程分开。研究人员综合了DQN、Gorila DQN、ApeX三种智能代理的特点,设计出了深度分布式代理模型。它可以在多台计算机上运行、运行速度更快。
actor从环境中收集到数据后,将其以优先重放缓存的形式存储到中央“内存库”。然后,learner会从重放缓存中提取数据,用于训练。
接下来,神经网络会以损失最小化的方式来更新参数。最后,每个参与者与学习者共享同一个网络架构,但保留自己的权重副本。
learner的权重会经常发送给actor,以让actor根据优先级更新自己的权重。
在代理处理任务时,不仅要能留意到当下的情况,还要能借鉴之前的结果。就是说,代理需要有“记忆力”。
举例来说,假如代理从一个房间走进另一个房间,计算每个房间中椅子的数量。如果没有记忆,代理需要数两次数目。但如果有记忆,代理只需用第一个房间中的椅子数加或减去差值,就可以计算出第二个房间中的椅子数。
在深度强化学习中,神经循环网络(如长短期记忆网络)被用于实现短期记忆。
除了拥有记忆以外,研究人员希望代理能做到离线学习(Off-policy learning)。
相比于异策略学习来说,它的对立面同策略学习(On-policy learning)更易于实现。同策略学习是指代理学习其直接行为造成的后果。而Off-policy learning则是代理在没有进行某个行为的前提下,推算出该行为可能会导致的后果。
在Off-policy learning模式下,即使采取随机行动,代理也有可能找到最佳行动方案。
第一个结合了记忆能力和Off-policy learning模式的智能代理是深度循环Q网络(Deep Recurrent Q-Network,DRQN)。
第一个结合了深度分布式结构、记忆能力和Off-policy learning模式的智能代理则是Recurrent Replay Distributed DQN(R2D2)。
三、NGU(前身):定向探索能力+内在奖励机制
DeepMind的第四代智能代理采用情境记忆模式,可以判断出当前情况是否曾出现过,并优先选择完成新任务。这一代智能代理被命名为Never Give Up(NGU)。
1、探索定向探索能力
研究人员对智能代理探索游戏环境的方式进行了设计,首先是采用epsilon-greedy方式。
使智能代理按照固定概率,采取一个随机动作,如果不能继续游戏,就采取目前为止的最佳动作。在epsilon-greedy方法下,代理依赖不定向随机的行为选择来发现不可见的状态,要花费很多时间。
为了克服耗时长的局限性,研究人员引入内在奖励机制,使代理在短时间内访问尽可能多的部分。内在奖励机制分为长期新颖性奖励和短期新颖性奖励。
2、长期新颖性奖励
当代理遇到其从未处理过的情况时,就会触发长期新颖性奖励(Long-term novelty rewards)。
算法依据状态密度函数来判定代理是否处于全新的环境中,即算法会依据代理当前状态在总体状态中发生的频率进行调整。如果密度较高,长期型新颖性奖励就低,反之则高。
这个模型也存在一些问题。在高维空间中,学习密度模型常由于维度灾难而出现问题。在代理模型中表现为灾难性遗忘(catastrophic forgetting),即遇到新情况时,代理会忘记之前的信息。还有可能发生无法为所有的输入提供精准输出的情况。
3、短期新颖性奖励
短期新颖性奖励(Short-term novelty rewards)则用于鼓励代理去探索近期没有遇到过的状态。情境记忆能力与短期新奇奖励相关性较高。
NGU可以快速学习一种实时调整的非参数密度模型(non-parametric density model)。在这种情况下,奖励的大小是通过测量当前状态与以往状态之间的差距来决定的。
但是,并不是所有较大的差距都指向有意义的探索。假设被应用于导肮,运行短期奖励机制的代理将关注每一个微小的变化,造成很大的计算量。
为了避免无用计算,代理需要学习与探索目标相关的特征,并且只计算这些特征之间的差距。
通过这些改造,NGU在《陷阱》游戏中取得了高分。就是说,智能代理在探索类游戏中的表现有所提升。但是,NGU在那些简单游戏中的表现则不太好。平均而言,NGU的表现不如R2D2。
四、Agent57:NGU+自适应元控制器
在NGU的基础上,智能代理继续迭代。
除了上述已有的能力,研究人员还希望新一代智能代理能够判断在什么时候应该探索、什么时候应该进行开发,为此引入了元控制器(meta-controller)的概念。
元控制器允许代理的每个参与者在近期和长期新颖性奖励之间进行权衡,同时探索新状态和利用已知状态。
将NGU与元控制器结合,Agent57横空出世。
数据显示,Agent57在57款测试游戏中的表现均超越人类基准,平均得分为4766.25%,中位得分为1933.49%,在难度排名前五的困难游戏中分数则为116.67%。这已经优于以往的所有智能代理模型。

总的来说,Agent57在简单游戏和困难游戏中均表现优异,强化学习能力有普遍提升。
结语:Agent57成RL能力最强智能代理
从2015年起,经过多次迭代,智能代理Agent57横空出世。Agent57在NGU基础上添加了元控制器,可以判断什么时候该探索、什么时候该开发,还具备时间敏感性。
目前,Agent57在Atari57中每项游戏的表现都超过了人类基准,是史上最为智能的人工代理。
如果加大计算量,Agent57还能达到更优的表现,这说明它有着超强的学习能力。研究人员称,经过进一步完善,Agent57或能落地,应用于勘探、规划及信用赋值(credit assignment)。
文章来源:DeepMind,arXiv
