








智东西(公众号:zhidxcom)
作者 | 香草
编辑 | 李水青
智东西3月6日报道,昨天下午,明星创企Stability AI发布Stable Diffusion 3(SD3)论文,首度披露其最强文生图大模型背后的技术细节,并放出更多新鲜的生成示例。

▲Stable Diffusion 3模型技术原理论文
与OpenAI近期爆火的文生视频模型Sora一样,SD3采用了扩散Transformer架构DiT,并在其基础上进行改进。新架构名为MMDiT,其主要突破点在于对文字、图像两种模态的数据使用了两组独立的权重,并通过注意力机制进行连接,这使得信息可以在文本和图像之间流动,大大提升了模型的语义理解和文字渲染能力。
在SD3放出的示例图中,包含文字渲染部分的图像占了很大比例。下图的提示词分别为:漂亮的像素艺术,画面是一个魔法师和悬浮文字“Achievement unlocked: Diffusion models can spell now”(成就已解锁:扩散模型可以拼写了);青蛙坐在20世纪50年代的一家餐馆里,穿着皮夹克,头戴礼帽,桌上有一个巨大的汉堡和一个写着“froggy fridays”(青蛙星期五)的小牌子。

▲SD3生成图像示例
目前,SD3还未开放访问权限,但Stability AI承诺未来将公开实验数据、代码和模型权重。不得不说,Stability AI真的是将开源贯彻到底,可谓是真正意义上的“Open”AI。
体验申请地址:
https://stability.ai/stablediffusion3
论文地址:
https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
一、文字渲染完胜Midjourney,语义理解平均胜率超六成
