








2024年已行进尾声,但对于生成式AI而言,这又是波澜壮阔的一年。Sora掀起视频生成热潮,多模态世界模型的研究热度渐起。更具革命性的推理模型o1悄然出世,带来的思维链CoT+强化学习这一新范式,正推动生成式AI迈入新的阶段。
大语言模型仍在狂飙,但价格战、营销战硝烟燃起,融资热度正在降温。不过行业赋能持续进行,应用层的兴起更加受到期待。同时,大模型向边端下沉的趋势日趋明显,AI手机、AI PC等AI硬件纷纷站上风口。GPT-4o的出现,将轻量化模型和端侧大模型推向新高度之余,端侧设备的交互革新也有了前进方向。不止AI硬件,大模型驱动下的具身智能更是热度空前,人形机器人正开启星辰大海。
作为支撑大模型运行以及生成式AI应用开发的关键,AI Infra走到了台前,从智算集群到基础软件,发展势头强劲,但挑战不少。
在上述背景下,2024中国生成式AI大会(上海站)「GenAICon 2024」将于12月5-6日在上海中星铂尔曼大酒店盛大举办。中国生成式AI大会已成功举办两届,迅速成长为国内生成式AI领域最具影响力的产业峰会之一。
此次也是中国生成式AI大会首次登陆上海举办。大会由智一科技旗下智能产业第一媒体智东西、AI与硬科技知识分享社区智猩猩共同发起主办。上海市人工智能行业协会为大会的指导单位。
大会上海站以“智能跃进 创造无限”为主题,50+位嘉宾将带来致辞、演讲、报告和对话讨论,基于前瞻性视角解构和把脉生成式AI的技术产品创新、商业落地解法、未来趋势走向与前沿研究焦点。
上海站由“主会场峰会+分会场研讨会+展览区”组成。主会场将进行大模型峰会、AI Infra峰会,分会场将进行端侧生成式AI技术研讨会、AI视频生成技术研讨会和具身智能技术研讨会。展览区则紧邻会场门口设置,14家企业将进行技术产品展示。
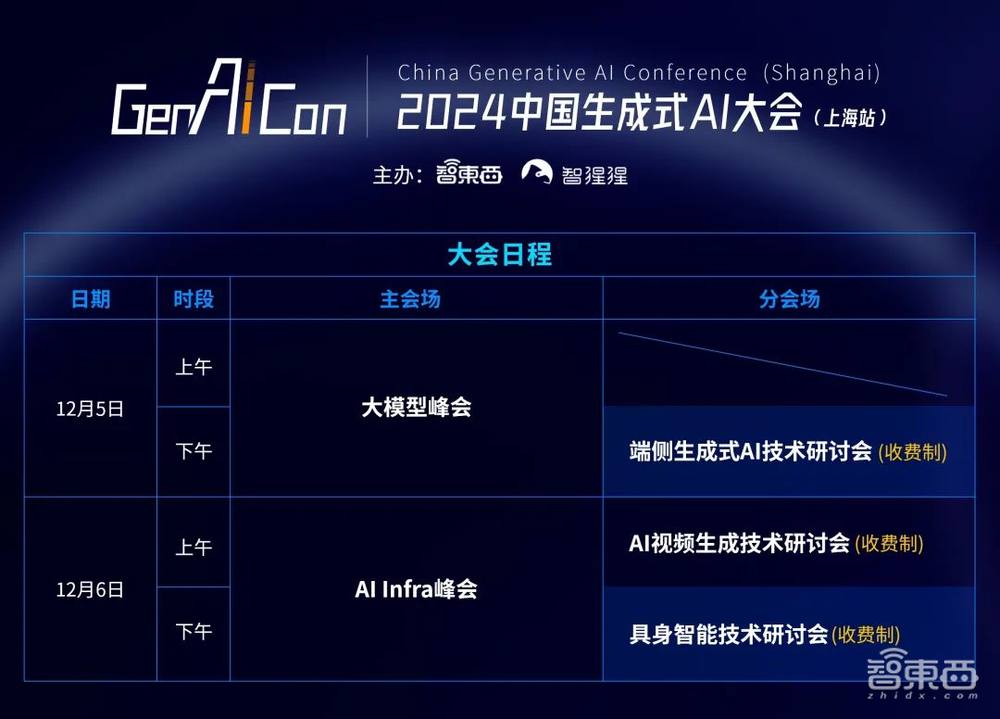
其中,端侧生成式AI技术研讨会将于12月5日下午进行,AI视频生成技术研讨会于12月6日上午进行,具身智能技术研讨会于12月6日下午进行。
目前,分会场三场研讨会邀请到17位来自学术界和工业界的青年学者和技术专家与会,并带来主题报告和圆桌Panel。今天将为大家正式揭晓分会场研讨会的完整议程。
一、分会场研讨会完整议程

