








芯东西(公众号:aichip001)
编辑 | 心缘
GTIC 2020全球AI芯片创新峰会刚刚在北京圆满收官!在这场全天座无虚席、全网直播观看人数逾150万次的高规格AI芯片产业峰会上,19位产学界重磅嘉宾从不同维度分享了对中国AI芯片自主创新和应用落地的观察与预判。
在峰会下午场,光子算数创始人兼CEO白冰以《AI芯片的另一条路:光子芯片》为主题发表演讲。
 ▲光子算数创始人兼CEO白冰
▲光子算数创始人兼CEO白冰
光子算数是国内少有的光子AI芯片赛道玩家。在演讲中,光子算数CEO白冰主要探讨了光学芯片的工程化进展、市场定位及目标客户、具体研发实施路径及相关适配算法等话题。
白冰提到,当前光学AI芯片仍处于较早期阶段,光子算数已做出测试级产品,于今年交予部分服务器厂商客户进行测试。
以下为白冰演讲实录整理:
一、光学芯片工程化进展,已至测试阶段
与常规数字芯片不同,白冰所创立的光子算数,采取了另外一条技术路线——光子芯片。
白冰说,用光学做计算处于比较早期的阶段。目前光子算数团队已将其做成测试级的产品,并于今年放至服务器厂商客户处进行测试。
作为一家初创公司,光子算数和大学、研究所等几家单位共同工作。其早期样片集成了几百个不同的光学单元,比如有电光转换,把电信号加载到光载波,然后通过传播到片内的光学组合,完成一些特定的函数变换。跟传统的计算特征不同,它不是面向加减乘除,而是直接完成一个复杂的变化过程。
这被称为可编程光子阵列芯片FPPGA(Field Programmable Photonic Gate Arrays),其中的光学单元可以通过电控,控制重新的连接组合方式,实现不同的复杂函数。也就是说,FPPGA具有可重构的特性。

光学芯片加速的不是完整算法,和所有的数字芯片一样,光学芯片面向复杂函数做加速计算,其计算对象是特定算子。光的劣势在于不是特别灵活,但是在某些函数上有优势。
整个系统是光电混合的,数据在光电两部分中完成一个流动,执行一个完整的计算过程,由光学、电学芯片组构成光电混合AI计算硬件系统。
光电混合系统仍要做到软硬协同,开发适合光学加速的算法,使得光电混合系统的硬件物理架构与算法的运算/访存特征相匹配。
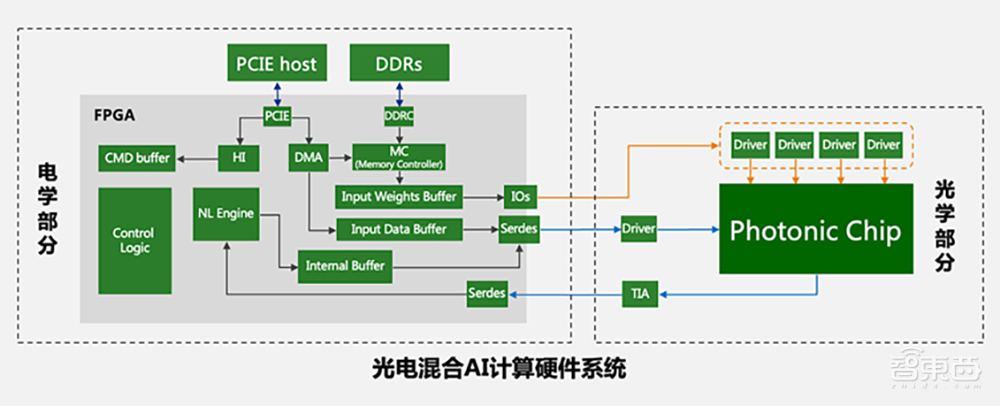
