








智东西(公众号:zhidxcom)
作者 | ZeR0 程茜
编辑 | 漠影
掀起视频大模型风暴的Sora,终于正式发布!
智东西12月10日报道,今日凌晨,OpenAI推出文生视频模型Sora的新版本Sora Turbo,称其比2月预览的Sora模型快得多。

Sora可生成最高1080p分辨率、最长20秒、16:9 / 1:1 / 9:16 画面比例的视频,支持用户输入文字或上传图像,并上线全新UI界面,以便对生成视频进行修改、创建、扩展、循环、混合,或用文本生成全新的内容。

OpenAI在Sora.com上发布一个独立产品,免费提供给ChatGPT Plus和Pro用户。
Plus用户每月最多可以生成50个480p分辨率视频,或更少的720p分辨率、5秒视频,对应月费20美元(折合人民币145元)。
Pro订阅者则最多可生成500个视频,并支持20秒时长、1080p分辨率,可下载无水印版视频,对应月费200美元(折合人民币1450元)。
平摊下来生成一个视频花2.9元。
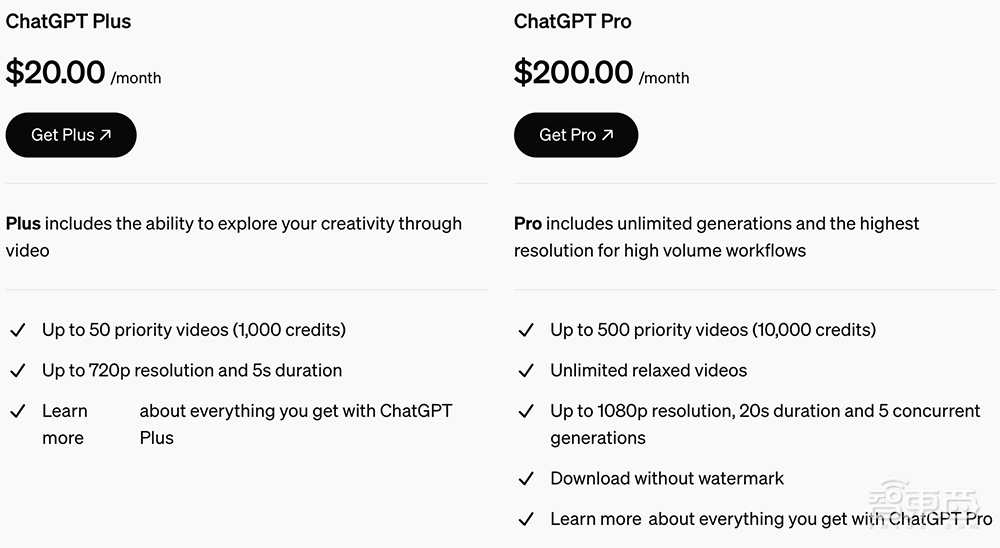
ChatGPT Plus和Pro每月分别为用户提供1000和10000积分。其中480p视频需要20-150个积分,720p视频需要30-540个积分,1080p视频需要100-2000个积分。Pro用户则享受无限量的relaxed视频。
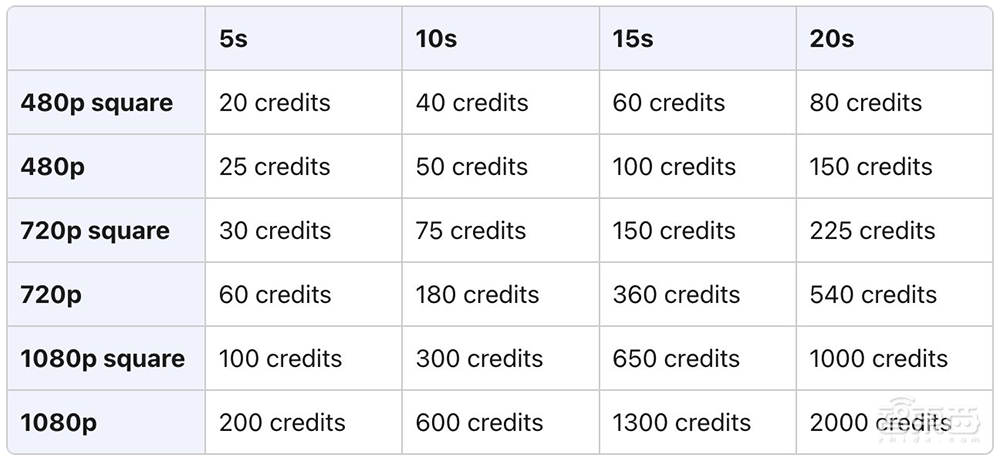
OpenAI正在为不同类型的用户制定不同定价,计划于明年初推出。
Sora一发布,ChatGPT氪金党们立即疯玩起来,纷纷在社交平台上晒出自己的第一个Sora生成视频大作。
例如下面这个新闻播报视频,虽然最终生成的视频中有一堆乱码文本,但视频画面切换的节点、文字滚动条、新闻风格镜头……这些都是Sora自主完成的,并且新闻主播的形象也十分逼真。

