








智东西(公众号:zhidxcom)
编辑 | 韦世玮
智东西6月5日消息,近日,在落幕不久的GTIC 2021嵌入式AI创新峰会上,知存科技CEO王绍迪博士以《存算一体AI芯片:AIoT设备的算力新选择》为题,为大家解读了存算一体技术如何带来更加高效的AI计算。
作为存算一体AI芯片赛道的领军者,知存科技主要研发基于Flash的存算一体芯片。王绍迪谈到,现在行业已经进入到了后摩尔时代,尤其当芯片进入到7nm和5nm阶段后,研发进度放缓,芯片研发成本急剧增高,每一次迭代单个芯片成本增加1倍。

▲知存科技创始人兼CEO王绍迪
但碎片化的IoT市场对先进工艺芯片的需求并不强烈,反而更青睐低成本、低功耗、易开发的芯片。不过,目前芯片都采用传统的冯诺伊曼架构,最先进的存储器仍采用1X工艺,“所以摩尔定律走到这个阶段,存储器的速度很难满足现在行业的需求。”王绍迪说。
在他看来,现在行业大多都面临着存储墙问题,存储器的数据搬运慢、搬运能耗大,缓存的大小和密度都很难提升。为了解决存储器瓶颈的问题,许多公司都采用了不同的方案,包括3D Xpoint、近内存计算、近存储计算和存内计算。
其中,王绍迪认为存算一体是最高效率的AI计算。今年知存科技发布了基于存算一体技术开发的第二代芯片WTM2101,算力相比第一代提高10倍,主要面向智能语音和智能健康领域,AI算力达50Gops,预计今年第四季度实现量产。
以下为王绍迪演讲实录整理:
一、摩尔定律发展放缓,先进工艺芯片研发成本高昂
存算一体是新兴的芯片架构,已经研究了很长时间,嵌入式AI也是一个非常新的技术,最近一年内才开始落地。我们先来谈谈存算一体芯片技术的研发背景。
摩尔定律一直陪伴着我们的成长,在过去10到20年里,硬件设备的芯片每年都以两倍以上的速度提升,同时芯片的成本也在降低。尤其从2000年到2010年之间,摩尔定律的增长速度都是很快的,符合每18个月算力提升一倍,成本降低一倍的节奏。
但自2010年之后,摩尔定律已经逐渐放缓,我们很难再看到每过一、两年芯片就实现速度翻倍,成本降低。在2011年之后,每代芯片的更迭只有接近10%的性能提升。
当芯片进入7nm、5nm制程后,芯片的研发进度逐渐放缓,越来越少的玩家在先进工艺上进行研发,包括行业内能够做先进工艺的代工厂只剩下三星、台积电两家,其它很多代工厂逐渐放弃了先进芯片的研究节点。
导致这一现象的原因有几个。芯片快速发展的最主要是商业驱动,我们投入新的工艺,到新的技术节点上是不是有足够的商业回报?