从技术架构图可以看到,左边是电学部分,包含逻辑控制、缓存等,以及专用的定制化IP。考虑到与光学芯片匹配,这些IP与传统的数字IP不一样,需要定制化开发;右边是光学模组,除了光学计算芯片外,还有一颗DFB激光器芯片,还有驱动、TIA以及小型的控制、电源芯片等组件。
中间采用热插拔的方式,跟通信模块一样。之所以选择这一方式,是因为光子算数团队考虑到光芯片、电芯片放到一起,可能卖不出去,因为很难拼得过GPU,考虑到其产品定位,因此做成插拔型。
光子算数与高校一起打造了面向服务器的光电混合AI加速计算卡,目前已完成一些定制化加速任务,包括机器学习推理、时间序列分析等特定任务。白冰说,计算卡现在的性能可用,不过还比较初步,能做到36路1080P视频同步处理,功耗不到70W,算力资源相对有限,混合精度下峰值算力接近20TOPS,光部分为低精度,电部分为高精度。

计算卡封装有光子协处理引擎模块,散热器、驱动、控制器、TIA、一些计算控制部分和赛灵思FPGA芯片,数据在光电之间形成循环流动。光的定位为电做协处理加速。
其中光子协处理引擎模块用的是两个QSFP28的光通信接口(每个都是100GB/s),光通信物理接口非常成熟,其光学带宽大约达200GB/s,典型功耗达7W,算力在1.2TOPS左右。该模块支持热插拔,不需要经过预调,内部封装了一些适合于用光学做的特殊的算子函数,比如随机投影、高维空间变换映射、压缩、小规模卷积、时间序列等高算子。现在该模块还比较初步,白冰透露道,下一阶段,光子算数会进一步扩大其规模。
光子协处理引擎模块里面是两层结构,上面是控制模组,其二级控制缓存处理随时可以换,以适应下一步软件迭代;下面是光学运算模组,包含整个光学计算部分,其中集成了大量的光学单元,为了一些特定的函数,可以做低延时、低能耗的变换过程。

完整计算过程是FPGA接收的数据从电接口进来,经过驱动放大,驱动光芯片上的调优器,把信号再返到光上,经过片内传输完成变换,然后再变成电信号返回。
目前光子算数已将一些光电混合AI加速计算服务器提供给机房和IDC试用与测试,接口是标准的PCIe口。此外,其服务器也与一些国产操作系统和CPU厂商做了适配。

白冰坦言,该服务器目前性能仍较有限,70W运行功耗下,大概能做三四十路的视频同步处理,跟纯电比没有那么强。
下一步,他们考虑将光的部分带宽扩大,进一步提升算力。当前在光通信领域,100GB/s是主流,200GB/s比较少,400GB/s、800GB/s主要有一些大厂在做,目前还没推出产品。尽管做这块成本较高,但这是比较切实可行的已有方案。
