








12月5-6日,由智猩猩与智东西联合主办的2024中国生成式AI大会(上海站)在上海圆满收官。在第二日主会场进行的「AI Infra峰会」上,枫清科技创始⼈兼CEO高雪峰以《从数据到知识:AI 重塑百行千业的基石》为主题发表了主题演讲。
在演讲中,高雪峰谈到要将生成式AI真正应用到企业决策场景中,弥合其与决策智能之间鸿沟的技术突破点,就是利用好企业本地知识,同时将符号逻辑推理的能力和各种大模型的算法能力相融合。
随后,高雪峰指出企业智能化的核心趋势,正在从以模型为中心(Model-Centric)的人工智能架构落地范式,转向以数据为中心(Data-Centric)这一新的人工智能落地范式。他总结了企业智能化面临的四个典型困境:模型幻觉、可解释性、推理能力弱、安全与合规;以及企业级人工智能平台场景落地需要解决的四个技术挑战:数据孤岛、数据整合、知识校验、实时性与时效。
为此,他在演讲中表示,枫清科技可以为企业提供知识引擎与大模型双轮驱动的新一代智能体平台,通过构建全链路优化体系,帮助企业提升数据质量,将企业本地数据知识化,并融合大模型沉淀的泛化知识,在知识网络之上进行符号逻辑推理,实现可解释的智能,进而使AI在多个场景下能够实现精准、透明的决策支持,推动企业智能化转型的顺利实施。
之后,他重点介绍了枫清科技助力企业智能化落地实现的两个示例,分别是为金融企业客户打造的智能指标问数这一示例,以及为APEC会议开发的中国-APEC数字平台这一示例。同时,他也分享了为头部央企提供企业级知识引擎和智能体平台,从而推动其智能化转型这一合作案例。
演讲最后高雪峰透露,今年4月份以来枫清科技已经跟金融、化工能源、汽车制造等行业的多家头部央企展开深入合作,进行人工智能场景平台的落地。
以下为高雪峰的演讲全文:
各位来宾,下午好!今天很开心在这与大家一起探讨当下最热的话题:如何将人工智能技术真正应用于千行百业,真正发挥其作为“新质生产力”的核心作用。。所以,我今天给大家带来的演讲题目是《从数据到知识:AI 重塑百⾏千业的基石》。
首先,我简单自我介绍下,我是高雪峰,枫清科技的创始人。在创办枫清科技之前,我曾担任IBM认知计算解决方案研究院院长,后来加入了阿里云,负责阿里云大数据和人工智能的技术产品。我一直在在大数据、人工智能和ToB企业市场领域摸爬滚打了大概20多年。因此,在2021年创办枫清科技时,我们一直坚持三个至今未变的原则:
1.我们在 2021 年谈到未来的人工智能以及 AGI 时,就曾跟大家说,将大模型与大图融合在一起,才能构建未来AGI的基础。也就我们所说的,将符号逻辑推理与连接主义的概率融合在一起,才能够构建真正的人工智能。