二、端侧生成式AI技术研讨会报告介绍
本次研讨会将于12月5日下午进行,目前邀请到上海人工智能实验室博士后研究员罗根,西湖大学工学院助理教授王欢,联想集团首席研究员、联想研究院人工智能实验室研发总监师忠超,vivo AI全球研究院AI技术总监李方圆,爱芯元智智慧IoT事业部产品总监吴炜5位青年学者和技术专家带来报告。
主题报告环节结束后,商汤科技研究院模型计算部系统研究员雷丹将受邀参与并主持圆桌Panel。

报告嘉宾:上海人工智能实验室博士后研究员 罗根
报告主题:《多模态大模型的高效感知、建模与计算》
内容概要:近年来,多模态大模型的不断进步也对端侧设备的部署和使用提出了更大的要求。针对该问题,罗根博士将从感知、建模与计算三个方面进行深入探讨:在感知层面,主要介绍通过混合分辨率视觉融合实现高效的视觉感知;在建模层面,主要介绍通过内生视觉专家实现紧凑的一体化多模态建模;在计算层面,主要介绍通过混合深度计算实现稀疏的模型动态推理。

报告嘉宾:西湖大学工学院助理教授 王欢
报告主题:《神经网络剪枝、蒸馏在Efficient AI中的发展与应用》
内容概要:AI模型深刻改变了我们的生活,但这些模型无论是训练还是测试阶段都需要消耗大量资源,导致速度慢、能耗高、存储及运存冗余等问题,解决这些问题亟需提高AI模型的效能(Efficiency),因此需要Efficient AI。Efficient AI涉及软硬件、算法等多个维度的协同设计和优化,硬件不足时往往可以通过在算法上的改进来补齐短板。在算法层面,要想实现提高效能,需要解决两个问题:(1)效能如何提高,(2)性能如何保证。前者一般是通过缩小模型大小来实现,最具代表性的方法就是神经网络剪枝(Pruning);后者一般是通过重训练(Retraining)、微调(Fine-tuning)得到,最具代表性的方法就是知识蒸馏(Knowledge Distillation)。
在这次交流中,我将介绍剪枝和蒸馏的主要历史背景和当前研究现状,结合我的研究经历,重点介绍如何利用剪枝和蒸馏实现对神经辐射场(NeRF)、文生图(T2I)等任务进行效能提升。其中文生图加速的工作SnapFusion(NeurIPS’23)是世界上首个端上文生图时间小于2s、且性能可以对标SD-v1.5的模型。

报告嘉宾:联想集团首席研究员、联想研究院人工智能实验室研发总监 师忠超
报告主题:《联想AIPC端侧智能体》
内容概要:本次演讲将重点介绍联想AIPC端侧智能体的独特架构,旨在通过开发端侧智能体,显著提升端侧大模型在处理复杂任务和场景应用时的性能。我们将深入探讨联想端侧个人智能体如何结合大模型的关键能力定向增强与端侧异构加速技术,在设备资源有限的条件下达到卓越的性能。此外,本次演讲也将展示联想如何运用混合意图理解与复杂任务自动分解策略等创新方法,优化个人知识库及工具库的应用,进而为用户提供更智能、更个性化的服务体验。

