








芯东西(公众号:aichip001)
编辑 | GACS
9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在9月15日高能效AI芯片专场上,知存科技业务拓展副总裁詹慕航分享了主题为《大算力需求下存内计算的应用和发展趋势》的主题演讲。
詹慕航分享说,AI神经网络的核心就是矩阵乘法/乘加运算,越典型的大模型越需要矩阵运算,便越适合存内计算的方式。知存科技顺应AI时代的新型需求,创新使用Flash存储器完成神经网络的储存和运算,以解决存储墙问题。
詹慕航列举了WTM-2端侧存内计算AI芯片,该系列芯片有着极低功耗、极低延迟的优势特点,其已经量产商用的国际首颗存内计算芯片WTM2101,功耗仅5uA-3mA,同时兼具高算力,适用端侧智能物联网场景。接着,詹慕航预告了针对视频增强场景的WTM-8系列芯片,该芯片可以将单核算力提升80倍,效率提升10倍。

以下为詹慕航的演讲实录:
非常感谢主办方能让这么多AI芯片行业专家们齐聚一堂,我们很欣慰地看到身边有这么多战友。
大家都是在为自主可控的目标,无论是近存计算还是存内计算,或者是Chiplet、3D Bounding,无论是数字、模拟,SRAM(静态存储器)、RRAM(阻变存储器)或者是Flash(快闪存储器)。大家都是在做同样一件事情,就是将算力提升、功耗降低、面积减少、延时降低,还有将存储器的带宽提高,这也都是我们在接下来可能要共同去努力的方向。
当然不得不提,我们很感谢,知存科技作为存算一体领域里的“排头兵”得到了行业和资本的认可。我们获得很多荣誉,近期获得了国家级专精特新“小巨人”。我很乐意跟大家分享一下我们这个“排头兵”做了什么、做到什么程度,做一个抛砖引玉。
知存科技公司成立较早,于2017年成立。对于整个存内计算领域,特别是模拟Flash闪存领域,我们行动得较早。创始团队从2013年开始就着手研究,也有了一些成果。
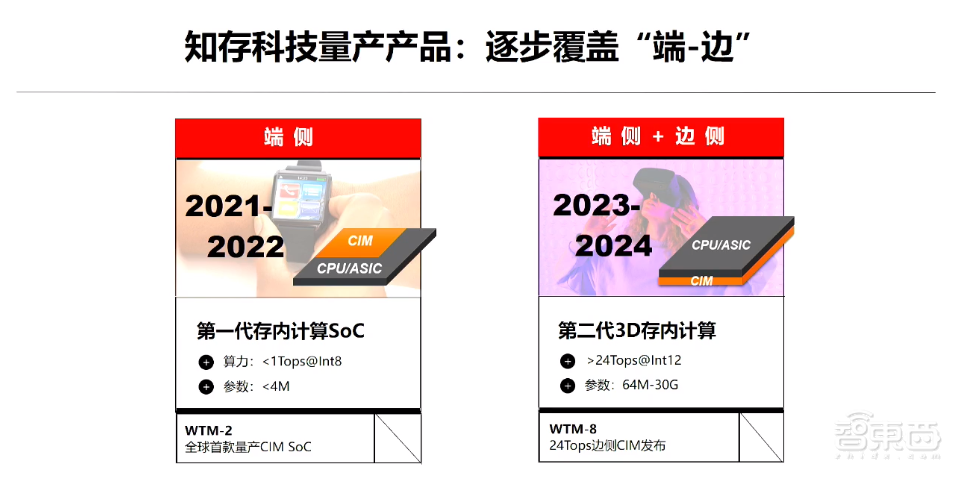
在做芯片方面,我们选了最艰难的一个模式。2018年,知存科技首颗存算一体的芯片的实验样本流片;2020年,小批量生产存算一体加速器WTM1001;2022年,全球首颗基于模拟Flash存算一体的芯片WTM2101正式量产。截至今天,知存科技的出货已经到了kk级别。我们今年还即将投片和发布一款基于边侧的图像视频处理芯片WTM-8系列。
今天和大家分享的内容主要分三大部分。第一,AI计算和内存墙的问题,包括如何从根本上解决内存墙/功耗墙等问题;第二,知存科技存内计算芯片产品及部署;第三,存内计算的发展趋势。
一、架构革新打破“内存墙”,用28nm做出逼近7nm的算力
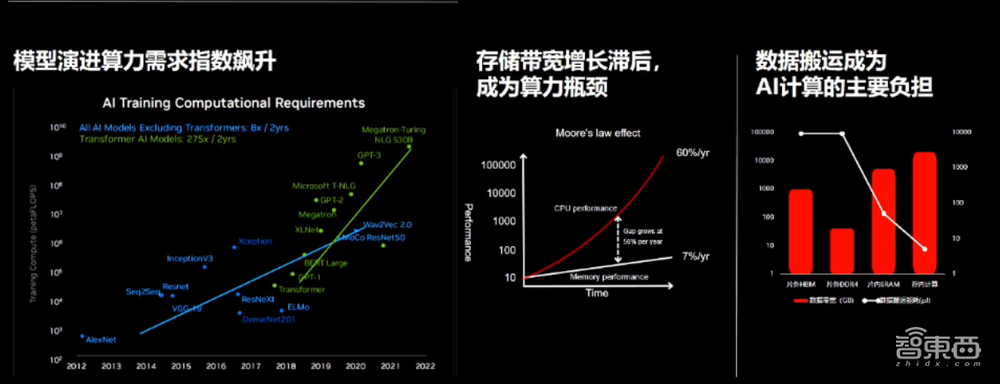
