








芯东西(公众号:aichip001)
作者 | 韦世玮
编辑 | Panken
芯东西12月18日消息,昨天,芯东西等少数媒体与英国AI芯片独角兽Graphcore高级副总裁、中国区总经理卢涛,Graphcore中国工程总负责人、算法科学家金琛,进行了一场深入交流。
这场交流围绕的主角正是Graphcore在今年7月发布的专为AI任务设计的第二代IPU,以及用于大规模系统级产品IPU-Machine: M2000(IPU-M2000)。
据了解,IPU-M2000是一款即插即用的机器智能刀片式计算单元,搭载第二代Colossus IPU处理器GC200,采用7nm制程工艺,由Poplar软件栈提供支持,易于部署。

同时,Graphcore还基于16台IPU-M2000构建了模块化机架规模解决方案——IPU-POD64,主要用于极大型机器智能横向扩展,具有灵活性和易于部署的特性。
此外,两位高管在分享Graphcore在今年12月最新动态的同时,还公布了第二代IPU的Benchmark,并分享Graphcore在中国以及全球的业务和业务落地情况、合作伙伴生态建设等信息。
一、IPU-POD64已全球发货,可横向及纵向扩展
今年12月,Graphcore发布了面向IPU的PyTorch产品及版本和Poplar SDK 1.4。同时,还公布了IPU-M2000应用测试性能及源码开放。
卢涛谈到,IPU-M2000是目前世界上继英伟达GPU、谷歌TPU后,第三个公开发布的能够训练BERT-Large模型的AI处理器,并已在Benchmark Blog、Benchmark charts、Performance results table等官网发布上线。
此外,IPU-M2000将在2021年上半年正式参与MLPerf性能测试,Graphcore也已加入MLPerf管理机构MLCommons。
卢涛重点谈到了IPU-POD64,该方案实现了X86和IPU智能计算的解藕,目前该产品已在全球范围内发货。
他认为,IPU-POD64是目前市面上唯一可纵向扩展和横向扩展的AI计算系统产品。
简单来说,在纵向扩展上,IPU-POD64可以实现从一台M2000到IPU-POD16(4台M2000),再到IPU-POD64(16台M2000)的软件透明扩展,且无需任何软件修改,单机即可进行集群规模的运算。
从横向扩展角度看,IPU-POD64还可实现多台IPU-POD64的横向扩展,最大可支持6.4万个IPU组成的AI计算集群。
目前,IPU-POD64目前已在全球范围内发货。卢涛提到,明年Graphcore在中国发展的两大重点,一是落地、二是生态建设。

二、在BERT-Large训练时长比A100缩短5.3倍
金琛主要向大家详细介绍IPU-M2000在各模型上的训练和推理等相关数据,既包括CNN模型EfficientNet,还包括语音模型Deep Voice、传统机器学习模型MCMC等。
例如,集成了16台M2000的IPU-POD64在BERT-Large上的训练时间,比一个英伟达DGX A100缩短了5.3倍,比三个DGX A100缩短了1.8倍,总体拥有成本的优势接近2倍。
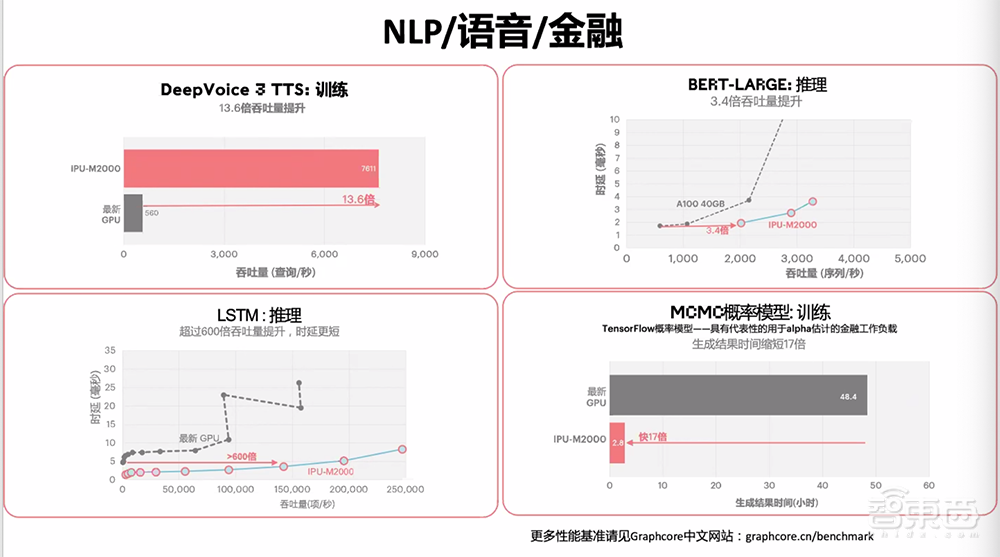
在EfficientNet-B4上,IPU-M2000的推理吞吐量比目前市面上最新GPU提升超过60倍,时延缩短超过16倍。
同时,IPU-M2000在面向NLP、语音和金融等不同领域模型训练和推理的性能结果也表现不错。
那么,IPU-M2000具体是如何支持PyTorch?
金琛谈到,在PyTorch代码里,他们引入了一个叫PopTorch的轻量级接口,通过这个接口,用户可基于当前的PyTorch模型做一个非常轻量级的封装,通过这个封装即可无缝地在IPU和CPU上运行模型。
当前的POPLAR SDK 1.4版本可同时支持模型并行和数据并行,但如果用户想做跨机柜的模型并行和数据并行,则需要等到下一版的SDK。