2.一定要以数据为中心,从数据的角度出发,构建未来人工智能的基础平台。
3.坚持ToB领域的深耕。这条路虽然慢,但这一领域能真正带来实际的生产力价值和长期回报。
一、信息化到智能化:人工智能的三大阶段
首先,我们来看一下人工智能的发展趋势。
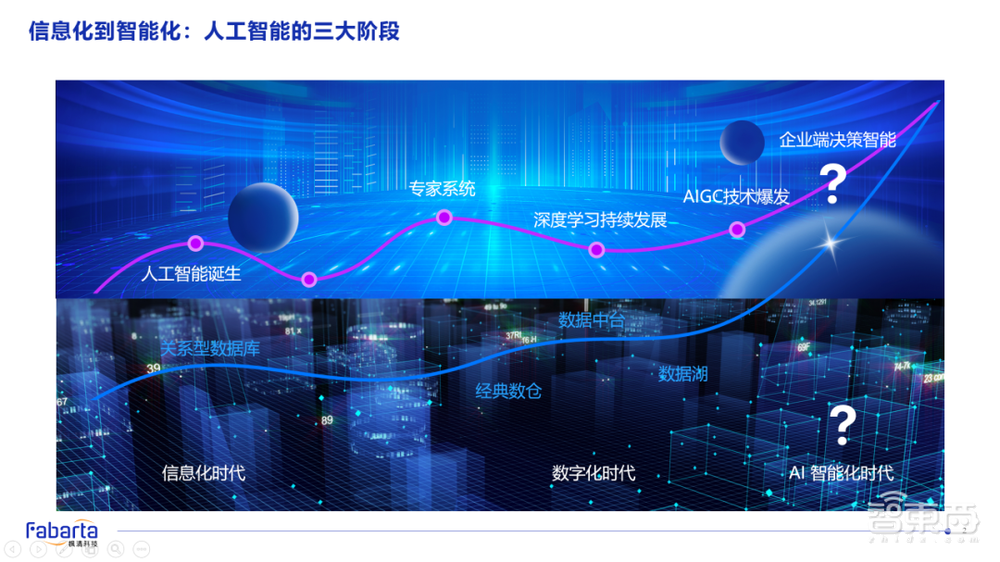
为什么我刚才说,我们在2021年与投资人、客户交流时,都在强调“大模型与大图的融合”才是未来通往AGI的基础?我们可以看到,自从1956年人工智能这个概念被达特茅斯会议提出到现在,连接主义和符号主义两种技术交替发展。任何单一技术都难以独占鳌头,也无法靠单独的技术实现未来的通用人工智能。
因此,我们说深度学习,包括当下火热的大模型,都以Transformer技术为基础,是概率体系的典型技术代表。所以,去年大模型火爆出圈,所有人都认为连接主义、Transformer一定是未来,能够带来真正的智能涌现,带来AGI。这是业界一直以来的一种声音。
但是,当我们将生成式人工智能技术应用到企业决策场景当中时,就会发现,真正的决策智能是不可能仅由生成式智能这一单一的技术来实现的。所以,如何跨越生成式人工智能到决策智能之间的鸿沟,真正让人工智能的技术在企业场景侧发挥价值,是我们当下最需要突破的核心技术点。当下在这个领域,有非常多的技术尝试和挑战,包括OpenAI新推出的GPT-o1,也不再追求参数越来越大的智能涌现,而是在推理的框架侧进行符号逻辑推理与概率体系的深度融合。
再看下面,为什么刚才我说,我们在坚持“以数据为核心”推动智能场景落地。可以看到,从最开始的信息化时代,到数字化时代,到我们一直坚信的未来智能化的时代,都涌现出了非常知名的数据基础设施的体系和标准。
在信息化时代,典型的代表是关系型数据库,涌现出了Oracle、DB2,以及一直延续到现在的NewSQL体系的关系型数据库,这些都是在信息化时代最伟大的沉淀。
回到数字化的时代,在互联网蓬勃发展的这些年,我们一直在强调、追求数字价值驱动企业决策。在这个时候,也涌现出了许多非常优秀的数据基础设施产品,如数仓、数据湖、智能湖仓等,都是这个领域典型的代表。
未来,当智能场景涌现在千行百业的时候,在智能化时代,也一定会有属于它的数据基础设施的形态。那么,这种数据基础设施的形态,与从生成式人工智能到决策智能之间的演进路径,是否有天然的结合点呢?这就是我们一直在探索、研究和实践的技术领域。