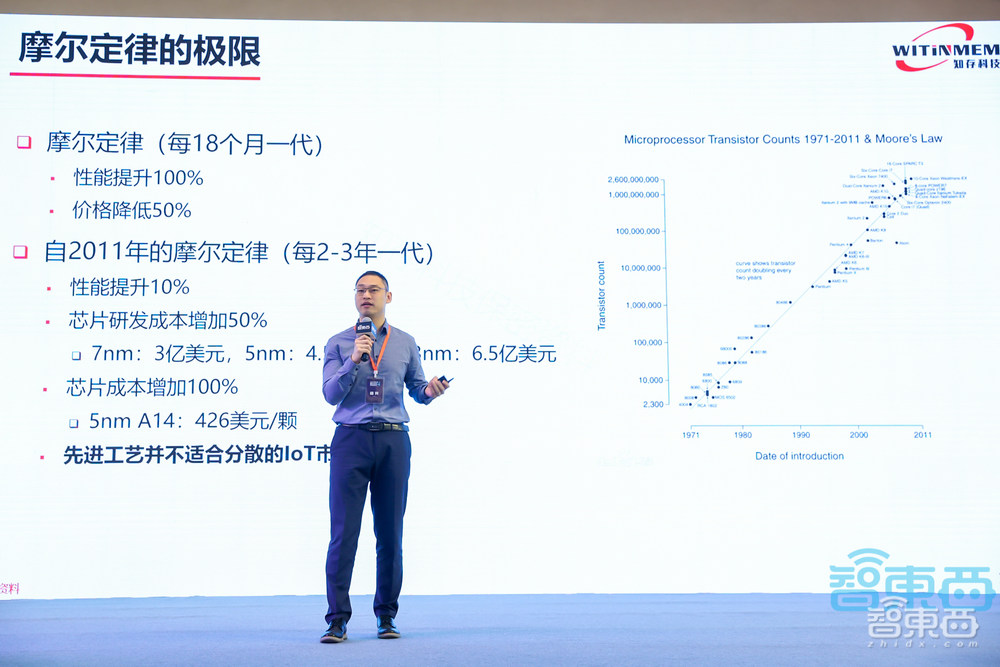
假设我们看现在新的技术节点推进到了7nm,研发一个芯片需要3亿美元,成本远远高于28nm的千万美元的研发成本;到5nm,研发成本又增加了50%,但是性能提升只有10%至20%,不像过去一代芯片比上一代性能提升100%。
未来3nm的研发成本更高,达到6.5亿美元,意味着将有40多亿人民币的研发费用放到一代芯片上。但研发新一代芯片又是否能带来足够的利润来填补整个投入的研发成本?
先进工艺的研发成本越来越高,生产成本也在逐渐提高,5nm的芯片成本比7nm高了一倍。当市场没有足够的利润支撑后,厂商就不会采用先进工艺来生产芯片。
这也意味着,整个市场能够真正应用先进芯片的厂商越来越少。
与此同时,目前最先进工艺最主要的应用场景是智能手机,除此之外,高性能计算也主要采用先进工艺,其它碎片化市场很难采用先进工艺。
二、单一SoC难满足AIoT碎片化市场,需建立正向生态
AIoT有很多的爆发机会,如果关注AIoT消费电子领域,可以发现消费电子近几年有很多新形态产品的出货量增速非常快,例如智能手表、TWS耳机(市场)在近几年都有着指数级别的增速,数据公司统计TWS耳机在2020年出货量有4亿多。
但耳机仅仅是AIoT的一个场景,AIoT有成千上万个场景,是不是每个场景都能爆发出这样的能量呢?目前来看,智能手环和智能手表的增速很快,智能家居有潜力,AR/VR也有很大机会,Facebook、苹果、微软等都押注在这个领域。这些品类在未来会不会成为更大的市场?目前是未知数。但不可否认的是,AIoT有很多的机会。

AIoT有一个特点,它是一个碎片化市场,这就导致了它的碎片化需求特别多,同时需要芯片做到低成本、易开发,低功耗,难度很大。
同时,单一的SoC只能满足有限个应用场景。导致芯片公司在设计芯片时,需要去考虑芯片到底要覆盖什么样的场景,有多大的市场。
不同的AIoT场景需求变化很大,有些场景需要成本极低,有些场景需要功耗极低。但芯片设计无法做到二者兼顾,兼顾过多导致冗余度增高,成本效率都会变差。
