








智东西(公众号:zhidxcom)
编辑 | 云鹏
智东西7月18日消息,近日,由智东西和智东西公开课主办的GTIC 2022全球AIoT智能家居峰会(以下简称AIoT智能家居峰会)正式举办,10位行业重磅大咖就AIoT智能家居的技术突破、创新应用和行业展望展开了精彩的深度探讨。
峰会以“新变量 新未来”为主题,采用线上形式进行,在全网16个渠道同步直播,线上观看人数达到了90多万人。
当前,家居场景是AIoT的重要落地方向之一,随着智能化技术的快速发展,技术边界不断被突破,语音在新型人机交互入口中的作用越来越明显。
在本次峰会上,阿里巴巴达摩院语音AIoT产研负责人田彪博士以《智能家居环境复杂声学挑战下的语音交互技术》为主题进行了演讲,全面介绍了阿里巴巴达摩院在相关重要技术方向的思考和进展。
田彪博士以电视、音箱和室内机器人等家居场景下典型产品的研发实践为例,介绍了声学设计、麦克风阵列处理、远场语音交互、语音模组和芯片等技术的设计思想与方案架构,如何通过技术的进步给用户带来更好更便捷的自然语音交互体验。同时,他结合产业落地情况与研究进展介绍了下一代的产品和技术演进趋势。
以下为田彪演讲实录整理:
我今天演讲的主题是《智能家居环境复杂声学挑战下的语音交互技术》,主要会讲三个部分,第一部分,在智能家居情况下,语音交互核心技术,包括技术产品化的情况,前面会讲一下复杂声学场景的定义还有模式化的概念。
第二部分主要会讲解一下我们在语音AI这个方面,在算法层面核心的技术理念和进展。第三个我会把我们整个产品化的应用案例跟大家做介绍,同时会对我们后面的技术做展望。
不仅是家,包括公共空间,在整个语音交互的过程中都会受到很多声学的挑战性因素的影响,比如洗衣机、扫地机器人。家居过程中噪声,对智能音箱或者电视上的语音交互,会造成噪声影响。
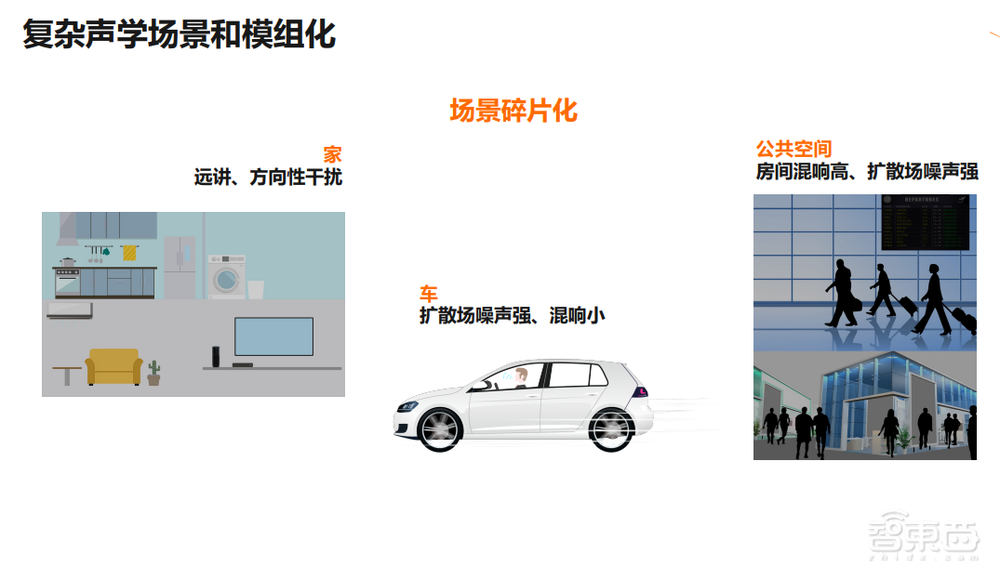
除了噪声之外,有混响的影响,包括干扰,因为家里可能有很多人,所以整个场景下,产品都会受到声学因素的影响。
在车里面、家里面,更多的就是远角方向性干扰会占比会更多一点。车里面整个空间会小一点,它扩散场的噪声会强,但是混响会比较小。
我们在公共空间,混响也很高,整个扩散场的噪声也很强,在不同场景下,声学挑战的每个因素的重要性是不一样的,所以我们的技术方案,在算法层面对于不同因素会有不同的算法处理,整个算法会出现碎片化,应用方案会出现不同的设计。
具体来讲,会涉及到具体应用过程中因素的影响,比如麦克风阵列的选择,数字麦还是模拟麦,算法上复杂度更高还是复杂度更低,跟算法资源、芯片资源都密切相关,这就会涉及到芯片的选型、对于功耗的控制、对于用户数据安全的保障,还涉及到云上的AI能力的对接,怎么去选择不同的云的能力,方案碎片化会比较严重。
