








智东西(公众号:zhidxcom)
编译 | 香草
编辑 | 李水青
智东西3月8日报道,近日,深度学习三巨头之一、Meta首席科学家杨立昆点赞分享了一篇万字博文《视频生成器是世界模拟器吗?(Are Video Generation Models World Simulators?)》。
▲杨立昆在X平台上转发并称这是一篇好文章
文章从Sora的工作原理、模拟假说、直观物理学、世界模型的定义、图像生成等角度,深入探讨了标题所提出的问题,并得出结论:像Sora这样的视频生成器,可能不是人们想象中的“世界模拟器”,但从更宽泛的定义上来看,它们可以被视作有限的“世界模型”。
本文作者以文生图模型为例证,论述了Sora可能和Stable Diffusion类似,生成过程超出了对像素空间表面统计的拟合,可能受到3D几何和动态关键方面的潜在表示的影响,从而学到有用的深度、因果等特征的抽象表征。换句话说,Sora能在潜在空间中学习抽象规律,具有部分模拟世界的能力。
自Sora于今年初发布以来,“Sora是否理解物理世界”话题引来众多大佬下场讨论。其中英伟达的科学家Jim Fan将Sora描述为“数据驱动的物理引擎”;杨立昆则多次开喷Sora,称Sora的训练方式无法构建世界模型,通过生成像素的方式来建模世界,与几乎已经被抛弃的“综合分析”方法一样,浪费时间且“是一次彻头彻尾的失败”。
该文章的作者是澳大利亚悉尼麦考瑞大学的哲学讲师拉斐尔·米利埃尔(Raphaël Millière),他主要从事AI、认知科学和心智哲学等方面的学术研究。以下是对该文章的全文编译,由于篇幅原因进行了部分删减。

▲文章首页截图
原文地址:
https://artificialcognition.net/posts/video-generation-world-simulators/#concluding-thoughts
一、Sora是一项工程壮举,架构没有真正突破
2024年2月16日,OpenAI推出Sora,一个令人印象深刻的新型深度学习模型,可以根据文本提示生成视频和图像。Sora可以生成长达一分钟的视频,具有不同的分辨率和宽高比。虽然目前无法测试该模型,但OpenAI挑选的结果表明它在先前的技术水平上有了巨大的改进。
OpenAI有些自大地声称Sora是一个“世界模拟器”。那么什么是世界模拟器呢?这是OpenAI对训练Sora动机的陈述:
“我们正在教AI如何理解和模拟物理世界中的运动,目标是训练出能够帮助人们解决需要与现实世界进行交互的问题的模型。”
OpenAI还发布了Sora技术报告,其中阐述了对Sora理论意义的理解:
“我们的研究结果表明,扩展视频生成模型是建立物理世界通用模拟器的一条可行之路。”
