








芯东西(公众号:aichip001)
编辑 | GACS
9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在次日高效能AI芯片芯片专场上,迈特芯创始人兼首席执行官黄瀚韬,分享了主题为《面向大模型的高能效并行存算大算力芯片》的主题演讲。
在算法方面,黄瀚韬认为,通过用更低的bit来表示GPT-3的主要数据,可以将大模型参数规模变小,从而实现在较低功耗的边缘和端侧运行。迈特芯可在ChatGLM2-6B大模型上用INT4和INT2算力,达到跟ChatGLM2-6B FP16相当的推理水平。
在架构方面,迈特芯从算法角度来探索硬件设计,针对大模型算法搭建立方单元架构,通过立方脉动阵列实现高强度并行计算,其解决方案能兼顾高通量和低功耗。
以下为黄瀚韬的演讲实录:
各位领导,各位嘉宾,很荣幸站在这里跟大家介绍我们公司新做的面向大模型的高能效存算算力芯片。我是迈特芯的创始人兼CEO。
一、算力需求迅速增长,需要高算力硬件支持
首先是从AI算力超摩尔进程的背景开始思考。基于AI、ChatGPT的大模型的用户数量增长是显著的,算法是基于大模型算法,参数是每两年增加240倍,算力也是增加了750倍。因为复杂的计算和参数量,导致它算力的需求是非常大的。每两年750倍算力需求的增长,其实是远超原本摩尔定律的增长,在大算力市场上是有一个非常大的算力需求。
从另一个角度看到,现在国内没有办法买到英伟达的A100。从全球市场来看,全球市场云服务商像CoreWeave,这是英伟达投资的云服务商,也是没有办法获得足够的GPU提供云服务。所以,算力市场还是很值得大家去探索的。
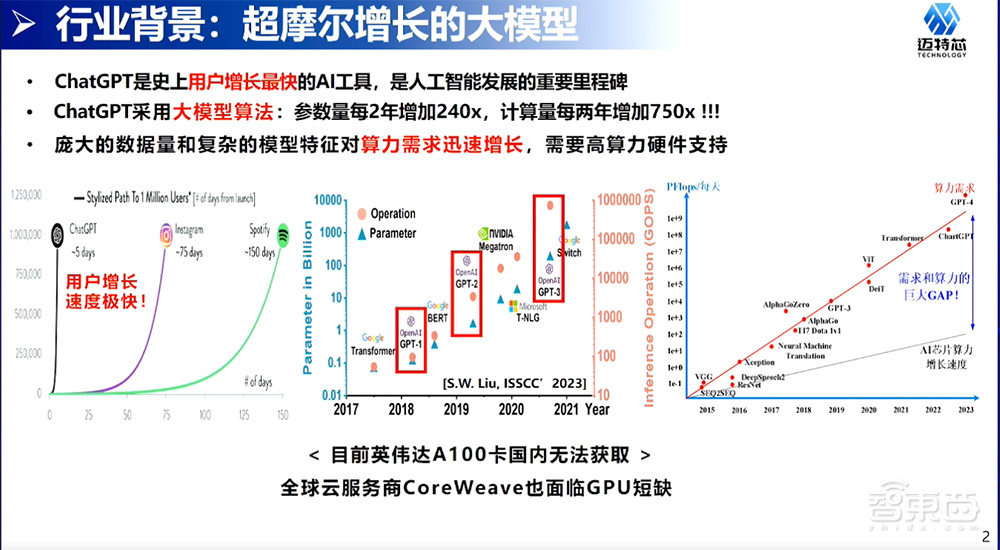
另外一个角度,现有的方案比如基于GPU的方案,它是一个高碳的硬件算力方案。以A100为例,它的功耗达到了400W的水平,这样的功耗对建立一个AI数据中心是很有挑战的。比如说,我们想建一个千张GPU卡的数据中心面临一个问题,要给它提供1兆瓦功率的供电,意味着每天的运营成本是很显著的。