AIoT任何一个细分场景都需要一个好的生态,之前两位嘉宾都讲到了从系统和算法层面AIoT生态的建立,包括商汤和大华在生态建立方面也做了非常多贡献。这个生态要有好用的系统、好用的应用、好用的算法,同时芯片也要好用,成本足够低,最重要的是开发快。当这些东西都齐备的时候,这个场景的市场就会爆发起来。
例如,智能耳机市场在过去两三年内处在飞速发展阶段,应用和种类越来越多,芯片也越来越便宜。更重要的是,TWS耳机的开发速度很快,一款简单的TWS耳机从开始研发到做出来,只需要两个月左右的时间。
如果一个新的场景不具备这三个条件中的任何一个,这个市场就很难高速增长。同时,这三个条件又是互相驱动的,首先要有合适的芯片,芯片可以运行合适的系统,系统需要丰富的应用,这样产品开发和创新速度都可以大幅度增速,市场可以快速发展,市场发展起来之后再去驱动系统、应用和芯片的迭代升级。
生态需要很多的厂商去参与建立,生态也会带来收益,很多市场会因为生态建立而爆发。
三、传统芯片架构面临存储墙瓶颈
说回到我们做的事情,当前嵌入式芯片都采用冯诺依曼架构,存算一体是一种不同于冯诺依曼的新架构,过去的7-8年处于快速发展阶段。
新计算架构和传统计算架构有非常大的不同,新计算架构面临着生态问题,没有合适的算法和系统,而传统的冯诺依曼架构从上世纪40年代开始就已被应用,生态已经非常完备。
冯诺依曼架构为了速度越来越快,存储器分级会越来越多,最简单的分级有缓存、内存、存储。在复杂分层中,会有8-9级,越往外的存储介质密度越大,速度越慢,越往内的存储密度越小,速度越快。
存储和内存的工艺尺寸发展落后于逻辑工艺,存储器件很难缩小,即使是最先进的存储和内存,依然采用10nm到20nm的工艺,这意味着存储器的速度很难满足现在的计算需求。
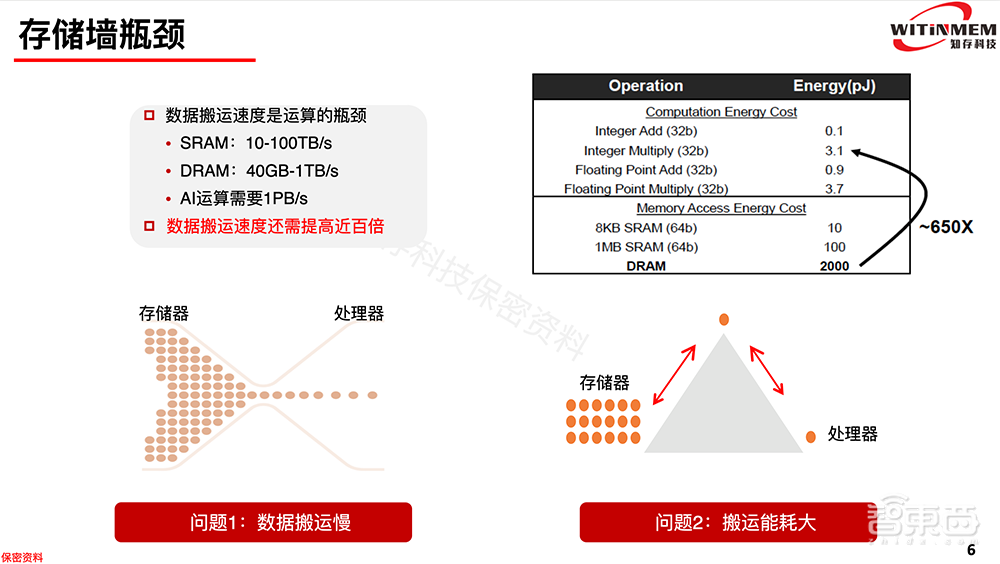
我们在冯诺依曼架构中做运算时,数据需要在多级存储之间搬运。内部缓存的速度快,但是容量小,当数据量很大时,数据会跑到外面的存储器当中,但外面的存储器速度相对较慢。
当前芯片的计算效率很高,不管采用28nm还是5nm。但是存储、内存、缓存的延迟和功耗远高于计算单元,导致存储墙问题。