Sora的技术报告对细节描述得很少,但提供了一些关于架构的线索。其核心是一个扩散变换器(Diffusion Transformer,简称DiT),这是比尔·皮布尔斯(Bill Peebles,也是Sora的主要作者之一)纽约大学的谢赛宁设计的一种架构。
DiT是一种具有Transformer主干网络的扩散模型。我们熟悉的图像生成模型,如Stable Diffusion是潜在扩散模型。它们使用预训练的变分自动编码器(VAE)将原始图像从像素空间压缩到潜在空间;然后,扩散模型在从VAE学习的较低维潜在空间上进行训练,而不是在高维像素空间上。这种扩散过程通常使用U-Net骨干实现。U-Net是一种卷积神经网络,最初用于图像分割,后来被调整用于去噪扩散。
DiT架构受潜在扩散模型的启发,但将U-Net骨干替换为修改后的视觉Transformer(ViT)。ViT是专门用于视觉任务的Transformer模型,它不以语言标记作为输入,而是接收图像块的序列。例如,一幅图像可以分割成16*16的补丁(Patches),从而为Transformer提供256个输入Tokens。同样,作为DiT的核心修改后,ViT接受来自VAE的图像补丁的潜在表示作为序列输入Tokens。相较于带有U-Net的传统潜在扩散模型,DiT具有一些优势:效率更高、扩展性更好,而且易于适应不同的生成分辨率。
在Sora之前,DiT架构已经被用于文本条件下的图像和视频生成。OpenAI提出的解决方案使用所谓的“视频压缩网络”(Video compressor network),这可能是针对视频进行改编的VAE。其基本思想与最初的DiT相同:
(1)视频压缩网络将原始视频输入压缩为潜在时空表示;
(2)压缩后的视频被转换为“时空补丁”,作为输入Token提供给扩散变换器;
(3)在最后一个Transformer块之后,与视频压缩网络一起训练的解码器模型将生成的潜在表示映射回像素空间。
与OpenAI之前的GPT-3等成就一样,大家的共识似乎是,Sora的架构并没有什么真正的突破。正如谢赛宁所说,它实质上是一种适用于视频的DiT,没有额外的花哨功能。
因此,Sora在很大程度上是一项工程壮举,也是对扩展能力的又一次证明。技术报告生动地说明了样本质量随着训练计算量的增加而提高。与语言模型一样,某些能力似乎也会随着规模的扩大而显现;自然地,Sora也再次引发了关于纯粹的扩展到底能达到什么程度的激烈争论。
二、模拟假说:视频生成模型在训练中习得物理规律
Sora的技术报告声称,随着规模的扩大,Sora获得了“新兴的模拟能力”。它提到了通过动态摄像机运动、遮挡、客体永久性和视频游戏模拟等来实现场景一致性,作为此类能力的示例。报告继续得出结论:
“这些能力表明,视频模型的持续扩展是开发高性能物理和数字世界模拟器的有力路径,这些模拟器涵盖了生活在其中的对象、动物和人。”
我们称之为模拟假说(Simulation hypothesis)。
这个假设的问题在于,它非常模糊。视频生成模型模拟物理世界到底意味着什么?什么样的证据可以支持这一主张?让我们逐一回答这些问题。
在Sora发布之后,AI行业的知名人士纷纷表达了他们对模拟假说的理解。英伟达的Jim Fan将Sora描述为“数据驱动的物理引擎”。他这样解释这句话的含义:
“Sora通过大量视频的梯度下降,在神经参数中隐式地学习物理引擎。Sora是一个可学习的模拟器,或者说是‘世界模型’。
Sora必须学习一些隐式的文本到3D、3D变换、光线追踪渲染和物理规则,以便尽可能准确地模拟视频像素。它必须学习游戏引擎的概念,以满足目标。”
物理引擎的术语有些令人困惑,尤其是考虑到有猜测认为Sora是在虚幻5场景上训练得到的,所以让我们先澄清这一点。
据我所知,包括Jim Fan在内,没有人真的认为Sora在推理时有一个物理引擎在循环中。换句话说,作为一个DiT模型,它不会在生成视频时调用虚幻引擎。
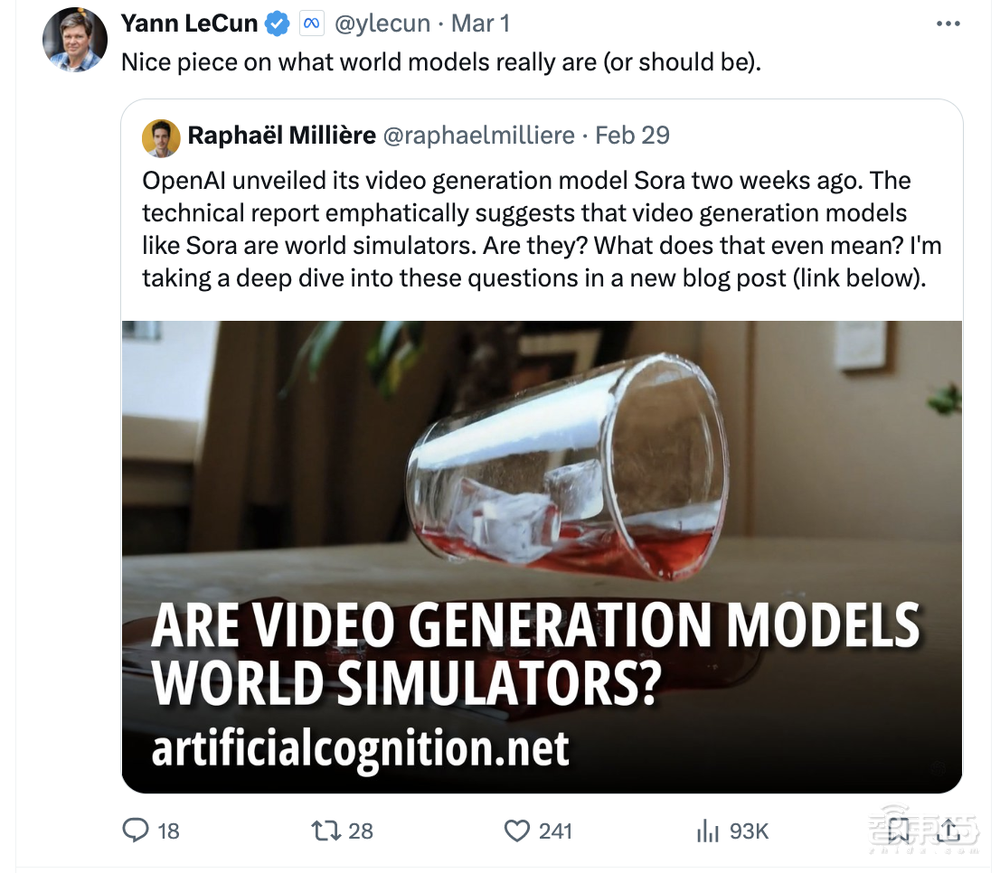
实际上,神经网络调用物理引擎以前已经有人尝试过,但不是用于视频生成,而是为了物理推理。2023年,谷歌大脑的一篇论文Mind’s Eye通过物理引擎模拟可能的结果,来提高语言模型在物理推理问题上的表现,将这些模拟的结果作为提示词中的线索。
▲Mind’s Eye论文截图
那么,我们应该如何理解Sora类似于“数据驱动的物理引擎”模拟物理世界的主张呢?谷歌DeepMind的Nando de Freitas这样说:
“一个有限大小的神经网络能够预测任何情况下会发生什么的唯一方式,是通过学习内部模型来促进这种预测,包括直观的物理定律。”
我们越来越接近模拟假说的明确陈述:一个基于端到端神经网络架构、参数设置有限的足够好的视频生成模型,应该有望在训练过程中获得物理世界的内部模型,因为这是神经网络生成任意场景的连贯、逼真视频的最有效方法——也许是唯一的方法。
Sora 是否真的从 2D 视频中归纳出物理定律?
如上所述,这可能看起来很荒谬。
游戏引擎通常也不模拟这些法则。虽然它们可能会模拟热效应(火灾、爆炸)和做功(物体克服摩擦力移动),但这些模拟通常是高度抽象的,并不严格遵守热力学方程。他们根本不需要这样做,因为他们的重点是渲染场景的视觉和交互可信度,而不是严格的物理准确性。
Sora会做类似的事情吗?
如果想回答这个问题,我们需要探讨直观物理学。
三、像人一样,通过直观物理引擎模拟事件?
