








芯东西(公众号:aichip001)
编辑 | GACS
9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在首日开幕式上,后摩智能联合创始人、研发副总裁陈亮分享了题为《存算一体:颠覆性架构重塑AI芯片》的主题演讲。
陈亮谈道,面向大模型时代的新需求,后模智能正计划推出扩展大模型应用边界的第二代天璇架构,以及基于这一整体性能、效率与灵活性更强架构的后摩鸿途H50芯片,预计在2024年正式推出。
创立于2020年的后摩智能是存算一体芯片公司之一。公司于2023年5月正式推出存算一体智驾芯片后摩鸿途™H30,物理算力达到256TOPS,典型功耗达到35W。根据后摩实验室及MLPerf公开测试结果,在ResNet50性能功耗对比上,采取12nm制程的H30相比某国际芯片巨头的7nm同类芯片性能提升超2倍,功耗减少超50%。
H30和H50系列背后是后摩智能自研的IPU架构,陈亮谈道,该架构设计遵循“中庸之道”。如果将集中式计算架构比作居住面积和扩展性有限的“中式庭院”,那么分布式计算架构类似于“高层公寓”,容纳性好但沟通性不足。
后摩智能的IPU架构选择在两者之间寻求平衡点:在计算方面,通过多核、多硬件线程实现计算效率与算力灵活扩展;在存储方面,通过多级数据缓存实现高效数据搬运与复用;在数据传输方面,通过双环拓扑专用总线实现灵活数据传输与共享。
以下为陈亮的演讲实录:
尊敬的各位嘉宾、各位老师:大家下午好!
后摩智能是一家做存算一体AI芯片的初创公司。我们在创业过程中,经常会被大家问到一个问题:既然存算一体技术优点这么多,那为什么国内或者国外的成熟大公司他们不做呢?我们的同事们也从不同的角度给出了一些解答。
一、AI计算面临三大现状,存算一体技术带来新探索
从我的角度来看,我们希望从真正的客户需求、产业的痛点,以及结合自身的特点出发,做出一些真正有意义、有价值的创新。我们看到AI计算的现状:
首先是算法对算力的要求越来越高,但是AI芯片的计算效率还不够,这个效率包括了能效比和面效比,也就是单位功耗所能提供的算力和性能,以及单位面积能提供的性能。
第二,系统的带宽瓶颈会导致计算资源的利用效率降低,如何有效地利用带宽,提高计算资源的利用效率,会成为更大的挑战。
第三,算法还远未达到收敛的程度。各种各样新的算法还层出不穷,虽然最近Transformer类的计算有一统江湖之势,但是大家知道,真正端到端的AI计算所涉及到的计算范式还是非常丰富的。如何能够在一个处理器内部完成端到端的AI计算,从而避免AI计算在不同的处理器核乃至不同芯片之间的数据传输,进而减少数据的搬运和存储的开销也是一个难题。
基于此,我们希望借助独特的存算一体技术,给大家带来一些AI计算的不同探索。
先简单介绍一下我们公司,后摩智能是2020年底成立,2021年初正式运营。
2021年8月,我们首款技术样片完成了设计和流片,并且完成了首款量产产品的产品定义。2022年3月,我们的技术样片回片跑通了自动驾驶的算法,完成了存算一体的技术验证。同年10月,我们首款量产产品后摩鸿途™H30设计完成,进行投片,2023年5月发布了第一个量产产品,后摩鸿途™H30。
