








智东西(公众号:zhidxcom)
作者 | 香草
编辑 | 李水青
输入单个物体视频,就能获取任意拍摄视角的全视图3D动态视频了!
智东西7月25日消息,昨日晚间,AI独角兽Stability AI推出其首个视频生视频(video-to-video)模型Stable Video 4D(SV4D),该模型能够将单个物体的视频输入,转换为8个不同视角的多个新视频,用户可任意指定摄像机角度。

▲输出全视图视频演示
目前,SV4D可以通过一次推理,在约40秒内生成8个视图的各5帧视频,整个4D优化需要20-25分钟。该模型已在Hugging Face上开源,适用于游戏开发、视频编辑、虚拟现实(VR)等场景的应用,可免费用于研究、非商业用途。
SV4D技术论文也同步发表,研究团队由Stability AI和东北大学学者组成,其中详细解读了该模型的框架结构、优化策略、测评结果等。

▲SV4D论文
Stability AI从2019年成立起,就致力于研发文字、图像、音频、视频等多个领域的开源模型,其在2022年跻身独角兽行列。虽然从去年以来它就陷入寻求卖身、核心技术团队离职、CEO卸任等困境,但即便如此也没能打断其不断开源新模型的脚步。
今年6月,Stability AI在债台高筑的情况下获得前Facebook总裁Sean Parker等投资者的8000万美元注资,并迎来了新任CEO——前Weta FX(维塔数码)负责人Prem Akkaraju。自Akkaraju上任以来,Stability AI在一个月内又接连发布聊天机器人Stable Assistant、音频生成模型Stable Audio Open以及此次发布的SV4D。
论文地址:
https://arxiv.org/abs/2407.17470
Hugging Face开源地址:
https://huggingface.co/stabilityai/sv4d
一、基于SVD升级4D框架,40秒生成多视角视频
SV4D主要用在3D模型的多视角视频生成。其输入为单个物体的单视角视频,输出为同一物体8个不同角度的多视角视频。
据介绍,该模型以图生视频模型Stable Video Diffusion(SVD)为基础,实现了从图生视频到视频生视频的能力飞跃。
具体运行时,用户首先上传一段视频并指定所需的摄像机角度,SV4D会根据指定的摄像机视角生成8个新视角视频,从而提供拍摄对象的全面、多角度视频。生成的视频可用于优化拍摄对象的动态表示,适用于游戏开发、视频编辑、VR等场景的应用。

▲SV4D输入输出
目前,SV4D仍处于研究阶段,可在40秒左右的时间内生成8个视角各5帧视频,整个4D优化流程约耗时20-25分钟。
以往用于多视角视频生成的方法,通常需要从图像扩散模型、视频扩散模型和多视图扩散模型的组合中进行采样,而SV4D能够同时生成多个新视图视频,大大提高了空间和时间轴的一致性。此外,该方法还可以实现更轻量的4D优化框架,而无需使用多个扩散模型进行繁琐的分数蒸馏采样。

