








芯东西(公众号:aichip001)
编辑 | GACS
9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在首日开幕式上,亿铸科技创始人、董事长兼CEO熊大鹏分享了题为《存算一体超异构AI大算力芯片破局大模型时代“芯”挑战》的主题演讲。
熊大鹏提出,大模型时代下的“芯”挑战,比起算力如何增长,更大的问题在于数据搬运能力的剪刀差越来越大。数据显示,计算能力与数据搬运之间的鸿沟,大概以每年50%的速率扩大。大模型出现后,数据访存在整个计算周期里的占比,达到了95%以上甚至更高。
亿铸科技认为,随着AI应用进入到2.0时代,要解决AI计算芯片面临的诸多挑战,关键在于回归阿姆达尔定律并成功破除“存储墙”。据悉,亿铸科技原型技术验证(POC)芯片已回片,并成功点亮。该POC是首颗基于ReRAM的面向数据中心、云计算、自动驾驶等场景的存算一体矩阵POC,能效比超过预期表现,进一步验证了公司的技术实力和市场潜力。
以下为熊大鹏的演讲实录:
大家好!我去年也参加了AI芯片峰会,但今年情况不一样,因为今年大模型的火爆给人工智能芯片等各方面都带来了巨大的变化。下面我将介绍亿铸科技存算一体超异构AI大算力芯片怎么去应对大模型时代的“芯”挑战。
一、数据搬运,大模型时代的“芯”挑战
大模型的参数规模,像GPT-3目前是1750亿,未来可能将会迎来几倍、几十倍、上百倍的增长。这样的增长带来的好处是,大模型的容量、智能等各方面将会超过人的大脑。
但与此同时,大模型时代也对我们提出了很多挑战跟需求。第一,算力如何提升。目前来说,人们针对大模型的芯片制造工艺或是其他各方面投入基本都已经到了极限。第二,大模型对计算能耗的需求非常大。AMD CEO苏姿丰说过,如果没有新的技术出现,按照目前的计算效率,12年以后,也就是2035年,每一台Zetta级别的超级计算机所需要的能耗将会相当于半个核电站。
从算力的角度来说,支撑底层算力的摩尔定律现在几近终结。但是我们的模型越来越大,算法越来越复杂,对算力的要求也越来越高,这将是一个很大的挑战。AI芯片,或者说大算力AI芯片,将来的路该怎么走?
除了算力以外还有一个更大的问题——数据搬运能力的剪刀差越来越大。
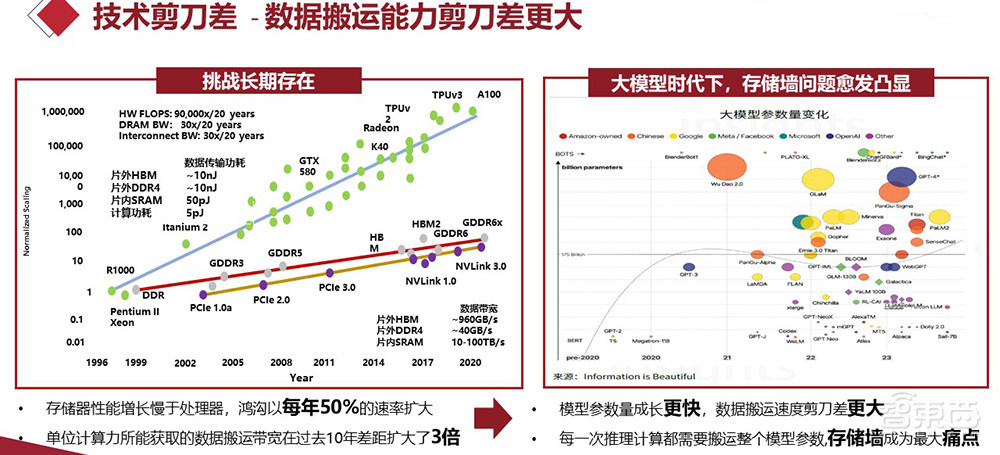
基于摩尔定律,算力每年大概以60%-70%的速率提升。但是对于数据搬运,无论是从外部的存储器搬运到芯片内部,还是芯片内部的数据总线,其物理线速度的提升基本是每年10%以内。这就导致计算能力与数据搬运之间的鸿沟,大概以每年50%的速率扩大。
在过去十年,单位计算力所需要和所能获取的数据搬运带宽,差距扩大了3倍。对大模型来说,其实问题的根源就在于,怎么把数据不被堵塞地从外部搬到内部。
下图这个模型,我已经在很多地方讲过。这里的F值,指的是数据访存在整个计算周期里的占比。
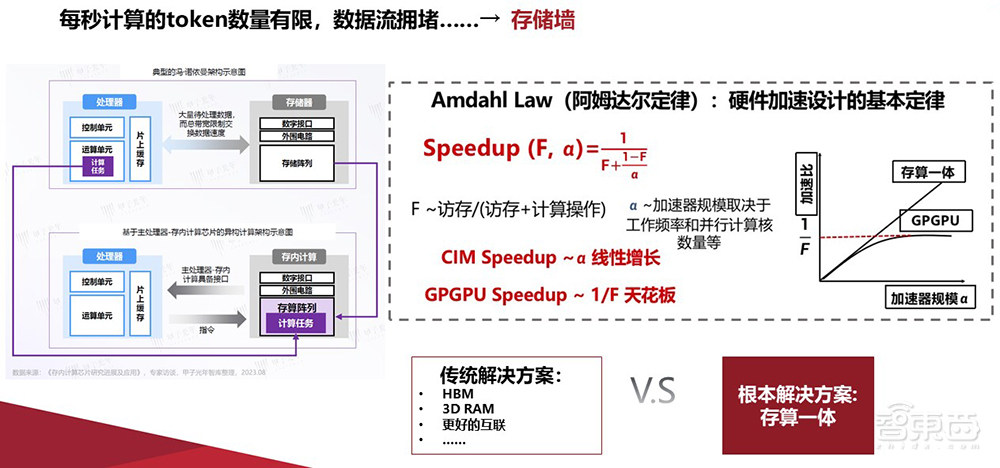
在过去存算分离的冯·诺伊曼架构下,做AI芯片或是跟AI芯片相关的应用时,F值就已经达到80%-90%。这意味着大量的能耗是卡在数据搬运访存上的,造成了性能瓶颈。在大模型的时代背景下,F值更是能达到95%。
这意味着如果数据搬运的速度不提升,即使我们将来用更好的工艺去获取更高的算力,对实际性能提升的百分比其实非常有限,可能只有10%-20%。这也是为什么到今天,更多的公司开始把注意力集中在解决数据搬运的问题上,比方说大量地采用HBM、 3D RAM封装技术等等。这些解决方案会带来更好的片间互连、板间互连,能够比较有效地去解决数据搬运问题,从而非常有效地提升实际性能。
二、数据搬运的根本解决方案在于存算一体
这些传统的解决方案的确有效。我们看F值就知道,如果把数据搬运效率提升1倍,不需要用5纳米、3纳米、1纳米工艺,实际计算性能也能提升1倍。
但是要真正解决这个问题,我们认为根本的解决方案是存算一体。存算一体相当于在存储单元的基础上,把计算的部分加上去,模型的参数搬运环节基本上就免掉了。
比方说1750亿参数的GPT-3模型,每一次推理计算的时候都要把350Gbyte的数据搬到芯片上,才能做一次推理、算一次Token。如果是训练,这个数据量会更大。但如果这个数据不需要搬运,就意味着数据搬运的瓶颈根本不存在,计算的效率会高很多。
存算一体的技术现在也慢慢被大厂所接受,比如AMD已经宣布他们将会以存算一体作为核心,结合异构的方式,实现既兼顾通用性,又能够有非常强的计算能力的芯片。
还例如特斯拉,最近宣布其基于近存储计算的超级计算机Dojo1已经准备好了,业界对此评价非常高。摩根士丹利说,光是芯片就有可能给特斯拉带来5000亿美元市值的增量。
三星也宣布将基于DRAM做存算一体,他们认为在不久的将来,存储器在AI服务器中的重要性将超过英伟达GPU的重要性。三星预计到2028年发布以存储器为中心的超级计算机。言下之意就是要做基于存算一体的超级计算机。
亿铸科技近期成功点亮大模型时代存算一体AI大算力原型技术验证芯片(POC)。该POC芯片基于成熟工艺制程,在100W以内,单卡算力可以突破P级,也就是1000T。另外,该POC芯片的能效比已经远超英伟达5纳米工艺制程的H100系列4T/W左右的能效比。
面对ChatGPT等大模型带来的AI算力挑战,亿铸科技在年初提出“存算一体超异构”,以存算一体(CIM)AI加速计算单元为核心,以统一ISA指令集和架构将不同的计算单元进行异构集成和系统优化,既能实现更大的AI算力以及更高的能效比,还可以提供更好的可编程性和更为通用的应用生态。