这就是我们今年5月份发布的后摩鸿途™H30存算一体的大算力AI芯片,大家在外面展台也可以看到它的实物,它的算力是256TOPS。这里面说的算力是物理算力,而不是稀疏化的算力,典型的功耗只有35W,这个功耗也是在跑实际算法过程中实测出来的。
以上是对我们公司和产品的简单介绍,下面从存算一体技术、AI处理器架构和软件工具链这三个方面来介绍一下我们公司成立两年多来的工作。
二、基于定制化电路结构,实现高效存内并行计算
首先介绍一下什么是存算一体。概念上讲,存算一体就是在存储单元的内部,完成部分或者全部的计算,它是解决芯片性能瓶颈,提高能效比的有效技术手段。
大家知道,在AI计算过程中,大量的数据在存储单元和计算单元之间交互,数据一行一行地从存储器中读取出来,送到计算单元中进行计算,再一行行地把结果写到存储单元当中。这样做的话,访存的功耗会急剧增加,并且会发生计算单元等待输入数据的情况,从而降低了计算单元的利用效率。相比于卷积为主的神经网络模型,以矩阵乘为主的Transformer类的计算,它的访存和计算比例更大,这个问题会更加严重。
这张图就是我们存算一体电路的架构框图。浅色的部分是标准的SRAM电路,深色的部分是我们在它旁边加入了一些定制化的电路结构,包括Activation Driver、乘法器、加法树和累加器等等。这些定制化的电路结构和传统的SRAM电路整合在一起,就可以实现高效的存内并行计算。存储单元内部的数据可以在同一时刻一起读出,这相比于一行一行的读取方式,极大地提高了并行性。
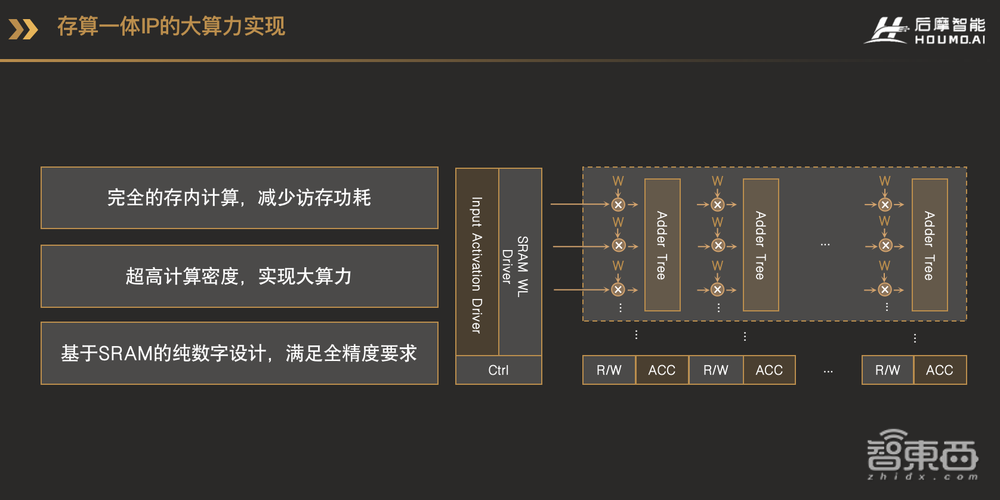
计算电路紧挨着存储单元,数据被读取出来之后,马上就可以在原地参与乘加计算,数据在存储单元和计算单元之间的传输开销也就相应地减少了。
计算单元方面,我们的定制化电路和存储单元的Bit Cell(存储单元)电路完全融合在一起,带来了更规整的电路结构,因而有更紧凑的电路设计,电路面积也就相应减少了。这里面的定制化电路,不管是存储电路,还是乘法、加法、累加等等,都是纯数字的设计,不会有任何计算的误差。
因为我们面向的市场是自动驾驶,所以自然少不了车规方面的考虑,除了标准SRAM模式下的Memory BIST,我们还设计了用于计算模式的CIM BIST机制,CIM是Computing In Memory的首字母简称。我们还通过冗余设计,以及加入行和列修复电路,提高量产良率和可靠性。有了错误检测机制和冗余设计,还可以在电路空闲时,通过软件的方式检测并修复电路中可能出现的错误。我们还改变了传统SRAM中Bit Cell的电路,消除了6T Bit Cell里的竞争现象,进一步提高了可靠性和稳定性。
这就是我们已经发布的后摩鸿途™H30芯片里所采用的存算一体电路的一些规格参数,采用的是12nm工艺,单个AI核内的存储容量已经到了MB级别,在INT8全精度条件下能效比是30到150TOPS/W,30到150TOPS/W有一个范围,是因为跟输入数据相关的pattern 。面效比大于4TOPS每平方毫米,这是传统电路的3倍以上。我们还支持软硬件修复功能。
目前我们已经在12nm、16nm、22nm、28nm工艺下进行过流片测试,7nm的测试样片也已经流片,明年会推出量产产品。
三、自研IPU架构,探寻集中式与分布式计算的“中庸之道”