另一个例子,以Meta Llama模型来做训练为例,训练一个Llama模型是需要2000多张A100的卡,同时也要调参做训练搞5个月。在这个过程中已经消耗2600MWh电量,换算成碳,已经花了1000吨的碳。迈特芯的初衷是希望做一个低功耗的芯片,把功耗降下来,把碳降下来,让社会更加环保、低功耗、可持续。
从另一个角度以现有GPU Google来看。在2016年谷歌提出TPU,TPU工作主要是用来做CNN、做推荐系统。随着2016年、2019、2020年、2022年TPU的V3、V4这几代迭代,我们看到了基于Transformer的算子不只有大模型,Transformer架构计算的比例是逐步增加的。
到2022年为止,已经有57%TPU算力都是用在Transformer的模型。大模型应用Transformer逐渐成为数据中心的核心计算。如果做一个专用的模型AI加速器,在做好Transformer的基础上,再把CNN做好,那是一个非常值得的放在数据中心主要的计算硬件。
二、大模型参数来源与应对量化技术挑战的两大方向
既然聊到大模型,我们就追根溯源,从大模型的第一步开始,就是这篇论文谷歌的Attention Is All You Need。这篇论文提出来的时候还没有什么大模型,主要是解决了当时翻译不准的问题,所以它这里提出了一个Encoder架构和一个Decoder架构。
Encoder架构是做语义理解,现在的Bert模型也是用Encoder架构做语义理解。Decoder模型是做文本生成,逐渐扩展到回答各种各样的问题。在Decoder方案上,OpenAI进行了扩展,提出了GPT-1、GPT-2、GPT-3,逐渐到现在看到的GPT-3的1750亿参数的规模。仔细看GPT-3模型,其实它还是在Transformer Decoder框架里进行扩展的,无非是深度更深一些,模型更宽一些、更大一些。
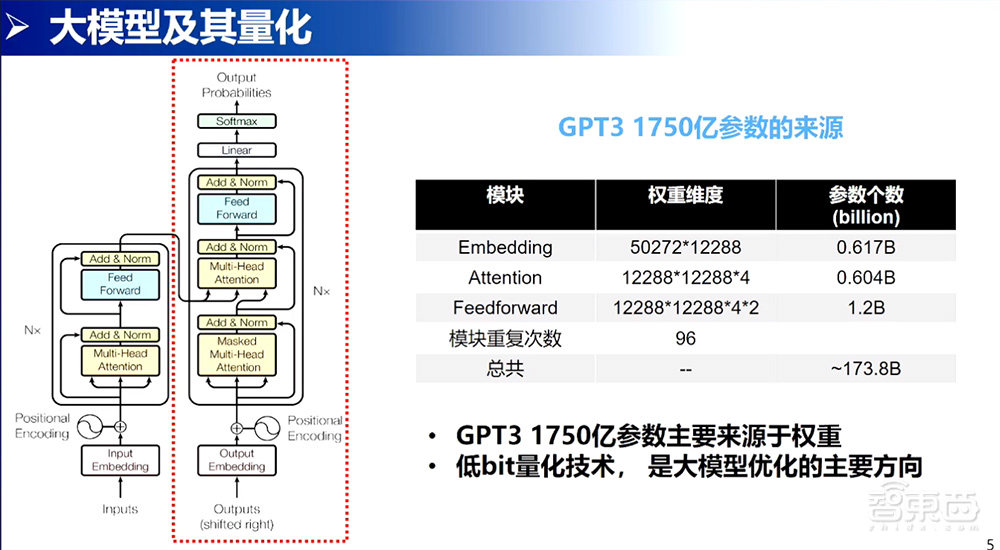
