








智东西(公众号:zhidxcom)
作者 | 香草
编辑 | 李水青
AI视频生成赛道风起云涌,国内外新颖的文生、图生视频产品层出不穷。在各大厂商的“内卷”之下,当下的视频生成模型各方面已经接近“以假乱真”的效果。
但与此同时,大部分视频生成模型的准确程度、遵循指令的能力还有待提升,生成视频仍然是一个“抽卡”的过程,往往需要用户生成许多次,才能获得符合需求的结果。这也造成算力成本过高、资源浪费等问题。
如何提升视频生成的精准度,减少“抽卡”次数,利用尽可能少的资源来获取符合需求的视频?
智东西8月3日报道,阿里团队近日推出视频生成模型Tora,能够根据轨迹、图像、文本或其组合,简单几笔快速生成精确运动控制的视频,同时也支持首尾帧控制,让视频生成的可控性又上了一个阶梯。
Tora是首个面向轨迹的DiT框架模型,利用DiT的可扩展性,Tora生成的物体运动不仅能精确地遵循轨迹,而且可以有效地模拟物理世界动态,相关论文已于8月1日发布在arXiv上。

▲Tora论文
Tora目前仅提供视频演示,其项目主页显示,其后续将发布在线Demo和推理、训练代码。
论文地址:
https://arxiv.org/abs/2407.21705
项目地址:
https://ali-videoai.github.io/tora_video/
一、三种模态组合输入,精准控制运动轨迹
Tora支持轨迹、文本、图像三种模态,或它们的组合输入,可对不同时长、宽高比和分辨率的视频内容进行动态精确控制。
轨迹输入可以是各种各样的直线、曲线,其具有方向,不同方向的多个轨迹也可以进行组合。例如,你可以用一条S型曲线控制漂浮物的运动轨迹,同时用文字描述来控制它的运动速度。下面这个视频中,所使用的提示词用到了“缓慢”、“优雅”、“轻轻”等副词。
同一条轨迹也可以在一个轴线上反复运动,生成来回摇动的画面。
在同一张图上,绘制不同的轨迹也可以让Tora生成不同运动方向的视频。
而基于同一个轨迹输入,Tora会根据主体的区别生成不同的运动方式。
与目前常见的运动笔刷功能有所不同的是,即使没有输入图像,Tora也可以基于轨迹和文本的组合,生成对应的视频。
例如下面这个视频中的1、3两个视频,就是在没有初始帧,只有轨迹和文字的情况下生成的。
Tora也支持首尾帧控制,不过这个案例只以图片形式出现在论文里,没有提供视频演示。

