








芯东西(公众号:aichip001)
编辑 | GACS
9月14日-15日,2023全球AI芯片峰会(GACS 2023)在深圳市南山区圆满举行。在首日主题演讲开幕式上,高通AI产品技术中国区负责人万卫星分享了主题为《终端侧AI是AI的未来》的主题演讲。
万卫星着重分享了高通对生成式AI未来发展趋势的观察:随着云端处理生成式AI的成本不断提升,未来云经济将难以支撑生成式AI的规模化发展。此外,基础模型正在向多模态扩展,模型能力越来越强大,而垂直领域模型的参数量也正在变得越来越小。未来,丰富的生成式AI模型将在终端侧运行,让大众享受到生成式AI带给生活、工作、娱乐上的变革。
以下为万卫星的演讲实录:
尊敬的各位嘉宾,各位同行,大家上午好!很荣幸作为高通中国的代表参加这次峰会并进行演讲,我非常期待能跟各位一起共同推动AI产业在中国的繁荣发展。今天我给大家带来的演讲主题是终端AI是AI的未来。
一、终端侧AI加速落地,高通已深耕端侧AI多年
随着去年Stable Diffusion、Midjourney和GPT的火爆,生成式AI的概念在以指数速度在我们普通大众中普及。前面有嘉宾也分享了,ChatGPT是有史以来最快的,只花了两个月的时间就拥有了1亿使用者的应用。
回到这张胶片,虽然我在这里列举的多数是图片相关的生成式AI应用,但是我们也知道生成式AI应用不仅仅是局限于图像,还包括文字生成文字、图片生成图片,甚至包括文字生成代码、音乐,图片生成视频,等等。
我们看到现在的基础大模型都在朝多模态模型转变,我们认为这将深刻影响到我们的生活、工作和娱乐方式。为了让普通大众能够更方便地享受到生成式AI,生成式AI需要在终端侧运行,这也是高通公司努力推动的一个方向。
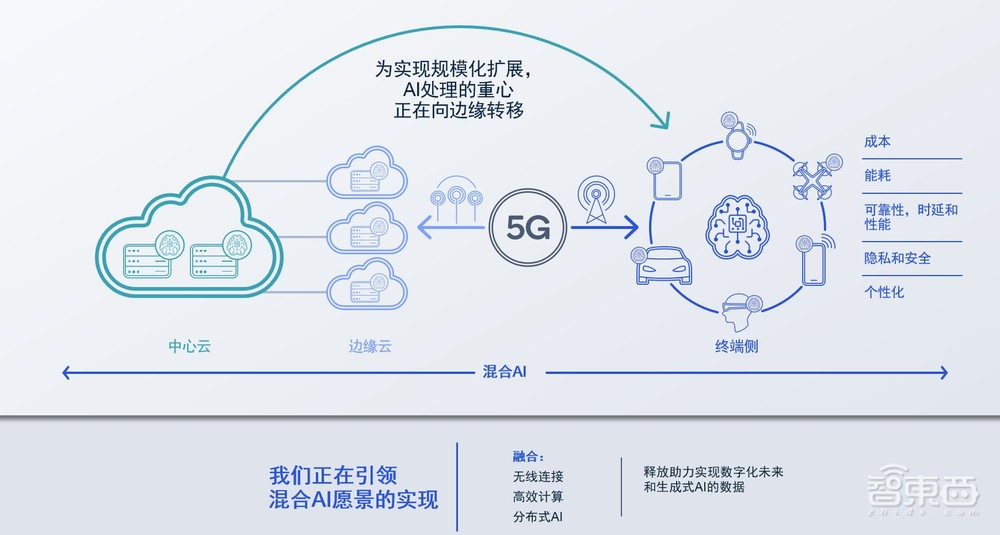
我们认为数据在哪里,AI的推理就应该在哪里。这个正确的地方,就是在终端侧。跟云端相比,端侧的优势包括成本、能耗、可靠性、时延和性能,还有非常重要的隐私和安全,因为所有数据都保留在终端,不会上传到任何云端。
除此之外,我们还可以根据端侧的信息为不同的用户提供定制化、个性化的服务,所有的这些服务都不依赖于任何网络连接。对于一些有着上千亿参数,只能在云端运行的大模型,高通的5G技术也能够帮助我们充分利用云端的算力,提高我们在端侧的AI体验。