▲SV4D与其他方法对比
与其他方法相比,SV4D能够生成更多样的多视图视频,且更加细致、忠实于输入视频,在帧和视图之间保持一致。
SV4D是Stability AI推出的首个视频到视频生成模型,已在Hugging Face上开源发布。Stability AI称,团队仍在积极完善该模型,使其能够处理更广泛的现实世界视频,而不仅仅是用于训练的合成数据集。
二、混合采样保持时间一致,4D生成全面超基准线
SV4D的技术论文也同步发表,其中详细解读了该模型的框架结构。
总的来说,SV4D是一个用来生成动态3D对象新视图视频的统一扩散模型。给定一个单目参考视频,SV4D为每个视频帧生成在时间上一致的新视图,然后使用生成的新视图视频来有效地优化隐式4D表示,而不需要基于分数蒸馏采样的优化。
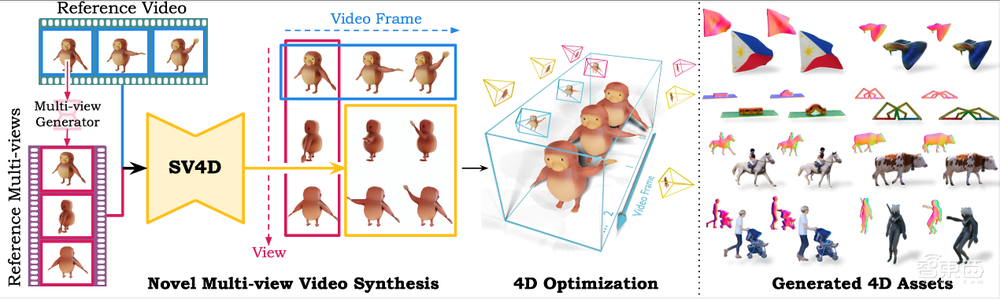
▲SV4D框架概述及生成的4D资产
SV4D的模型结构如下图。基于相机条件,SV4D将相机视点的正弦嵌入传递给UNet中的卷积块,并在空间和视图注意力块中,使用输入视频进行交叉注意力条件设定。为了提高时间一致性,SV4D引入了一个额外的运动注意力块,并以第一帧的相应视图为交叉注意力条件。
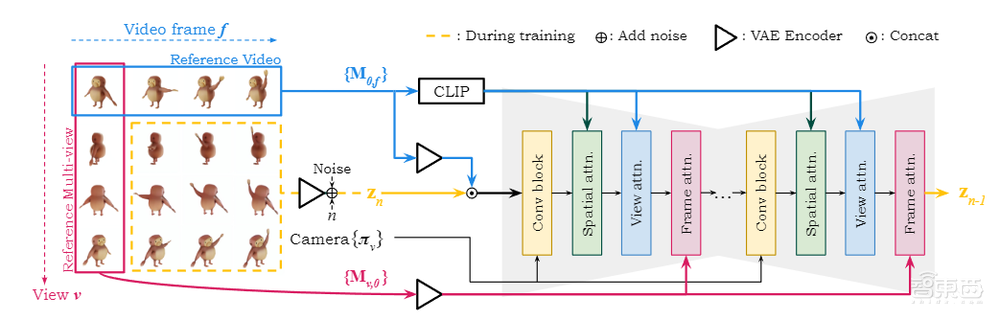
▲SV4D模型结构
为了在保持时间一致性的同时,扩展生成的多视图视频,研发团队在推理过程中提出了一种新颖的混合采样策略。
首先,SV4D采样一组稀疏的锚定帧,然后将锚定帧作为新的条件图像,对中间帧进行密集采样/插值。为了确保连续生成之间的平滑过渡,SV4D在密集采样期间,交替使用时间窗口内的第一帧前向帧或最后一帧后向帧进行条件设置。
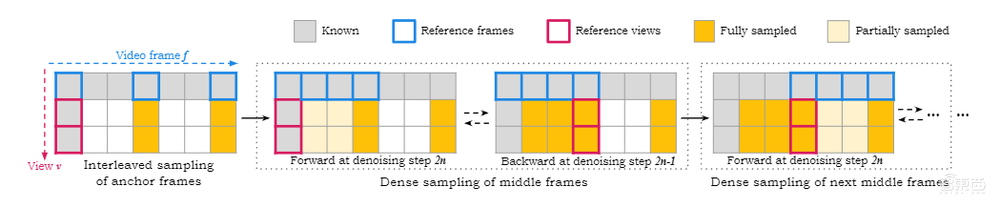
▲SV4D模型采样
在框架的优化上,SV4D使用参考多视图图像的第一帧,优化由多分辨率哈希网格以及密度和颜色多层感知机(MLP)表示的静态NeRF,然后解冻时间变形MLP,并使用随机采样的视图和帧来优化动态NeRF。
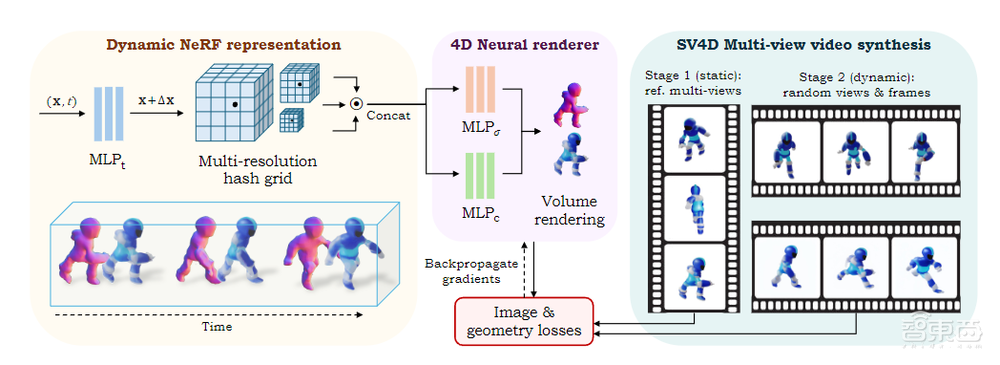
▲优化框架概述
为了训练统一的新视图视频生成模型,SV4D研发团队从现有的Objaverse数据集中整理了一个动态3D对象数据集。在多个数据集上的实验结果和用户研究表明,与之前的工作相比,SV4D在新视图视频合成以及4D生成方面具有最先进的性能。
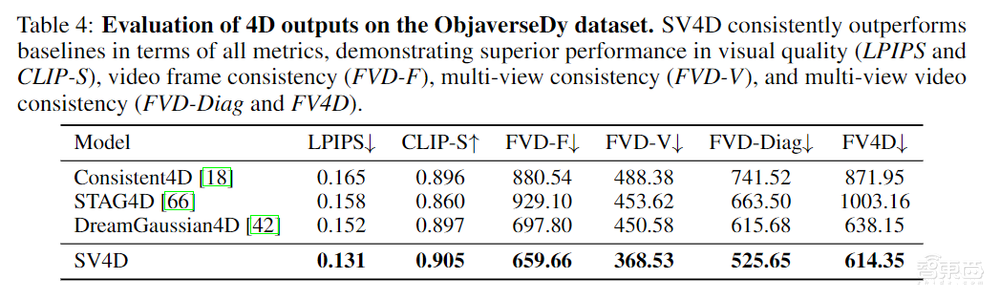
▲ObjaverseDy数据集上4D输出的评估
在ObjaverseDy数据集上的4D输出评估中,SV4D在所有指标方面优于基线,在视觉质量(LPIPS和CLIP-S)、视频帧一致性(FVD-F)、多视图一致性(FVD-V)和多视图视频一致性(FVD-Diag和FV4D)方面都击败了此前的模型。
结语:Stability AI多模态再添新布局
Stability AI以文生图开源模型起家,在文本、视频、3D等多个模态上都有所布局。此次开源SV4D,是其在3D+视频生成两个方向上的共同进展。
尽管该模型目前仍处于前期研究阶段,但它在各指标表现出的优秀能力和模型架构上的创新思路,为未来的发展开辟了广阔的前景。随着模型的迭代和优化,SV4D有望在游戏、VR等更多领域的应用发挥重要作用。