接下来看一下1750亿参数的来源。首先就是Embedding的操作,Embedding操作就是一个lookup table的过程,找矩阵lookup的过程。这个事情很简单,没有太多的计算。Attention的部分也没有什么变化,有4个全连接的层,每一层都有12288的维度,它就是一个很大维度的矩阵层,它有4个。Feed Forward又是一个矩阵层,是一个12288×4×12288的很大矩阵层,Feed Forward连接层是有2层。这个模块是重复了96次,一叠加就得到了一个接近1750亿参数的大模型。
我们看到1750亿参数大模型主要的数据都是权重,而且权重已经是获得的,在我们做推理的时候。如果能把权重用更低的bit来表示,我们就能获得一个比较好的、比较高效的存储,实现我们大模型在端侧、在边缘进行计算的方案。
说到量化,上面先给大家举了一个例子,量化的技术就是把本来的浮点映射到需要的定点的个数。这里的定点是4bit,假设它是0~15,就可以把这样的浮点直接映射到0~15的数字范围内。
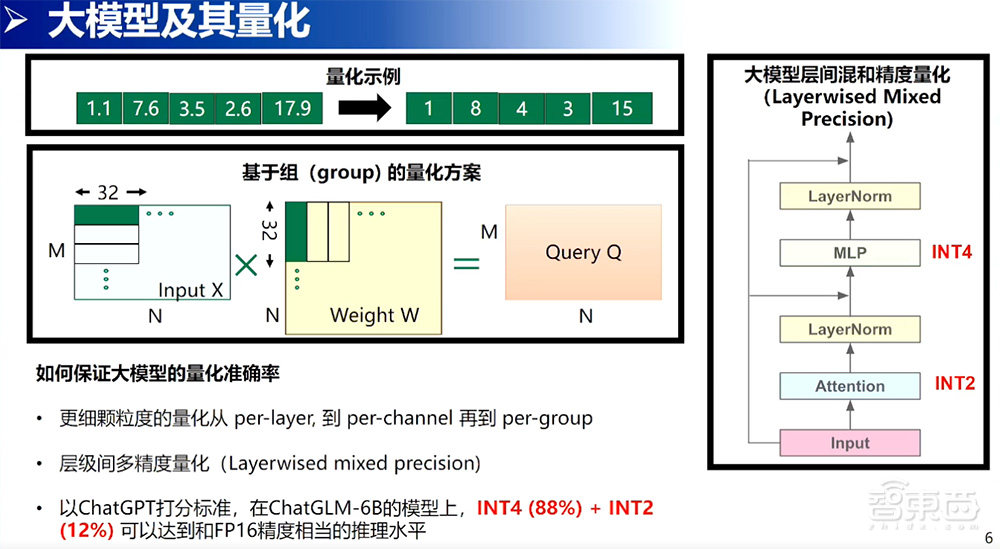
做量化技术最大的挑战,就是如何在保证大模型准确率的前提下尽量量化。因为这样的问题提出了两个方向:第一个方向,用更细颗粒度的量化技术。在AI部署的过程中看到在量化技术上,从每一层per-layer的量化技术整个权重是一个min max,是一个scale parameter量化的参数,变成是以per-channel矩阵每一列是一个量化参数。直到现在,变成的是基于组的量化参数,颗粒度更小,因为量化带来的误差就会更小。
第二个技术方向,看的是层间多精度量化。可以看到右边的图,这个图的表达意思是说在大模型,一个96层多层间的模型结构之间,不是每一个层都是同样重要的。在不同的层之间,还是可以做一些取舍的。这里举例,有些层可以用2bit做,有些层可以用4bit做,有些层如果为了保持精度的极限一点也不丢失是可以用8bit来做的。在不同层间,做了一个精度混合,通过这种方式来保证精度没有丢失。
