








芯东西(公众号:aichip001)
编辑 | GACS
9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在15日的高能效AI芯片专场上,云天励飞公司的副总裁、芯片业务线总经理李爱军,分享了主题为《大模型时代下国产边缘计算芯片的挑战和突围》的主题演讲。
李爱军在演讲中说,大模型的出现让边缘计算看到了Corner case的破解之道。全球边缘计算市场规模不断扩大,但面临着场景、芯片平台、算力需求碎片化的痛点,算法投入产出不成正比。大模型具有强大的图像或语言理解能力、场景泛化能力,有望解决这些痛点。
为满足大模型部署需求,边缘计算芯片设计需要考虑SoC集成、算力可灵活扩展芯片架构、统一的工具链架构、隐私保护等方面因素。李爱军谈道,云天励飞基于其自研算法开发平台和算法芯片化平台,不仅训练了“云天天书”大模型,还推出了新一代边缘计算芯片平台。
以下为李爱军的演讲实录:
大家好!我是云天励飞的李爱军,今天我给大家带来大模型边缘计算芯片的挑战和突围的主题分享,我的分享里面有三个关键词:一个是边缘计算,第二个是大模型,第三个是国产芯片。
为什么是这三个关键词?我们大家都知道,AI在落地的过程中,特别是芯片,主要涉及到端、边、云三个大的场景。对于芯片来说,云和端这两个场景相对而言比较明确。比如说云,主要是拿来做训练,强调它的通用性;对于端,它强调场景非常聚焦,比方说手机,强调了它极致的能效比;中间的边,就代表边缘计算。
而边缘计算场景对于整个AI来说,实际上是一个全新的场景,过去这十年,大家都在这个场景里面探索。边缘计算这个场景本身给大家带来的想象空间也是非常巨大和无限,因为大家对于边缘计算的共识是场景非常的丰富。
大模型自从去年11月份ChatGPT出来以后,已经经历了大半年的过程,大家也都能看到,整个AI的方向基本上已经非常明确,或者说大模型代表AI的第二阶段。大模型在云端带动了整个GPU,在端侧,包括手机也在迅速跟进,高通的手机芯片,以及类似苹果、华为这些业内的顶尖厂家,都在陆续推出基于端侧的大模型。对边缘计算来说,大模型跟边缘计算有没有结合点、交叉点?这是我们在思考和探索的。
另外一个是国产芯片,在现在这样的大国际形势下,国产芯片,特别是国产工艺芯片,我想这已经是一个绕不开的主题了。我相信在边缘计算这个场景下,在不久的将来,一定会有一家企业基于国产的工艺推出满足边缘计算场景的突破。
我将从下面三个方面进行主题分享。
一、三个技术平台,实现“算法芯片化”
云天励飞是一家什么样的企业?云天励飞是一个应用驱动的技术型企业,公司是2014年的8月份成立的,云天励飞是一家为数不多的,具有算法、芯片、大数据全栈能力的AI企业。
在过去九年时间里,我们探索出了一条AI落地的一套方法和设计平台,就是算法芯片化这样的设计平台。通过这个平台,我们有效地把AI的算法、边缘场景的落地,以及AI处理器的指令集和芯片架构、工具链,能够有机整合在一起。通过应用产生数据、数据训练算法、算法定义芯片、芯片赋能应用,这样的一个数据飞轮,我们不断地推动AI在边缘场景的落地。
云天励飞的算法芯片化平台,它由下面三个可落地的技术平台组成:
第一个是应用落地驱动的算法平台。在这个平台上,我们实现了算法超过14个领域,以及102个种类的落地。同时,这些算法可以支持端云协同,支持细分场景下的算法快速微调和部署。同时基于这样的平台,我们也正在研发云天励飞的“云天天书”大模型。
二是算法驱动的神经网络处理器平台,通过这个平台上,我们能够实现算法高效推理的指令集设计。同时,基于这样的平台,我们也完成了四代神经网络处理器的迭代。并且得益于这些迭代,我们能够高效地支持卷积神经网络(CNN)以及新一代的Transformer计算范式。并且能够高效地支持目前大家所熟悉的,包括视觉大模型、多模态大模型、NLP大模型在边缘端的高效部署。
三是面向边缘计算场景的芯片平台,通过这样的平台,我们实现了三代可商用的边缘计算芯片的落地,并且算力范围从2TOPS到128TOPS的这样的覆盖。我们通过这个平台,实现了D2D Chiplet这样的先进封装技术,这个可能是基于国产工艺,第一个进入可量产的Chiplet技术。同时,基于这样的平台,我们还实现了C2C Mesh这种高效互联技术,通过这样的互联技术,我们可以实现算力的灵活可扩展。
二、大模型时代下,边缘计算芯片面临三大技术挑战
在大模型时代下,边缘计算芯片具有哪些挑战。我们知道,整个边缘计算场景,它的规模是呈不断扩大的趋势。那什么是边缘计算?边缘计算,它卡在端和云的中间。边缘计算又分成Edge Device和Edge Server两个细分场景,包括有边缘的智能终端设备、边缘的智能网关,以及边缘服务器这些场景。
据IDC的预测,到2023年底,全球的边缘计算市场将达到2000亿美金的规模,年增长率也非常高,达到13%以上。预计到2026年,边缘计算市场将突破3000亿美金。可以说,这是一个非常值得大家期待的AI落地的场景。

1、边缘计算场景落地的现状,Corner Case难以有效解决是落地痛点
但是在落地的过程中,特别是云天励飞过去九年,我们在落地过程中,我们所看到的现状是怎样的?