▲Tora首尾帧控制
那么,只有文本、图像两个模态输入的话,能否实现同样的效果呢?带着这个疑问,我尝试将相同的初始帧和提示词输入其他AI视频生成器。
下面视频中从左到右、从上到下依次为Tora、Vidu、清影、可灵生成的视频。可以看到,当轨迹为直线时,无轨迹输入的视频生成勉强还算符合需求。
但当需要的运动轨迹变为曲线,传统的文本+图像输入就难以满足需求。
二、基于OpenSora框架,创新两种运动处理模块
Tora采用OpenSora作为其基本模型DiT架构,OpenSora是AI创企潞晨科技设计并开源的视频生成模型框架。
为了实现基于DiT的轨迹控制视频生成,Tora引入了两个新型运动处理模块:轨迹提取器(Trajectory Extractor)和运动引导融合器(Motion-guidance Fuser),用于将提供的轨迹编码为多级时空运动补丁(motion patches)。
下图展示了Tora的整体架构。这一方法符合DiT的可扩展性,能够创建高分辨率、运动可控的视频,且持续时间更长。
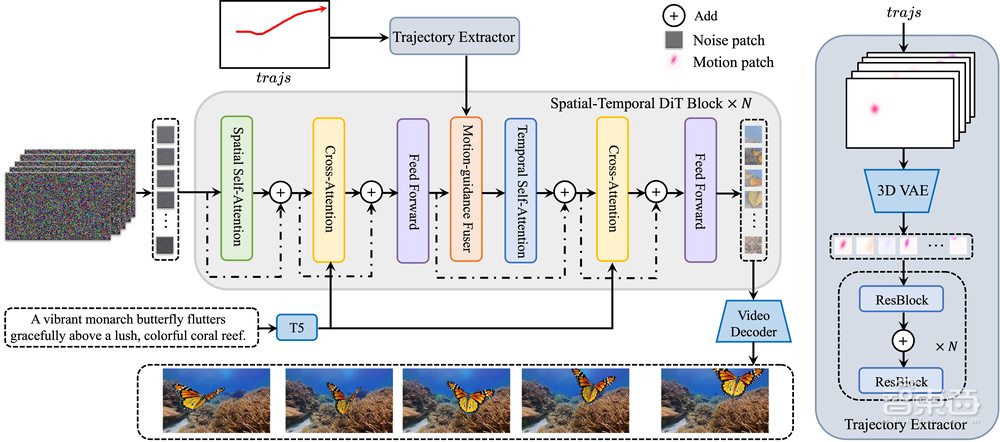
▲Tora整体架构
其中,轨迹提取器采用3D运动VAE(变分自编码器),将轨迹向量嵌入到与视频补丁(video patches)相同的潜在空间中,可以有效地保留连续帧之间的运动信息,随后使用堆叠的卷积层来提取分层运动特征。
运动引导融合器则利用自适应归一化层,将这些多级运动条件无缝输入到相应的DiT块中,以确保视频生成始终遵循定义轨迹。
为了将基于DiT的视频生成与轨迹相结合,作者探索了三种融合架构的变体,将运动补丁注入到每个STDiT块中,其中自适应范数(Adaptive Norm)展示了最佳性能。
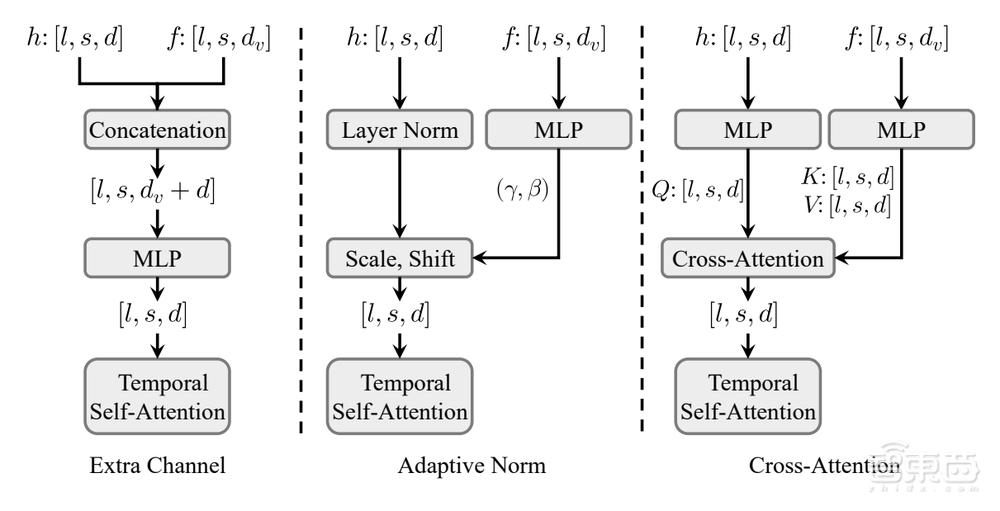
▲运动引导融合器的三种架构设计
在具体的训练过程中,作者针对不同输入条件采取了不同的训练策略。
在轨迹训练中,Tora使用两阶段训练方法进行轨迹学习,第一阶段从训练视频中提取密集光流,第二阶段根据运动分段结果和光流分数,从光流中随机选择1到N个对象轨迹样本,最后应用高斯滤波器进行细化。
在图像训练中,Tora遵循OpenSora采用的掩码策略来支持视觉调节,在训练过程中随机解锁帧,未屏蔽帧的视频补丁不受任何噪声的影响,这使得Tora能够将文本、图像和轨迹无缝集成到一个统一的模型中。
与先进的运动可控视频生成模型进行定量比较时,随着生成帧数的增加,Tora比基于UNet的方法具有越来越大的性能优势,保持较高的轨迹控制的稳定度。

▲Tora与其他可控视频生成模型对比
例如基于同一输入,Tora生成的视频比DragNUWA、MotionCtrl模型生成的更加平滑,对运动轨迹的遵循也更准确。
三、“期货”已兑现,阿里持续布局AI视频
AI视频生成玩家们打得如火如荼,阿里也一直在持续围攻AI视频赛道。比起Sora等主攻视频生成长度和质量的通用模型,阿里团队的项目似乎更注重于算法在不同视频生成形式上的具体应用。
今年1月,通义千问上线了“全民舞王”,凭借“兵马俑跳科目三”出圈了一把;2月,阿里发布肖像视频生成框架EMO,一张图就能让照片里的人开口说话。
当时智东西统计了阿里在AI视频上的布局,其在4个月内连发了至少7个新项目,覆盖文生视频、图生视频、人物跳舞、肖像说话等方向。(国产神级AI登场!高启强化身罗翔,蔡徐坤变Rap之王,还跟Sora联动)
如今又半年过去,EMO已经从“期货”变成通义App中的“全民唱演”功能,人人可用。阿里也发布了更多AI视频项目。
1、AtomoVideo:高保真图像到视频生成
AtomoVideo发布于3月5日,是一个高保真图生视频框架,基于多粒度图像注入和高质量的数据集及训练策略,能够保持生成视频与给定参考图像之间的高保真度,同时实现丰富的运动强度和良好的时间一致性。

▲AtomoVideo生成视频效果
项目主页:https://atomo-video.github.io/
2、EasyAnimate-v3:单张图像+文本生成高分辨率长视频
EasyAnimate是阿里在4月12日推出的视频生成处理流程,并在短短3个月内迭代到v3版本。它通过扩展DiT框架引入了运动模块,增强了对时间动态的捕捉能力,确保生成视频的流畅性和一致性,可生成不同分辨率6秒左右、帧率24fps的视频。

▲EasyAnimate v3生成视频效果
项目主页:https://github.com/aigc-apps/EasyAnimate
结语:AI视频生成可控性再上一层
在AI视频生成时长、质量已经达到一定程度之际,如何让生成的视频更可控、更符合需求,是当下的重要命题。
在精准度、可控性和资源利用效率等方面的持续优化下,AI视频生成产品的使用体验将迎来新的阶段,价格也会更加亲民,让更多创作者参与进来。