算法、芯片、云,不同的环节结合就没那么紧密,会比较零散零散,这样虽然很容易拼起来,但整个方案的语音交互体验就没有那么好。整个产品开发的过程就会有更多的困难,进度也会受一定的影响。
现在整个行业都在做类似的事情,就是怎么把声学的技术硬件做模组化的设计,使得整个语音交互端侧的核心链路能够实现统一的封装,这样会使得整个方案进入平台化的状态。

这样与硬件相关的技术和经验能够以统一的形式来被沉淀下来,客户去集成语音交互能力的时候,能够使用标准的接口跟API去对接,能够大幅降低语音AI能力开发的难度,同时在这个上面也可以进行二次的开发,更好的去满足特定产品的需求。
我们核心的产品形态会是语音交互模组,后面我会再更细节的去讲一下,我们阿里云AI这块整个的技术栈,整个语音交互链路都会去设计,包括端上的信号的处理、回声消除、降噪波束形成、声源定位,包含端侧的唤醒命令值、快捷指令,包括硬件层面声学硬件的设计跟服务。
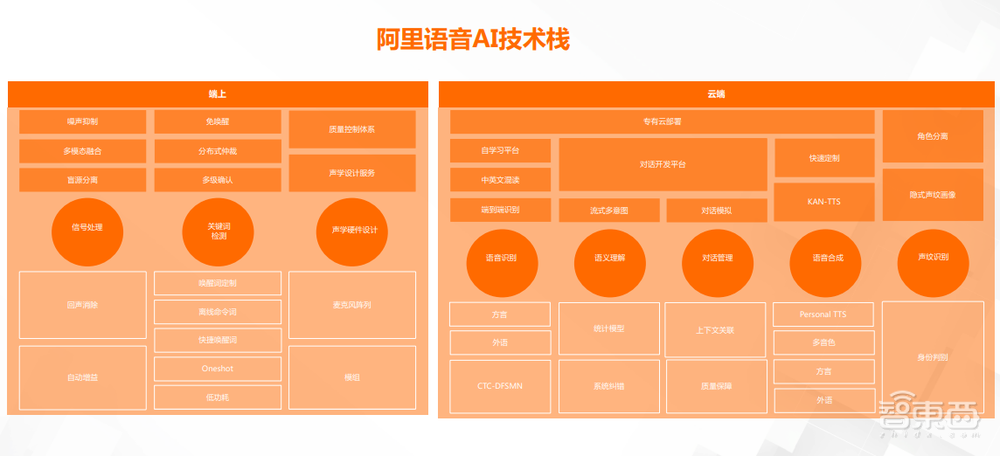
云端上有很多我们传统的语义理解、对话管理、语音合成、声纹识别,在这个过程中我们会聚焦在核心的技术方向上,持续的去投入跟建设,尽量去推动技术边界的扩展、技术深度的提升。
今天我会更多的去讲我们在端上信号处理相关的算法的理念跟方案,设计就会使得我们整体上对于复杂声学因素的影响,能够尽量去降低整个算法的影响效果,整个用户体验也会变好。我们在声学前端有三个核心理念,也有对应的技术方案。
首先我们要去解决前端处理,包括回声消除、噪声降噪、自动增益控制,传统的三A技术都是基于自适应滤波信号处理的方法去做的,在现在这个时代,我们更多的会去结合信号处理的滤波,以及我们基于深度学习模型去做统一的方案,这个是我们大的理念,把回声消除的线性部分,后处理部分跟降噪的部分,还包括自动增益控制的部分,使用 hybrid的架构,去把它融合,发挥模型的非线性建模的能力,以及自适应滤波对环境对资源开销小的优势。
整体而言,这个方案在我们的很多的模组对外输出方案上都得到了实现,也能看到对于传统的信号处理算法技术有非常显著的提升。相关的技术方案,我们之前也参加国际比赛,拿到不错的成绩。看方案属于国际上现在比较前沿的技术架构。
第二部分,我们会基于盲源分离的方案去把混响回声消除、声源分离,都通过盲源分离理论去统一起来。
同时我们在这一块不仅会把前端的不同任务通过统一的框架去处理,也会跟语音唤醒去做进一步的联合,使得唤醒的信息能够反馈到前端来,能够指导前端,让盲源分离能够处理得更好。
这样的技术方案对于信道相关没有做太多的假设,不需要有更多的经验的要求,这样就使得我们整个方案非常适用于小的阵列,也更容易被各种各样的设备去集成,同时在各种场景下有非常好的适配性。
整体上从技术核心层面,使得我们整个算法方案有很强的适配性,能够帮助我们去解决前面说的常见的技术方案碎片化问题。