三、卢涛:英伟达是唯一挑战,中短期内要做到市场第二
金琛提到,从IPU-M2000在多个大型复杂模型中的测试结果显示,其性能表现均优于市面上主流的GPU处理器。
但实际上,当下模型算法演进的速度远快于芯片性能的提升,这些主流模型测试的结果对现实落地应用的指导性意义又有多大?
卢涛认为,AI性能基准测试的结果对现实落地的指导意义还是很大的。
假设,现在要在互联网场景落地或部署NLP等相关技术,BERT-Large就是一个很大的模型,比企业自己采用的模型还要大。
另一方面,不管未来AI处理器或CPU能否满足超大规模模型或多模态模型的增长,至少目前BERT-Large是一个对工业界和研究界有价值的基准。最实际的意义是,如果一家企业的芯片通过了BERT-Large测试,那么也相当于具备了在市场落地的入场券。
在卢涛看来,当下Graphcore面临唯一的巨头挑战还是英伟达。不管是英伟达的GPU或CUDA,还是其多年和开发者、社区共同建立起来的统一AI加速计算生态,都更具挑战性,也是Graphcore更加关注的。
“但Graphcore对未来很有信心。”卢涛提到,一是其处理器在不同的应用领域都体现了真正的价值,并且在主流Benchmark中也证明了自身产品的收益;二是其不少合作伙伴在GPU上难以解决的任务,反而在IPU上可以实现。
“只要我们的IPU有价值点和价值定位,始终会有客户愿意买单。”他说,尤其随着Graphcore和合作伙伴对SDK的不断打磨,从GPU迁移到IPU的难度将会比大家想象的低得多。
未来,Graphcore在中国市场的策略是要将互联网+云计算作为自身的第一大落地场景,到2021年,要在中国的云计算和互联网市场外再突破一到两个主流行业,例如金融、汽车、智慧医疗、智慧教育等。
与此同时,卢涛也谈到,Graphcore的中短期目标是希望在未来几年内,在数据中心AI训练和推理上的芯片发货、批量部署等方面,做到市场第二名的地位,仅次于英伟达。
结语:AI芯片市场新老玩家混战加剧
作为“闯入”中国AI芯片市场的少数国外独角兽之一,仅成立四年的Graphcore可谓是成长迅速,不仅相继推出自研IPU加速在数据中心AI训练和推理领域的竞争,还与阿里巴巴、微软等企业合作,逐步构建起面向开发者的软件和开源生态。
但也正如卢涛所说,在当下的人工智能领域,以GPU席卷市场的英伟达仍是一个重要的挑战。要想早日“超车”英伟达,Graphcore需要做的不仅仅是在芯片领域不断精进和创新,实现落地应用的降本增效,如何更好地瞄准市场,从小的着力点逐步加速超越,也是这个年轻的挑战者需要持续思考的问题。