Stability AI从视觉效果、语义理解、文字渲染三个方面将SD3的性能与主流文生图模型进行比较,包括闭源模型DALL-E 3、Midjourney V6以及自家的开源模型SDXL、SDXL Turbo、Stable Cascade等。其中根据目前披露的示例来看,SD3的文字渲染仅支持英文,暂不支持中文等其他语言。
根据人类反馈结果,SD3最大参数规模的8B模型在视觉效果上,几乎胜过所有市面上的模型,语义理解能力平均胜率超60%,文字渲染能力则“遥遥领先”,在与Midjourney V6等6款模型的比较上胜率超80%,对DALL-E 3的胜率也接近70%。
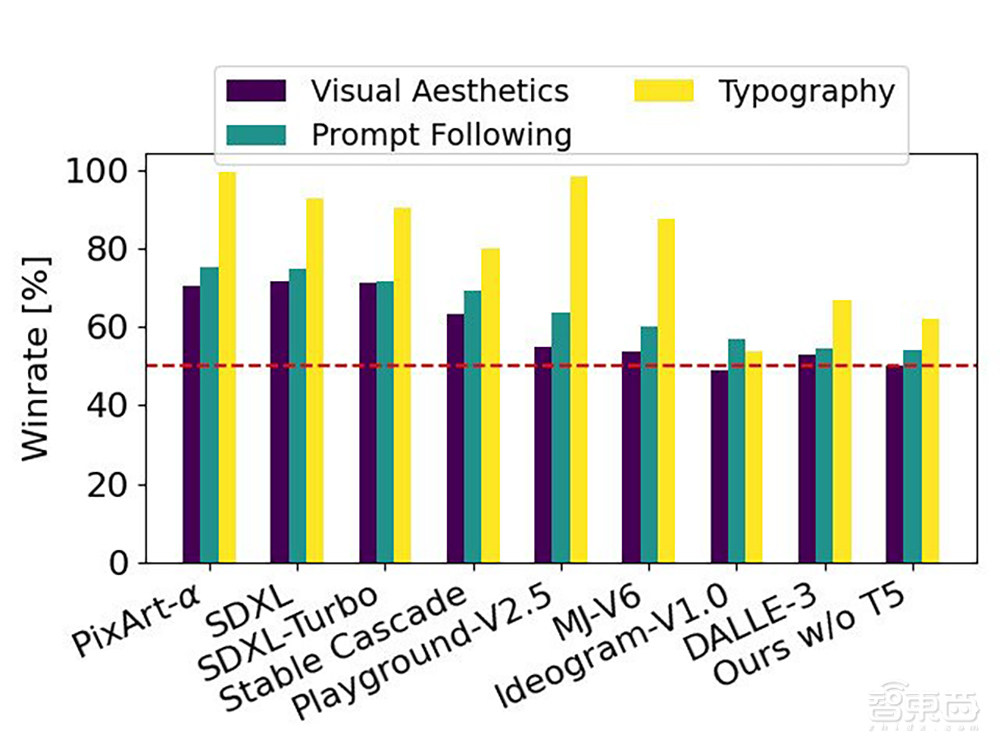
▲SD3-8B模型与主流文生图模型相比的胜率
当然,人类评估带有一定的主观色彩和偶然性。论文中,Stability AI还放出了测评基准的比较结果。
在用于评估文本到图像对齐的测评基准GenEval上,深度参数为38、经过DPO(直接偏好优化)的SD3模型取得多个任务上的最佳成绩。
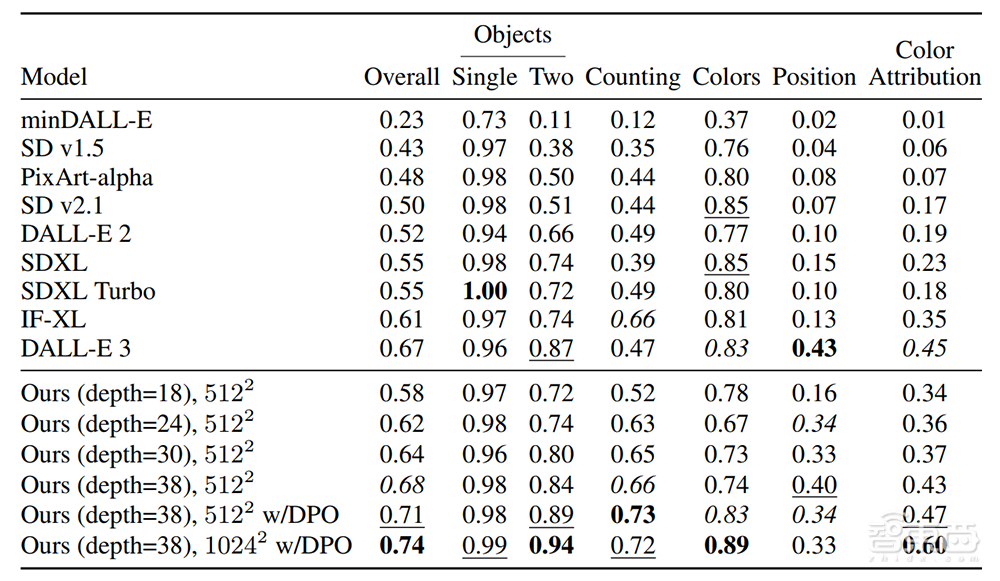
▲SD3在GenEval基准上与其他主流模型的对比
Stability AI在论文中放出了更多新鲜的文生图示例,让我们一起来感受一下“最强文生图大模型”有多强吧。
1、文字渲染能力:精准拼写英文单词,自动适配画面背景
提示词1:一幅由流动的色彩和风格组成的美丽画作,上面写着“The SD3 research paper is here!”(SD3研究论文来了!),背景是斑斑点点的水滴和飞溅的颜料。

提示词2:一只穿着西装、戴着帽子的熊站在森林中的一条河里,举着“I can’t bear it”(我无法忍受)的牌子。

提示词3:一只面带微笑的卡通狗坐在桌旁,手端咖啡杯,房间里火光冲天。这只狗向自己保证:“This is fine.”(不会有事的。)