第三就是说进一步的统一融合,会把视觉跟听觉的能力进一步的融合。我们知道视觉对噪声是非常鲁棒的,它不会受噪声的影响。但是语音算法无论你怎么去做,它对于强噪声特别复杂的场景,还是有力所能不及的地方,这个时候如果能够使用到视觉信息,非常有助于我们把整个语音效果做得更好。
如果我们有人脸的信息,我们可以把语音段里的人声跟非人声段做很好的区分,传统的技术很难去做,性价比非常低,它很难去把语音跟非语音说明的很精准,但是视觉的话,能够监控你的面部特征、唇动的特征,能够区分语音和非语音。
做麦克风阵列的同学可能都知道,如果你能够很好的区分噪声跟语音的话,整个信号的噪声统计量跟信号的统计量就能估计的更准确。
所以这一块我们融合了视觉的信息,这三块的技术,我们在最近两年都已经发表了最新的成果,感兴趣的同学和同仁可以去搜索一下我们阿里语音的论文,就可以看到更多的细节。
在识别还有合成层面,我们最近也在逐步推进,以前大模型大部分还是在云端去做服务的。端上一般我们以唤醒快捷指令离线的方案去做,但是对于大词汇量的语音识别系统在端上来跑,尤其在嵌入系统上去跑,还是有非常大的挑战的。
我们W语言实验室基于我们自己研发的神经网架构得到端的语音识别框架,它可以做到非常小的尺寸,而且精度能够做得非常高,能够纯文本地的实现的语音识别系统,在我们的淘宝直播的应用场景,在大概10兆以内的内存开销下,就能够去做到非常大词汇量的语音识别系统,而且跟我们云端的效果非常接近。
我们在TTS方面,无论是模型的构造还是计算量层面,也做了非常多的技术突破,使得整个TTS能够跟云端相媲美,整个技术核心的语音交互的技术也都往端上迁移。
总体而言就是说我们会把前端跟唤醒联合建模,还有识别合成,我们面向复杂声学挑战下的语音交互技术,逐步在端上去实现全站的语音交互能力。
这是我们整体的模组方案的架构图。我们会从OS层到 AI能力层,最后再到产品的形态以及服务。
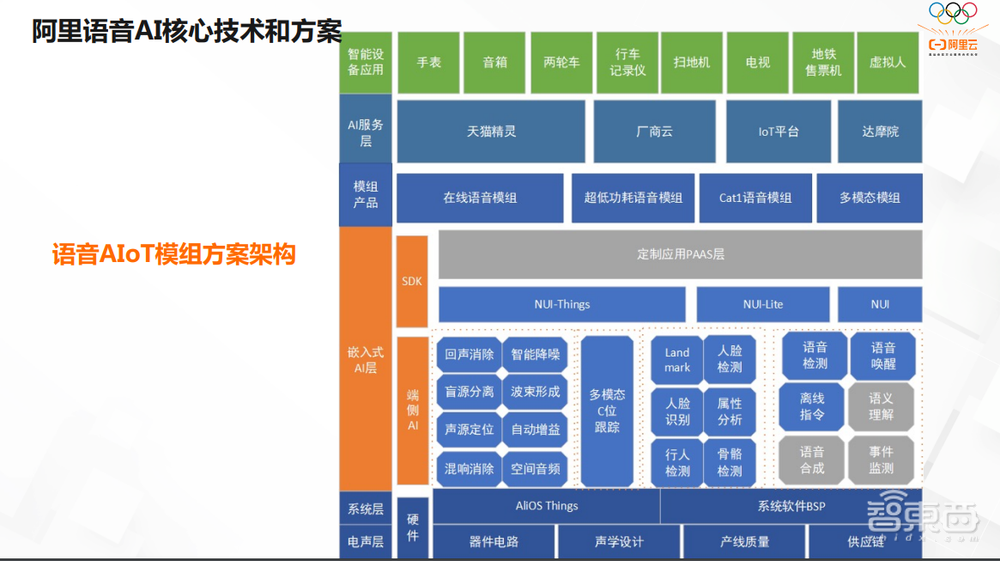
我们的核心的边界还是以模组的形式去服务更多的客户,包括我们内部的天猫的客户,也包括我们外部很多的客户。
我们现在核心的有几个型号的产品,高性价比的模组、算力更强的高性能语音模组、多模态的模组,会把我们之前前面讲的统一的技术方案,整个语音交互技术,都会在模组形态上进行集成,这样它能以一种模组的形态被集成到客户的各个产品里面去。
然后是RTOS的系统,主要是面向音箱家电的产品,像厂商就会集成我们模组去构造它语音交互的能力,高性能的语音模组就会去处理非常有挑战的场景,整个算法复杂度还会提升。
比如说移动机器人、扫地机,算法复杂度比较高,使用的麦克风也比较多,这样我们有挑战的家居场景下的设备,能够去集成我们这样高性能的语音模组。