还有此前体验许久的艺术家,直接用Sora生成了一个1分38秒的MV。
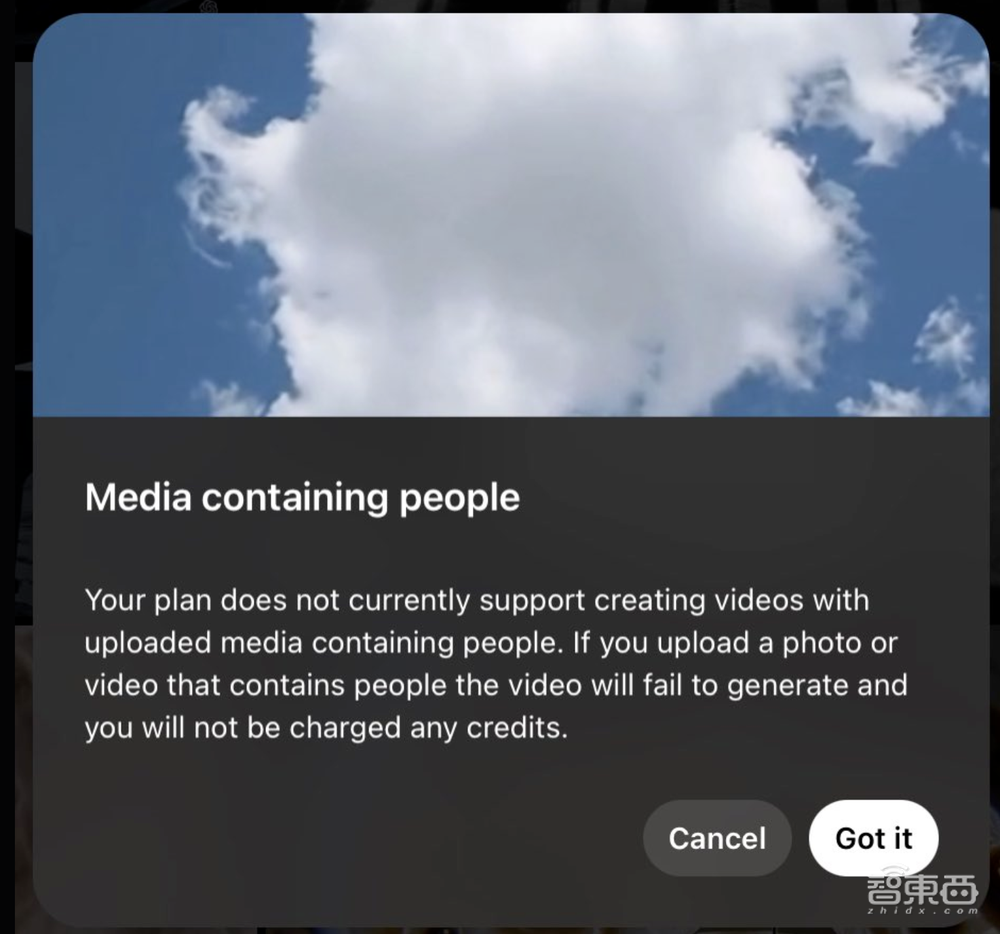
不过有网友发现,同为付费用户,ChatGPT Plus并不能生成带有人物的视频,只有ChatGPT Pro才可以。
服务器很快就火爆到进不去了。
OpenAI联合创始人兼CEO Sam Altman转发了Sora团队技术人员关于注册被禁用的帖子:“需求高于预期,注册将被禁用,生成将在一段时间内变慢。尽力而为。”
他还抽空发文恭喜谷歌刚刚发布的量子计算芯片Willow。
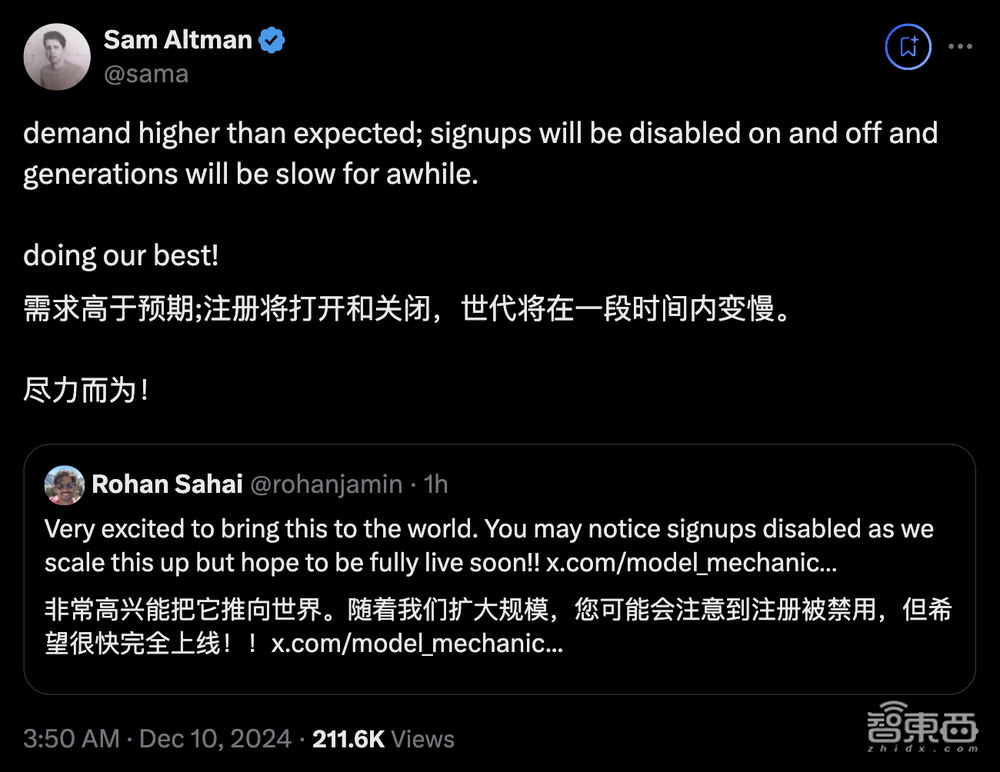 ▲阿尔特曼回应Sora注册被暂时禁用
▲阿尔特曼回应Sora注册被暂时禁用
