








芯东西(公众号:aichip001)
编辑 | GACS
9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在首日AI芯片架构创新专场上,奎芯科技联合创始人兼副总裁王晓阳分享了题为《驱动云/边缘侧算力建设的高性能互联接口方案》的主题演讲。
王晓阳介绍了在目前AIGC推动算力需求快速增长的大环境下,基于HBM的算力芯片所面临的瓶颈和挑战,包括与SoC紧耦合带来的尺寸限制、面积占用、工艺限制、热敏感,以及先进封装导致的封装成本高、良率下降、生产周期加长等问题。此外,在大型语言模型(LLM)的推理阶段也存在一定的内存瓶颈,降本增效问题亟待解决。
为了解决这些问题,奎芯科技提出了自研的高性能互联接口及解决方案,把HBM和SoC的芯片进行解耦,实现了SoC可利用面积增加44%,整体系统内存带宽和容量增加1/3,最大封装面积增大1倍以上等显著进步。针对内存瓶颈提出HBM近存计算方案,单晶圆最高可提升50%算力。
以下为王晓阳的演讲实录:
各位嘉宾,下午好!今天非常荣幸参加AI芯片峰会,我们希望能够给大家介绍一下奎芯公司在算力建设方面的思考,以及我们对于高性能互联接口方案的介绍。
奎芯科技主要提供IP产品、Chiplet产品,以及一些集成服务,我们的IP产品主要有接口IP、技术库IP、模拟IP,此外还提供Chiplet产品和解决方案。我们现在在国内有5个办公点、4个研发中心,研发团队规模超过150人。
一、大模型游戏规则下,使用HBM的算力芯片面临瓶颈
首先简单介绍一下AI的发展趋势。最近几年,AI模型的发展非常迅速,差不多以每年10倍的速度增长。ChatGPT-3的1750亿参数已经成为过去式了,未来可能迎来万亿参数的时代。我们所需要的AI系统的算力也越来越大,基本上每几个月要翻一倍。