有了这么好的存算IP核,怎么把它充分利用好,就是考验AI处理器架构和芯片设计能力的问题了。
为此,后摩智能基于存算一体,专为万物智能而设计了IPU(Intelligence Processing Unit),并规划了三代IPU架构:第一代命名为天枢架构,专门为智能驾驶打造的;第二代天璇架构,可以覆盖更多的场景,从成本、面积、功耗都非常敏感的终端场景,到自动驾驶,再到大模型等云端场景都可以覆盖;第三代天玑架构的IPU,为通用人工智能打造的IPU。
下面我将带大家了解一下我们的IPU架构设计。
首先是我们怎么思考AI处理器这件事的。在早期的时候,AI芯片通过堆积大量的计算资源,以提高并行性,从而提高性能。其典型的代表是左图中特斯拉的FSD,采用集中式的存储和计算架构,可以达到很好的性能提升。但是对于算力要求更大,灵活性要求更高的场景,如果只靠单纯的堆砌更多的计算资源,到了一定程度后,由于物理实现的限制,或者输入输出数据的规模等方面的限制,计算资源的利用效率会急剧降低,因为单个任务计算并行性已经无法匹配计算资源的并行性了。
我把集中式计算和存储架构类似为建筑设计里面的中式庭院,向内围合形成一个小院子,各种功能集于一身,使得人与人、人与自然可以高效地沟通,但问题是院落面积终究是有限的,能容纳的居住者数量也就有限,而且设计建造这样的庭院开销和难度很大,因此可扩展性差。
这时候一个自然的想法就是利用多核,或者硬件多线程的方式,如右中间的这个Tenstorrent Wormhole所示,这张图和特斯拉的FST都出于一个人之手,这个人叫Jim Keller。他把算力很大的核拆成若干个小核。这样做到极致,就是用众多的CPU小核,在旁边配上小块的SRAM,组成一个二维阵列,业界也有人称这种架构为“近存计算”。
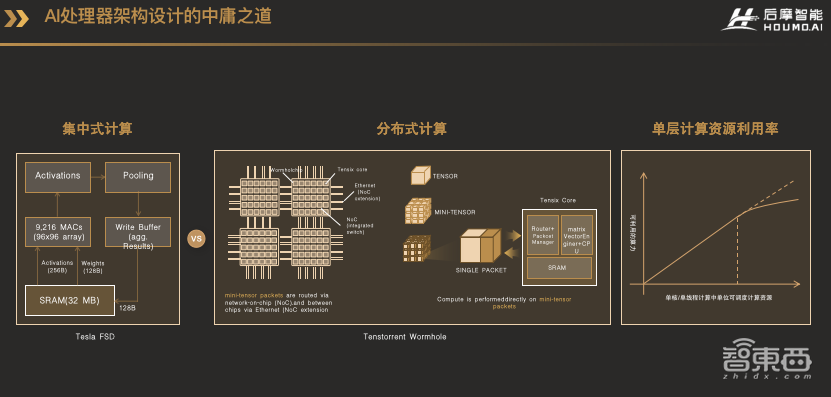
这样做的好处是对物理实现非常友好,并且提供了非常灵活的编程性。但一个问题就是对于终端推理,尤其是自动驾驶这样相对特定的应用场景,能效比和面效比比大核的形式差一些。这种分布式的计算和存储结构,可以类比为建筑设计里面西方的高层公寓,采用独立简单的小单元,在三维空间上可以很好的扩展,能够容纳更多的人,但因为单元相对封闭,人和人之间的沟通就会比较差了。
所以我们认为在单核或单线程可以调度的计算资源,与真实的可以利用的计算资源之间,存在一条Roofline的曲线关系。我们的设计逻辑就是找到这条Roofline曲线的拐点,当遇到拐点的时候,再通过多核或者多线程的方式来扩展算力。这样的设计理念类似于融合了东西方建筑的特点,先设计一个简单优美的庭院,再保障了计算资源利用效率的同时,再通过高层公寓的方式,在三维空间上灵活扩展算力。
这张图就是我们已经推出的H30芯片里天枢架构IPU的架构框图。大家可以看到我们的芯片里有4个IPU核,都挂在系统总线NoC上,每个核是完全一样的设计。每个核又由4个Tile组成,每个Tile就对应了一个硬件线程。在Tile内部,包括了一个CPU、Tensor Engine、Special Function Unit、Vector Processor和多通道DMA。其中Tensor Engine就是由我们的存算电路和一个Feature Buffer,还有相应的控制电路组成。这些计算单元全部在CPU的调度之下进行运行,CPU除了可以调度不同的计算单元之外,还可以进行一些简单的灵活的,但是算力要求不高的计算。