无论是在摩尔定律有效的阶段,还是现在逐渐失效的阶段,有一点是不变的,就是对算力本身的需求。对于除了Tranformer之外的所有AI模型,(算力需求)每两年有8倍的增量;对于AIGC、生成式AI包括Tranformer模型,(算力需求)有275倍的增量。
算力本身不是伪命题,它只是一个硬币的一面,另外一面是存储的带宽,或者叫吞吐数据的速率。这些年,行业在算力上的发展还可以,但存储的性能指标有一些滞后,有一个很大的Gap。时常我们在抓取数据、吞吐数据的时候,消耗了大量的时间和功耗,整个能效比大大地拖延。
要解决内存墙/功耗墙的问题,需要认识到先进工艺已经不能有效地解决大算力的需求了,那么我们就从架构上进行革新。
我们回顾一下高中物理的知识,基于欧姆定律:输出电压=电流×电阻,电阻倒数就是电导,Flash是浮栅晶体管,我们通过编程可以微调电导值,亚阈值可以做出很多。
大家在市面上买到的Flash是基于NOR Flash,买到后需要从底层改写Flash的浮栅晶体管和电导。做完之后,输出的电流,整体比如是一千行、一千列。它有两个大的优点:一是密度大,是1000×1000,这是100万个cell;二是并行度高,因为它是模拟计算。
存内计算是放在AD(数模转换)之前,就去做这样的运算,它的并行度非常高。比如读取一次用户数据的时候,就可以在同时进行这1000行、1000列、100万的运算。传统GPU/CPU要去抓取十几万次,我们只需要抓取一次就能做百万级的并行运算。
整个AI神经网络或者CNN矩阵运算、卷积运算,核心实际上就是矩阵乘法/乘加运算。越是大模型,越是矩阵运算,越适合存内计算的方式,因为存和算本身在一起,一次性并行完成。
从工艺来看,降低成本是行业共同的目标之一,知存科技的存内计算基于成熟工艺,通过架构的创新,能够达到两代以后先进工艺所要达到算力与能耗需求。我们在去年量产的WTM2101芯片是基于40nm制程,该芯片在算力和能效比上相当于12nm工艺的6到10倍。
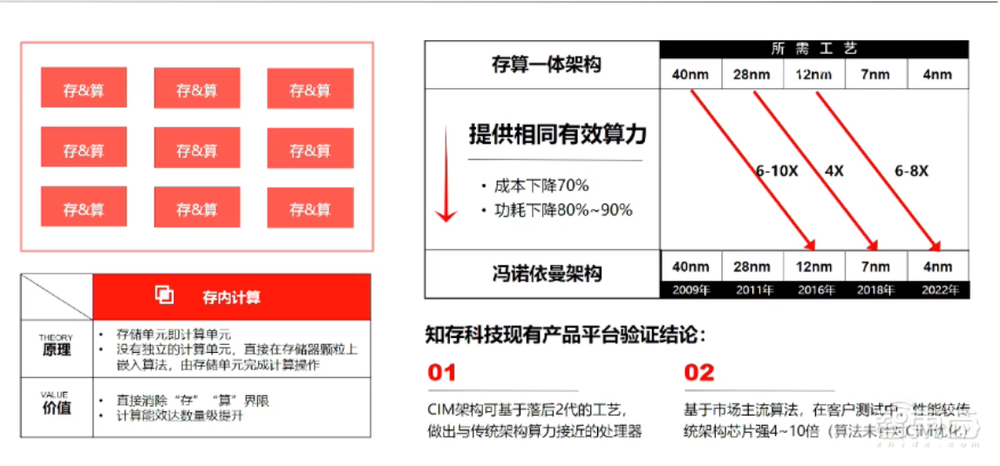
有人开玩笑说,这是“非冯”和“冯”的一场battle。存内计算最核心的原理是在模拟器件上,因为它是进行本征计算,存储单元本身就是计算单元,所以我们没有独立的计算单元,也没有独立的存储单元,这样就节省了很多数据的吞吐量、搬运的能耗。
二、基于Flash的量产存算一体芯片,逐步覆盖从端到边
接下来给大家汇报一下知存科技目前的产品,以及知存科技将来的技术路线图。
经历过这么多的事情,一句话总结:我们实现了0到1的突破。轻舟已过万重山,我们现在已到了量产级别。要把一颗芯片从样片做到量产,我们有额外的工作要去做。除了之前做很多的设计,我们要去解决可靠性、一致性、良率等诸多问题。