在今年2月份的世界移动通信大会上,我们基于第二代骁龙8的终端演示了全球首个在安卓手机上运行Stable Diffusion的终端侧演示,通过高通全栈式AI对Stable Diffusion这样一个超过10亿参数的文生图大模型的优化,我们可以15秒内完成20步推理,输出一张512*512的图片。

今年6月份,同样也是基于第二代骁龙8,我们完成了全球最快的手机上运行ControlNet终端侧演示,ControlNet是一个参数量比Stable Diffusion更大的图生图大语言模型,用户可以输入一些文本,同时选择输入你日常拍摄的一张普通照片。比如说现在展示的拍了一张花瓶的照片,通过ControlNet得到一张具有文艺复兴时期作品风格的输出照片。当然,你也可以用它做其他的事情,比如对旅游照片做背景切换或者构图等等。
二、生成式AI发展三大趋势,终端侧AI势不可挡
下面我想谈一谈我们观察到的,生成式AI当前的发展趋势。
第一个趋势,生成式AI的成本。我们这里举了一个例子,单就网络搜索为例,使用生成式AI的新技术跟传统的办法相比,每次搜索的成本提升10倍。考虑到还有各种各样的生成式AI应用正在涌现,以及全球数十亿的用户,显而易见,云经济将难以支撑生成式AI的规模化发展。
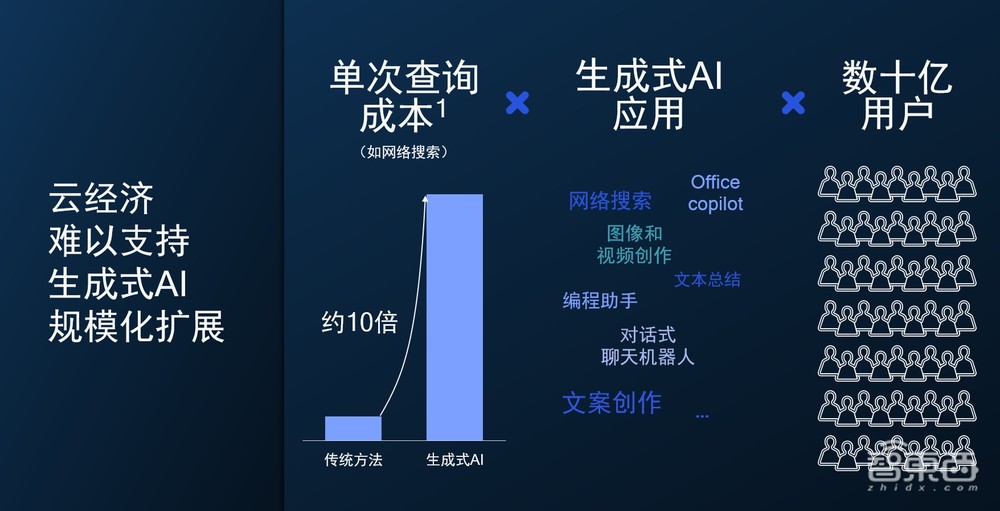
第二个趋势,我前面也提到,现在数据的模态非常多,有文本、图像,音乐、语音等等,基础模型正在向多模态扩展,也就是说用户可以随意输入任意模态的数据,可以得到与之对应的任意模态的输出数据,也就是所谓的“X to X”。
第三个趋势,我们能看到现在的基础模型变得越来越强大,但同时垂直领域模型的参数量变得越来越小,比如说GPT-3总的参数量在1750亿,但是Meta发布的Llama,包括国内的百川等模型,他们的参数量要小很多,可能只有70亿或者130亿。
跟大参数量基础模型相比,这些相对较小参数量的大模型在某些垂直领域,性能依然十分强大,这也是为什么我们认为在未来,我们非常有机会将这些模型在终端侧部署,让更广泛大众能够享受到生成式AI给我们的生活、工作、娱乐带来的各种变革。