当前,我认为我们更需要思考在全新LLM(大语言模型)游戏规则下,理论算力的提升是否还像以前那么重要,未来的瓶颈究竟在哪里,我们该如何提高效率、降低成本,来达到可持续性的发展。
最近几年,体系结构讨论最多的问题之一就是两堵墙:内存墙和I/O墙。多年来,随着工艺的进步、计算架构的革新方法,理论算力的增长速度非常惊人,但内存带宽、互联带宽的增长却相对缓慢,造成了巨大的落差。
最近,业界也在尝试很多方法解决这样的问题,包括增加缓存、堆叠缓存,尽量提高单节点的算力,用更高速的互联接口与更高效的互联协议来做芯片互联等。
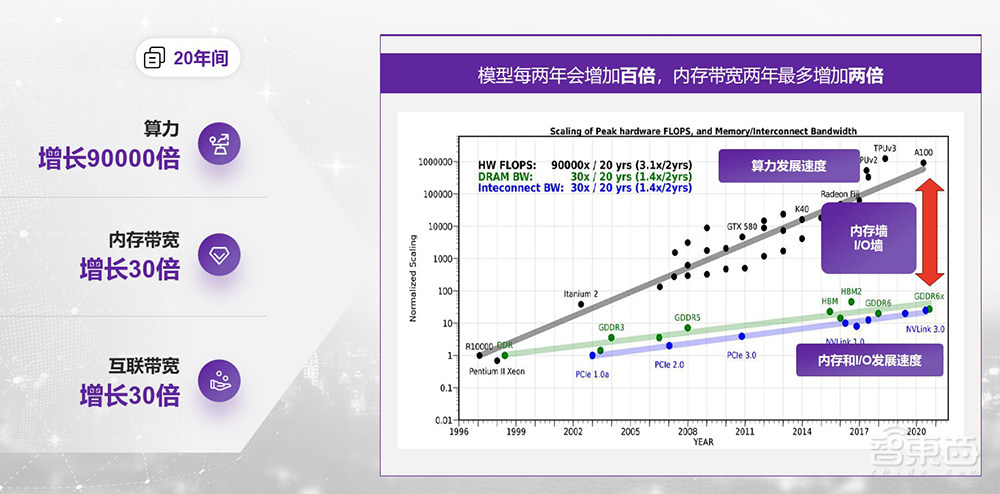
正因如此,在如今新的LLM的游戏规则下,内存的容量、带宽以及互联带宽已经逐渐成为核心竞争力,算力的重要性相对下降了一些。我们可以看到,最新的英伟达芯片非常重点地强调了HBM带宽、LPDDR的容量、NVLink的速度等;包括AMD的MI300系列,对算力指标都没有那么强调,这个在过去是不太可能的事情。我记得在去年的芯片发布会上,对算力指标还是非常重视。
目前主流的大算力AI芯片仍以HBM为主,虽然HBM可能比较贵,但如果用成本除以带宽来讲,单位带宽成本还是最低的。目前HBM的使用有比较多的限制,主要因为HBM的颗粒必须跟SoC对齐和封装在一起,是紧耦合的状态,而紧耦合会导致一些问题。
首先,HBM的尺寸是固定的,SoC的尺寸必须符合HBM尺寸的量级,所以SoC的芯片尺寸是有限制的。同时,因为紧紧贴合的原因,同一颗大芯片,放的HBM的颗数有限。HBM颗粒必须和计算部分进行绑定,所以热传导影响非常大,而DRAM颗粒对热很敏感,超过85度以上就需要重新加速,所以对效率会造成很大的影响,对SoC的频率也有限制。