提示词4:一副美丽的油画,画面是午后的河中有一艘蒸汽船。在河的一侧是一座大型的砖砌建筑,顶部有一个标志,上面写着“SD3”。

2、语义理解能力:完美呈现细节描述,想象力Max
提示词5:半透明的猪,里面是一头更小的猪。

提示词6:一只奶酪做的螃蟹在餐盘上。

提示词7:一个穿着运动鞋的长腿可爱大眼拟人化芝士汉堡,在装饰简朴的客厅沙发上休息的电影剧照。
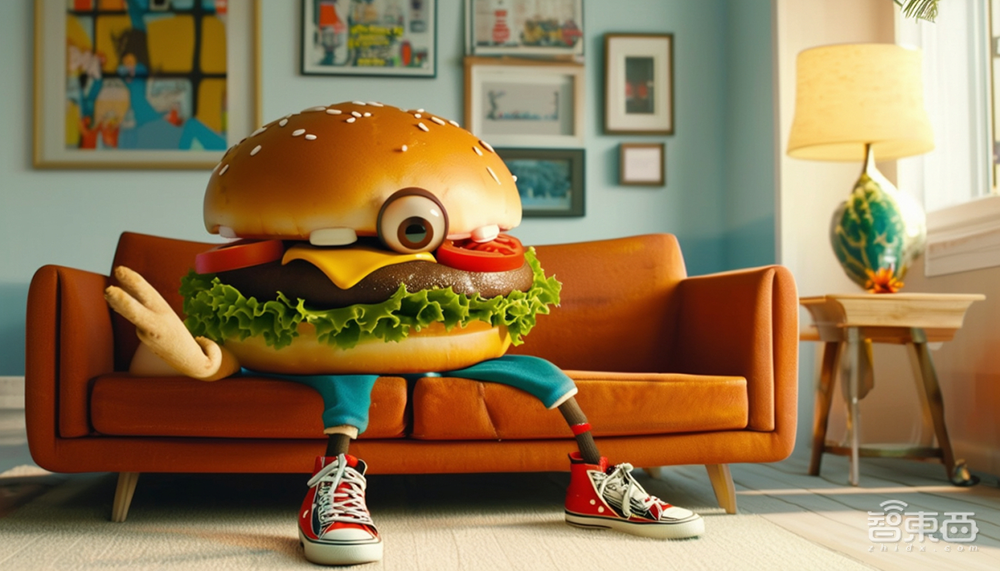
提示词8:一只袋鼠拿着啤酒,戴着滑雪镜,热情地唱着愚蠢的歌。