我们公司做了一个实验验证,在ChatGLM2-6B清华开源的大模型上,用88%的INT4和12%的INT12,可以达到跟ChatGLM2-6B FP16相当的一个推理水平。这个推理水平也不是我说得,是用ChatGPT打分打到的。
三、创新立方脉动架构,以此开发X-Edge三款芯片
聊过了算法方向的东西,再回来看架构。硬件的设计是为算法服务的,所以总是要从算法角度来探索怎样设计这样的硬件,会为算法提供更准确、更快速的服务。在这个角度上,首先借鉴了行业的老大GPU。GPU的架构,就是以标量单元、矢量单元、立方单元三种单元构成的一个既有灵活性又有高吞吐量的计算方案。
从我们的角度来说,针对大模型、大算力,标量单元、矢量单元可以不要,专心把立方单元做好。立方单元就是一个面的矩阵和另一个面矩阵进行快速的乘加。
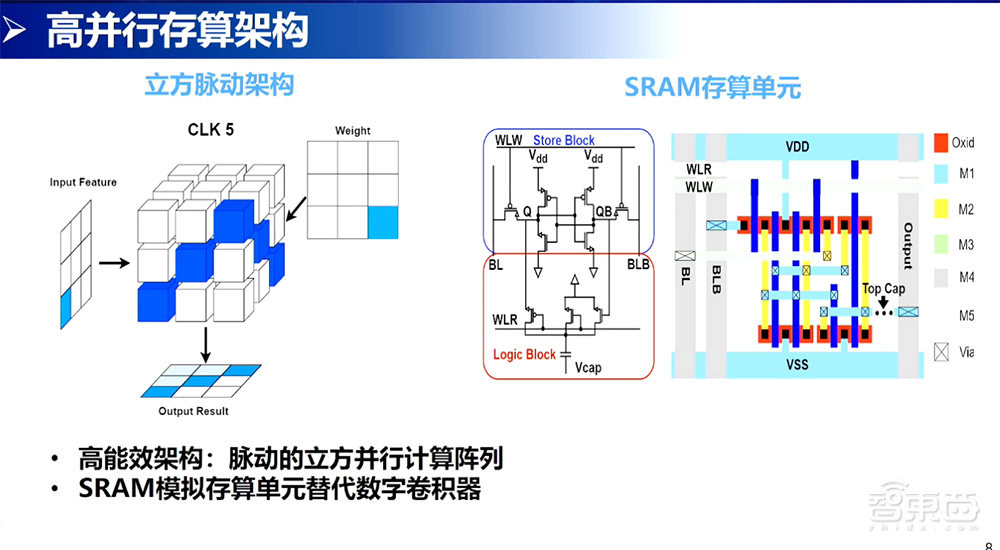
在立方并行计算层面,首先是推出自己立方脉动架构。这个立方脉动架构是以3×3矩阵层为例,当3×3如果排列的序列够多的时候就可以看到是两个面和两个面进行乘法,构成了一个高能效的架构,立方脉动架构。
右边是我们自己设计的存算单元,由9个transistor(晶体管)+1个capacitor(电容器)构成的。我们的思路是先实现一个立方脉动基于传统数字的架构,再通过一个存算的SRAM计算单元进行替代,实现一个既有高通量又有低功耗的解决方案。
在此基础上迈特芯开发了三款芯片,分别是X-Edge多精度芯片、多稀疏芯片、存算芯片。今天专注的是在存算芯片,不过前两个我也会稍微介绍一下。
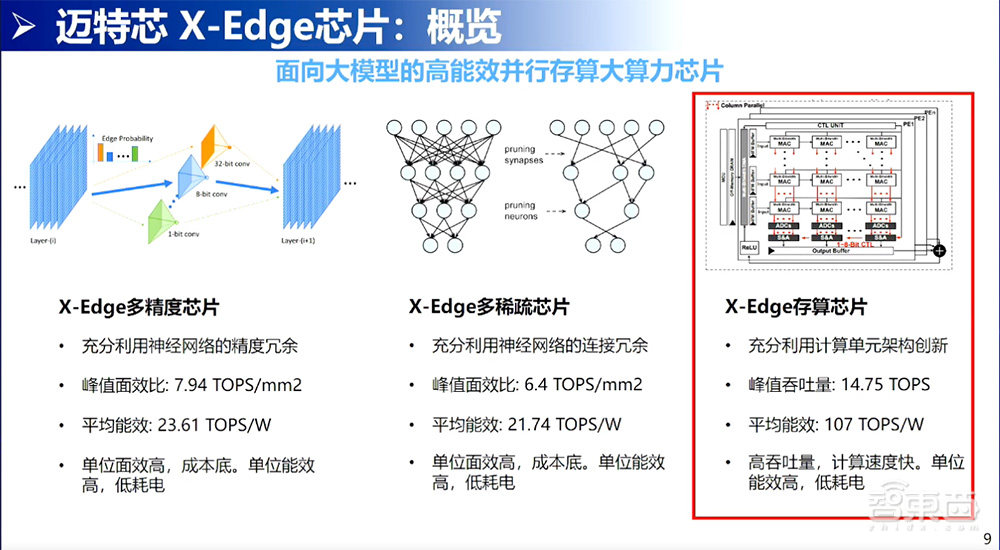
多精度芯片就是探索在模型之间可以有不同的精度,比如有1bit精度、2bit精度、4bit精度、8bit精度。不同的精度,可以探索不同层间分配不同的精度。在分配不同精度的同时通过神经网络搜索的算法、后续的量化算法,实现精度没有丢失。搭配我们硬件的支持,可以做到比较好的接近8TOPS/平方毫米的面效比,也是可以做到24TOPS/W能效比。