首先边缘计算的场景非常众多、纷繁复杂,有园区、安防、商业、教育等等。这么多的场景,场景的要求又各种各样。
同时,在边缘计算场景落地的芯片平台种类也是五花八门,有X86架构的、ARM架构的,有FPGA的,也有SoC主控芯片,也有算力芯片,甚至传统的NVR芯片也被归在这个类。
算力的需求也是极度碎片化的,从0.5T算力,到几十T甚至到几百T,需求各异。同时对数据精度的要求也不一样,有INT8的要求,INT12的要求,还有FP16的要求。
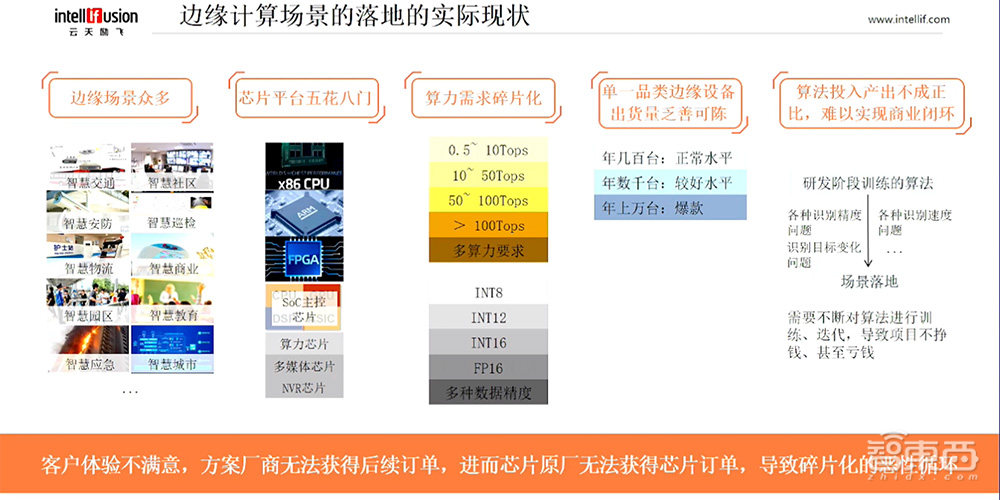
从算法角度来说,算法投入产出不成正比,难以实现商业闭环。算法从研发训练出来,在场景落地的过程中,会遇到各种各样的精度、识别度的问题,以及目标变化的问题。目标变化并不是目标本身有变化,而是这个目标的姿态有变化,比如说一个猫,正面看像是猫,可是背面看就不认识了。这需要算法不断进行迭代和训练,这就导致整个落地的过程中成本不收敛,也就是我们做一个项目,不挣钱甚至亏钱。
因为整个落地过程中客户对于整个体验是不满意的,客户不满意就不会给方案商继续下订单,方案商没有订单,意味着芯片原厂也没有订单,这就形成了碎片化的恶性循环,这就是当前边缘计算场景落地的困境。
边缘计算场景的痛点究其问题,最大的痛点在哪里?在于场景的Corner Case难以有效解决。我们以长尾算法为例,长尾算法的开发部署要经历,第一个是单场景数据的搜集,还有算法的训练,产品的测试,再到应用部署4个环节。这里面有两个循环,一个是产品研发阶段的小循环,还有一个产品研发完以后去部署应用的时候,还有叫Corner Case的持续的循环。因为这两个循环的存在,导致整个落地成本居高不下。
2、Corner Case破解之道:大模型的运用
大模型的出现,让我们看到了解决场景边缘,特别是解决边缘计算场景的Corner Case的希望。大模型现在有两种,一个是CV(计算机视觉)大模型,一个是NLP(自然语言处理)大模型。
CV大模型具有什么样的特点和优势?首先,CV大模型具有强大的图像理解能力,同时它也具有强大的场景泛化能力,这意味着它可以实现在摄像头视野范围内所有目标的分割、检测和深度估计,为泛场景的精确识别提供技术保障。这里面我们可以看到目前的开源网络,包括Dino-v2、Segment-Anything、Ground-Dino等等这些算法。
而NLP大模型,它有强大的语言理解能力,以及强大的多轮交互能力,这意味着算法能够快速、准确地理解用户指令,从而可以实现场景Corner case的精准操作。
CV大模型与NLP大模型的结合,在边缘计算场景的落地,让我们能够看到Corner Case有被解决的希望。

3、边缘计算芯片运行大模型的双重挑战
大模型在边缘计算场景运用,对于边缘计算芯片有什么样的要求和挑战呢?