如果我们仔细看一下不同的这些生成式AI的用例,包括文字生成图像或对话、NLP(自然语言处理)、编程、推理甚至包括图像、视频理解等等,所有支撑这些AI用例的大模型,它的参数量在10亿-150亿之间,这也是为什么我们认为在终端侧完全有可能让这些模型跑起来。

当前我们可以支持10亿包括15亿参数的大模型在骁龙平台支持的终端侧运行。未来几个月我们也非常有希望能看到,超过100亿参数的大模型能够完整地在骁龙平台上跑起来。我们在终端侧通过不断提升大模型支持的参数阈值,让更多云端的生成式AI用例向边缘侧迁移。
像手机这样的终端,它有着相机、麦克风、传感器、蓝牙、Wi-Fi、调制解调器等等能够提供感知信息的模块,而这些感知信息可以作为生成式AI输入提示,让终端可以提供更个性化的服务,而不需要通过任何网络连接。

但同时人们可能担心,所有的个性化隐私数据当作生成式AI的输入,会不会有隐私安全泄露的问题?针对这方面的担心,我们认为一个比较好的解决方案,是让整个模型完全闭环跑在终端侧,让所有感知信息、隐私数据全部保留在终端侧,没有任何数据可以上云。
三、高通AI引擎成硬件杀手锏,多项黑科技实现能效翻倍
高通之所以能够支撑这些超过10亿参数,甚至未来超过100亿参数量的大模型在终端部署,所依赖的是高通强大的高通AI引擎和统一的技术路线图。
下面,我会从硬件和软件两个角度分别跟大家展开介绍。
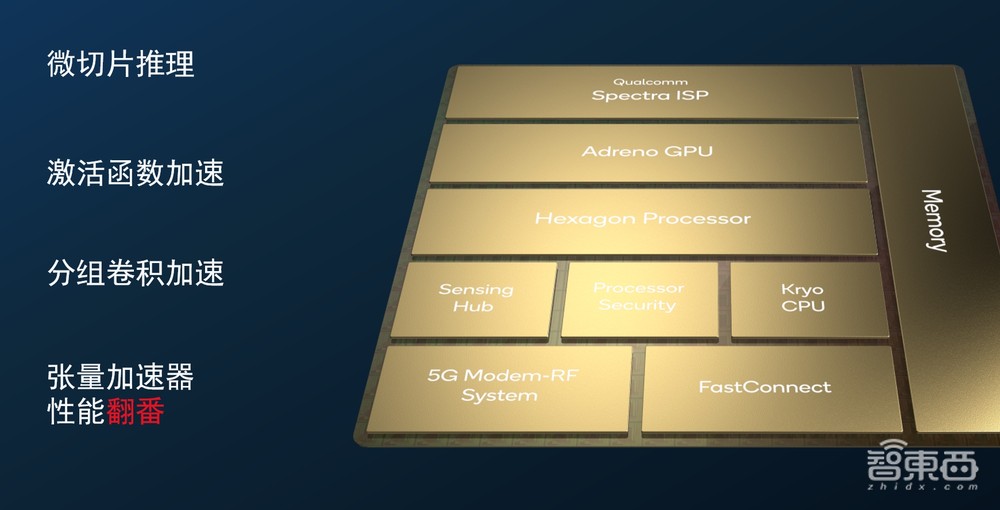
第一就是我们的硬件高通AI引擎。可以看到,高通AI引擎既有通用的CPU、GPU硬件加速单元,还有一颗专门为大算力AI工作负载而设计的高性能AI硬件加速单元Hexagon处理器。
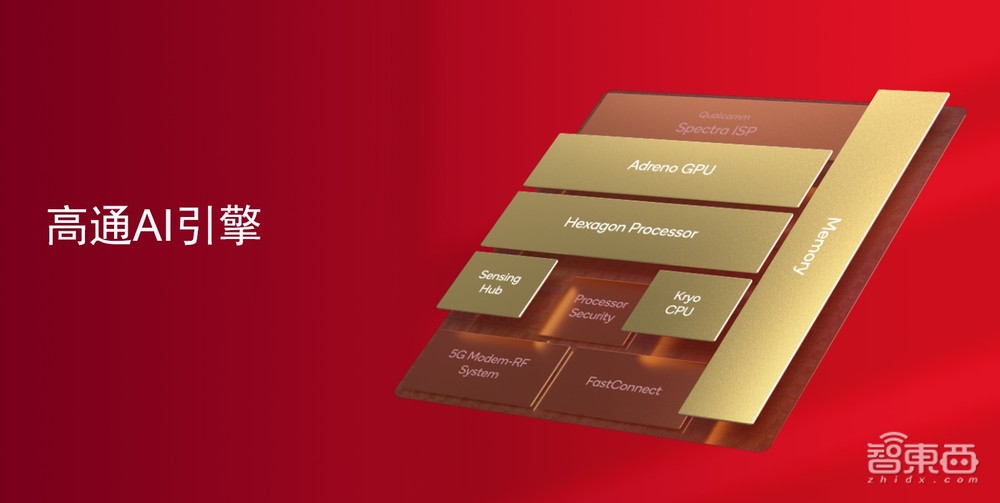
在此之上我们还有另外一块单独的超低功耗处理器,高通传感器中枢,适用于一些始终开启功能,比如相机、屏幕和语音唤醒等等。这些模块共同构成了一整套异构计算系统,同时结合我们的异构软件系统,能够充分释放高通AI引擎的AI加速能力。
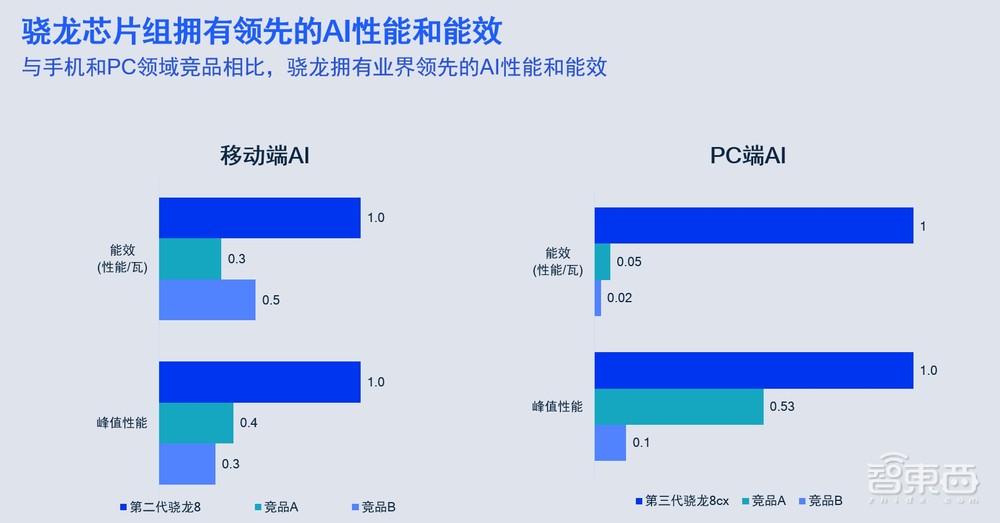