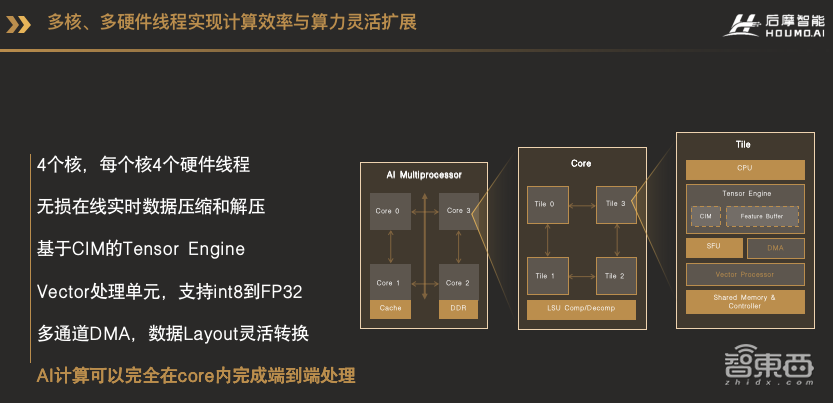
这样的架构使得AI计算不但不用在多个处理器,例如CPU、GPU、DSP之间分配任务,甚至数据不用出AI核,就可以完成端到端的AI计算。
从Memory Hierarchy的结构来看,整个系统包括了4级缓存,最外的缓存是片外的DDR,片内的第一级缓存我们叫L2缓存,是所有的CPU芯片都可以共享的缓存。L1的缓存就是Core内部一个共享存储资源,Core内部所有的计算资源都可以共享这个Shared Memory。L0的缓存就是CIM,也就是存算单元。这四级的缓存都是可以被软件分配和管理,这样的设计使得软件有更大的空间对不同类型的任务进行存储空间的分配,从而减少数据搬运,并且更好地利用数据复用性。
说过了存和算,这个架构里还有一个重要的部分就是数据的传输。就像我们人和人之间需要更好的沟通一样,计算单元之间,也需要非常灵活的共享数据和消息。因此,我们设计了专用的数据传输总线,有了这个传输数据总线,就可以灵活的在各个Tile,以及各个Core之间建立高速的直接的数据传输通道,而不需要通过系统的总线和缓存了。通过自定义的总线,各Tile和各Core之间,可以非常灵活地组成不同的拓扑结构。我们的天枢架构IPU采用双环的拓扑结构,四个Tile组成第一级的环,四个核又组成第二级的环。
AI计算里数据复用是一个很重要的特性,利用数据的复用性可以减少片外带宽的压力。因此我们设计了多播的传输机制,也就是说一个Tile里的数据,可以通过一次DMA传输,广播给需要这个Tile数据的所有的其他的Tile,而不需要多次重复地从同一个地址去读取同样的数据。
多核加多播的传输机制,带来的一个问题就是数据和消息的同步问题。例如Tile 0把数据传给Tile1、2、3,然后四个Tile一起开始一次计算,这类的数据同步问题其实是多线程编程里面经常会遇到的问题。我们通过专用的消息传递通道和同步机制,可以让四个Tile乃至四个核(Core)在收到消息的同一时间一起开始工作。
大家看到,因为我们第一代IPU和H30芯片所用的核数和Tile的数量都比较少,14个,它形成了环形拓扑结构。但如果我们根据算力的需要,把这个核的力度切得更小,或者当算力需要更多的核的时候怎么办呢?在这里提前预告一下我们下一代的天璇架构的IPU设计:基于Mesh互联的AI Cluster,它可以将计算单元灵活的配置成M行N列,根据场景需求,AI算力规模可大可小。
除了互联拓扑外,存算电路CIM核的改进,我们自研的CPU和向量处理器的性能提升,针对AI算法更高效,尤其是大模型的计算,更加高效的SFU和数据传输机制,最终体现在更好的整体性能和灵活性。大家可以想象一下,如果这个二维阵列在二维空间甚至三维空间上继续扩展下去,那么我们的芯片可以做些什么?总之,敬请期待。
四、提供2倍以上的真实算力,功耗可以降低50%