对于AI处理器而言,因为大模型带来全新的计算泛式和计算要求,它需要AI处理器能够高效地执行Transformer这样的计算范式,同时要能够高效执行包括Softmax、Layer norm等新算子,它的算力要求要大,大模型的算力,特别CV大模型的算力是传统小模型的几倍甚至十几倍。因为大模型的参数量巨大,它对于内存的带宽要求以及内存容量要求,相比原来的小模型也是翻番,甚至翻几番。
另外大模型同样带来了对边缘计算芯片的全新设计要求。大模型在边缘计算场景落地,需要形成边缘的计算芯片上全业务的闭环。这就意味着对边缘计算芯片,不光对于算力有要求,还需要芯片是一个具有SoC集成度的芯片要求。也就是它不光要有AI算力,还要有相对比较强的通用算力,包括CPU、GPU等等。
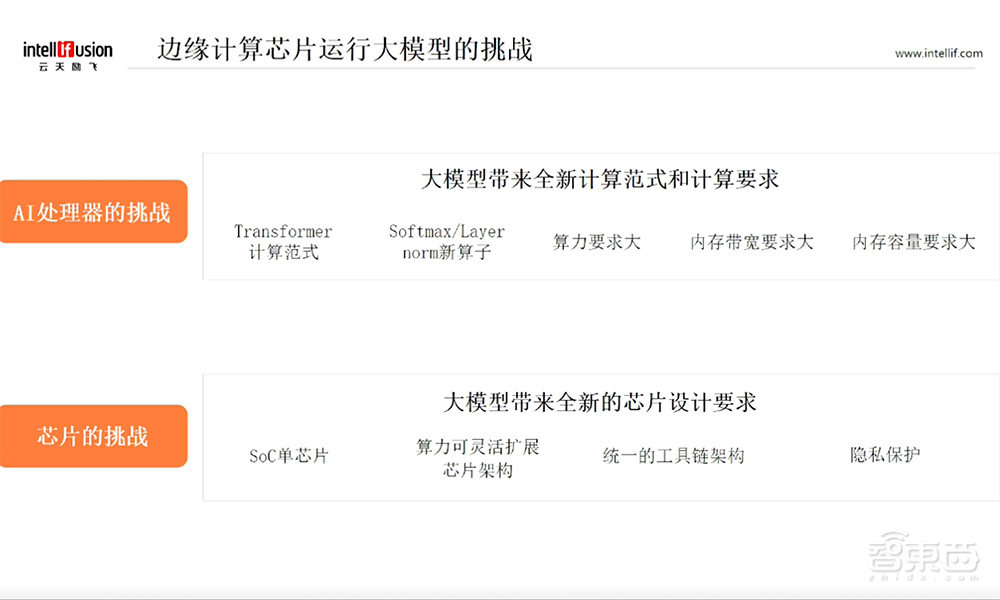
因为大模型在落地场景中参数规模有变化,有可能10亿规模,也有可能百亿规模,也有可能是几百亿规模,它希望芯片的架构是一个算力可灵活扩展的架构,在应用的时候可以量体裁衣,根据场景的要求选择不同的算力。不同算力的芯片对于算法来说,希望有一个统一的工具链架构,而不是说这个算力场景我要用这家芯片,那个算力用那家芯片,而工具链又是各家做各家的。如果这种情况下,整个大模型在边缘场景下的落地仍然会举步维艰。
同时大模型因为比传统的小模型带来一些优势,包括泛化的优势、理解的优势等,对于用户的数据,它的处理量级比小模型会大一个数量级甚至两个数量级,也就是有更多海量的用户数据会被在边缘侧处理,同时这些数据的理解也会更加深刻,这就带来用户数据的隐私保护的问题。
三、加速大模型落地边缘场景,解构云天励飞的架构创新
在边缘计算芯片这些技术困境下,云天励飞做了哪些事情?
