








智东西(公众号:zhidxcom)
作者 | 长颈鹿
编辑 | 李水青
智东西4月12日报道,4月9日,谷歌面向180多个国家/地区推出公开预览版的Gemini 1.5 Pro,它具有首个原生音频(语音)理解功能和新的文件API,可轻松处理文件。
不到两个月前,谷歌在Google AI Studio中推出Gemini 1.5 Pro模型,供开发人员试用。该模型在长语境理解方面取得突破,能持续运行多达100万个tokens,相当于可一次处理大量的信息——包括1小时的视频、11小时的音频、超过3万行代码或超过70万字的代码库。现在这些能力都将对外开放,同时谷歌还推出系统指令和JSON模式等新功能,助开发人员加强模型输出控制。
同日,谷歌宣布Gemma开源模型系列增员,推出用于代码生成等任务的CodeGemma,以及用于研究实验的效率优化架构RecurrentGemma。这是自今年2月谷歌推出Gemma之后该系列的首次更新。
一、Gemma的两个变体模型:一个智能编写代码,一个提高处理效率
Gemma家族迎来了两个新成员,均为研究人员提高效率而设计的模型。一个是用于为开发人员和企业提供代码生成服务的CodeGemma,它可以帮助开发人员完成代码、生成代码片段,并且还能提供与代码相关的交流和支持,这些功能可以应用于开发过程中的各种场景和任务。
另一个是用于从事实验研究的效率优化架构RecurrentGemma,这意味着在处理数据时,这个模型可以更有效地利用计算资源,提高处理速度和效率。此外,谷歌还更新了Gemma自身的升级和使用协议。
1.CodeGemma:面向开发人员和企业的代码编写、生成和对话的语言模型
基于开源大模型Gemma,CodeGemma为社区带来了更高性能且轻量化的编码功能。CodeGemma模型有专门用于代码补全和代码生成任务的7B预训练模型变体、用于代码聊天和指令跟踪的7B指令微调变体模型,以及适用于本地电脑的用于快速代码补全的2B预训练模型变体。
CodeGemma模型有以下几个优势:
(1)智能代码的完成和生成:无论本地工作还是利用云资源,CodeGemma都能生成代码行、函数,甚至整个代码块。
(2)更高的准确性:CodeGemma模型从网络文档、数学和代码的5000亿个英语数据为基础进行训练,生成的代码在语法和在语义上更为准确,有助于减少调试时间。
(3)精通多种语言:能够适用于Python、JavaScript、Java和其他流行语言。
(4)简化工作流程:将CodeGemma模型集成到您的开发环境中,从而减少模板的编写,更快地专注于重要的代码。
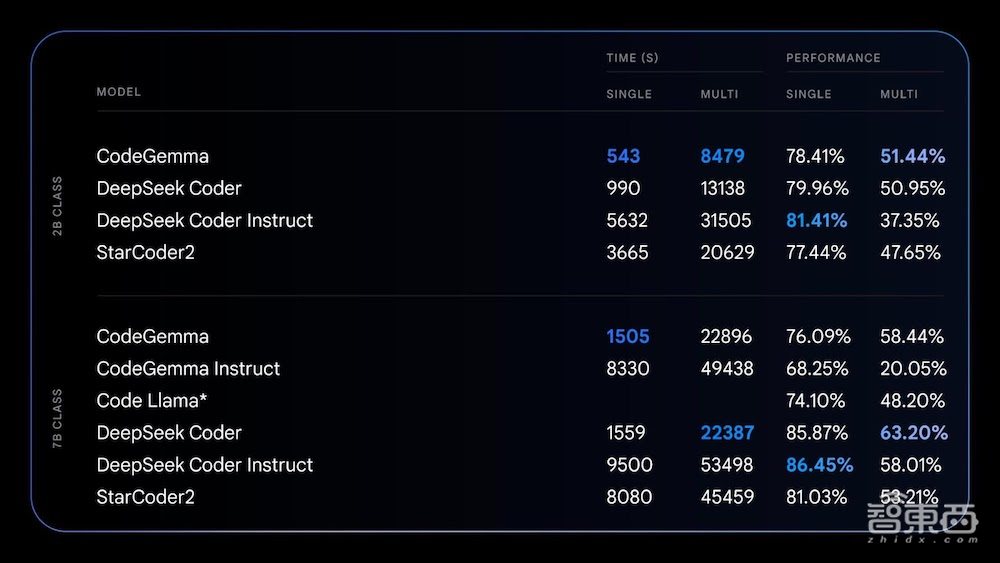 ▲CodeGemma与其他类似模型在单行和多行代码完成任务方面的性能比较(来源:谷歌)