一、Sora专属页面上线:预设风格、多种选项、社区分享
OpenAI开发了新的界面,以便更轻松地使用文本、图像和视频提示Sora。
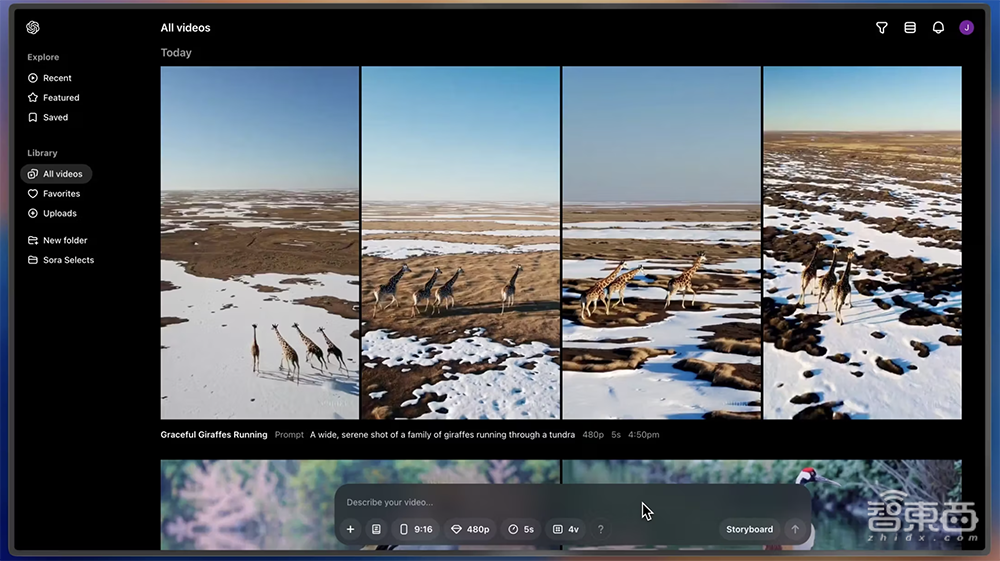
页面下方有输入框,可以输入想要生成视频的文字描述,并提供“预设”、“屏幕比例”、“分辨率”、“时长”、“变体”等选项。如果鼠标移到“?”图标,会显示生成视频所需消耗的积分值。
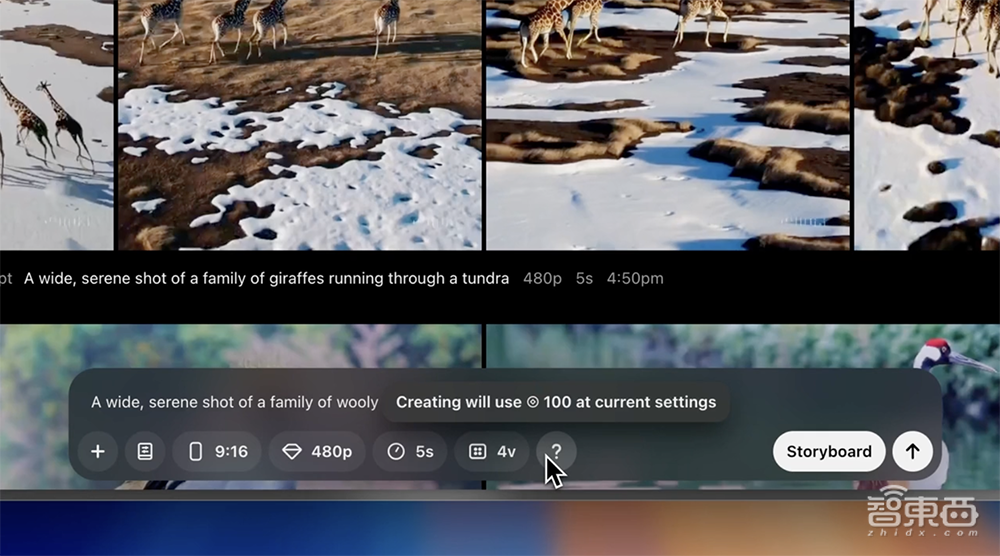
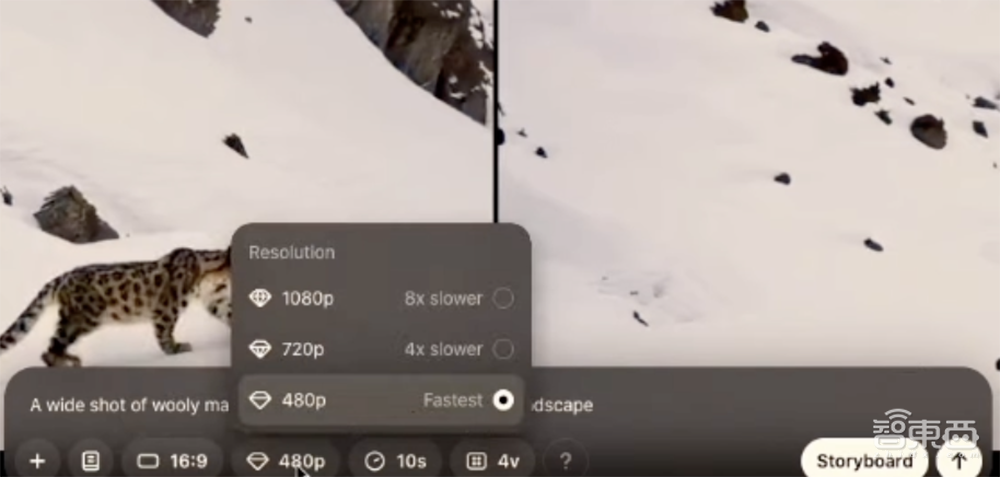
画面比例可选16:9、1:1、9:16。分辨率可选1080p(慢8倍)、720p(慢4倍)、480p(最快)。时长可选20秒、15秒、10秒、5秒。一次可生成1个、2个或4个视频变体。