首先是云天励飞正在自研“云天天书”大模型,这个大模型是基于云天的算法开放平台和算法芯片化平台,通过结合互联网上海量的语料数据,训练出通用的基础大模型。在通用基础大模型的基础上,结合云天励飞过去九年来的沉淀积累,训练出行业大模型,这里面就包括智慧城市、智慧安防、智慧交通、智慧商超等等,这些领域的行业大模型。之后再针对落地细分的场景,将数据集进行微调,从而实现真正可落地的,满足场景泛化要求的场景大模型。云天天书大模型也是由CV大模型、NLP大模型和多模态大模型组成。
在芯片侧,云天励飞打造了新一代的边缘计算芯片平台DeepEdge10。它是一个系列化的芯片平台。它是基于国产的工艺,可以说这颗芯片是真正的国产芯片。其次它采用了先进的Chiplet技术,它能实现算力的灵活扩展。DeepEdge10是具有SoC主控集成度的芯片,内置了云天最新的第四代神经网络处理器,可以高效支持大模型边缘侧的执行和落地。另外它实现了D2D Chiplet创新技术,同时实现了D2D/C2C Mash扩展架构,来实现算力的灵活可扩展。
在主控集SoC方面,DeepEdge10具有性能强劲的、主流的CPU核。另外它集成了满足边缘场景应用的2D/3D的GPU能力,同时集成了第四代神经网络处理器400T,所以它具有澎湃的边缘AI的算力。它还有强大的多媒体能力,包括对于8K30视频以及2亿像素的图像处理能力,还有不错的显示能力,支持双屏异显等等。它有完备的高低速外围接口,例如我们熟悉的USB、PCI等,包括以太网口都全部支持,甚至还支持CAN FD,可以满足工业场景的实时连接需要。同时,它具有硬件级安全特性,支持国际主流的加解密算法,同时支持安全boot,以及物理级的安全系统。
DeepEdge10内置了云天励飞第四代神经网络处理器,具有这些特点:首先它的数据格式,它是支持FP16、INT16和INT8这些精度,因为有了这些支持,我们得以做混合精度量化。另外支持多线程执行,同时支持QAT模型、支持动态量化模型、支持最新的Transformer网络结构模型。
对于大模型的新的计算,我们有哪些考虑呢?首先是我们设计了三维并行的矩阵计算架构。结合矩阵计算和矢量计算的联合优化,我们可以高效地提升像Softmax、LayerNorm这些算子的性能。通过稀疏化、参数/数据的压缩和低比特量化技术,我们可以实现大模型对带宽要求的极致优化。通过INT8、INT16、FP16,可以实现混合数据精度的量化,从而保证大模型在边缘侧落地的时候几乎不掉精度。通过D2D以及C2C的高速互联接口,可以实现算力的灵活扩展。
DeepEdge10芯片是国内首个基于国产工艺量产的D2D Chiplet芯片。D2D就是die to die,意味着两个die之间高速互联。我们采用的die to die技术具有非常高的速率,还有带宽的密度、pJ级功耗级别,以及纳米级延时等等,包括传输、路由、统一内存等等。因为有了这些特性,所以我们才能够负责任地说,我们可以支持当前的大模型,包括百亿大模型乃至千亿大模型参数大、计算量大、低延时的要求。
通过以上的创新,云天励飞打造了DeepEdge10这样基于国产工艺的芯片平台,我们形成了一个系列化的芯片。这样的芯片平台我们可以有效地支持当前在边缘计算场景落地的,从迷你PCIe卡、AI盒子、加速卡,到边缘服务器等各类硬件产品的需要,从而实现整个丰富边缘计算场景的落地。
我们通过架构的创新,可以说DeepEdge10实现了国产芯片在边缘计算场景的突围。云天励飞致力于国产工艺以及国产大模型边缘计算芯片的突围,不论遭受怎样的外部压力,我们矢志不渝。谢谢大家!
以上是李爱军演讲内容的完整整理。