高通的AI硬件优势在哪里?我觉得第一是性能,我们不仅能提供领先的峰值性能,也能提供非常好的能效。我们在既定功耗下的性能领先于手机和PC领域的竞争对手。
第二点,前面有嘉宾提到,目前大语言模型70%都是基于Transformer,高通在硬件上,也针对Transformer网络架构做了专门的硬件优化,重塑了神经网络架构,减少算子数量,引入了先进的量化、微切片推理等技术。
微切片推理技术可以把一个比较大的模型切成更细粒度的切片,在更细粒度的层面上对整个算子融合,包括边缘计算等做加速,充分利用较大的配套内存,提高配套内存的使用率,尽量去降低跟DDR的交互。
因为大家知道,其实在数据读取上,读取配套内存跟读取DDR,性能大概有1-2个数量级的差异。除此之外,我们还专门针对Transformer里面的激活函数和分组卷积做了专门的加速。
大家都知道神经网络里面有不同的数据类型,这颗Hexagon处理器上有标量、向量和张量加速器。尤其是张量加速器,跟上一代产品相比,算力翻倍。
另外是量化技术,功耗对于终端设备是一个非常关键的问题,所以我们在做模型推理的时候,对模型做量化是一个非常好的手段。高通此前就提供了对INT8和INT16的支持,甚至我们支持它们之间的混合量化。有些神经网络架构对首尾层精度要求比较高,但在中间层对精度要求没那么高,所以我们提出的混合量化,可以针对某些层用INT16去做量化,对于精度要求不那么高的,用INT8去做量化。

这样既可以享受到INT8量化带来的性能优势,也可以享受到INT16带来的精度优势。在去年年底的骁龙峰会上,第二代骁龙8宣布首次支持INT4精度量化。INT4量化跟INT8量化相比,可以带来60%的功耗节省或者90%的性能提升。
四、一次开发多端部署,打通软件底层加速生态扩展
前面讲的大多数跟硬件相关,在软件方面我们推出了高通AI软件栈(Qualcomm AI Stack),这是一个跨平台、跨终端、跨OS的统一软件栈,它贯彻了我们的每一条产品线,包括手机,汽车、PC,还有各种IoT设备、机器人等。
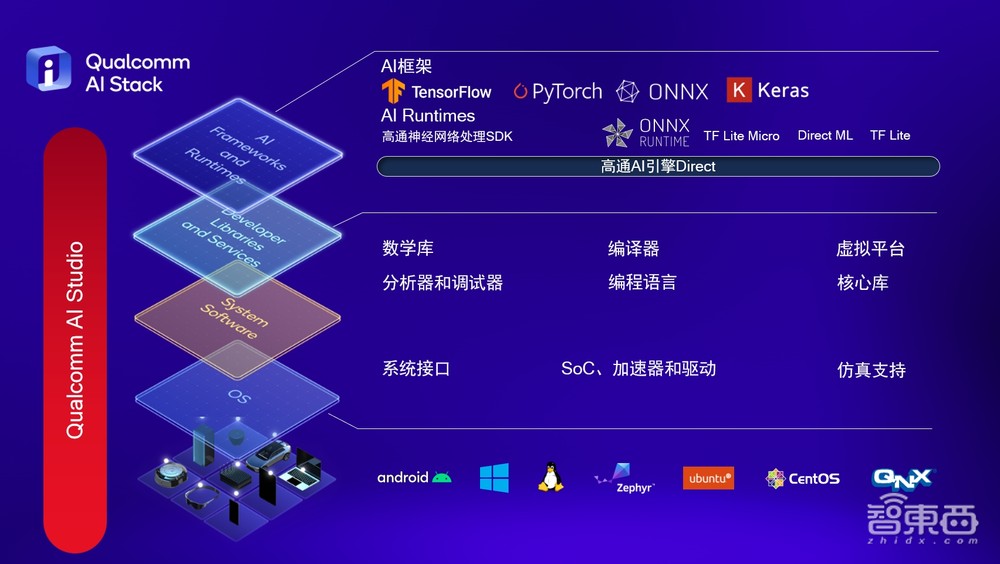
这张图就是我们高通AI软件栈的整体框架。从上往下看,最上面是我们的框架层,我们支持目前主流的框架,包括TensorFlow、PyTorch、ONNX、Keras等等。