此外,在SoC设计方面也不够灵活,因为HBM可以左右两边摆,上下两边摆,但以这样的方式去放的话,可能要采购不同的HBM的HOST IP。当然,工艺也是一个问题,SoC的设计选择不同工艺的时候,更多考虑的是在这个工艺下的HBM的IP是否可以获取,这是一个设计公司普遍面临的问题。同时,因为HBM HOST IP的面积比较大,所以SoC的面积占用比较多,没有空间放下更多的计算。
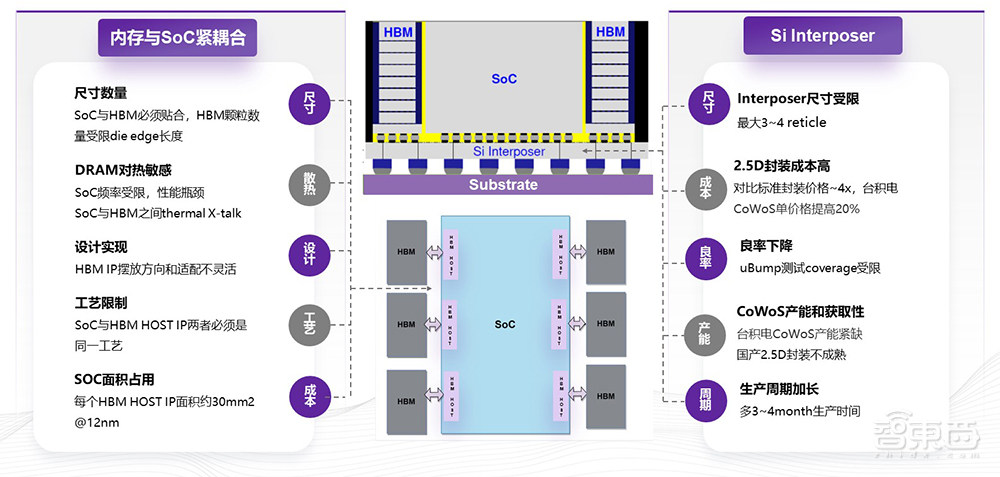
主流的HBM的应用还是以先进封装为主,包括CoWoS和硅桥的形式。对于这种形式,首先它的Interposer(中介层)尺寸受限,目前最大可能是3-4个reticle(掩膜);其次,2.5D封装成本比较高,粗略估算可能比普通的基板贵4倍左右,最近台积电的CoWoS也在涨价;另外,因为是Micro-bump连接,所以它测试的覆盖范围是受限的,良率会降低,尤其是封装超过6个HBM和2个ASIC以后,它的良率降低会很明显;最后还有国产工艺的问题,国产2.5D先进封装目前还不是非常成熟。
种种因素加起来,目前使用HBM、用2.5D来封装还是存在很多限制或者成本的问题。
二、提出内存互联解决方案M2LINK,解耦HBM和SoC芯片
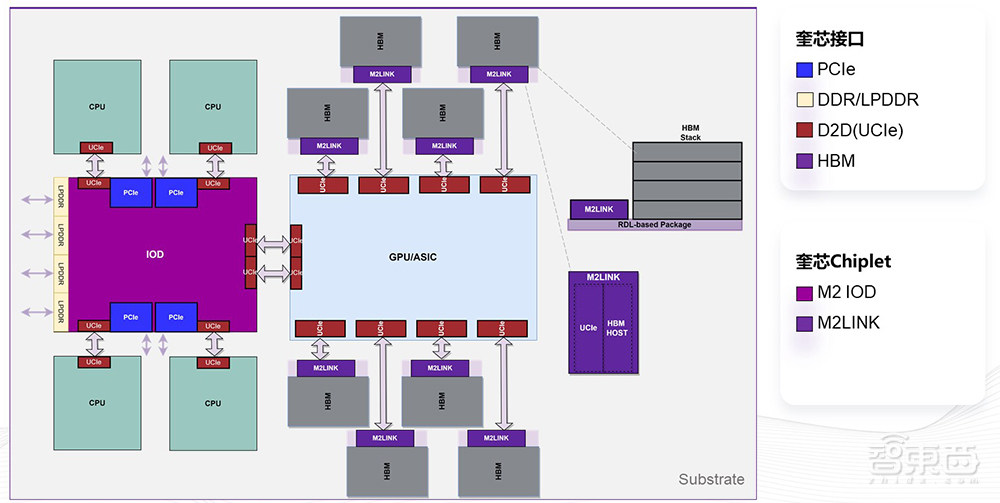
奎芯科技正在基于我们自己的D2D(UCIe)接口和HBM接口,打造一个新的方案M2LINK,它的核心诉求是把HBM和SoC的芯片进行解耦。该方案的基本做法是把HBM的接口协议转化成UCIe协议,然后在这个标准模块上用RDL Interposer来封装,把它做成一个标准模组,然后通过普通的基板和SoC进行封装。这样整个距离可以拉到大概2.5公分左右,也不需要和主SoC耦合和绑定。