报告嘉宾:vivo AI全球研究院AI技术总监 李方圆
报告主题:《智能手机的未来:端侧大模型重塑用户体验》
内容概要:手机是从早到晚伴随我们工作、学习、生活、娱乐最长时间的智能设备。在AIGC时代,现有的手机AI功能已无法满足用户对更高层次体验的追求,主要表现在单点功能与系统融合不够紧密、机械的被动执行缺乏主动性,通用的功能难以与用户个性化需求相结合等不足。手机终端大模型凭借其强大的语义理解、语言生成和逻辑推理能力,一方面能够大幅提升传统AI功能的准确性和效果,另一方面能够理解执行用户更加复杂的指令,结合用户使用手机的情景,提供更加主动、个性化的智能服务。
本次演讲,将分享vivo如何从传统的AI时代迈向大模型AI时代的技术演进之路。围绕记忆、端侧化、主动执行3个方面探索更懂用户、更懂手机、更加主动的个人智能的应用场景,并与大家揭秘背后的核心技术蓝心端侧大模型的构建思路与方案。

报告嘉宾:爱芯元智智慧IoT事业部产品总监 吴炜
报告主题:《多模态大模型在端侧的创新实践与挑战》
内容概要:随着大模型的发展,AI已从简单的图像分类识别功能,升级为对视频、音频、文字等多模态信息的整合分析,实现对内容更深刻的理解。多模态大模型已成为推动各行各业发展的重要力量。然而,要将大模型应用于端侧设备,面临着算力、带宽、功耗和成本之间的多重平衡挑战。爱芯元智致力于打造世界领先的AI芯片,积极布局多模态大模型,助力大模型在端侧的普及和高效部署。
本次演讲,将通过展示实际应用案例,探讨多模态大模型如何在更广泛的应用场景中发挥更大的价值。同时,还将与行业伙伴共同探索大模型在端侧应用的无限可能,推动“普惠AI,造就美好生活”的使命。
三、AI视频生成技术研讨会报告介绍
本次研讨会将于12月6日上午进行,目前邀请到中存算董事长陈巍,上海交通大学人工智能研究院助理教授晏轶超,新壹科技AI算法主任架构师李璋,井英科技联合创始人、CTO王健,旷视研究院高级研究员李华东5位青年学者和技术专家带来报告。
主题报告环节结束后的圆桌Panel,将由中存算董事长陈巍,上海交通大学人工智能研究院助理教授晏轶超,井英科技联合创始人、CTO王健,以及旷视研究院高级研究员李华东一起带来。

报告嘉宾:中存算董事长 陈巍
报告主题:《视频大模型架构对比及长序列模型加速》
内容概要:随着大模型技术的快速发展,视频大模型(VLM)正与短视频产业结合并迎来新的爆发机遇,逐渐成为互联网应用的热点。
本次分享从视频大模型与世界模型的角度,对比主流视频生成大模型架构,探讨视频生成的关键技术(包括NaViT、RADM等),分析视频生成类大模型的主要挑战与发展趋势;探讨内存墙(Memory Wall)和通信墙对视频大模型GPGPU/TPU集群训练和部署的挑战,并针对这类视频长序列模型的算力芯片级训练部署,结合具体项目给出软硬结合的解决方案与系统经验。

报告嘉宾:上海交通大学人工智能研究院助理教授 晏轶超
报告主题:《先验引导的三维数字人视频生成》
内容概要:“人”一直是视频生成的核心对象,面对大规模视频的生成需求,利用生成式人工智能技术产生高拟真,规模化的虚拟数字人正逐渐成为研究热点。三维高斯、大模型等技术在过去一年快速发展,并与数字人技术进行了广泛结合,本次报告将从数字人重建、生成、编辑等方向介绍数字人视频生成领域的最近进展,对三维数字人技术的发展趋势进行探讨。

报告嘉宾:新壹科技AI算法主任架构师 李璋
报告主题:《视频垂直大模型在智能数字人生成中的应用》
内容概要:在生成式AI技术蓬勃发展的背景下,智能数字人已成为内容创作、虚拟助手和人机交互等领域的重要应用之一。然而,传统生成模型在高精度、多模态的智能数字人生成中仍面临诸多挑战。为此,垂直领域的大模型提供了一条全新路径。
本次演讲,首先会介绍从通用大模型到垂直大模型的演进,之后将着重讲解新壹视频大模型的整体架构设计及其在数字人视频生成与优化中的核心技术突破;此外,还将对智能数字人生成的技术难点,包括数字人生成中实现自然语言驱动动作与表情生成的关键技术等进行深入分析,并分享视频垂直大模型驱动的智能数字人在相关领域的典型应用案例。