二、热插拔式模块,可由大厂软件调用
接着白冰谈到第二个话题,光学芯片的产品定位,即这个东西做完之后,卖给谁?
如果想在云端替代NVIDIA GPU,是非常困难的,其核心竞争力在于它的软件工具。把电和光放到一张卡上,要开发完整的软件套件,工作量非常大且代价很高。当然云端加速计算卡也可以做定制化,但定制化在云端的适用空间会相对有限,这是做云端AI芯片的所有公司共同面临的窘境。
光子算数为什么选择做成热插拔方式?实际上,这是将适合用光学做的特定算子封装到光学模块里,通过热插拔接口和国内大厂的加速计算卡插在一起,这种接口制都是成熟的,开发者使用大厂的软件工具,即可通过API调用光子算数的模块内嵌特定算子。面向具体应用,开发者通过大厂软件工具,开发由光子算数的光学算子与大厂原有的电学算子组成的光电混合算法整体。
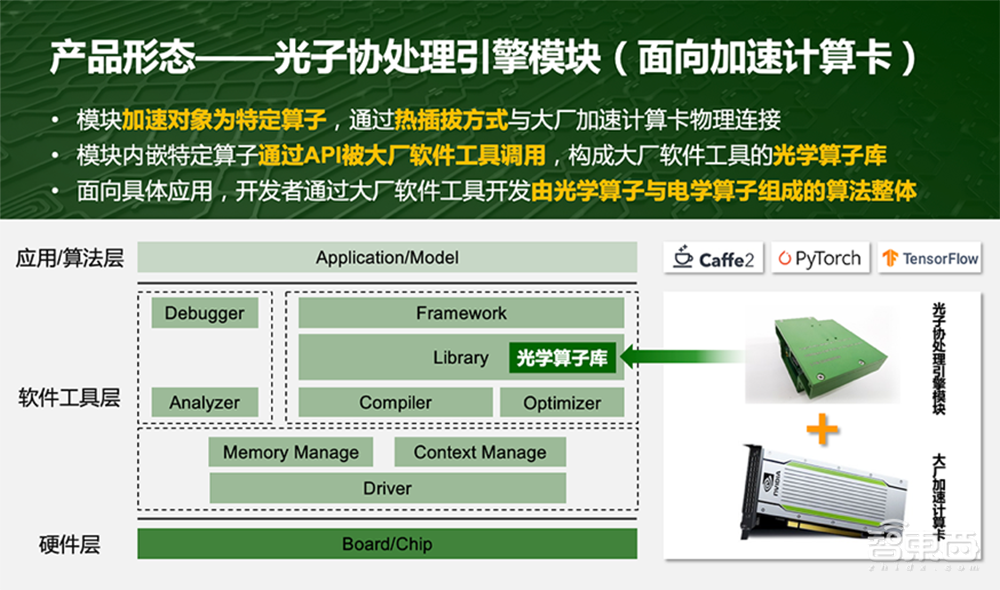
光子算数对自己的市场定位是提供传统加速计算卡的升级组件,使传统加速计算卡提升性能、降低能耗、降低成本,不受制于软件工具。消费者依然买大厂的卡和工具,如需升级,即可选用光子算数的模块。
白冰提了一个形象的比喻,用一张传统卡加上光子协处理引擎模块的效果,相当于给汽车配了一个涡轮增压。

三、研发实施路径:算法先行,硬件跟进
白冰还谈到关于研发路线的建议。他们研发的内容是系统性工程,相较于设计新型的光学计算单元,难度是可以克服的。
更多的,其行业特征特别像光模块,它的行业拓展是小芯片、大组装,其封装和组装成本占整个的70%,是一个系统工程。更主要的,要做软硬系统的匹配,同时硬件要做到光与电的协同,其中包括一些算子、标定的东西并涉及到一些关键技术。
最核心的,要做适合光学做的算法,算法先行,硬件跟进。目前市面上的传统算法不太适合光学芯片去执行,计算机发展这么多年,一直是软和硬耦合在一起发展,“硬”一直是数字芯片,所以算法里嵌了很多数字芯片的基因,用光学硬件很难加速。
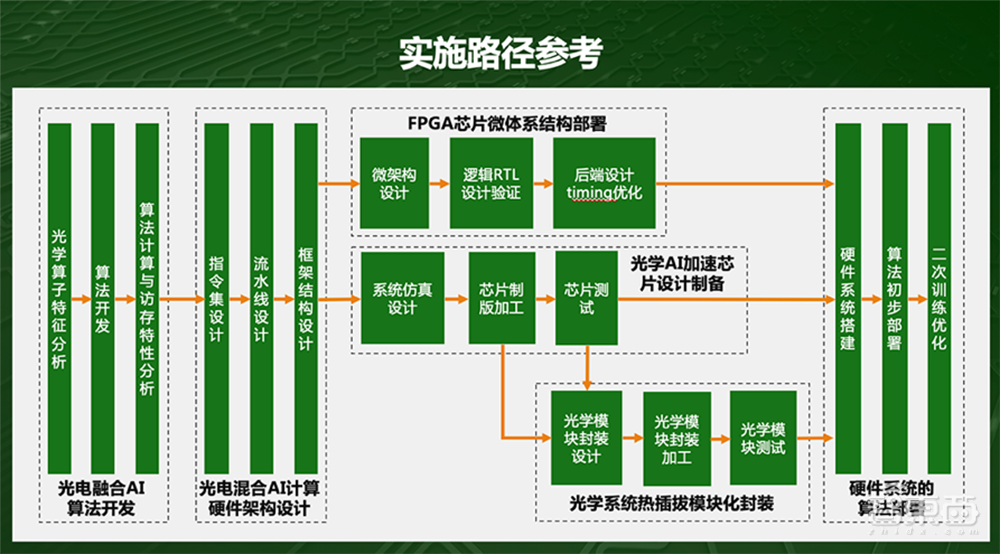
因此首先要开发适合光学做的算子,给光学算子配一些数字算子,去组成完整的算法,然后来分析光电混合算法的运算和访存特征,再之后再设计硬件,如何给算法加速。
“这是我们做的核心关键思路,这也是为什么很多公司目前做不出来的原因。”白冰说。
四、适配光学计算的算法示例
那么,哪些算法适合用光学计算去处理呢?