知存科技整个团队在这几年的时间里,所有该踩雷的都踩过了。关键是知存科技作为一个“排头兵”,前面没有可以对标的产品,没有可以去借鉴的技术。
从整个规格的定义,从Flash架构到MPU核,我们存算架构的设计都是自己摸索出来。我们在前头拿着手电筒,在无人区探索出来,包括前端的设计模拟、包括数字、前端后端封测,整个团队付出很大努力。幸亏有惊无险,我们走过来了,并拥有了目前业界唯一可以基于Flash的存算一体架构量产芯片。
对于生态的建设,知存科技志存高远。我们有专事工具链的团队,不光是做一颗好的芯片,我们要推给客户的是一颗好用的芯片。在算法的移植上和客户对于芯片的使用上,我们对于工具链早早地同步进行投入。
介绍一下我们的WTM2101芯片,它用于端侧,算力小于1Tops,精度在INT8以下,参数量为1.8MB,当然我们的算力不停地会有迭代和演进。
在WTM2101芯片上,模型参数的大小已经远远超过市场的需求,其拥有的50Gops算力在很多场景跑不满,也放不满1.8MB的模型和参数。对于模拟精度的控制,我们有稀疏和致密的方法,在WTM2101上我们可以做到8-bit。WTM-8系列芯片有12-bit的精度,参数量也是从几十MB到几十G不等,取决于客户的应用场景和客户的模型大小。
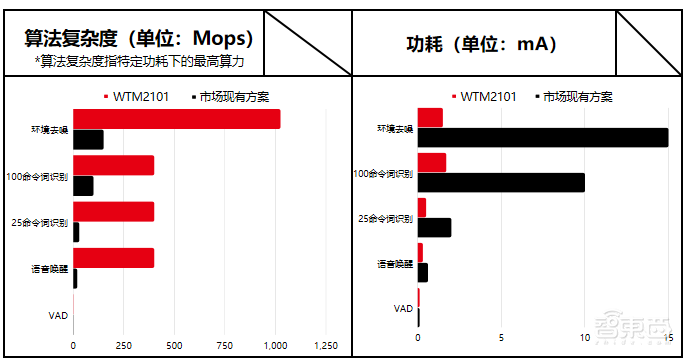
给大家看一些实例,这是量产产品真正的实测数据。用算法复杂度间接地折算,来表现WTM2101的算力,可以看到在降噪以及命令词的识别场景下,相较于市场现有方案,WTM2101在AI算力上有数十倍到百倍的提升;与此同时,功耗降低数十倍到微安级别。知存科技的算法复杂度很大,1000MB左右,市场现有方案能存放的算法复杂度却很小。
WTM2101的应用产品包括智能手表等,当客户把知存科技的芯片放到手表里,发现有以下两件事情:
1)健康算法。无论你做PPG、ECG、心跳心率,还是姿态的监控,比如一个抬腕的健康类的算法,在用了我们的芯片以后24小时里的误识别率竟然达到了0。因为要去做AI Training,我们给它喂大量数据、大量时间的Training训练之后,在这个芯片真正应用的时候,它能够很精确地判断出来。
2)功耗小且Always on。由于我们的方案节省功耗,所以续航很好,如果你的手表以前需要4天充一次电,我们直接会延长续航时间2-3天。如果算力有10倍的提升,功耗又有10倍降低的时候,整个能效是2个数量级的提升,我们的方案是非常惊艳的一个产品。
WTM2101覆盖的产品目前主要有语音识别和人声增强、健康算法等方面。