报告嘉宾:井英科技联合创始人、CTO 王健
报告主题:《AI短剧拐点背后的技术突破》
内容概要:自今年2月OpenAI发布Sora起,视频生成大模型成为了热点方向。但其具体落地的业务场景却一直不明确。近期,井英科技通过视频生成模型实现了100分钟以上短视频的制作,并成功实现了用户付费观看的商业模式。
本次分享将介绍AI短剧从最初的不可行到现如今可行的关键技术突破,并探讨了除视频生成大模型之外的其他关键技术进展。

报告嘉宾:旷视研究院高级研究员李华东
报告主题:《可控人物视频生成》
内容概要:短视频、影视和游戏动画创作正在迅速发展。然而,传统的视频制作过程耗时耗力,通常需要大量的人工后期编辑。视频生成大模型算法提供了一种低成本、高效的高质量视频内容生成解决方案。但视频生成算法生成的内容可控性不足,限制了其实际应用的有效性。因此,如何实现视频生成内容的可控性仍是一大关键挑战。
在本次报告中,我将介绍 MegActor 系列工作,这是一种支持混合模态控制的人像视频生成算法。该算法支持角色自定义(包括真实人物、二次元人物和游戏人物等),并能够通过视频、音频和文本输入实现单独和混合控制。其功能涵盖了控制角色说话、唱歌和生成表情动画等。MegActor 系列是社区内的首个开源可控人物视频生成大模型,将持续优化以推动技术的不断发展。
四、具身智能技术研讨会报告介绍
本次研讨会将于12月6日下午进行,目前邀请到上海人工智能实验室青年科学家王泰,上海科技大学信息科学与技术学院助理教授、博士生导师顾家远,上海交通大学在读博士、穹彻智能实习研究员吕峻,国地共建具身智能机器人创新中心数据智能负责人李广宇,哈尔滨工业大学计算学部在读博士王雪松,中国科学院空天信息创新研究院特别研究助理姚方龙6位青年学者和技术专家带来报告。
主题报告环节结束后的圆桌Panel,也将由上述6位嘉宾一起带来。

报告嘉宾:上海人工智能实验室青年科学家 王泰
报告主题:《大规模具身多模态三维感知》
内容概要:近年来,大模型的成功以及模仿学习、强化学习等方法的突破持续推动着具身智能的快速发展。但这一领域仍然面临着数据匮乏的核心问题,大规模训练和评测仍存在客观瓶颈。生成式 AI 的进展为解决这一问题提供了重要路径。
本报告将聚焦于三维场景中具身多模态感知相关的具体任务,详细介绍团队利用多模态大模型的生成能力设计三维多模态数据的自动化标注管线,从而形成大规模三维物体、场景在不同粒度全方位的语料标注,构建带有显式三维建模和空间感知能力的具身感知基础模型,并最终利用大模型实现更符合人类判断的自动化评测。最后,报告将展望生成式 AI 在机器人交互数据方面的巨大潜力,同时探讨其潜在的局限性。

报告嘉宾:上海科技大学信息科学与技术学院助理教授、博士生导师 顾家远
报告主题:《服务于具身智能的仿真评估平台和数字资产》
内容概要:在具身智能领域,通用机器人决策模型的开发取得了显著进展。然而,收集真实世界的训练数据和对这些模型进行真实环境下的评估仍然成本高昂。仿真技术提供了一种可行的替代方案,但其有效性高度依赖于多样且逼真的数字资产。传统上,这些资产主要由游戏产业创建,但随着具身智能的发展,对高质量数字资产的需求激增,以提高仿真环境的多样性和逼真度。这引发了一系列关键问题:这些资产的真实程度应达到何种水平?我们如何有效地创建这些仿真环境?在此过程中,哪些工具是必不可少的?
在本次报告中,我将介绍最近的工作SimplerEnv,一个专为评估基于真实世界数据训练的决策模型而开发的仿真环境平台。该平台支持对多种通用机器人操作模型的评估,如RT-1和Octo。此外,我还将讨论另一个研究成果Point-SAM,一个3D原生工具,能够对三维部件和物体进行交互式分割。理解物体的功能性部件对具身智能的研究至关重要,这一工具为此提供了重要支持。