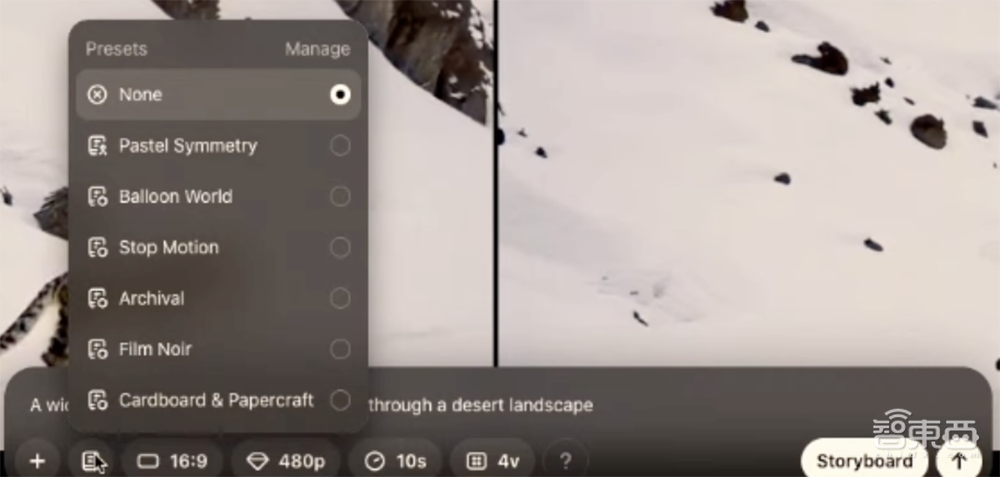
预设有6个选项。
点击“Create”即可创建视频。
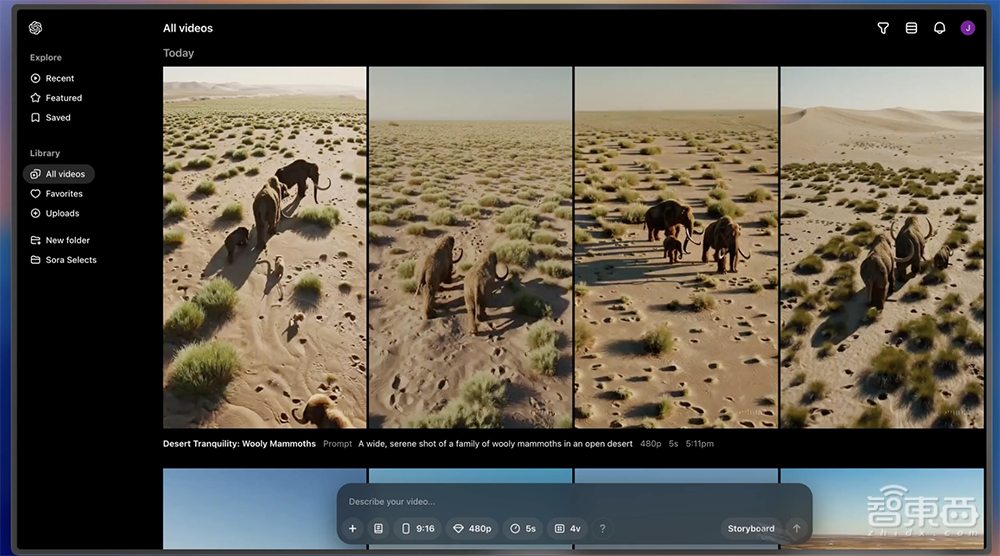
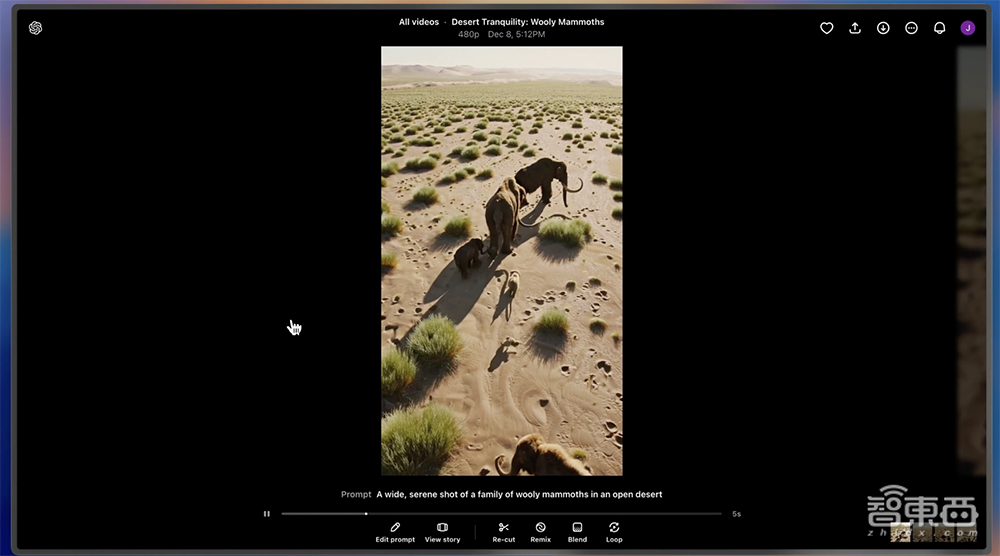
打开每个视频,底部还能进一步编辑提示词、观看故事、Re-cut(重剪辑)、Remix(基于此修改或创建新视频)、Blend(两个视频无缝过渡)和Loop(无缝循环播放)。
页面右上角有“喜欢”、“分享”、“下载”等选项。
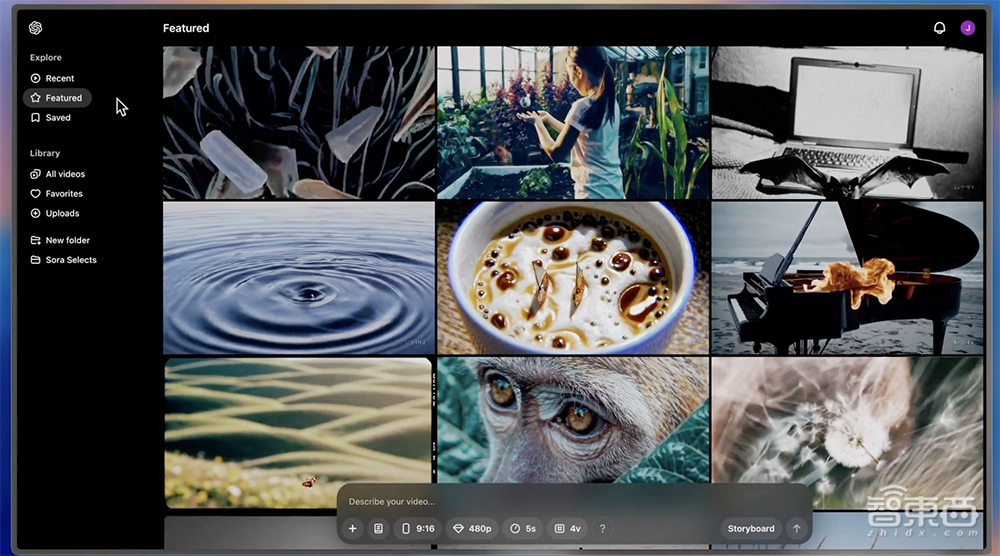