从功耗对比图可以看出来,常用运算的功耗在0.x和x pJ,缓存和内存读取数据的功耗达到了100pJ和2000pJ。并且读取功耗随着存储器密度增大而增大。
计算中需要的数据量越来越多,数据量的需求每年都呈几何倍数增长,但是存储器的速度很难提高。尤其在现在的高算力和大数据的时代,处理器的核越来越多,但是存储器带宽提升很少,每个核使用的带宽越来越小,突破存储墙瓶颈显得尤为重要。
四、存算一体架构的优势,模拟计算更高效
过去十年很多公司为了解决存储墙瓶颈的问题,采用了以存储/内存为中心的计算架构。将芯片、内存、存储两两组合拉近,减少数据搬运距离,都可以解决一部分问题。
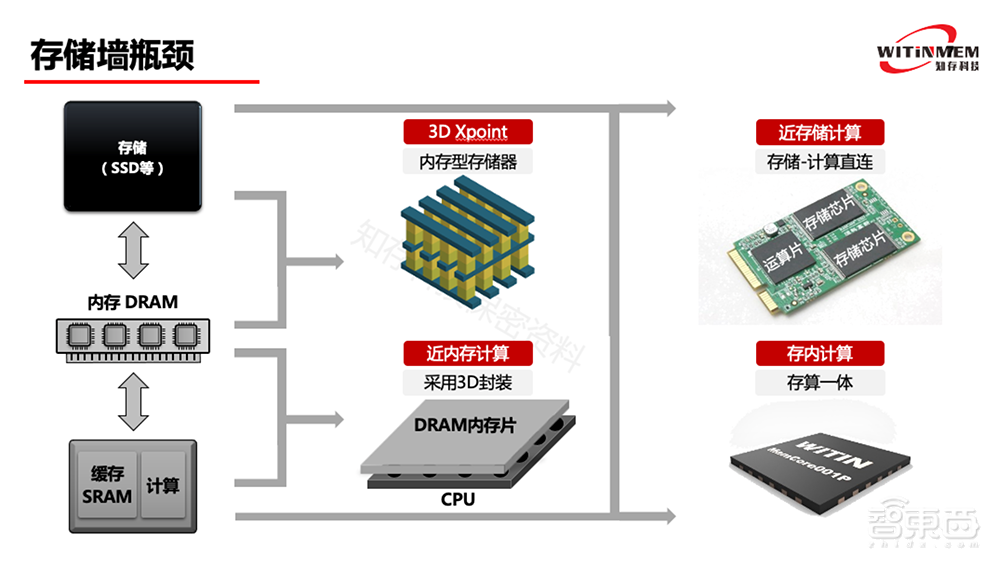
比如美光和英特尔推出3D Xpoint存储器,结合存储和内存,这个存储器速度比内存稍微慢一些但比硬盘快,密度比内存大但比存储小,这是一个存储型的内存(Storage Class Memory)。
另外,像三星、台湾力晶推出DRAM和逻辑芯片的3D Stacking芯片,可以大幅度提高内存和芯片之间的带宽。
近存储计算也是一种方案,在硬盘中增加一个计算芯片,释放CPU的计算压力。
存算一体属于其中最特别的一种方式,相对于其它三种计算方式,存算一体计算方式直接采用存储器单元做运算,而不是把存储器和运算芯片的距离拉近,计算更为高效。
存算一体可采用模拟计算,模拟计算近几年的发展很快,它的一个特点是可以直接用存储器单元完成运算,可采用不同的存储器介质,例如SRAM、Flash、RRAM。
模拟计算把向量乘矩阵的运算映射到存储器当中,直接用存储器完成向量乘矩阵的运算,整个运算过程中没有乘法器、加法器以及其他逻辑计算单元参与。
五、3年量产存算一体芯片,用Flash做运算
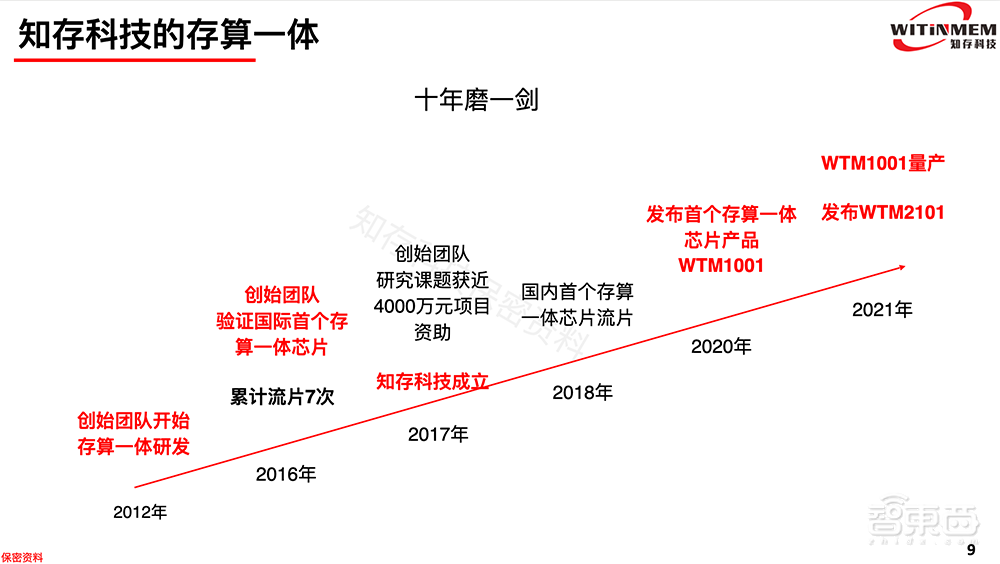
今年是知存科技创始团队研发存算一体技术的第九年。早期从2012至2016年,当时存算一体没有主流的方向,没有主流架构,创始团队采取Flash存算一体进行流片尝试,也是个实验科学。