第二个角度,做的事情就是稀疏。稀疏的角度看到的权重就像人的大脑一样,不是每个神经元都同等重要,有些神经元从未被激活过,所以对神经网络来说,有些神经元也是可以通过算法把它稀疏掉。在这个角度上,充分利用神经网络连接的冗余度,实现更高的峰值面效比。对于存算来说,就是充分利用计算单元架构创新提高它的能效。在这个能效上,我们达到了100TOPS/W的效果。
这一页是我们整体架构。从架构来说,在实践层面上没有过多的创新。我们的核心创新点就是立方脉动阵列方向,就是中间这块有一个立方脉动阵列,能快速做好矩阵乘法。与此同时,我们也有做矩阵Transformation的操作,比如进行转制、变换、拼接、短连接的工作。对于这些非线性的操作,像LayerNorm、Softmax、Gelu,是使用FP16精度高一些的方式实现的。其中灵活存储管理的方向是通过片上的储存,尽量提高数值的复用,降低对带宽的需求。这是整体的架构设计。
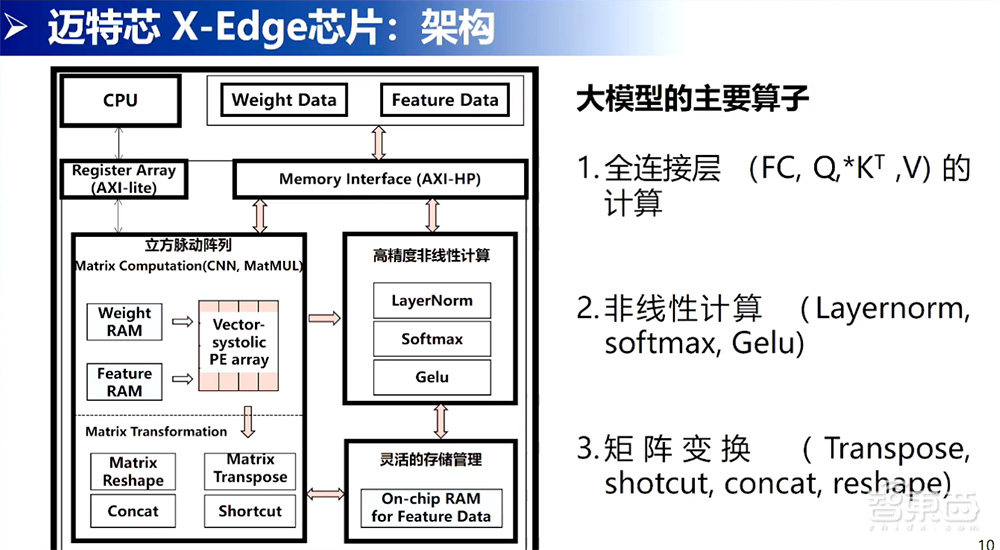
这一页是我们现在存算芯片的指标。目前这一版芯片能达到15TOPS峰值结果,平均的准确率是69.9%。下面是有跟英伟达A100表格进行对比,它的准确率是70.43%,我们是69%,准确率的差别在大部分应用场景上是可以接受的,这也是可以通过进行多层间量化技术进行弥补,实现精度是没有丢失的。
其它的,我们的峰值面效可以达到900TOPS/W。在这个神经网络上的平均能效是107.58TOPS/W。我们也进行了台积电28纳米SRAM的流片。右上角是我们版图和芯片图。
四、大算力芯片在大模型、3D重建、X+端边缘平台三方面应用
聊到大模型,就聊到了应用。从应用角度看,我们认为做大模型的应用,最后要做到100~1000TOPS。因为我们还是一个初创公司,走在这个路上还正在努力走下去。在这个方向上,现在做到努力支持的就是支持清华ChatGLM2-6B的模型。
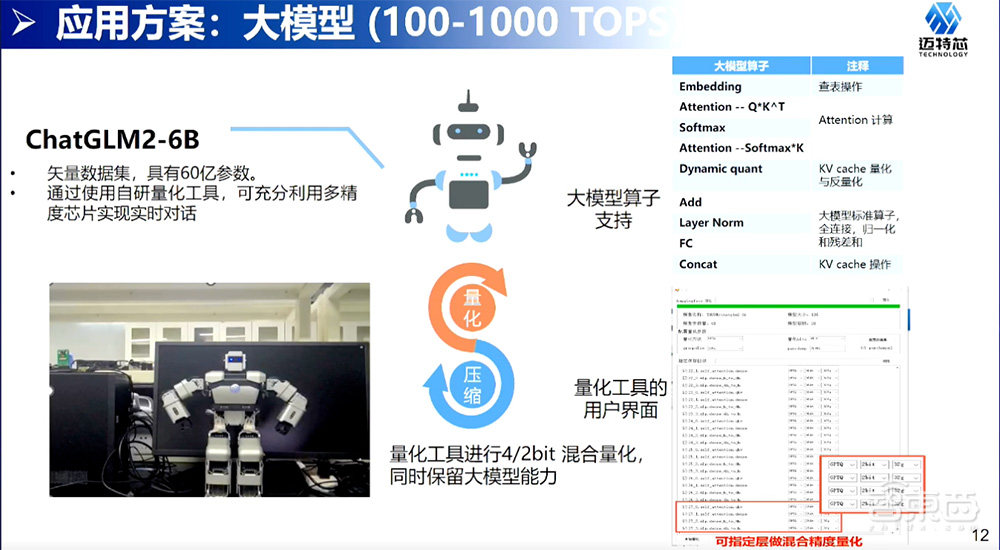