OpenAI还提供精选和最新动态,不断更新社区的创作。点击页面左侧Featured,可看到分享的作品。
点击页面右上方账户,可以看到视频教程。
二、画面元素丝滑替换,逐帧分镜头讲故事超便捷
具体来看看Sora不同功能的效果。
1、Remix:替换、删除或重构视频中的元素
你可以输入指令,要求Sora生成的视频反复修改画面元素。有“强”、“中”、“微”、“定制”四种Remix强度选项。
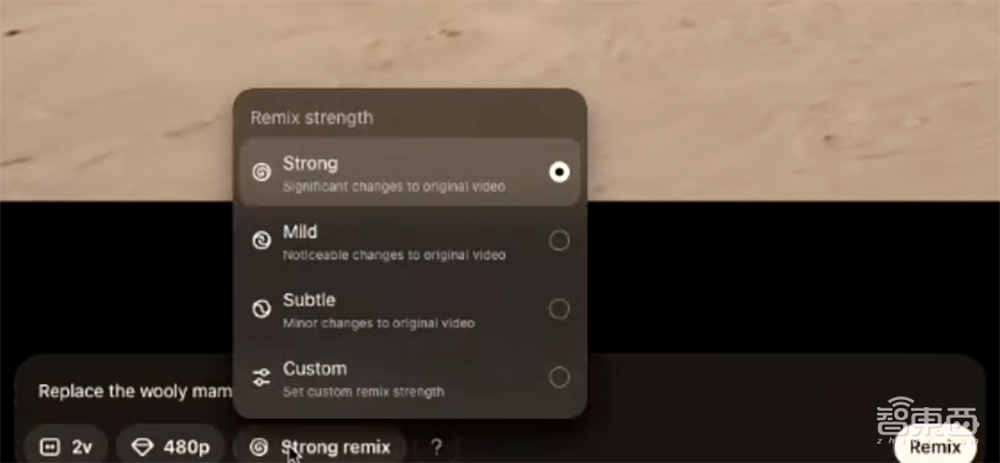
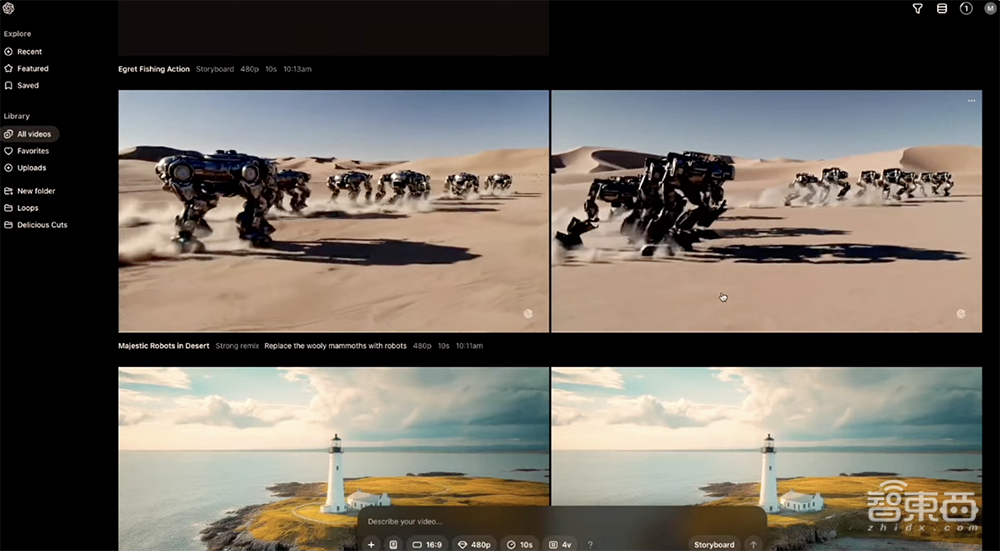
比如把视频画面中的“猛犸象换成机器人”:
再比如生成“打开通往图书馆的大门”的视频:

然后“把门换成法式门”:

“把图书馆变成一艘宇宙飞船”:

“移除宇宙飞船,添加丛林”:

“把丛林换成月球景观”:

2、Re-cut:找到你最满意的视频片段,将它截取出来,向任一方向延展以完成场景

3、Storyboard工具:在时间轴上组织和编辑视频的独特序列,精确指定每一帧的输入
使用故事板(Storyboard),视频画面能被控制得非常精细。用户可通过输入文字提示、上传图片或基于已有视频,在页面添加多个分镜头。
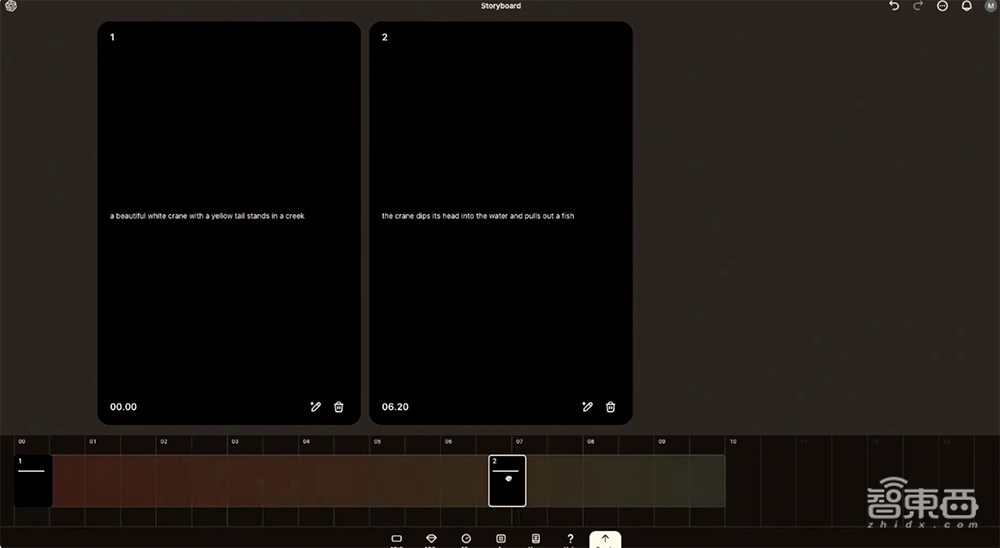
比如指定第一帧是“一只美丽的黄尾白鹤站在小溪里”,第二帧画面是“鹤把头伸进水里,捞出一条鱼”。

系统会自动扩写提示词。
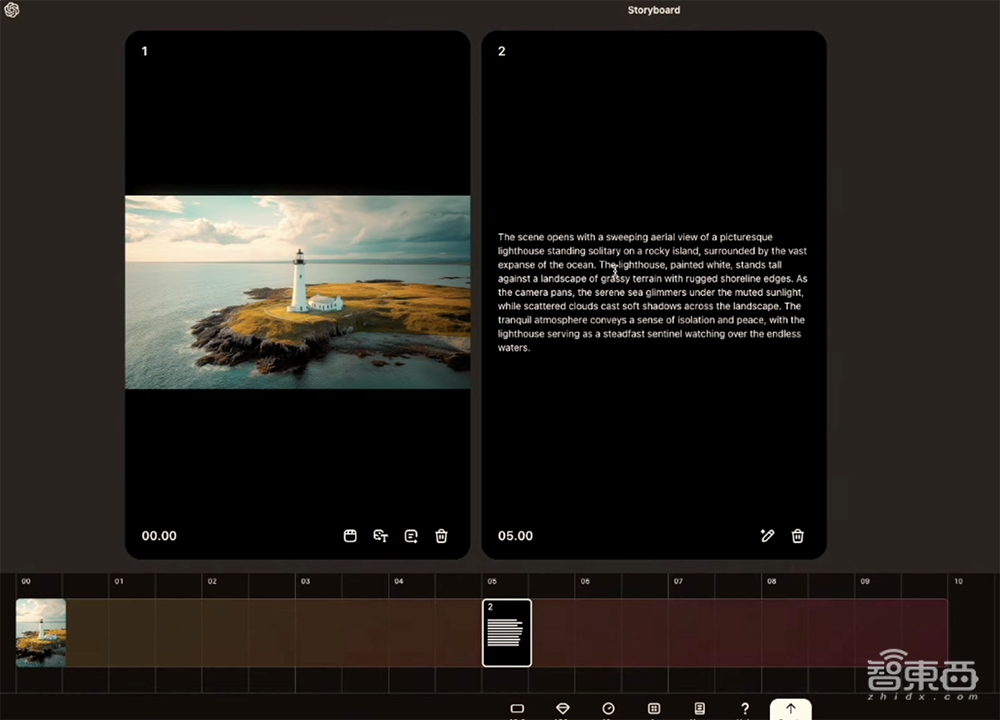
有了这个工具,你就可以制作多镜头视频大片了。
例如生成一个“一片广阔的红色景观,远处有一艘停靠的宇宙飞船”的视频:

将下一个镜头指定为“从宇宙飞船内部向外看,一位太空牛仔站在画面中央”:

然后来个“针织布面罩框住宇航员的眼睛的详细特写视图”:

视频就有了清晰的故事线。
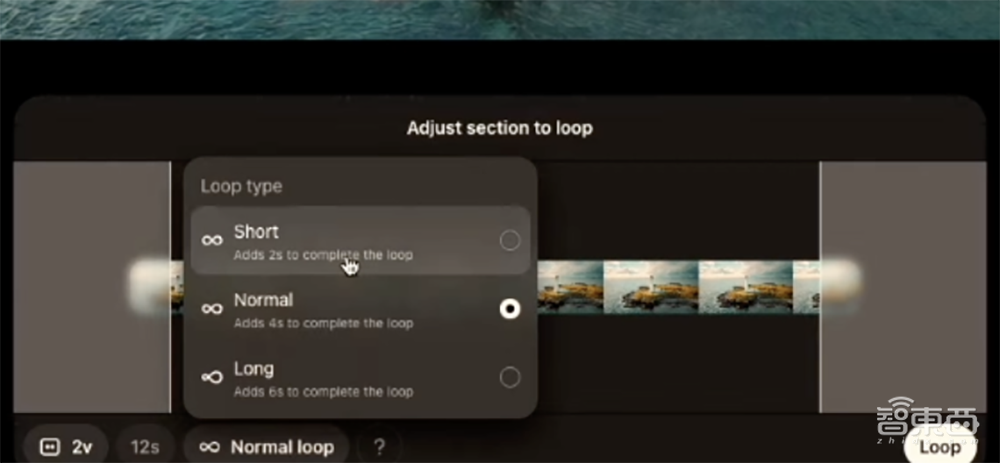
4、Loop:使用循环剪辑并创建无缝重复的视频
Loop有“短”(2秒)、“中”(4秒)、“长”(完整版)三种循环选项。
示例1:花

示例2:楼梯

5、Blend:将两个视频合成为一个无缝剪辑
Blend曲线有过渡(Transition)、混合(Mix)、采样(Sample)、定制(Custom)四个选项。
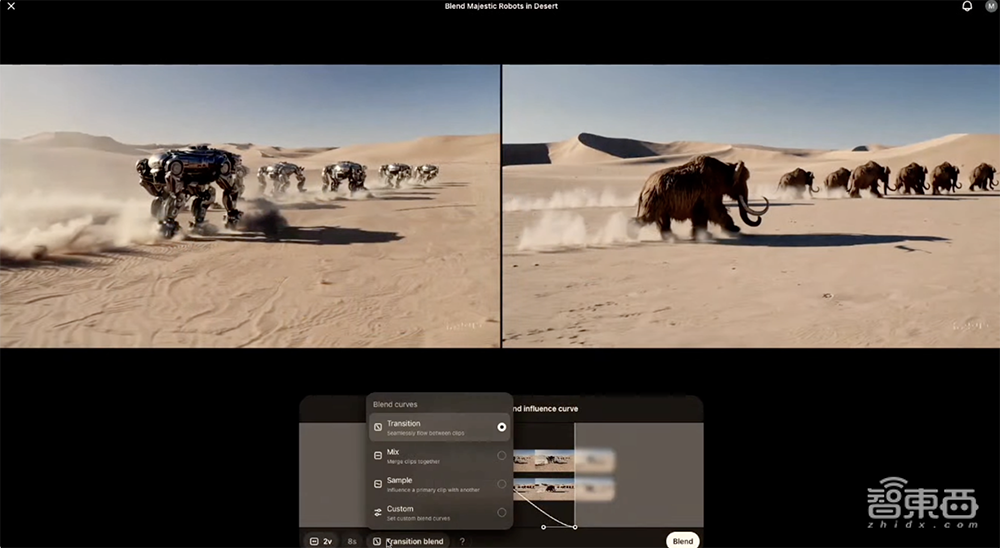
可将两个视频画面无缝融合:

6、Style presets(样式预设):使用预设创建和分享激发想象力的风格
右下角是两个猛犸象在步行的视频,你可以将风格切换成“硬纸板和纸质工艺品”(左上)、“复古电影”(右上)、“怀旧档案”(左下)。

三、网友玩出Sora各种bug:搞错性别、文字乱码、镜头变化不听指令
Sora公开上线后,首批ChatGPT试用者们积极在社交平台晒作品。许多视频乍一看都非常逼真,其中也不乏一些令人啼笑皆非的画面细节。
这个用户的提示词是“一只鹈鹕沿着俯瞰港口的沿海小径骑自行车”,不过最后生成的视频中,鹈鹕在中途莫名其妙地变为向相反的方向骑行。

还有用户的生成视频中,Sora直接把人物性别搞反了。网友的提示词是“一个30多岁的男人,黑头发,戴着眼镜,和一位黑发女人一起走在尼斯的长廊上。天气很好,有几个人在海滩上晒日光浴”。但视频中出现了两位女士。

再来看下面的用户体验视频,网友称这条视频Sora花费了大约30s,不过其并没有公开提示词。

还有用户立即对比了Sora、Runway、快手可灵、MiniMax海螺的效果。提示词是“维京演员的情感表演。当演员皱眉时,镜头推到脸上”。
从结果来看,Sora的视频镜头多变,且颇有大片风范,但没有实现“当演员皱眉时,镜头推到脸上”。