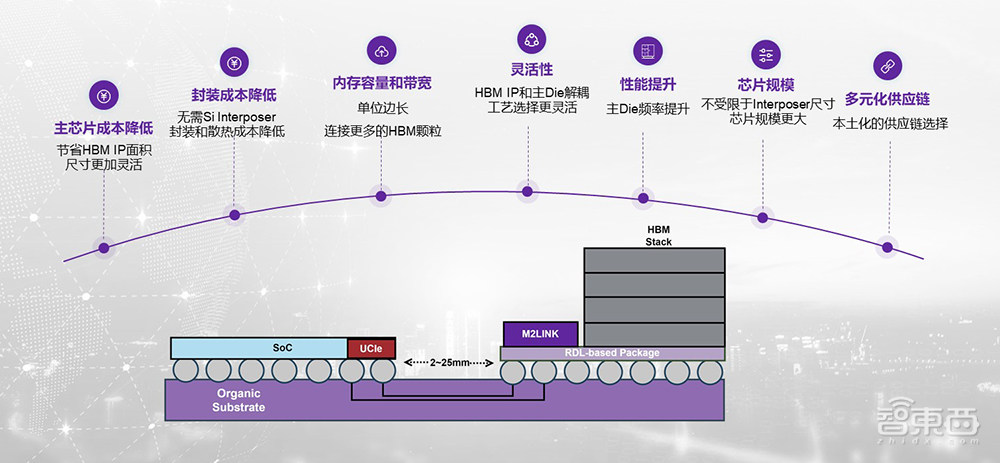
这样做的好处有很多,比如主芯片的整体成本会降低,因为节省了很多面积;其次,封装的成本降低,并且散热会更容易,主芯片的频率可以再增加;芯片系统的内存容量和带宽会增加,因为单位边长可以塞下更多的HBM;性能得到提升,因为主Die频率可以提高;另外,芯片规模可以变大,因为不受Interposer三个reticle的限制;此外在国内,整个封装的供应链可以利用得更好,避免了2.5D的问题。
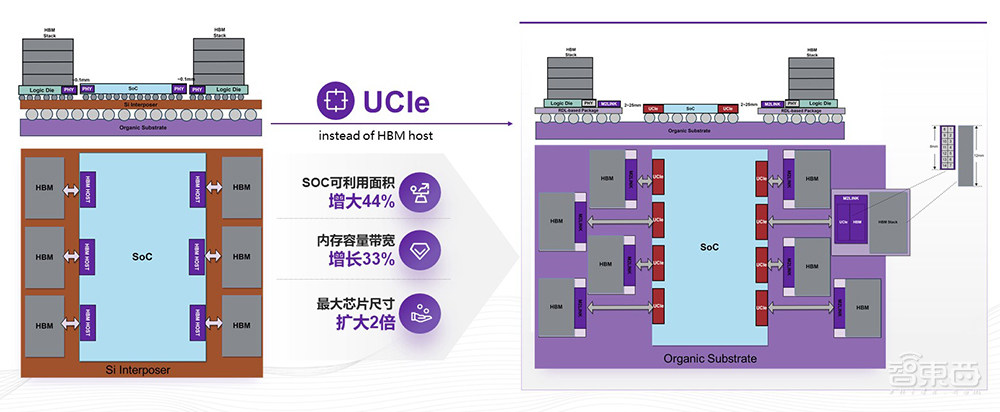
我们可以看到这个俯视图,左边这颗芯片的单边长假设是30多毫米,可以两边各放三个HBM;如果用我们的方案,两边可以各放4个,也就是共8个HBM。这样做的话,同等大小的SoC可利用面积增加44%,整体系统内存带宽和容量可以增加1/3,最大封装面积可以增大1倍以上。
在这个基础上,我们对于未来的CPU+AI或者GPGPU集成的方案也有一些规划。对于芯片设计客户来说,除了刚才提到的M2LINK、HBM标准模组以外,奎芯还可以提供兼容UCIe的D2D接口、LPDDR5X的内存接口、PCle的接口,以及可以做成一个标准的I/O Die,来解耦计算、存储与I/O,加速客户芯片设计的速度,降低设计复杂度,从而降低整体成本。
三、自研LPDDR5X、D2D接口,提供全套HBM3、Chiplet解决方案