二、企业智能化趋势:从Model-Centric转向Data-Centric
今年4月份,国家把“人工智能+”写进了政府工作报告当中,正式揭开了所有企业级的场景在行业中真正拥抱人工智能技术、带来生产力变革的序幕。我们也跟很多龙头企业、央国企展开了合作,帮助它们把包括生成式人工智能在内的多种人工智能算法和分析技术,结合企业本地的数据,在业务场景中真正发挥价值,尝试向决策智能迈进。
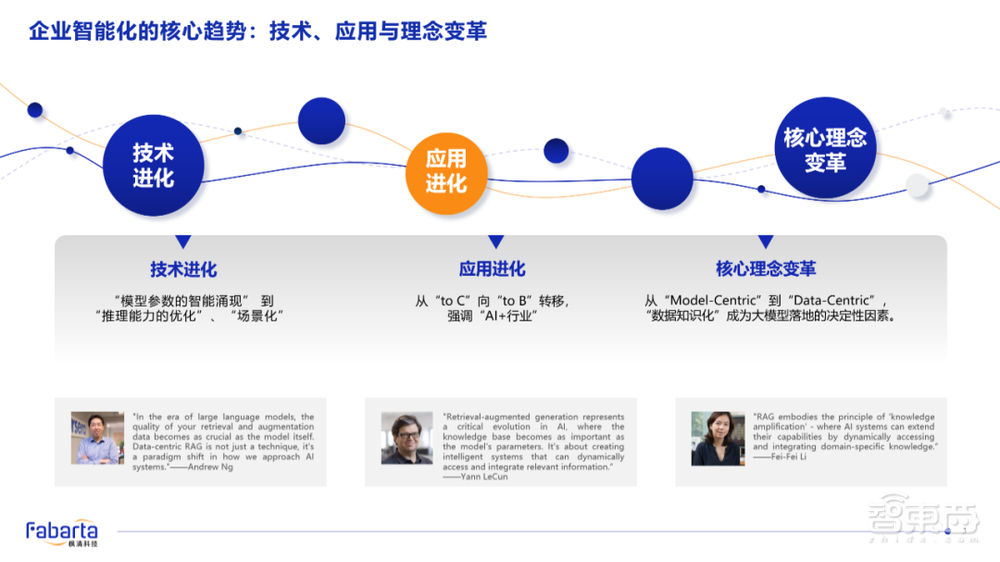
在此前提之下,我们认识到,在企业业务场景当中单独去进行模型微调,或者简单地围绕模型或企业数据的进行RAG检索,很难满足客户在业务场景中的真正需求。
今天,我们看到海外已经有很多声音,不再追求模型参数越来越大所产生的智能涌现。大家已经越来越少地谈论这件事情,而是开始关注如何在推理框架的能力上,将符号逻辑推理能力与生成式连接主义技术融合,尝试进行技术突破。
大家一直以来坚持的以模型为中心(Model-Centric)的人工智能架构落地的范式,在ToB的业务场景中也已经开始慢慢地转向以数据为中心(Data-Centric)的新的人工智能落地范式。
三、企业智能化的4个现实困境与4大技术挑战
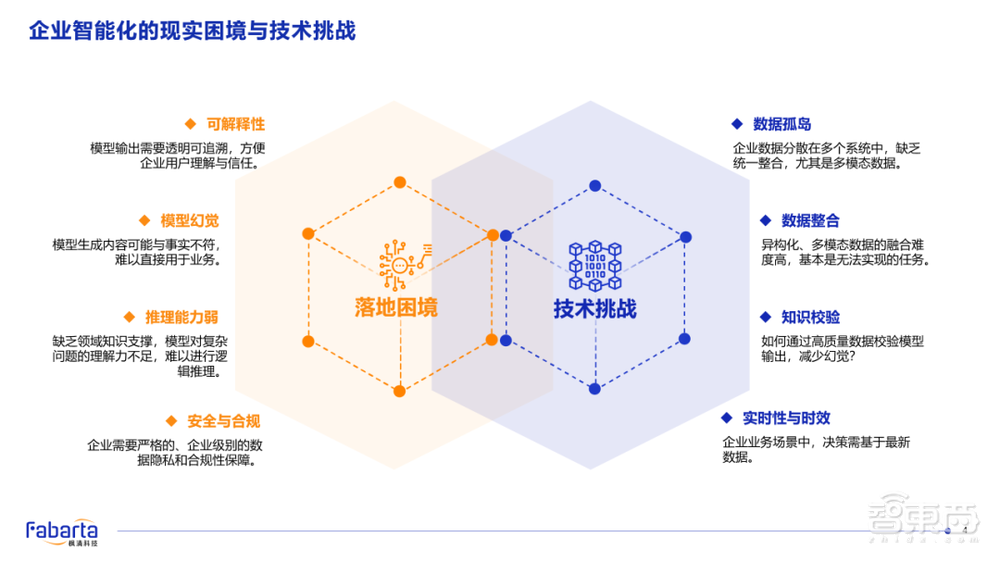
所以,企业的智能化落地会有哪些典型的落地困境?
第一个是模型幻觉。大模型会一本正经的胡说八道。有一些我们的企业客户跟我反馈,这叫大模型的“脑误”。这个问题在企业决策的场景当中,是必须要解决的。
第二个是可解释性。当企业决策智能给出决策建议或辅助建议时,缺乏透明的思考逻辑和决策依据。企业的决策者很难真正地相信这些建议并据此做出相应的行动和决策。
第三个是推理能力弱。仅靠 Transformer的概率连接主义,很难增强其推理能力,所以我们需要把符号逻辑推理的能力融入到落地的技术平台当中。
最后一个是安全与合规性。许多企业都面临同样的需求:部门A与子公司A或B的数据通常不允许互通。那么,如何将这些数据全部用于大模型的微调(Fine-Tune),又能单独为各部门和子公司提供智能决策建议呢?目前的技术无法同时满足这两个要求。因为只要将所有数据用于同一个大模型的微调,无论采用何种方式,都可能通过提示词(Prompts)提取出其他部门或子公司企业的数据。因此,要确保数据安全与合规,实现对知识进行细粒度的权限控制,是企业级智能化平台落地必须要满足的需求。
如果想要解决刚才说的四个困境,企业级人工智能平台落地时会遇到哪些具体的技术挑战呢?