对人类而言,即使是婴儿也展现出对物理世界的稳定预期。例如看到一只球沿着地板滚向墙壁,我们会直觉地知道球会撞到墙壁并反弹回来,而不是穿过它。
这就是认知科学家称之为直观物理学(Intuitive physics)的东西:一种快速、自动的日常推理,它让人们知道当各种物体相互作用时会发生什么,而不需要有意识地进行物理计算。
▲作为概率推理的直观物理学论文截图
人类是如何做到的呢?认知科学家提出了一个著名的假设,人们使用一个直观物理引擎(IPE)来模拟物理事件。
IPE类似于计算机游戏中的物理引擎,它基于不完全准确的物理原理,通过随机模拟来预测物理现象。根据这种观点,当我们观察物理场景时,会根据质量、摩擦、弹性等感知证据构建对物体、属性和作用力的心理表征,然后运行内部模拟来预测接下来会发生什么。
然而,关于IPE假设也存在争议。批评者指出,人类的物理推理有时会偏离IPE式模拟预测,包括系统偏差和错误以及对视觉捷径的依赖等。一些人认为,非牛顿心理模型、深度学习模型可能更好地解释人类对物理的直觉。
尽管存在争议,但至少有一个相对合理且有丰富实验文献支持的案例支持模拟假说。现在,我们可以将这一背景知识应用于人工神经网络,探讨它们是否能够模拟物理世界。
四、已有“世界模型”,未达强因果概念高标准
通过心理学中的直观物理学,我们提出了一个重要的点:对物理场景进行心理模拟,与仅仅表示物理世界的各个方面(例如几何形状)之间存在表面上的区别,这个区别在讨论像视频生成模型这样的神经网络的能力时非常重要。
世界模型(World models)的含义已经被淡化,以至于在实践中变得相当难以捉摸。在机器学习研究中,它主要起源于20世纪90年代Juergen Schmidhuber实验室的强化学习文献。在这种情况下,世界模型指的是智能体对其交互的外部环境的内部表示。具体来说,给定环境状态和智能体行动,世界模型可以预测智能体采取该行动后环境的未来状态。
在2018年Ha和Schmidhuber发表的世界模型论文中,他们提出世界模型包括一个感官组件,它处理原始观察结果,并将它们压缩成一个紧凑的编码。具体来说,基于RNN的世界模型被训练为在智能体之前的经验条件下,内部模拟并预测未来的潜在观察编码、奖励和终止信号(完成状态)。

▲Ha和Schmidhuber的世界模型模拟的环境中驾驶的智能体
Ha和Schmidhuber的世界模型论文影响了许多后续作品。谷歌DeepMind近日推出了基础世界模型Genie,虽然它不是一个强化学习系统,但它与Ha和Schmidhuber的框架具有关键的相似之处。
Genie生成一个交互式环境,人类用户可以通过影响未来视频生成的操作来控制智能体,它引入了无监督动作空间学习的概念,以避免训练过程中对动作标签的依赖。因此,任意视频都可以作为训练数据,而不是带有动作标记的示例。

▲Genie
另一个值得一提的世界模型概念来自杨立昆,这在他的联合嵌入式预测架构(JEPA)中得到了突出体现。在他的框架中,世界模型是一个智能体用于规划和推理世界如何运作的内部预测模型,用于两个关键功能:
(1)估算智能体感知系统未提供的有关当前世界状态的缺失信息;
(2)预测智能体提出的一系列动作可能产生的多个可能的未来世界状态。

▲杨立昆提出的自主机器智能认知架构的高层示意图
在JEPA架构中,世界模型模块是由预测器网络实现的。它最近被应用于视频,自监督模型V-JEPA通过预测视频潜在空间中遮蔽时空区域的表示来学习。V-JEPA和Sora之间的一个关键区别是它们各自的学习目标,以及这些目标可能对其潜在表示产生的下游影响。Sora针对像素空间的帧重建进行训练的,而V-JEPA则针对潜在空间的特征预测进行训练。根据杨立昆的观点,这会导致它们潜在表示之间的巨大差异。在他看来,像素级别的生成目标根本不足以诱导可能对在世界中规划和行动有用的抽象表示。
总之,人们使用“世界模型”一词的方式略有不同。无论是生成模型、强化模型,还是JEPA模型,都没有达到因果推理文献中“世界模型”这一强因果概念所设定的高标准。
那么像Sora这样的视频生成模型呢?我们可以从图像生成模型中寻找线索。
五、图像生成模型能学习3D几何结构,提供重要线索
Sora模型的核心是DiT,它受到常用于图像生成的潜在扩散模型的启发,但将U-Net骨干替换为了ViT。
这引发了一系列问题:基于潜在扩散的图像生成模型实际上编码了哪些信息?是仅仅编码了图像表面的启发式信息,还是编码了视觉场景的潜在变量,比如3D几何结构?