▲CodeGemma与其他类似模型在单行和多行代码完成任务方面的性能比较(来源:谷歌)
2.RecurrentGemma:为研究人员提供更高效、更快速的批量推理
RecurrentGemma是一种新型技术模型,它通过递归神经网络和局部注意力来提高内存效率。
在实现与Gemma 2B模型类似的基准分数性能的同时,RecurrentGemma的独特架构带来了多项优势:
(1)降低内存使用率:较低的内存需求允许在内存有限的设备(如单GPU或CPU)上生成较长的样本。
(2)更高的生产能力:由于降低了内存使用率,RecurrentGemma可以通过更高的批量大小执行推理,从而每秒生成更多的文本(尤其是在生成长序列时)。
(3)研究创新:RecurrentGemma是一种新型的模型,它虽不是基于Transformer架构,但在性能上表现出色,凸显了深度学习领域的研究正在不断取得进步。
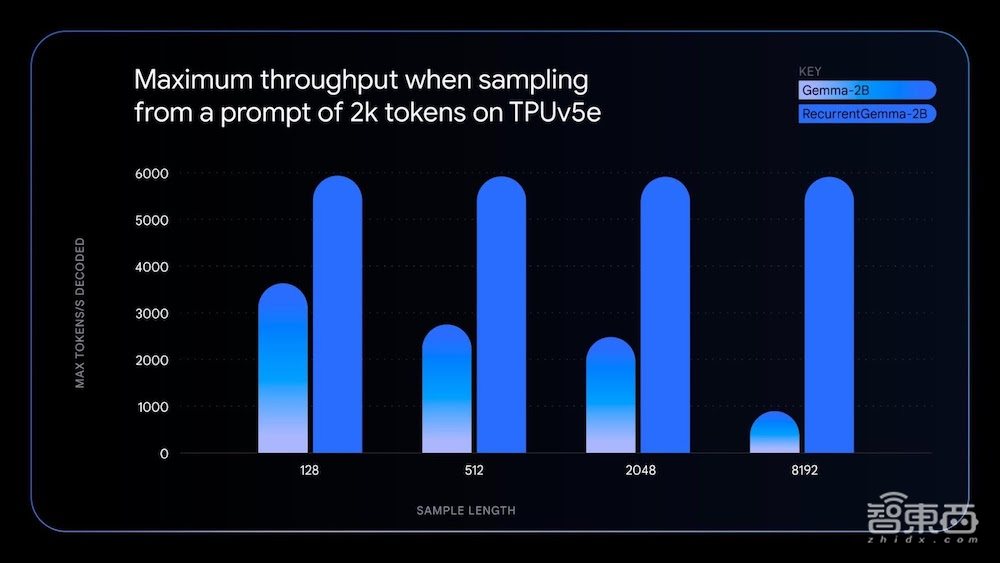 ▲RecurrentGemma与Gemma在采样速度的比较(来源:谷歌)
▲RecurrentGemma与Gemma在采样速度的比较(来源:谷歌)
两个新的变体模型继承了Gemma的基础结构和特性,并且在此基础上进一步增加了更多能力。具体能力为:
(1)开放可用性:与原始的Gemma模型一样,新模型变体也具有开放的可用性,这鼓励创新和合作,任何人都可以使用它,并且具有灵活的使用条款。
(2)高性能和高效能:新模型变体具有高性能和高效能,通过针对特定领域的代码专业知识和优化设计,使得模型的完成和生成速度非常快。
(3)负责任的设计:这些模型遵循负责任的AI原则,以确保模型能够提供安全可靠的结果。
(4)灵活适用于各种软件和硬件:CodeGemma和RecurrentGemma都是使用JAX构建的,并与JAX、PyTorch、Hugging Face Transformers和Gemma.cpp兼容。这使得模型能够在本地进行实验,并在包括笔记本电脑、台式机、NVIDIA GPU和Google Cloud TPU等各种硬件上进行成本效益高的部署。
此外,CodeGemma还与Keras、NVIDIA NeMo、TensorRT-LLM、Optimum-NVIDIA、MediaPipe等兼容,并可在Vertex AI上使用。RecurrentGemma会在未来几周内同样支持上述所有产品。
3.三种方法,使用Gemma模型变体
这些首批Gemma模型变体可在全球多个地方使用,从9号开始在Kaggle、Hugging Face和Vertex AI Model Garden上使用。谷歌提供了三种Gemma模型变体的使用方法:
(1)获取模型:访问Gemma网站、Vertex AI Model Garden、Hugging Face、NVIDIA NIM APIs或Kaggle,按照下载说明获取模型。