3、视觉美学能力:驾驭不同画风,色彩明亮鲜艳
提示词9:这幅细致的笔墨画描绘了一艘巨大复杂的外星太空船,位于荒郊野外的一个农场上空。

提示词10:分形主题餐厅柜台后的拟人分形人。

提示词11:黑暗的高对比度效果图,迷幻的生命之树照亮了神秘洞穴中的尘埃。

提示词12:倾斜移位航拍,傍晚木桌上由寿司组成的可爱城市。

二、基于Sora同款架构DiT,文本、图像采用两组独立权重
那么,如此强大的文字理解、渲染和视觉效果,SD3是怎么做到的?
作者提出一种新架构MMDiT(Multimodal Diffusion Transformer),它建立在DiT的基础上——没错,就是Sora采用的那个DiT模型。其中,“MM”指的是它处理多模态信息的能力。
下图是MMDiT的整体架构示意图。与之前版本的SD模型一样,SD3使用预训练模型来推导合适的文本、图像提示。
不同之处在于,MMDiT对文本和图像两种模态使用了两组独立的权重,并在图像和文本标记之间实现双向信息流,从而提高了文本理解和拼写能力。
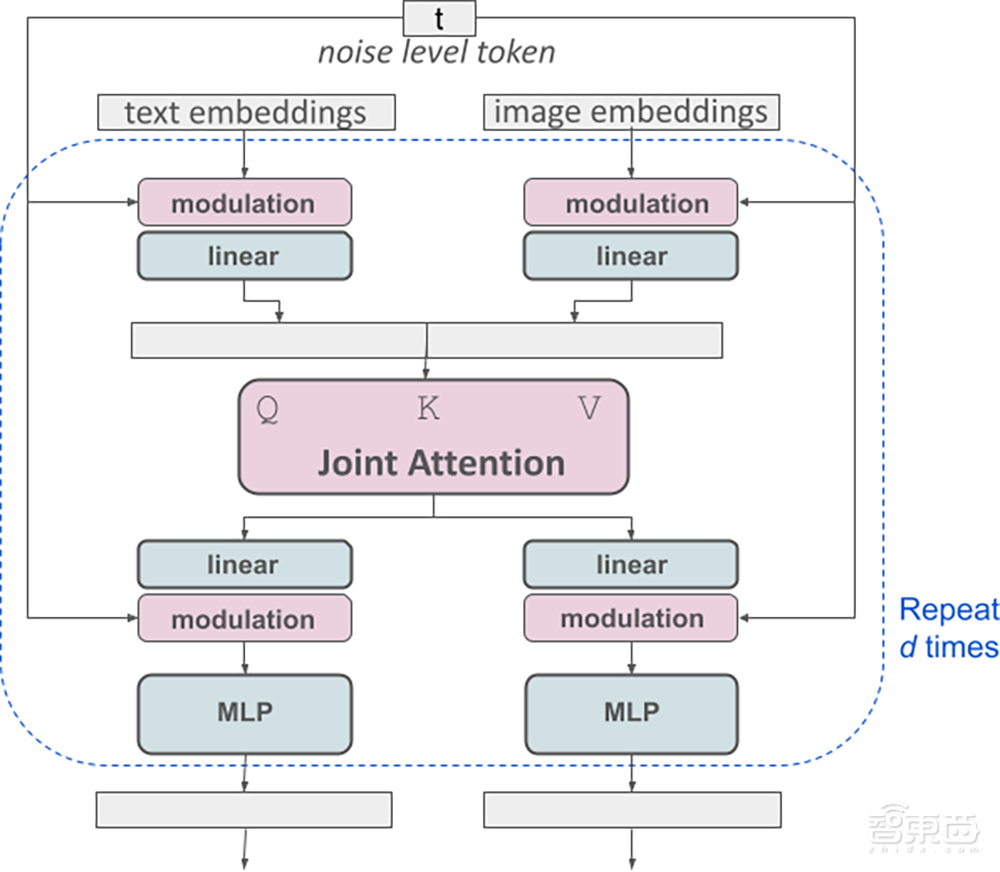
▲MMDiT架构示意图
具体来说,SD3使用预训练的自编码器,将RGB图像映射到一个低维的潜在空间;在文本编码上,采用三种不同的文本嵌入器来编码文本表示,包括两个CLIP模型和T5。
随后,SD3通过添加位置编码,将图像的潜在像素表示的2*2补丁(Patch)扁平化为补丁编码序列,构造了一个由文本嵌入和图像输入组成的序列。