当然,H30 这样一个大芯片,再加上纯自研的存算一体电路,很多工程实现方面的挑战需要解决,其中最关键的就是存算一体电路的特有验证问题、仿真加速及FPGA原型问题以及电源完整性问题。为了实现大算力存算一体电路的仿真验证,我们打造了一个存算电路的行为模型,使其与真实的电路的行为完全一致,也就是做Formal 验证。
这么大算力大规模的电路,加速仿真验证也是一大考验。我们单核的 IPU 规模就已经超过能找到的任何一款 FPGA 规模,所以我们团队巧妙地将设计裁剪、分割 Partition 到多块 FPGA。
至于电源完整性的问题,大算力AI芯片需要考虑动态IR drop对性能的影响,特别是对于定制化存算电路,计算密度巨大,需处理IR drop问题及其对周边电路的影响。我们采取多种方法降低峰值电流影响,因为存算电路与标准电路不同,无法按标准电路要求进行Sign-off。
这是我们H30芯片的架构框图和芯片规格。主要的规格参数包括256TOPS INT8精度的物理算力,DDR带宽128GB/s,16路FHD的编解码,8x PCIe4.0接口。典型功耗35W,采用12nm工艺。

我们通过底层的存算电路和AI处理器架构的创新,带来性能指标上的突破。这是我们12nm芯片和某国际巨头7nm芯片的性能和功耗对比,在同样功耗下,我们的H30芯片可以提供2倍以上的真实算力,端到端的AI计算能力;在同样的性能条件下,我们的功耗可以降低50%。
上面讲完了硬件架构设计,相当于我们的芯片有了一个强健的身体,下面介绍一下我们芯片的灵魂:编译器和工具链。
我们的芯片采用HDPL语言编程,即Houmo Data Parallel Language的缩写,它是我们对主流并行编程模型的扩展,能高效的解决数据并行问题,并且支持消息传递机制。我们的Tile内部是由异构的计算单元组成的,采用SIMD的编程模型,而Tile间以及IPU核间是同构的,采用SIMT的编程模型。
我们出色的软件工具链工程师已经把刚才讲到的Tile间和核间数据共享和消息传输的复杂机制都封装了起来,用户可以很容易地用我们的模型开发SDK,或者算子开发SDK,在我们的IPU上进行软件和算法的开发。其中模型开发SDK允许用户使用我们的算子库进行模型和算法的开发。算子开发SDK则允许用户开发自己的定制化算子。
编译优化方面,除了常用的不同计算单元之间可以以流水的方式并行以外,我们的每个Tile,以及每个Core之间,也可以独立并行执行不同的任务,也可以将一个任务切分到不同的Tile,或者不同的核上,并且以Pipeline的形式并行。例如对CV类的处理,在追求Throughput,也就是高吞吐率的场景下,可以让一张输入图片,同时进行多个网络的计算,也可以让多张图片在多个Title或者多个核上,同时进行同一个网络的计算。在追求低延时的场景下,可以将一张大图拆成若干份,同时利用多个Tile,或者多个Core的算力进行计算。
在2D Mesh的拓扑结构下,任务的流水线是在2维空间,甚至未来会在3维空间上进行流水,这也就是类似Spatial Computing(空间计算)的概念。
H30芯片在一些现在最先进网络已经有视频效果呈现,包括激光雷达的一个处理网络、BEV的网络。
我们的第一代量产产品后摩鸿途™H30现在已经可以提供给客户送测了;第二代产品预计2024年可以提供给客户。以上就是我分享的全部内容,谢谢大家!
以上是陈亮演讲内容的完整整理。