第一个是数据孤岛。我原来在阿里的时候,负责大数据产品,也就是飞天大数据,是阿里当时非常有名的登月系统。我们把阿里所有子公司的数据全部汇聚到MaxCompute大数据平台之上,当时耗费了18个月的时间,我们把它称为“登月”。那么现在,对一个大型企业来说,仅将结构化数据的数据孤岛全集中到一个大型数据仓库中,就已经是一件无法完成的的任务。更别说把企业闲置的80%以上的非结构化数据与结构化数据进行汇聚或连通,这一看就是很难完成的任务。
第二个是数据整合。比如说,银行里存储的每个人的身份证信息,与其数据库表中该人对应的贷款、存款等信息之间存在实际的关联关系。那结构化数据表和非结构化数据的各种属性之间存在隐含的知识网络连接。所以,如何把数据整合起来,是一个非常大的挑战。
第三个是知识校验,如何将企业本地数据实现真正的知识化?在这里提到的不是单纯的向量化,而是真正地实现数据的知识化。也就是说,如何利用企业数据,包括元数据,语义信息以及数据之间的关系等,构建出一个庞大的知识网络。这是企业构建真正属于自己的知识引擎必须要做到的事情,也是非常复杂的事情。
还有一个是数据的时效。通常在做决策的时候,需要依据企业最新的数据,以便智能体平台能够为企业做出及时决策支撑和反馈。不管是Fine-Tuning,还是预训练,都很难满足企业对时效性的需求。
四、Data-Centric:驱动AI场景化落地的新范式

因此,我们才提出要以数据为中心,搭建企业人工智能落地的平台架构。
最开始,业内使用“Data-Centric(以数据为中心)”和“Model-Centric(以模型为中心)”这两个词,是为了研究如何使模型算法更高效、更低成本地实现收敛,达到最好的模型效果。“Model-Centric”通过不断调整模型算法,而“Data-Centric”则通过做好本地数据的清洗和知识工程来达到最好的模型效果。在模型训练和收敛方面,业界已普遍采用Data-Centric的方式。很多大模型的企业,在研究算法的同时,也花费了很多精力构建自己的知识引擎,构建自己的数据知识化与知识工程。