报告嘉宾:上海交通大学在读博士、穹彻智能实习研究员 吕峻
报告主题:《Real2Sim2Real:一种基于多信息源的具身操作技能开发系统》
内容概要:数据是具身智能在今天面临的核心问题之一。如何利用来自不同信息源的数据,例如仿真数据、人类演示数据、静态视觉数据等,构建数据金字塔,共同实现具身操作技巧开发,降低对真实机器人数据的依赖与数据成本成为值得关注的课题。过去几年,我们构建了包含Real2Sim、Learn@Sim、Sim2Real模块的具身智能系统,旨在通过各类感知技术对现实物理世界进行建模,基于建模在人类演示数据、自然语言提示词等的指导下于仿真环境中学习开发特定的机器人操作技巧,并将仿真中学习到技能迁移到真实环境中。相关成果发表在IJRR、RSS、CoRL、ICRA等期刊与会议上,曾获选RSS 2023 Best System Finalist。

报告嘉宾:国地共建具身智能机器人创新中心数据智能负责人 李广宇
报告主题:《数据视角下的具身操作》
内容概要:数据稀缺是目前困扰具身操作研究的共识。从各种机器人整机、机械臂、灵巧手等本体厂家纷纷推出的遥操作采集系统,到以UMI为代表的低成本采集设备,再到各类人类操作动作捕捉方案,以及各种仿真数据合成方法。如何高效的获取具身操作数据,已经成为学术界和产业界的研究重点。
另一方面,针对不同途径获取的数据,具身数据金字塔的概念已经广为传播:下层是数据量大、获取成本低,但单位价值较低的互联网数据和仿真合成数据;顶层是采集成本昂贵,单位价值高的真机遥操作数据;而中间层是介于真机遥操作和仿真合成之间的,人类动作捕捉数据和仿真遥操作数据。同时当前的机器人数据中,本体构型丰富多样,传感器配置各异。如何有效融合多种来源,多种本体的具身数据,也是研究者和工程师的关注点。
本次报告中,我将梳理具身数据方向的各种技术路线,并介绍具身智能国创中心在数据方面的进展,包括数据采集和训练基地建设情况、数据集开源开放情况,以及一些围绕数据融合方向的探索和尝试。

报告嘉宾:哈尔滨工业大学计算学部在读博士 王雪松
报告主题:《具身智能大模型研究的关键问题与展望》
内容概要:随着深度学习、大模型技术的突破性进展,人工智能的发展从感知智能和认知智能,逐步向能够与真实物理环境进行交互的具身智能阶段发展,并在大模型在多种任务上的强大泛化能力和人形机器人对于人类社会场景的适应能力的基础上,有望通过具身智能的发展,最终实现通用人工智能。不过,具身智能为我们带来希望的同时,也更多的带来了挑战,机器人如何感知世界、理解世界?如何拥有对自己行为的认知?如何高效合理的运动?等等。
本次报告将从大模型技术和人形机器人技术是如何推动具身智能发展的角度进行切入,阐述当前大模型技术在解决具身智能问题时的诸多不足,进而详解具身智能大模型在感知、规划、导航、乃至机器人操控方面有哪些亟待研究的关键问题,同时也将对未来具身智能如何更好发展做出展望。

报告嘉宾:中国科学院空天信息创新研究院特别研究助理 姚方龙
报告主题:《万物具身:耦合空间智能与具身智能的复空间具身体系》
内容概要:空间智能旨在开发理解三维物理世界的模型,模拟物体物理特性、空间位置和功能,具身智能通过赋予智能“身体”,与环境交互反馈中实现智能增长和环境自适应,二者既有区别又相互补充。本报告旨在尝试联结空间智能与具身智能,构思出“万物具身(Embodiment-of-Objects)”概念,设计了复空间具身体系(Multiverse Embodied System)计算范式,探索了“超图+空天世界模拟器+空天世界模型”的研究路线,初步形成思维超图引导的智能体世界模型、异质超图引导的智能体关联导航、时空超图引导的智能体预测规划等关键技术,推动从单体智能向空天地海任务、环境、场景耦合的体系智能演进。
五、报名进入最后阶段,立即抢票参加研讨会
分会场三场研讨会主要面向大会购票用户及定向邀请的用户开放。
希望到现场参加研讨会的朋友,可以扫描下方二维码,添加小助手“泡泡”进行咨询。已添加过“泡泡”的老朋友,给“泡泡”私信,发送“GenAI24”即可。