快手可灵的生成效果是最契合提示词的,人物有细微的皱眉动作,且镜头聚焦到了人物脸上。

MiniMax的海螺生成的视频则是拉远了镜头。

Runway的人物表情相比其他三家在皱眉的同时带动了脸部其他位置的变化。

四、公开、专用、人类三类数据来源,数百名创意人士已体验10个月
OpenAI还发布了Sora System Card来分享其安全和监控方法的详细信息。
Sora构建于DALL·E和GPT模型的基础之上,是一种采用Transformer架构的扩散模型,从一个看起来像静态噪声的基础视频开始生成视频,然后通过多个步骤消除噪声,逐渐对其进行转换。通过让模型一次预测多个帧,Sora生成的视频可以确保主体即使暂时消失在视野之外也能保持不变。
该模型使用了DALL·E 3中的重新标注技术(Recaptioning Technique)。该技术可以为视觉训练数据生成高度描述性的字幕,使模型能够更忠实地遵循生成的视频中用户的文本指令。
除了能够仅根据文本指令生成视频外,该模型还能够利用现有的静态图像生成视频或者利用现有视频进行扩展或填充缺失的帧。OpenAI相信这一能力将是实现通用人工智能(AGI)的重要里程碑。
1、训练数据来源:公开可用、企业专有数据、人类数据
与语言模型拥有文本token不同,Sora拥有视觉块(visual patches),这已被证明是视觉数据模型的有效表示。
基于此,OpenAI的研究人员发现视觉块是一种高度可扩展且有效的表示形式,可用于在各种类型的视频和图像上训练生成模型。在高层次上,他们首先将视频压缩成一个低维的潜在空间,然后将表示分解成时空视觉块。
此外,Sora接受了各种数据集的训练,包括公开可用的数据、通过合作伙伴关系访问的专有数据以及内部开发的自定义数据集。这些包括:主要从行业标准的机器学习数据集和Web爬虫中收集到的公开可用数据;OpenAI建立合作伙伴关系以访问非公开可用的专有数据,并合作调试和创建适合其需求的数据集;来自AI培训师、红队成员和员工的反馈。
2、四项输出前安全措施,数百名专业人士已测试10个月
Sora的能力可能带来新的风险,例如滥用相似或产生误导性或露骨视频内容的可能性。
在安全方面,自2024年2月发布Sora以来,OpenAI与来自60多个国家/地区的数百名视觉艺术家、设计师和电影制作人合作,以获得有关如何推进该模型以对创意专业人士最有帮助的反馈。
 ▲动画师上传微缩模型图片后生成的视频
▲动画师上传微缩模型图片后生成的视频
OpenAI采用了以下形式,作为Sora向用户显示其请求输出之前采取的安全缓解措施:
通过多模态审核分类器进行文本和图像审核、自定义大语言模型筛选(定制GPT,利用视频生成的时间窗口,对某些特定主题高精度审核)、图像输出分类器、 黑名单(提前设置文本阻止列表)。
当前OpenAI屏蔽了一些特别有害的形式,如儿童虐待、深度性伪造等。这些题材上传会被限制。
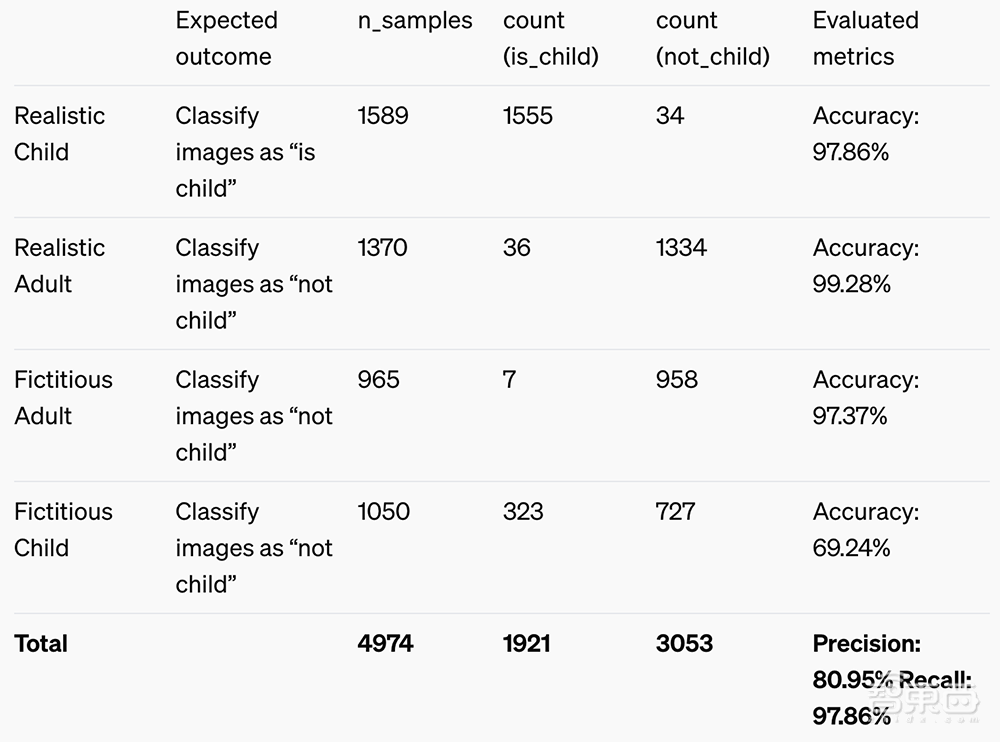
OpenAI称其分类器非常准确,但偶尔可能会错误地标注成人或非现实的儿童图像。他们也承认研究和现有文献强调了年龄预测模型存在种族偏见的可能性。
接下来几个月里,OpenAI团队将致力于提高分类器的性能,最大限度地减少误报,并加深其对潜在偏差的理解。
为了确保Sora技术被负责任的使用,所有Sora生成视频均附带C2PA元数据。它将识别视频是否来自Sora,以提供透明度,并可用于验证来源。OpenAI默认添加了可见水印等保护措施,并构建了一个内部搜索工具,该工具使用第二代的技术属性来帮助验证内容是否来自Sora。
结语:Sora仍有很多局限性
正在部署的Sora版本有很多限制,通常会产生不现实的物理效果,同时长时间复杂动作仍具挑战性。
OpenAI仍在努力使每个人都负担得起这项技术。该团队希望Sora早期版本能让世界各地的人们探索新的创意形式,讲述自己的故事,并突破视频讲故事的可能性。
对于视频创作者来说,Sora的到来无疑是最顶的圣诞节礼物之一。很期待看到世界将用Sora创造出什么。