目前,关于这个问题的研究并不多。
Zhan等人于2023年提出了一种方法来评估潜在扩散模型是否编码了图像中描绘的3D场景的不同物理属性。测试结果显示,像Stable Diffusion这样的模型能够编码关于3D场景几何、支持关系、照明和相对深度的信息,尽管在遮挡方面的分类性能较低。
这项研究仅仅表明物理属性的信息可以从模型的激活中解码出来,并不意味着这些信息在模型行为上具有因果效力。
Chen等人在2023年的研究填补了这一空白。他们创建了一个由潜在扩散模型Stable Diffusion生成的图像数据集,并训练线性探测器来预测显著对象的分割和深度值。通过干预实验,他们发现模型的内部激活对生成图像的几何形状有因果影响。

▲用Chen等人的扩散模型解码的深度和突出物体表示
这个实验表明,像SD这样的潜在扩散模型能够学习到关于简单场景几何的线性表示,特别是与深度和前景/背景区分相关的表示,即使它们仅仅在没有显式深度监督的情况下,只通过2D图像进行训练。
此外,这些表示在迭代采样过程的早期阶段就出现了,而在这些阶段,图像本身对于人类观察者来说仍然像是随机噪声,并且几乎不包含深度信息。这表明潜在扩散模型所做的远远超出了对像素空间表面统计的拟合。它们引导了关于深度和显著性的潜在信息,因为这样的信息对于生成逼真的图像目标非常有用。
还有其他关于图像生成模型的相关研究。低秩自适应(LoRA)可以用来直接从潜在扩散模型中提取内在的“场景图”,如表面法线和深度。该方法可以将任何图像生成模型转化为固有场景属性预测器,而不需要额外的解码网络。结果表明,可以通过利用模型参数中已经存在的信息来提取关于3D场景几何的精细预测。

▲在SD的内在场景地图使用I-LoRA方法
这并不意味着潜在扩散模型能完美地表示视觉场景的各个方面的三维几何。实际上,经过训练的人眼通常可以注意到输出中的各种缺陷,物理不一致性甚至可以通过分类器进行量化,就像Sarker等人(2023年)所做的那样。这些不一致性包括物体及其阴影的错位,以及违反投影几何学的情况,例如线条未能正确地收敛到消失点或不遵循线性透视:

▲AI生成的图像中存在的物理不一致性
对于如何修复生成图像中这些持续存在的缺陷,有很多有趣的猜想。一个假设是,测试的模型可能不够大,或者训练数据不够充分。通过扩大参数和数据集的规模,可能足以使潜在扩散模型学习正确的投影几何,就像它足以修复先前模型中的许多其他逼真性和连贯性问题一样。但也有可能存在更基本的问题,阻止潜在扩散模型正确学习投影几何。例如,它们的架构可能缺乏适当的归纳偏差。在这种情况下,使用ViT作为主干结构的DiT也可能减轻纯潜在扩散的不足之处。
总之,对潜在扩散模型的探测和干预研究表明,它们确实能表示视觉场景3D几何的一些特征,这与它们原则上可以学习至少有限程度的“世界模型”的假设是一致的。它们的潜在空间编码了结构保持、因果有效的信息,这些信息超越了像素空间的表面统计数据。这是解决关于Sora和模拟假说的猜测的重要线索。
六、Sora在潜在空间中学习抽象规律,是有限的“世界模拟器”
与用于图像生成的潜在扩散模型一样,Sora是根据视觉输入进行端到端训练的,其训练和生成都没有明确地以物理变量为条件。但就像潜在扩散模型一样,它的输出表现出惊人的规律性。
在回顾了认知科学和机器学习中的直观物理模拟和世界模型的不同方式后,我们可以肯定的第一件事是,Sora从根本上不同于使用专用“直观物理引擎”来运行模拟的复合模型。
与直观物理引擎模型不同,Sora没有专门的感知、预测和决策模块,需要像物理引擎这样的接口;它只是一个高维空间,其中潜在表示经历跨层的连续变换。
Sora也与Ha和Schmidhuber的世界模型大不相同。它不基于离散动作、观察和奖励信号的历史来运行模拟。