2016年,我们完成了第七次流片,也是存算一次芯片的首次验证。2017年获得近四千万的项目投资后,公司成立,专注于存算一体技术开发。
真正把实验室的技术做到产品级,中间有非常多坎坷的路要走,从2017年底开始做存算一体产业化,到2020年发布第一个存算一体产品,再到今年把第一个存算一体芯片量产,同时推出第二代产品,经历过十多次芯片的迭代。
过去九年我们尝试过很多存储器,包括新型存储器,最终选择Flash的原因是——它是现在非常成熟、密度高、运算效率也是最高的存储器之一。
固态硬盘、USB盘、ROM、嵌入式存储都使用的是浮栅晶体管。存算一体技术用浮栅晶体管存储数据又用它完成乘加法运算。浮栅晶体管类似MOS晶体管,可以像用MOS晶体管处理模拟信号一样完成信号的线性放大和累加。同时浮栅晶体管可以被编程,从而改变其信号放大能力。
基于这种做法,等同于将Flash存储器的每个存储单元都变成一个乘加法器,这样意味着一个2Mbit的小Flash阵列变成了两百万个乘加法器,达到百万级的并行算力。
六、第二代存算一体芯片将于今年Q4量产
我们的第二代芯片WTM2101是基于最先进的eFlash工艺设计,用于嵌入式场景,包括智能语音、智能健康、轻量级视觉等场景。
WTM2101芯片的功耗在几十微安到十几毫安,算力最大为50Gops,最大支持1.8M的权重参数,现在基于该芯片移植了很多商用算法,将在今年第四季度量产。
这个芯片可用于VAD唤醒、语音识别、通话降噪、声纹识别等,可以应用在很多嵌入式领域中,包括健康监测,以及极低功耗(毫安级)的视觉识别。近一年来,我们发现有很多过去不存在的应用场景,说明AIoT创新在加速,市场在增大。

我们的芯片配有深度学习网络映射工具WITIN Mapper,可以将深度学习算法自动映射到存算一体矩阵当中,然后按顺序执行运算。单次执行最多包含40个矩阵,通过多次执行可以运行更大规模的网络,例如我们已经映射了一个100多层的网络,每层网络的运算只需要一个存算一体指令。
今后几年,我们会和合作伙伴紧密配合,一起推动存算一体的AIoT生态。谢谢大家!
以上是王绍迪演讲内容的完整整理。