要做到以上事情,首先必须得有高质量的接口IP做保障。我们自研的LPDDR5X已经成功流片,4X已经硅验证。我们的速度支持业界最高的8.5G,目前支持像台积电6纳米的工艺。我们LPDDR的每一个PHY都有独立的MCU支持firmware based training,也可结合HW training提供更好的兼容性。同时,我们也支持多频点设定和自适应动态监控与调整,支持多种低功耗的模式选择,且全系列包含内嵌的BIST电路方便测试。
我们的D2D的接口也已经研发完成,支持UCIe 1.1标准,同时会做两个版本,一个是标准封装,一个是2.5D的先进封装。单片的速率最高可以达到32G,最低功耗小于0.5pJ/bit,我们做到了非常低的端到端延迟,同时我们会提供适配层,支持客户的自定义协议层。

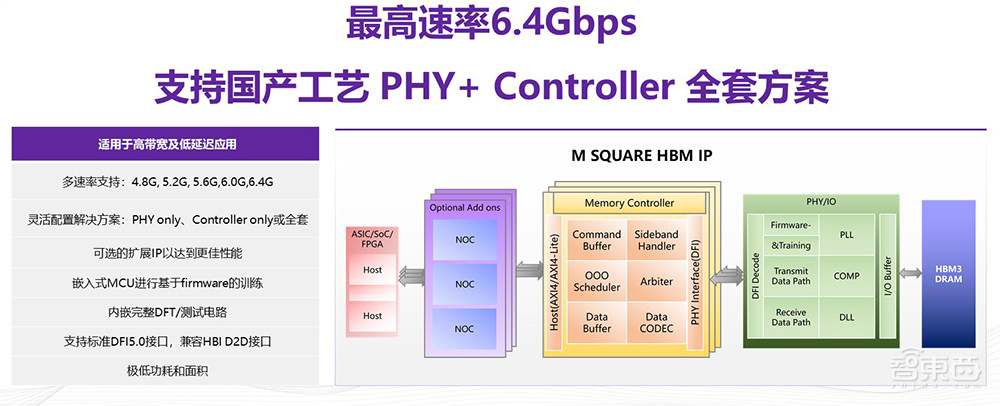
奎芯可以提供全套的HBM 3 HOST IP解决方案,包含HBM的PHY、I/O、Controller,以及一些针对性能优化的可选的IP。HBM3的IP已经在客户端落地,最高速度支持6.4Gbps,可以支持多频点的选择,内嵌的MCU可以支持firmware based training,内嵌完整的DFT/测试电路,并且这个IP也具有极低的功耗和面积。
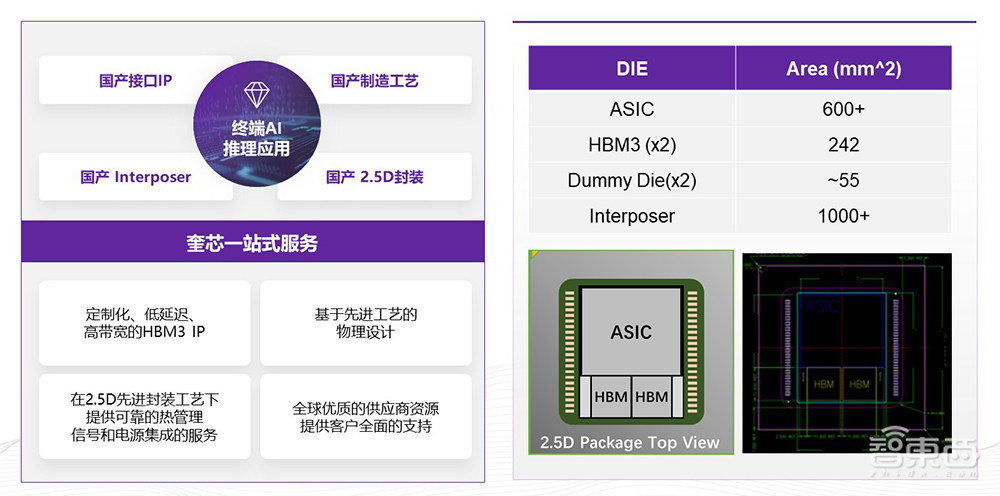
基于奎芯对整个封装供应链的整合能力,我们HBM3的国产化落地案例也已经和客户正在紧密开发中。目前和客户一起打造的是一款标准的带有HPM3的2.5D的全国产封装的大芯片,我们自己提供了HBM3的IP,提供interposer的设计、2.5D的封装设计,以及完整的解决方案。这个芯片面积达到1000平方毫米以上。
对于Chiplet,大家可能最初认为主要先落地于云端或者大芯片上。其实在端侧,也有Chiplet落地的案例和需求。
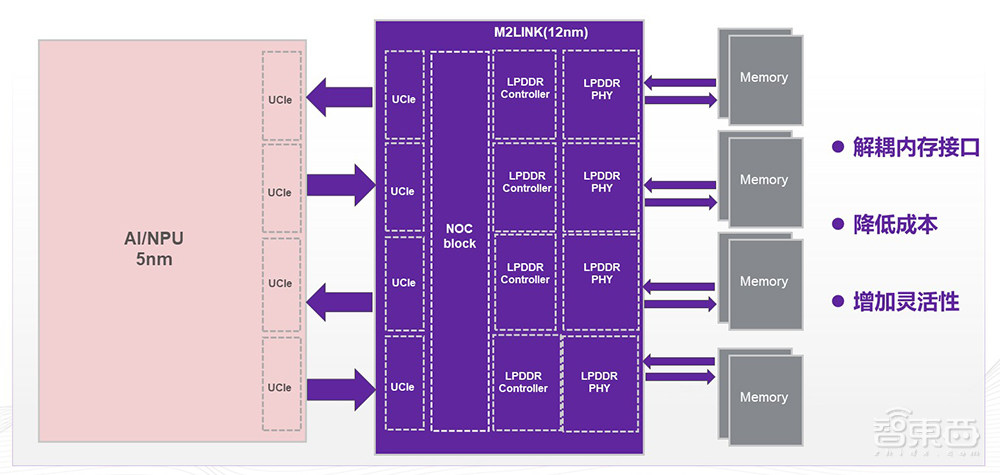