白冰举了些例子,比如光学随机投影,用光学芯片物理实现无需复杂精确控制,加工容差大、一致性要求低。该方案有循环的效果,不是卷积,而是对数据直接进行维度的变化,直接能做非线性的处理,比如升维或压缩这样。
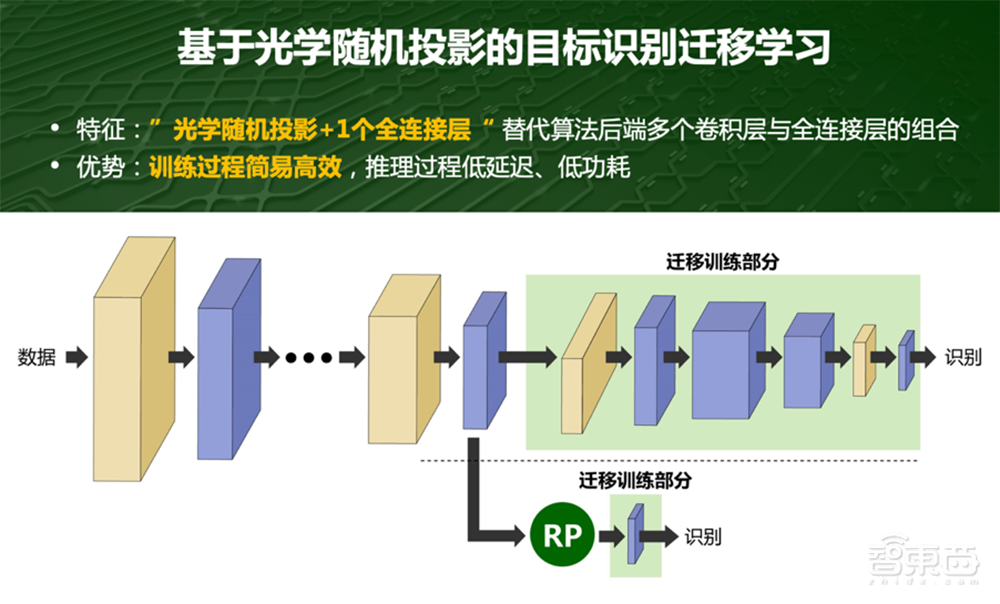
例如对平面上的目标进行分类,用一条曲线可以把它分开,曲线是比较复杂的,算法里面可能对应很多层,在处理之前,可以将数据扔到光学芯片里,做一个升维操作,数据从二维空间变到三维、四维空间,多了Z轴。这个投影用光学做的话没有代价,在电里面用一个线性的平面就可以把两类目标区隔开,可以把十层的网络压缩到两层,这样就是投影变换,光学芯片会有内部的架构。
光子算数把光学函数和数字算子组成了关键的光电混合算法,经尝试,至少可以跟市面上主流的算法做更新。
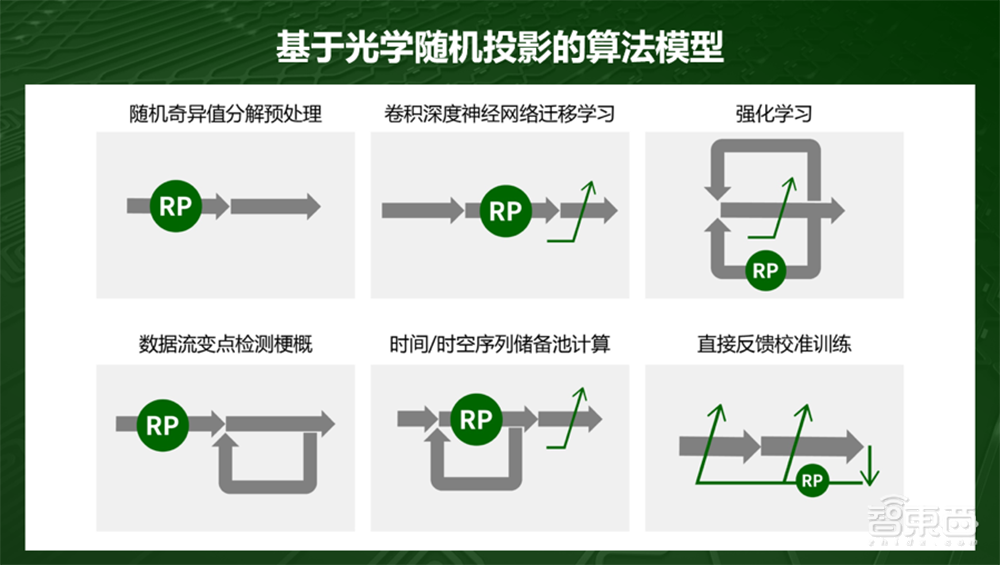
比如基于光学随机投影做目标识别迁移学习时,后半部分进行重新训练,算法训练量还是很大的。其实可以不走绿色部分,直接在蓝色块用光学芯片做预处理,后面加简单的线性层,就可以完成任务,做一个维度的升维变化。