而我们在此谈到的,并不是上述领域的“Model-Centric”和“Data-Centric”,而是人工智能技术在企业多场景落地的过程当中涉及的两种架构范式:“Model-Centric”和“Data-Centric”。
此处的“Model-Centric”指的是企业部署一个或多个多模态大模型,然后通过两种方式利用企业的本地数据:第一种是扔给模型进行Fine-Tune,让大模型能够体现本地数据的价值;第二种是简单地构建基础知识库,通过RAG的方式补充模型没有理解的一些本地数据。这就是以模型为中心,依然是概率体系的架构特征,并没有从根本解决幻觉、可解释性、推理能力等等问题。
相反,“以数据为中心”则是不一样的架构,关注的是企业本地的数据,并将其转化为可用的知识。当然,这种转化也是通过智能的方式来构建。当我们需要使用大模型或多模态大模型去做内容理解的时候,就用它去做内容理解;需要给它足够的Prompt生成一长段内容的时候,我们就用它去做内容生成;当需要对结构化数据进行简单的数理分析时,可以用非常传统的数据分析的方法去做结构化的数据分析。这种以本地数据知识化为核心的架构,是企业级人工智能场景落地的有效范式。这种方法已经在多家大型的头部企业进行过验证,是一种能够快速将人工智能的技术应用在企业决策场景中的典型范式。
通过与多家头部央国企的接触,我们也观察到,他们已经开始寻求构建整个企业或者集团的大型知识库或知识网络体系。当然不止自己本地的数据,也会包含外部的各种各样的数据。我们把大模型中沉淀的知识称之为“泛化知识”。我们要做的是搭建一个平台,能够把企业的本地数据知识化,然后把大模型中的泛化知识与企业本地的知识融合在一起,来推动大模型在企业多个场景中的落地。
五、从数据到知识:企业智能化的技术路径
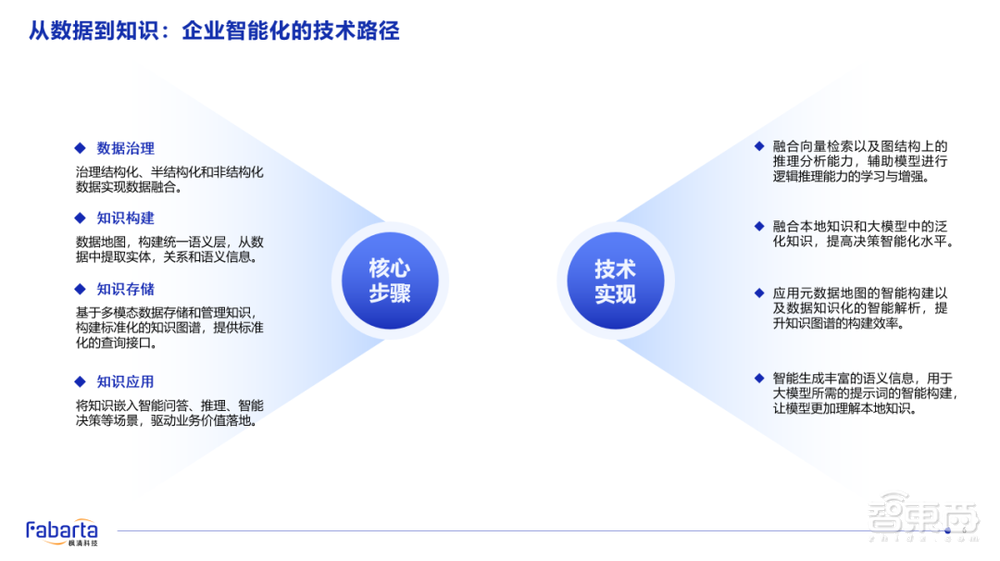
所以,我们具体的过程是什么呢?最开始一定是要对企业的本地多模态数据进行智能化治理,然后构建为企业的本地知识网络,同样要把它存储在知识网络里,并进行相应的多种类型的知识领域的应用。在应用的过程当中,我可能会利用大模型的能力进行内容生成或知识的构建。