目前,我们在为客户打造一款具有极低功耗的边缘计算或者端侧计算的产品,这是一个I/O Die。对于这种场景,客户希望计算部分用最先进的制程来做。但针对5纳米和4纳米昂贵的成本,客户希望能够解耦内存接口,放到相对成熟的工艺上实现,并且为工艺演进提供灵活性。
我们结合客户的需求,打造了一个包含LPDDR5 HOST的完整I/O Die,实现了内存接口的解耦,降低客户成本,为客户未来的产品升级增加了灵活性。
四、提出近存计算解决方案,单晶圆算力可提升50%以上
再映射一下之前讲的AI的趋势。LLM是最火的话题,但我们未来更多的是思考LLM在训练完成之后,做微调、推理的时候如何降低成本的问题,或者提高计算利用率。
最近有很多公司在做分析和研究,我们看到,在推理过程中,大部分计算可能都是GEMV,即矩阵向量乘的计算。这种计算的特点是计算密度非常低,需要更高效地用内存的读写来解决问题。一些大公司现在开始尝试存内计算,包括一些国内公司。
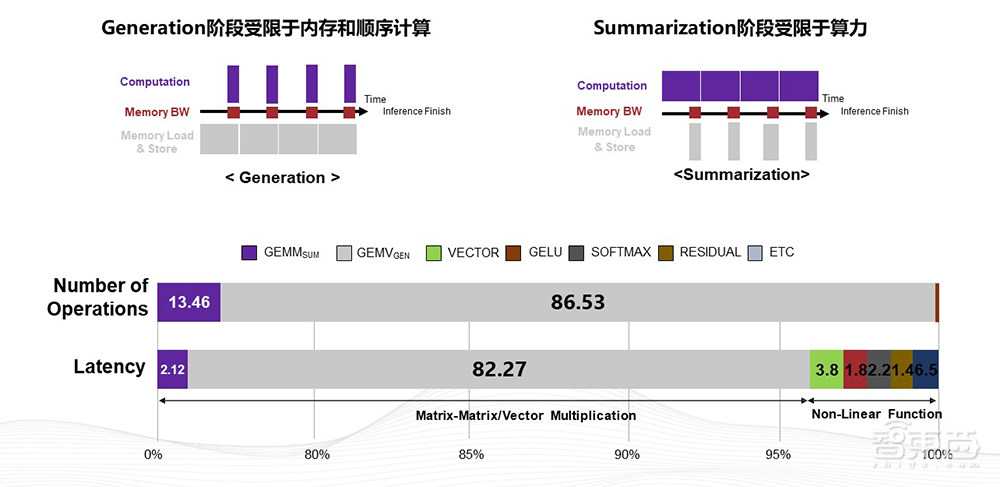
我们认为,当前阶段用近存计算相对容易,并且短期内通用性更强。我们可以在M2LINK的基础上整合NPU的计算,更充分高效地利用HBM带宽,提高单位算力内存容量和带宽,降低规模,从而降低成本。由于计算芯片力度的变小,良率会得到提升,所以单wafer(晶圆)可以获得的总体算力会提升。当然,还可以根据模型的需求,来灵活地组合算力。
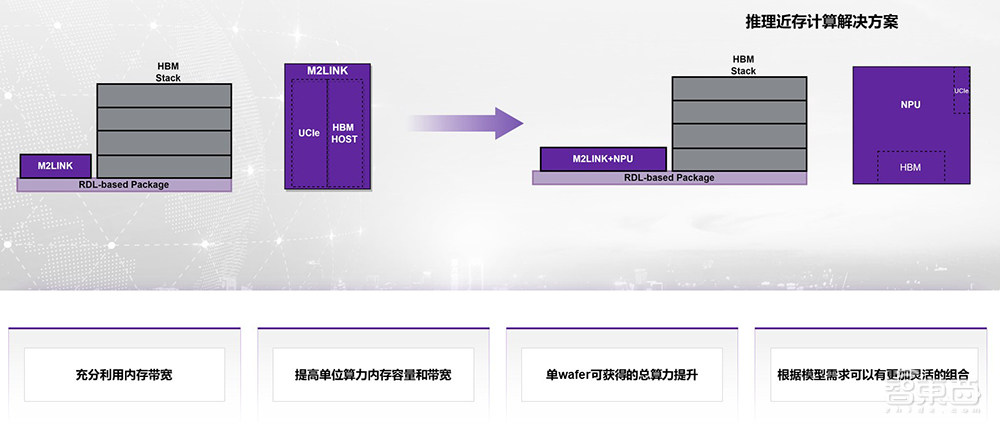