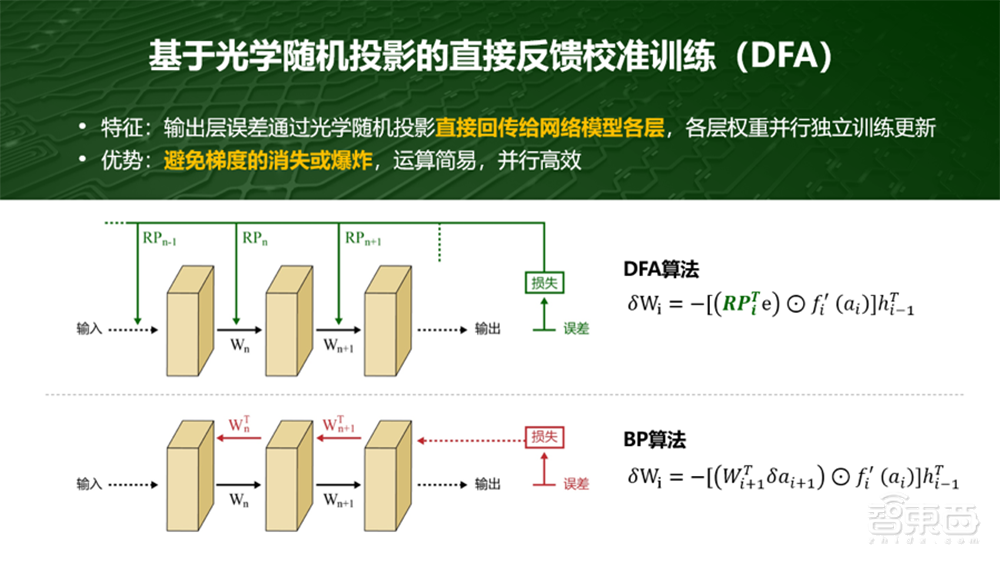
再比如训练时,通常会用BP,连续求导会有梯度消失或爆炸的问题,另外训练量也比较大。用光学做,可以直接将输出层Loss通过光学随机投影直接回传到不同的权重层,每层并行独立更新权重,这样可以做并行训练处理并且避免了连续求导的过程。
尽管这一领域相对早期的,主要面向特定化的市场,但可以看到,它已在某些领域有些成熟化的产品出现和得到应用。由于当前光学芯片主要作为协处理器,光子算数也在持续地与做电学芯片的大厂积极沟通合作。
以上是白冰演讲内容的完整整理。除白冰外,在本届GTIC 2020 AI芯片创新峰会期间,清华大学微纳电子系尹首一教授,比特大陆、地平线、黑芝麻智能、燧原科技、壁仞科技、知存科技、亿智电子、豪微科技等芯片创企,全球FPGA领先玩家赛灵思,Imagination、安谋中国等知名IP供应商,全球EDA巨头Cadence,以及北极光创投、中芯聚源等知名投资机构,分别分享了对AI芯片产业的观察与思考。如感兴趣更多嘉宾演讲的核心干货,欢迎关注芯东西后续推送内容。