在这方面,OpenAI的技术报告有些误导性内容。其给出的Sora演示视频看起来像是从Minecraft这样的视频游戏中捕获的,但技术报告对这些输出结果的解释却更进一步:Sora可通过基本策略(basic policy)控制Minecraft中的玩家,同时还能高保真地呈现世界及其动态效果。

▲Sora演示视频
这表明Sora模仿了一个智能体(“可控”角色)的政策,就像离线强化学习一样。但这里没有传统意义上的“策略”——或者说代理、动作、奖励。与Genie不同,Sora没有接受过从视频中诱发潜在动作的训练,并且其输出也不以此类动作为条件。
如果按照字面意思,技术报告暗示Sora已经自发地学会了在Minecraft角色内部表示类似隐式策略的东西,但这肯定不是我们仅通过查看输出就可以推断出来的。这是一个相当大胆的主张,应该通过分析模型内部的情况来澄清和支持。
因此,Sora与IPE模型、基于RL世界模型以及Genie不同,在以下强定义上,它不是一个“世界模拟器”。
定义1:一个可以对环境的元素和动态进行向前时间模拟,并且其预测是基于这些模拟的输出条件的系统。
Sora对时空Token的预测是基于先前的时空Token序列进行的,它不涉及运行大量关于2D视频场景中所描绘的3D世界的向前时间模拟。它不会像传统搜索算法一样,通过运行多个内部模拟来预测合法移动,并根据结果调整下一步的预测。
然而,我们不能完全排除Sora是一个“世界模拟器”的假设,或者稍微不那么严谨地说,它是一个“世界模型”,这个概念的弱意义是受到Othello-GPT等系统的启发。
定义2:一种可学习其输入域(包括三维环境的物理属性等)属性的结构保留、因果效应表征的系统。
作为DiT,Sora本质上是一个潜在扩散模型,尽管它有一个Transformer主干网络。Sora与像Stable Diffusion这样的潜在扩散模型在两个重要方面有所不同:(1)处理视频(3D“时空”对象)的潜在表示,而不是图像;(2)其规模可能要大得多,并且在更多的数据上进行训练。因此,我们可以预期,Stable Diffusion在潜在空间中的3D几何图形,可以转化为像Sora这样的系统;我们也可以预期,Sora能代表其输入域的更多“世界属性”,包括随时间展开的过程属性等。
加里·马库斯(Gary Marcus)等批评者指出,Sora的某些输出结果公然违反了物理学原理,以此作为反对模拟假说的证据。OpenAI在自己的博文和Sora技术报告中承认了这些局限性,并提供了一些特别严重的例子。例如,在下面摘录的视频中,我们可以看到明显的时空不一致,包括违反重力、碰撞动力学、稳固性和物体永恒性。

▲Sora生成的视频违反重力和碰撞物理学原理

▲Sora生成的视频违反了实体和客体永恒性
首先要注意的是,虽然这些不一致的现象自然会让我们觉得不可思议,但这些视频也表现出了高度的一致性。玻璃杯悬浮、液体在玻璃中流动、椅子变形为奇怪的形状、人在被遮挡时突然出现……这些反常现象之所以让人觉得奇怪,部分原因是其他一切看起来都与人们预想的差不多。这就是为什么这些输出结果看起来更像是来自一个物理原理奇特的世界的怪异科幻特效,而不是抽象混乱的视觉图案。例如,场景的全局3D几何结构相当一致,各种场景元素的运动轨迹也是如此。
Sora的输出结果显然会在直观物理方面出错,就像SD的输出结果会在投影几何方面出错一样,但这并不能排除这样一种假设,即该模型在某些方面的三维几何和动态表现是一致的。
我们在讨论Sora架构时提到的一点值得重温。与用于生成图像的潜在扩散模型一样,Sora的生成过程并不是在像素空间中进行的,而是在潜在空间中进行的,即对时空斑块的潜在表征进行编码的空间。这大概率是很重要的一点,因为一些评论家认为Sora只是学会了在逐帧像素变化中插值常见模式。对这一评价的一种理解是,Sora只是对像素空间中视频时空“纹理”的常见变换进行近似处理。