这个方案本质就是可以将一个大的GPGPU或AI芯片拆成小粒度,每一个小粒度的GPU或者NPU,把它和HBM颗粒绑定,中间的主SoC可以做成一个CPU,这主要是负责任务的调度或者做一些计算。这样的话可以充分地利用好每一个HBM的带宽,极大地降低HBM模组和主芯片之间的带宽。我们这么做的话,它的UCIe的互联带宽要求可以降到原来的1/5左右,这样可以变相地堆叠更多的HBM模组,提高效率。
举一个例子,GPT-3模型大概有400G的存储容量需求,用H100/A100的80GB HBM来存的话,可能需要5个以上的H100/A100才能放得下。如果把大的H100/A100拆成8个小的,每个HBM仍然16GB的话,A100算力的一个NPU差不多可以匹配8个HBM,相当于128G,一个完整的模型只需要三颗芯片就可以放得下,整体降低了系统的开销成本。
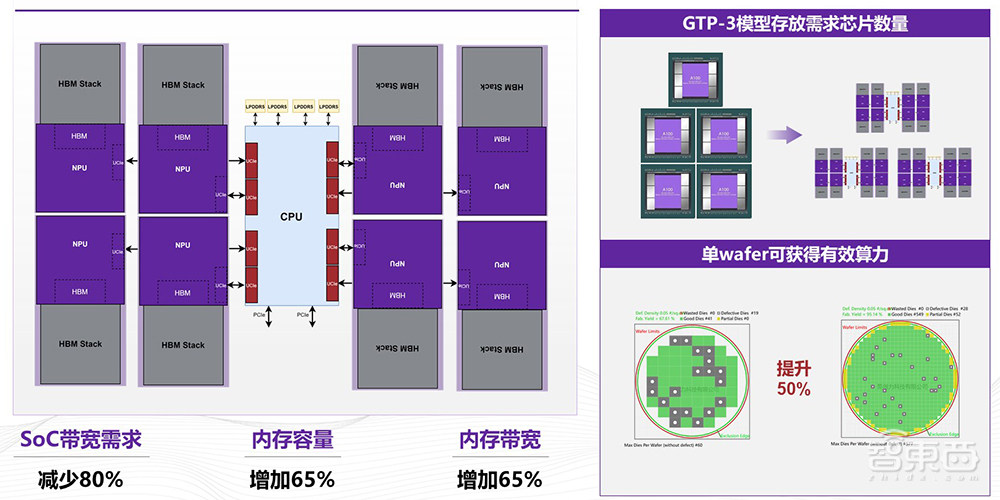
另外一个层面,H100可以在一个wafer上切出大概60颗左右,算上一些报废率,可能在50颗左右。此外,一颗芯片算力不可能用完,可能达到80%左右。
我们可以计算一下,一个wafer如果用一颗SoC来做的话,大概可以做到40颗完整的H100的算力。如果把粒度拆小,100平方毫米是一颗NPU的话,一个wafer 12寸上大概是600颗左右,去掉坏的剩余500多颗。整体上,一个wafer算力可以提升50%左右,这也是变相节约成本的方式。当然,NPU和HBM深度绑定之后,整体系统上的内存带宽和容量也得到大大的提升。
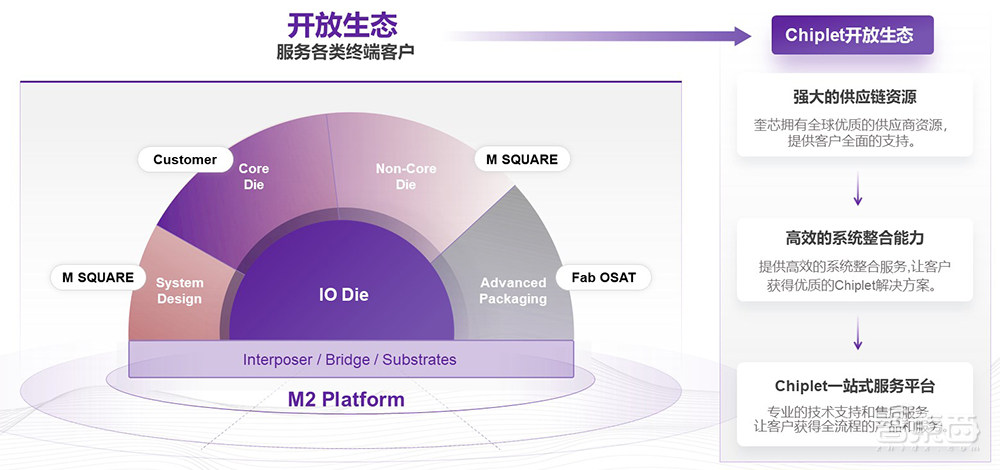
奎芯科技希望建立一个开放生态一站式的Chiplet的服务平台,我们提供接口IP、Chiplet裸Die、系统设计、先进封装设计等服务,整合供应链资源,为客户提供完整的一站式解决方案。以上是我的分享,谢谢大家!
以上是王晓阳演讲内容的完整整理。