在将该补丁编码和文本编码嵌入到一个共同维度后,SD3将这两个序列连接起来,按照DiT的方法应用调制注意力和MLP(多层感知机)序列。
如下图(b)所示,SD3为每种模态设置了独立的Transformer,但在注意力操作时,将两种模态的序列结合在一起。这样一来,两种表征都能在各自的空间内工作,同时也将另一种空间考虑在内。
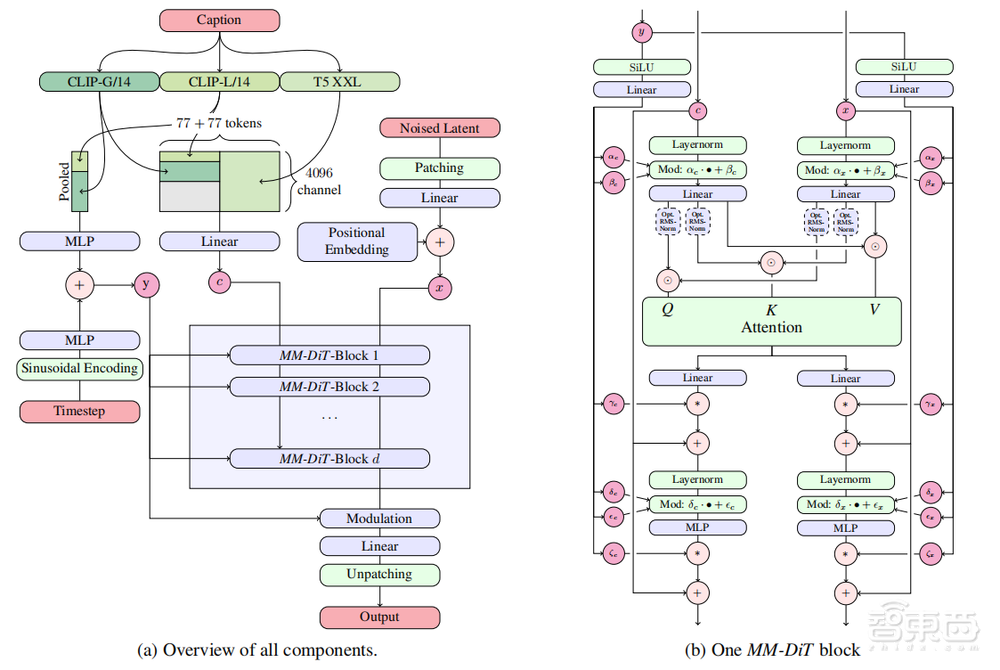
▲MMDiT模型完整架构
SD3采用的是整流(Rectified Flow,RF)公式,它的前向过程更简单,采样速度更快。为了证明改进的RF方法的优越性,作者在2个数据集上训练了61种不同的公式,包括各种扩散目标、损失函数以及不同的时间步采样。
数据方面,作者使用开源模型CogVLM生成了合成标记,最终的数据集中有50%原始标记和50%合成标记,这些更加具有描述性的合成标记极大地提升了模型的性能。
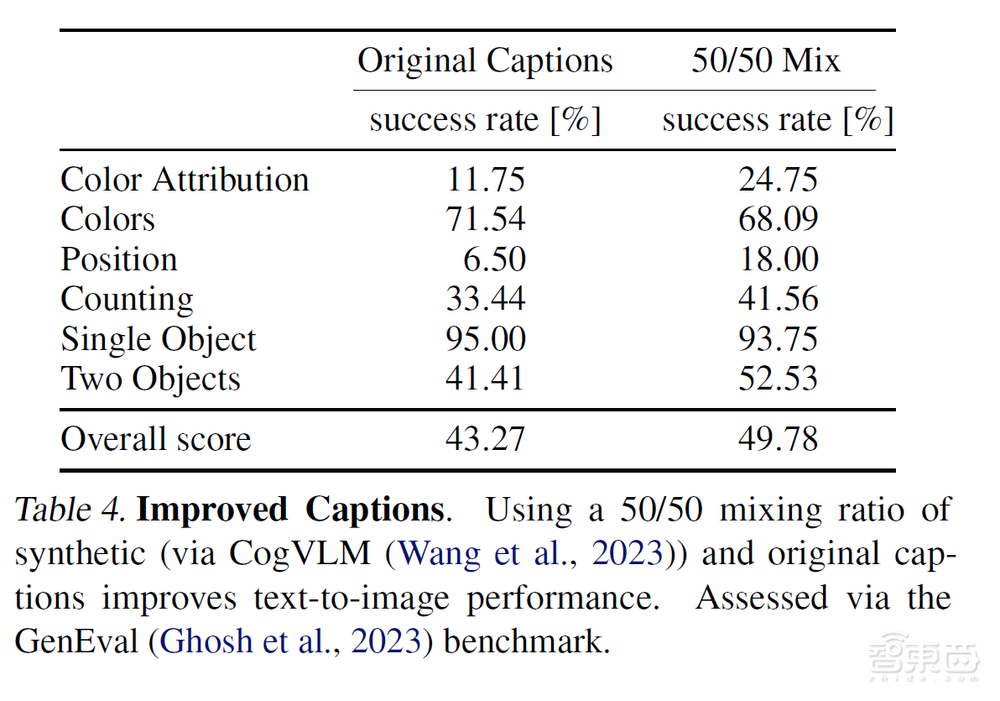
▲使用合成数据对模型训练的提升
模型训练方面,Stability AI称早期未优化的推理测试是在消费级硬件上进行的,其最大的80亿参数SD3模型适用于24GB显存的英伟达RTX 4090,使用50个采样步长生成分辨率为1024*1024的图像耗时34秒。此外,SD3将发布多种规模的版本,从8亿到80亿参数不等,以进一步消除硬件障碍。
三、生成式AI成果连发,图像视频音频3D语言全面布局
就在同一天,Stability AI还与3D重建平台Tripo AI合作推出了TripoSR,可在一秒内从单张图像生成高质量的3D模型。