再往下是Runtimes层,高通有自己的Runtimes,叫高通神经网络处理SDK,我们的合作伙伴或者开发者可以直接调用我们的Runtimes。当然,我们也支持开源的Runtimes,包括像ONNX、Direct ML、TF Lite等等。我们还有更底层的模块去支持第三方的Runtimes,叫高通AI引擎Direct。第三方Runtimes可以调用高通AI引擎Direct的接口,充分利用高通AI引擎的AI硬件加速单元来做推理加速。
再往下就是开发者库和服务层,我们提供丰富的加速库给到开发者去做调用。同时,我们还提供编译器,让开发者在做模型转化时对高通底层的硬件更友好。同时我们的编译器也可以支持用户通过我们给定的引导去写自己定义的算子。
除了编译器之外,我们还提供比较丰富强大的分析器和调试器。开发者在做推理部署的时候会发现,很多时候推理性能或者精度不如人意,我们的工具可以告诉开发者整个推理性能在哪里;网络结构、推理结构对高通硬件是否友好;或者是哪一层引起的精度问题,是因为量化位宽不够,还是本身的算子在高通HTP实现的效率不够好等等。
再往下就是我们的系统层。系统层提供了丰富的系统接口,也提供了各种各样底层的Kernel驱动器。当然,我们还提供了一个仿真支持。如果开发者没有拿到高通的平台或者开发板,但又想知道整体算法在骁龙平台上部署的表现情况或者精度怎么样,可以用我们的仿真支持,我们有一个模拟器会给到大家。
再往下就是OS层,高通的产品线非常丰富,OS层支持安卓手机、平板、PC的Windows系统,还有各种IoT设备采用的Linux或者是CentOS等等,还有我们的QNX。我们把所有的OS都集成在高通AI软件栈里面,能够支持高通所有的产品形态。
除此之外,我们还有高通AI模型增效工具包(AIMET),AIMET最主要有两个功能,一个是帮助大家做量化,我们支持PTQ(量化感知训练)和QAT(训练后量化);另外是模型压缩。
总结一下,高通AI软件栈是一个跨平台、跨终端、跨OS的统一软件栈。高通AI软件栈旨在帮助合作伙伴及开发者在骁龙平台上更高效地完成软件部署,提高它的扩展性,也就是所谓的一次开发、多次部署。以上就是我今天演讲的全部内容,谢谢大家!
以上是万卫星演讲内容的完整整理。