以这种方式思考Sora如何生成视频可能会产生误导。在Sora的架构中,编码器和解码器之间发生的一切都发生在潜在空间中。正如对潜在扩散模型的研究表明,深度等属性的潜在表征可以从早期扩散时间步开始产生因果效应。Sora的情况也可能如此:与场景直观物理相关的属性的潜在表征即使在早期扩散时间步也能对生成过程产生因果效应,这并非不可信。
杨立昆等人可能不同意这一观点,因为Sora的训练目标是像素级重建,尽管生成过程发生在潜在空间。因此,有人认为Sora对视频场景的潜在表征不可能那么抽象。但是,同样的论点也适用于用于图像生成的潜在扩散模型;而且,我们也有具体证据表明,这些模型确实能学习到有用的深度等特征的抽象表征。也许V-JEPA的表征比Sora的更加抽象和结构化,但这是一个开放的经验性问题。
结语:视频生成模型,从娱乐到世界模拟的探索
那么,像Sora这样的视频生成模型是世界模拟器吗?
或许在某种程度上是,但不一定是人们所想象的方式。它们的生成过程并不以直观物理的前向时间模拟为条件,就像直观物理引擎那样;但它可能受到3D几何和动态关键方面的潜在表示的影响。
从更弱的意义上说,Sora可能有一个有限的世界模型,就像用于图像生成的潜在扩散模型有一个更有限的世界模型一样。但我们还不能确定,除非某个研究小组以正确的方式对Sora进行研究。OpenAI仍然偶尔进行可解释性研究,所以还是有希望的;我们希望看到更广泛的研究团队能在可解释性方面做出努力,比如Stable Video这样的开源视频生成模型。虽然这些模型的能力远不如Sora,但它们便于研究。
在我们进行猜想的同时,请允许我对视频生成模型的未来做一个简单的推测。我曾说过,Sora并不是一个模拟器,因为它并不是通过先对场景进行一系列模拟来预测视频帧的。不过,也许Sora或其他更强大的视频生成模型可以在一个更综合的系统中用作模拟器。例如,Genie论文的作者们暗示了类似的模型可以用来为训练强化学习智能体生成多样化的模拟环境。未来,我们可以想象机器人系统将使用三个主要组件:
(1)一个大型的视觉语言模型,用于解析语言指令,将其转化为计划,并对视觉输入进行推理;
(2)一个大型的视频生成模型,用于模拟未来可能的观察结果,以进行底层规划;
(3)一个通用的逆动力学模型,用于从这些模拟中提取合适的行动,并据此执行计划。
也许(2)和(3)可以合并到一个通用的Genie式生成模型中,该模型具有内置的(或者学习到的)表示潜在动作的能力;也可以将这三个模型合并成一个巨大的Gato式多模态模型,该模型可以解析和生成语言、时空和动作的标记。这些推测性的场景揭示了从视频的生成建模到更强大意义上的“世界模拟”之间的路径。
让我们以一个有趣的开放性问题来做个总结。无论视频生成模型在AI和机器人技术的未来中扮演什么角色,人们可能会问,与任何深度学习模型一样,它们是否会以非表面的方式与认知科学相关。正如前面讨论的那样,关于人类物理推理在多大程度上依赖于直观物理引擎的显式模拟,目前仍未达成共识。也许视频生成模型的进展,以及未来对其作为基于代理架构的实际模拟器的可行性研究,会给IPE模型带来一些压力。这也可能会引发有趣的讨论,即是否应将能可靠模拟直观物理的神经网络作为端到端学习IPE的核心机制,而不是作为直观物理IPE模型的真正替代品。
无论人们对Sora和OpenAI持何种观点,思考视频生成模型如何超越其娱乐价值而与深度学习和认知科学的关键研究问题相关,都是一件令人兴奋的事情。从GIF生成器到世界模拟器,我们拭目以待。