在大模型出现之前,知识图谱的构建是一件成本非常高的事情。但是有了大语言参数模型,我们可以把构建庞大的企业知识网络的效率变得非常高。这里面涉及到很多技术细节的突破。同时,也有很多技术特点需要去解决并实现。
第一个是企业知识的表征。以前企业的本地很多各种各样的文档,把它向量化就可以了。但实际上,向量化的过程就是信息压缩、特征提取的过程。但是在这,我们不是把企业本地的数据单纯地压缩或是特征提取向量化,而是把企业所有的数据,向量与向量之间关系、实体和实体之间的关系、实体和向量之间的关系等等,都构建了一个庞大的企业数据知识网络。
在这样的一个知识网络里面,需要我们能够具备融合图向量和类似Mongo的原文数据的分布式存储和计算的能力。
在这之上,其实我们还要能够通过智能体平台的方式,智能地构建不同领域的知识引擎,生成特定的Prompts来去结合不同的大模型的能力,连接大模型内部的泛化知识,最后赋能多场景价值的应用。
同时,我们的知识网络会不断丰富语义信息。例如在为金融客户构建知识库的时候,当问答系统遇到不理解的关键词,我们会通过用户反馈的方式,将这些词的语义理解叠加到知识网络中,使系统能够理解新的问题,或者用户诉求该如何满足。
六、知识驱动:创新路径加速大模型落地
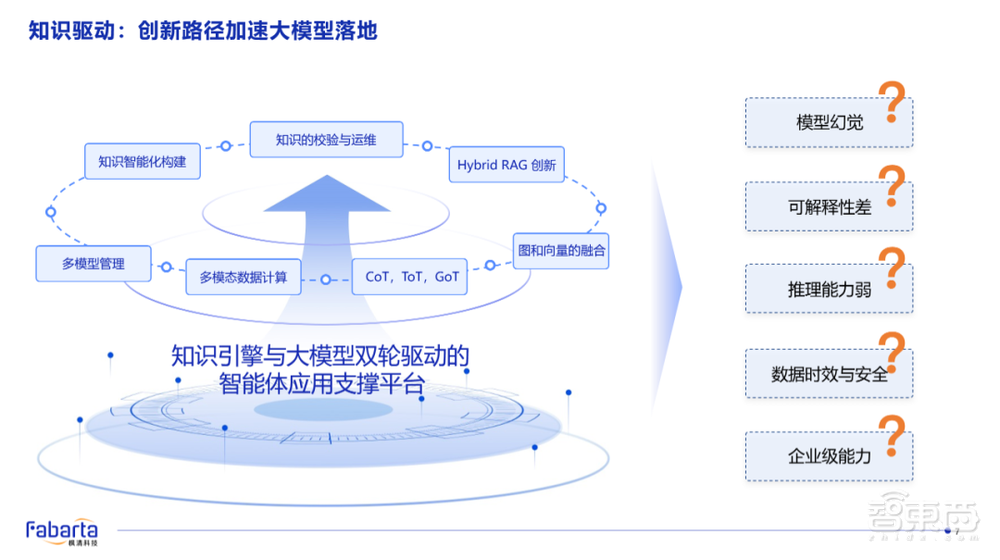
所以,在人工智能的企业场景落地的平台当中,我们必须要解决的核心的问题就是模型幻觉、可解释性、推理能力、时效性和企业级安全能力。
为此,我们进行了多项技术创新,包括图和向量的分布式存储与计算融合、独创的Hybrid RAG技术、知识的运维与校验,以及针对大模型推理框架的Graph of Thoughts等前沿技术实现。这些都是我们在落地知识驱动的智能平台落地时需要解决的问题。
下图展示了我们如何通过图、向量融合等技术,有效地解决了大模型幻觉、推理能力弱以及大模型数据时效性等问题:
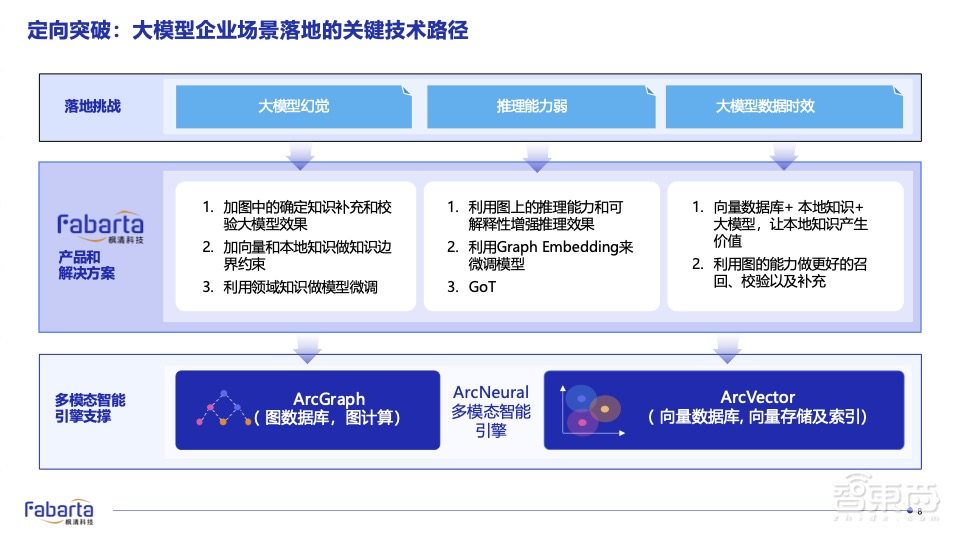
我们当下服务的都是龙头的央国企,即链主企业。通过链主企业,来构建对行业的影响力。
七、从AI Market Place到人工智能平台新范式