具体来说,语音的识别包括人声增强。WTM2101的应用场景有对讲机、助听器、TWS耳机。另外在降噪上,我们有大量Training训练数据,包括做一些加噪的训练、做量化。我们在提取、识别噪音的时候是非线性的,所以它可以精确且快速地识别出各种人声之外的背景噪音,并有效地把它消除掉,包括回声消除。健康算法这个技术的应用场景除了手表,还包括医疗行业的产品形态。
对于端侧而言,WTM2101是一颗大算力且有效的处理器芯片。
我们的合作伙伴包括一款叫CW01的儿童手表的ODM(原始设计制造商)。合作产品还有INMO Air2眼镜,我们提供命令词识别,戴着眼镜的时候精准、快速地识别语音指令。另外还有上一周刚刚发布的魅蓝K歌耳机,大家可以搜一下这款耳机,299元,可以K歌,有耳返的功能,这是一个物有所值、非常好玩的产品。

接下来是一颗支持大算力和端侧大模型的视觉类芯片——WTM-8系列芯片,大家可以把它理解成类似于R1这颗芯片。它在端侧可以打破很多使用场景,因为它在散热上没有忧虑,对功耗的控制非常好。从视频方面来说,渲染用传统GPU做也还不错,但超过三维重构、插帧、超分都是更适合用神经网络技术。
WTM-8系列芯片的高性能成像功能类似于实现AI ISP功能,产品可以将功耗大幅地降低,对于有散热要求的情况就会非常友好。对于分辨率,产品从4K一直可以支持到8K分辨率,帧率可以支持60、90、120。对于视频显示,在帧率比如插帧方面,知存科技可以从30帧插到60、60插到90、90插到120。对于超分,比如710,我可以超到1080p、2K、4K,包括做一些AI的ME、MC等运动补偿前处理,以及后处理的去噪、宽动态HDR等。
打个比方,当你拿手机拍照,出来是很清晰的照片。但当你去录像,截屏经常比较糊。如果有我们这颗芯片加持,大家在录像的时候,它已经进行了AI插帧和AI超分,你截取的照片就会非常清晰。
我们目前在和一些行业头部客户做深度合作的预演,对于将来产品形态,特别是有关视频视觉,有更加长远的预演。
三、大模型、智能驾驶,将是存算一体芯片的新战场
未来在AI芯片或者存算会是什么样的场景?这几天谈得非常多的是大语言模型,大模型出现神经网络属性及矩阵运算的形态,我们相信,一定是非常适合存算一体或者存内计算这样底层架构的创新。相比冯·诺依曼来说,它是非常适合。我们目前的状态是在做研究。
还有一些更加智慧的产品形态。大家可能在餐馆里见到一些送餐机器人,这是比较初级的机器人;更加智能的机器人,你点了菜之后,它可能帮你进行后端的处理。以上都依赖于在高效大算力芯片的支持,这在不久的将来这都可以实现。
还有一些类似于高级驾驶辅助系统ADAS等应用,我们也在积极跟进,而且也相信这很快会成为AI芯片、存算一体芯片的一个主战场。
最后我想说,很高兴看到越来越多的战友和伙伴加入到AI芯片领域,再到我们存算一体的家庭里,我们希望把整个市场的蛋糕越做越大,大家都能够做自主可控、自力更生的事情,谢谢大家!
以上是詹慕航演讲内容的完整整理。