这个模型里面有自己的矢量数据集支持。矢量数据集这点,就是用来支持不同专业领域的知识可以保存在移动端的设备上,通过这个支持来提供一些专有化能力的回答。第二,通过使用自研的量化工具,可以极大地降低ChatGLM2-6B模型大小,使它可以在芯片上跑得起来。还有对大模型算子的支持,大模型这些主流的算子我们也有支持,也有对像动态量化或者不定长纬度的支持。下面是我们一个简单的量化工具。
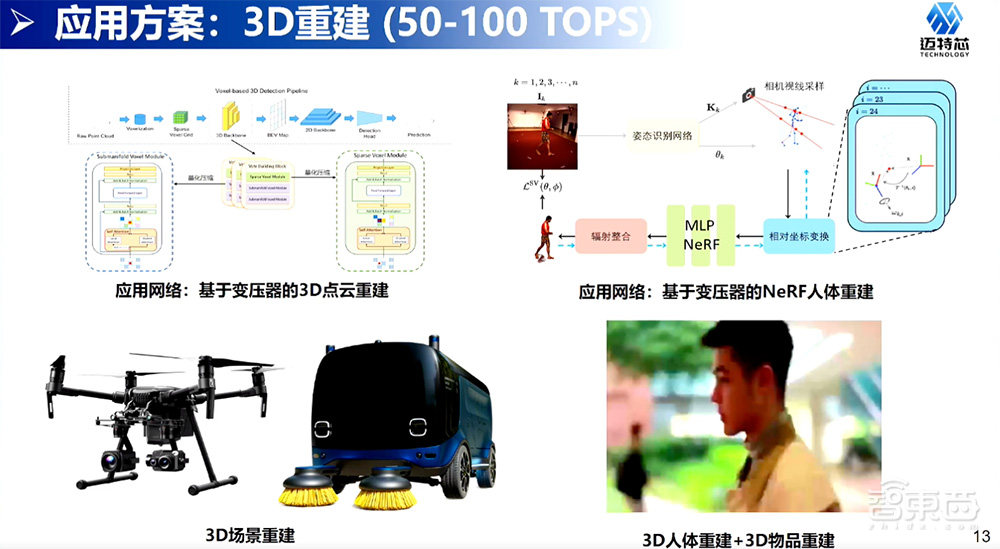
另一个角度来说,我们正在主打50~100TOPS的方向。作为一个存算一体,直接走向大算力、走向100~1000TOPS的跨度太大了,应该先从一个50TOPS中等算力的规格开始做起,从这个算力做起主要针对的是两种情况。
一种情况是无人机的情况,就是对CNN、基于Transformer ViT模型的支持,这样的模型可以让我们实现3D点云的重建,尤其是在端侧3D点云的重建,还有在端侧人物识别、人物检测、目标检测等视觉的应用,这些应用的主要亮点是可以在同等算力情况下用的功耗会更小。当芯片验证做得更充分一些,也会向比较简单的小车级,就是功能性小车级层面进行开拓市场,进行降成本替代的工作。
最后是X+端边缘平台的应用。在这个方向上提供更多的算力,希望能提供20~50TOPS算力,主要应用在端边缘算力卡,还有一些机器人平台、监控摄像头平台、地铁巡检平台等等在端边缘对算力是有一定需求的,但是现有端边缘的算力支持,比如1~5T的算力支持还不足够,希望我们的芯片是可以支持的,会主打这个方向的端平台的应用。

在X+端边缘平台上跟刚刚分享的一样,这是一个非常琐碎的市场,所以要建设好这个市场,需要有一个集中式的工具链,才能做好这个服务。我们有做好编译器上面的优化,将不同层面的网络进行编译,也做好量化模型优化的工具,比如神经网络搜索、量化、裁减工具,也有做好对这些平台的基础适配,这样的话可以跟厂家把端边缘的场景用好。谢谢各位的聆听。
以上是黄瀚韬演讲内容的完整整理。