多模态模组会面向公众空间,刚才讲的像地铁车站它噪声非常强,有些受人流的噪声影响也很大。我们就会把本地的视觉的能力跟前面模态融合的前端算法融合起来。它核心特点就是性能比较高。
我们通过统一的建模方法,把混响完全分离,回声消除都通过分离方案进行构造的话,它就能够用比较低复杂度的设计,使得算法能够在小的资源的芯片上能够得到高性能。
另外它基于多核异构的芯片,使用的是RTOS的系统,所以成本来讲也是比较有竞争力的。
另外我们也使极极功耗的唤醒,能够使得整个系统处于非常低功耗的状态,整个电流功耗水平能够做的比较低,使得整个设备尤其电池类的设备,就能够具有更好的待机时长。
在整个智能设备的打造过程中,会涉及到非常多的硬件声学方面的工作。对于最终呈现出来的语音交互效果都有着非常重要的影响。
比如说麦克风如果质量不够好的话,算法收到的信号质量就很低,整个算法效果处理之后也不会很好,最后语音效果也不好。比如说喇叭,最后对打断唤醒都是有非常很大的影响的,所以在这个里面我们允许团队提供声学硬件研发设计跟量产的服务,包括原理图的设计、电声性能的测量测试,包括端到端的产线,还有性能调优。
我们也有消声室、测听室环境,使得我们在硬件层面也能够为算法提供非常好的基础。
我们的高性价比语音模组芯片,比如像小雅的音箱、早教机,包括两轮车车载精灵设备,都集成了我们两麦的模组跟算法,我们高性能的有更高复杂度的算法会应用在扫地机、机械狗,在移动高噪的场景下,我们会使用这样模组,解决高噪大回声移动远场的挑战。

我们的多模模组用的比较多的是地铁线,我们17年就开始来做公众空间的语音交互,以前像云端AI,一开始使用更多的使用是“close talking”的场景,在真正的公共空间能把语音交互很好的使用起来,我们做了比较早的技术突破跟产品化,也在全国各地的很多的地铁线上都进行了落地。协同办公的场景、电商的场景都能用到我们模组方案。
后面我主要会讲一下我们最新的布局,达摩院的使命是要持续的去探索技术边界,通过算法技术的进步,去解锁语音在各种挑战性新场景下的应用。
达摩院的技术创新全景图,叫做懂你的语音AI,我们在公众号上做了非常长的文章介绍,汇报我们整个中央端语音交互技术,向所有的同仁做汇报,大家感兴趣的可以去搜索相关关键词找到全文。

总体而言,我们会在前端通过联合优化的声学前端使得整个语音交互首先能够听清,涉及到非常多的信号处理联合建模,语音增强唤醒的一体化建模相关技术的布局。
第二个就是说解决语音到文字的模态转换,这样我们会在统一语音识别的基础框架以及嘈杂环境下来进行说话人的识别,在这方面工作也有很多进展。在GPS层面,我们会把它的高自然度、高表现力技术持续去突破。
在能听到人的语音之后,我们拿到文本,会通过语音声学NLP的联合建模、标准学习的技术,使得我们整体对口语的语言理解达到更高的层次,真正实现语音交互能够更懂你。
以上是田彪演讲内容的完整整理。