那么,一定是通过平台驱动的方式,来推动多智能化场景的均衡落地。下图是我们非常典型应用的一个平台搭建。
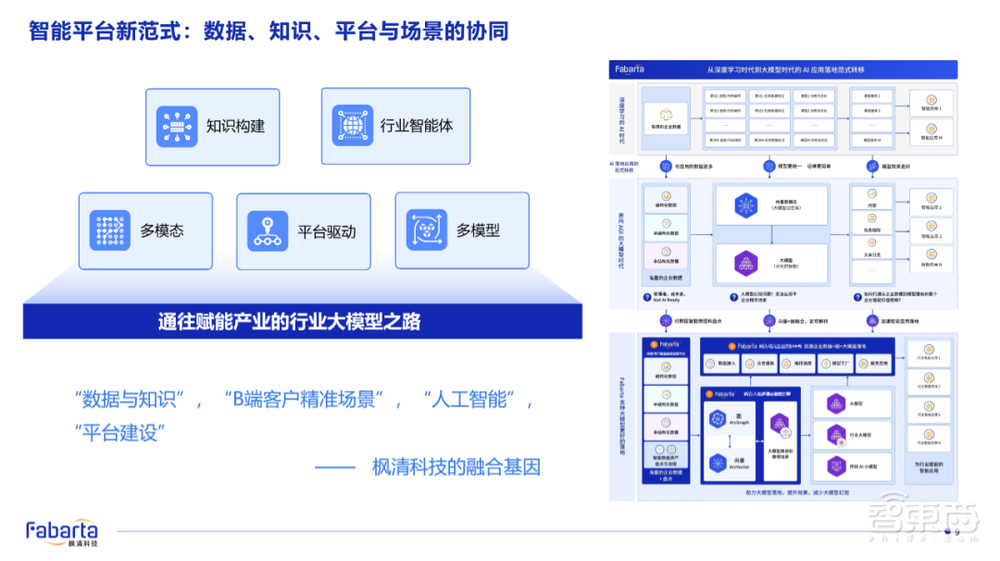
回到AI平台这个词或说这个事,我相信大家都听过很长时间了。在上一代人工智能技术出现的时候,我们就在谈AI平台。但那时的AI平台,是由算法、数据和应用场景以“烟囱式”堆积而成的平台。这个平台,我更愿意把它称之为AI的Market Place。
现在随着大模型的涌现,模型这一层可以汇聚到一个或者几个大模型领域当中。企业的模型在慢慢收敛到个位数级别,带来的影响是底下的数据也一定会收敛到个位数的统一级别,即刚才提到的数据知识化的过程。
通过这样的平台能力,去赋能多价值场景的落地,这是当下非常典型的人工智能平台落地的架构。
八、“知识引擎+大模型”双轮驱动企业智能化
下图是我们帮很多头部链主央企构建的真正能够解决实际场景落地价值的人工智能平台。最下面是基础设施(智算中心);上层是由各个大模型企业以及云厂商提供的模型工厂;再往上是大模型的运维平台,我们叫做Model OPS的平台,包括训练推理加速、模型的生命周期管理等等。很多企业在最开始尝试的时候,结合了行业的数据集直接面向了最上层的多应用场景的赋能。这个就是之前提及的Model-Centric的路径。
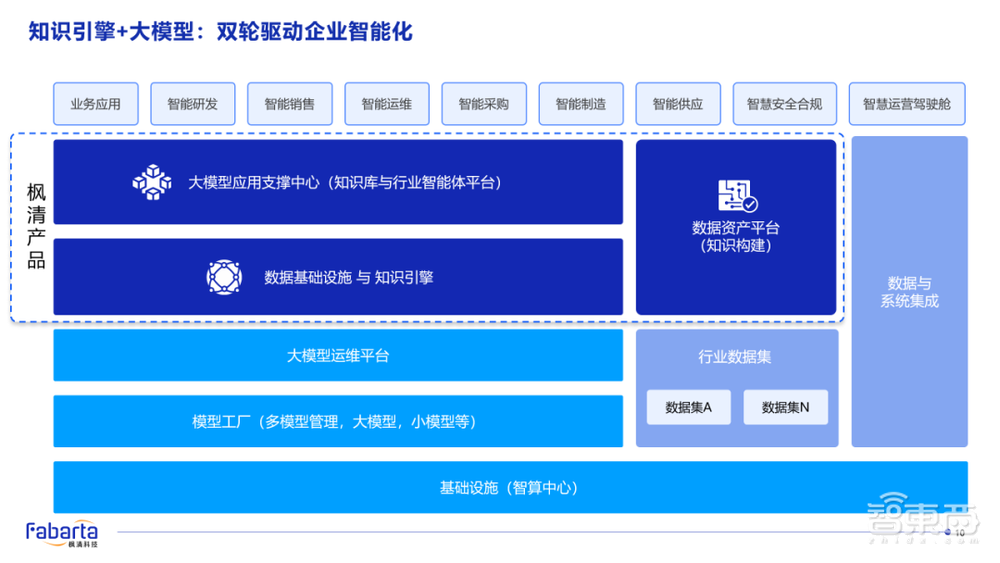
但是,大部分企业在这样的实践的过程当中,发现刚才那几个问题无法解决,无法真正实现决策智能的场景价值。所以,这也是为什么我跟所有企业说,中间其实缺了这样的一层,也就是我们枫清科技的“一体两翼”的产品矩阵,来进行知识的构建,把企业本地的数据构建为知识。它是一个数据关系的庞大网络,而在这个网络之上就可以进行符号逻辑推理,并结合大模型的生成能力,做真正可解释的智能。
然后,底下有我们核心的知识引擎、支持图、向量以及源数据的分布式存储计算的多模态智能引擎。在此之上有大模型应用支撑中心,能够链接并管理不同的大模型;同时有行业智能体平台,能够管理本地知识引擎,起到连接本地知识、行业知识以及模型中的泛化知识的作用。最后,所有应用场景都通过行业智能体的方式,透传给企业智能化的应用。