通过前面讲到的CMOS工艺、新型存储器、存算一体的架构、Chiplet、先进封装,我们能够将芯片有效算力做到更大,参数能放置更多,支持更大规模的模型,能效比更高,软件的兼容性和可编程性更好。另外很关键的一点,就是芯片的发展空间非常大。目前该POC芯片采用了传统工艺制程,未来,不管是容量还是性能,比较保守地说,至少拥有几倍或者十倍以上的成长空间,这是可以预期的。

三、AI应用进入2.0时代,存算一体成为AI大模型算力发展“灵丹妙药”
在强AI的大模型时代,一定范围内,大模型会替代传统的小模型。由于大模型突出的泛化性,将会低成本地催生新的AI应用场景,并且在各个垂直领域能够快速地落地和推广。另外,我们认为大模型将来有可能会以IAAS(Intelligence As A Service,智能即服务)的产品形式赋能各个行业。
此外,极高的AI研发投入带来的副作用,是“通用智能寡头”的格局。但出于大模型的泛化性,在具体的垂直行业、垂直领域反而有利于通用人工智能落地。将来在各个领域,我们认为会出现“百花齐放”的格局。
总的来说,AI应用已经进入到了新的2.0时代。目前最突出的问题,就是大模型导致的巨量数据搬运问题,这个问题的根源来自于存储墙。
现在性能最好的H100芯片,如果用在参数总量为350Gbyte的GPT-3模型上做推理计算,数据搬运每秒只能搬6次左右。这就意味着用H100,1秒大概只能算6个或10个Token。
但从计算能力上来说,这样的数据搬运其实只占用H100计算能力中很少的百分比,大部分算力是空余的。如果把这个存储墙问题解决,H100的实际效能可能至少提升10倍以上。
我们认为在大模型时代,AI大算力芯片的竞争核心会逐步转向破除“存储墙”。这部分谁解决得好,谁就会在未来AI芯片竞争格局里占优势,Amdahl Law阿姆达尔定律早已揭示了这点。
在大模型时代,数据搬运已经占据整个计算周期90%以上。这意味着算力本身对于实际算力来说,重要性反而不是那么高,更重要的是解决数据的搬运。
由此出发,我们认为存算一体超异构的AI芯片架构,天然地适合AI的并行计算。换句话说,存算一体是为AI大模型而生的计算架构,它的核心就是解决存储墙,从而解决能耗跟实际算力瓶颈的问题。今天就介绍这些,谢谢大家!
以上是熊大鹏演讲内容的完整整理。