(2)探索集成选项:查找用于将模型集成到您喜爱的工具和平台的指南和资源。
(3)进行实验和创新:将Gemma模型变体添加到您的下一个项目中,并探索其能力。
这些指导旨在帮助用户开始使用Gemma模型,并将其整合到他们的工作流程中,以实现更高效的工作和更好的成果。
二、Gemini 1.5 Pro开放使用,支持本地语音和视频理解
本月9日,谷歌将在180多个国家和地区通过Gemini API公开预览版提供Gemini 1.5 Pro,并首次提供本地音频理解功能和新的文件API以方便处理文件。此外,谷歌还将推出系统说明和JSON模式等新功能,让开发人员能够更好地控制模型输出。最后,谷歌将发布下一代文本嵌入模型,使其性能优于同类模型。
Gemini 1.5 Pro的有以下两大新功能扩展:
1.音频模态支持:Gemini 1.5 Pro现在可以在Gemini API和Google AI Studio中实现对音频的理解,这意味着用户可以通过语音输入来与Gemini进行交互。
2.视频理解:Gemini 1.5 Pro现在可以同时处理视频中的每一帧图像和音频内容,并从中提取有用的信息。未来,谷歌还计划为此添加API支持,以便用户可以在自己的应用程序中利用这一功能。
从9日起,开发人员将能够通过Gemini API访问谷歌的新一代文本嵌入模型。这个新模型名为text-embedding-004(在Vertex AI中称为text-embedding-preview-0409),在MTEB基准测试中取得了更强的检索性能,并优于现有可比模型。
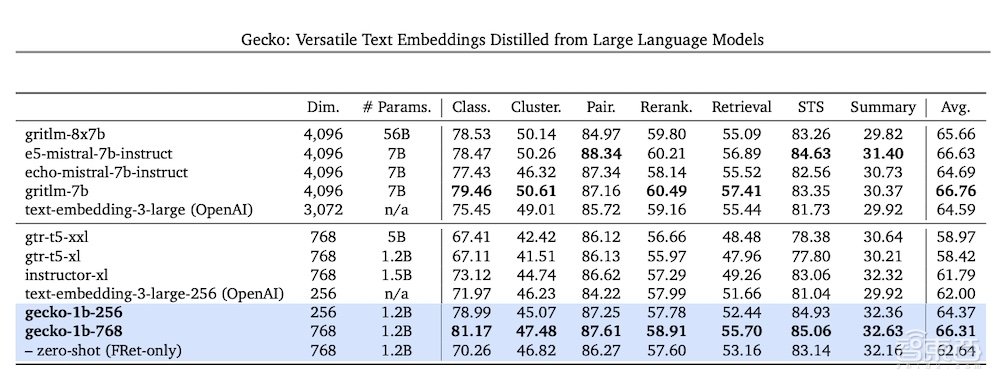 ▲在 MTEB 基准测试中,使用256维输出的”Text-embedding-004″(又名Gecko)优于所有较大的768维输出模型(来源:谷歌)
▲在 MTEB 基准测试中,使用256维输出的”Text-embedding-004″(又名Gecko)优于所有较大的768维输出模型(来源:谷歌)
谷歌实验室称这些是Gemini API 和Google AI Studio未来几周内的第一批改进,未来还将持续优化更多。
结语:开源闭源两手抓,谷歌加快落地大模型
无论是开源的大语言模型Gemma还是多模态大模型Gemini的改进,于同类模型而言都有着领先的功能特征。不断优化开源大模型彰显着谷歌在AI领域的技术实力,同时也为整个行业提供了重要的技术资源和参考;闭源大模型成员的增添,意味着对开发环境进行了大幅优化,以便考虑到技术研究人员的需求。
谷歌强调大模型的实用性以及输出的准确性,它还期望一个能共同塑造由人工智能驱动的内容创作和理解的未来,为推动人类AI技术的发展和应用做出了一份努力。