▲TripoSR输入输出示例
据介绍,TripoSR支持较低的推理预算,即使没有GPU也能运行。该模型基于Adobe的三维重建模型LRM构建,主要针对娱乐、游戏、工业设计等行业需求。
在英伟达A100上进行测试时,TripoSR能在0.5秒生成草稿质量的三维纹理网格,优于OpenLRM等其他开源图生3D模型。
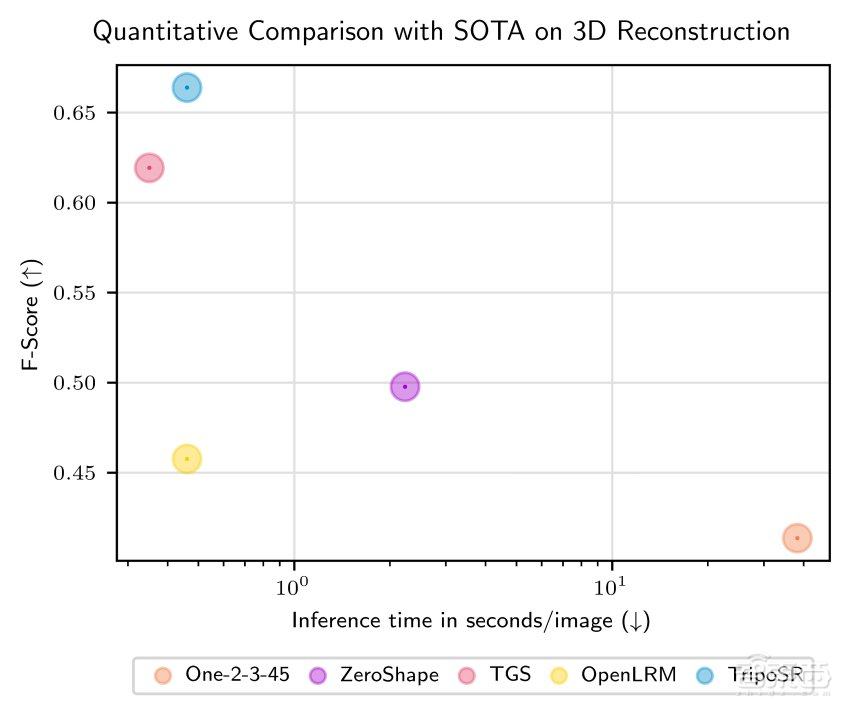
▲TripoSR与OpenLRM等三维重建模型的比较
开源地址:
https://github.com/VAST-AI-Research/TripoSR
密集的产品或模型发布并不是心血来潮,而是这家生成式AI独角兽的常态。仅仅2024年以来,它便在短短两个多月内连发5款新模型。除了昨天的SD3和TripoSR,还有文生图模型Stable Cascade、语音模型Stable LM 2 1.6B、代码模型Stable Code 3B。
成立5年来,Stability AI在图像、视频、音频、3D和语言五个领域全方位布局生成式AI,形成了强大的“Stable家族”。最重要的是,它一直秉持着自己开源开放的原则,几乎所有模型都支持下载并发布了技术论文。据其官网数据,Stability AI在托管平台Discord已拥有27万用户,基于其API(应用程序接口)生成的图像超过4亿张。
但同时,开源也是一把双刃剑,尤其是对于一家技术是主要竞争力的大模型公司而言——更不用说模型训练有多“烧钱”了。
2023年11月,Stability AI被曝由于财务状况压力巨大正在寻求出售。几乎同时,Stability AI宣布将推出会员模式,其CEO在社交平台X上提到“最近几周的情况表明,商业模式的一致性在AI中非常重要”。12月,Stability AI正式推出三种等级的会员制度,其中专业级月费20美元,可商用全套核心模型。
结语:文生图开源社区再添一员巨将
Stability AI最近颇有种“AI界汪峰”的感觉。
先是2月22日,推出超强新版本文生图模型Stable Diffusion 3,却被谷歌的开源大模型Gemma抢了风头。又在昨天,开源图生3D新模型TripoSR,结果撞上OpenAI最强竞争对手Anthropic发布Claude 3,见证了GPT-4时代的“终结”。或许是咽不下这口气,Stability AI在同一天又发布了这篇SD3论文,不仅披露了背后的MMDiT详细架构,还承诺SD3将全面开源。
在生成式AI的浪潮中,Stability AI坚持为开源社区添砖加瓦,为研究人员和开发者提供了宝贵的资源。在技术论文中,我们不仅看到了该模型的强大能力,也看到了Stability AI对其开源精神的信守承诺。
虽然Stability AI公司内部管理、CEO的处事风格等一直存在争议,还被福布斯预告今年将会倒闭,但随着其一次次推动技术的边界,也向我们证明了在科技领域,技术才是最重要的“护城河”。
在SD3的预告中,Stability AI还暗示其可能会具备视频生成能力。未来我们期待看到SD3等开源模型迸发出更多潜力,造福更多用户和开发者。