我早在IBM的时候,大概七八年前,IBM内部就推出了一个非常秘密的项目:Intelligent Workflow。当时正在做的事情就是类似目前的这个架构,只不过没有把太多生成式人工智能技术融入其中。当时也有Watson Debater,也是基于Transformer的技术,能够实现非常好的人机对话的实际应用。所以,我们要帮帮助B端客户慢慢地实现决策智能,必须要采用的这样的架构,没有任何第二个选择。
九、助力链主企业智能化实现示例和场景演示
下图是我们的一个案例,通过我们搭建的平台,针对于头部链主企业在实际业务场中具体的智能化诉求,我们提供了最基本的比对、交互、检索、创作、总结等行业智能化的Agent能力,并结合企业本地已经知识化的数据体系,可以给企业进行多场景智能化赋能,这些方案已在多家头部央企成功落地并应用于决策。
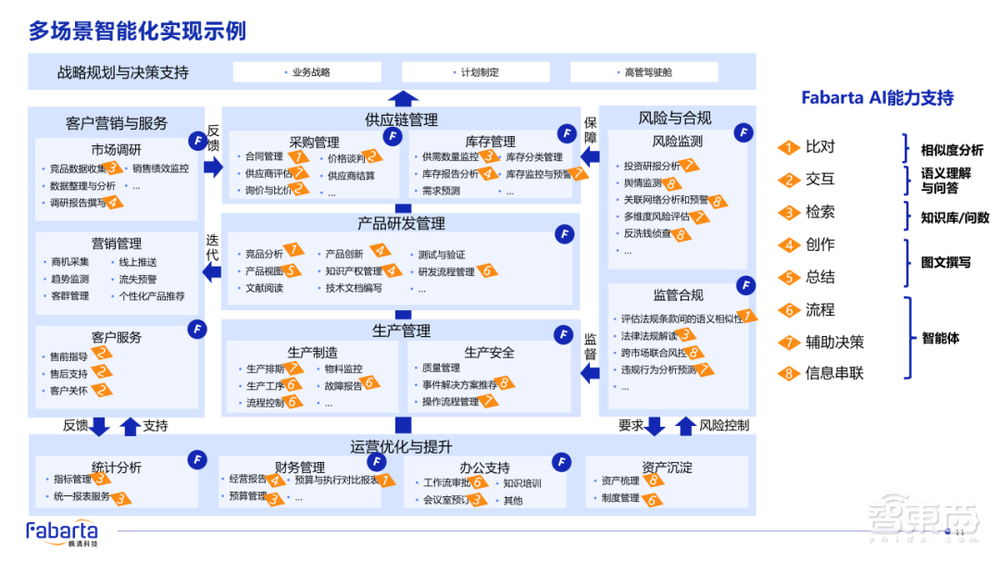
然后在这举个很简单的示例:智能指标问数。Text2SQL其实不是大语言模型最擅长的,因为这不属于生成智能。但是,回归到企业的决策指标问数领域,我们依赖的可不单纯是企业本地的结构化数仓中的指标库数据,还需要关联企业本地的多模态数据。然后,这些数据对企业的决策产生影响之后,我们要做粒度非常细的、直接对话式的根因分析,才能够真正实现企业的决策智能。
在一个问数场景中,如何把我以上所说的这些理念以及技术点给融合在一起呢?
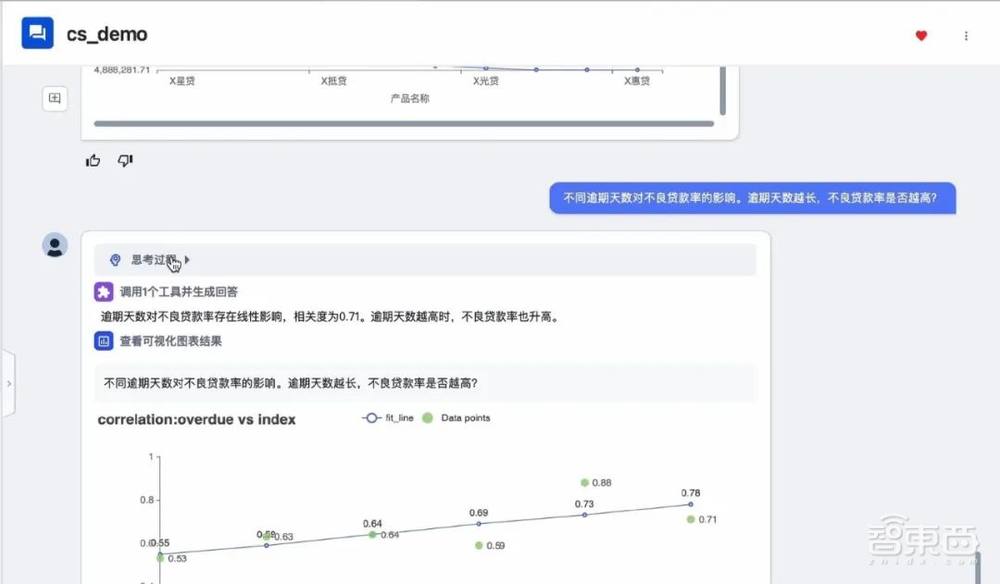
上面这张图展示的是我们为一个金融客户开发的智能指标系统。当用户查询不良贷款相关指标时,系统能够智能搜索并生成不良贷款指标数据及对比。当用户询问不良贷款指标的后续影响时,系统会直接呈现深度影响分析及解释逻辑。系统还集成了智能体工具。例如,当用户询问“A越高,B是否越低”等相关性问题时,智能体会调用相关性分析算法工具,给出相关性和相关系数。
在系统搭建过程中,我们将企业本地的非结构化数据(例如不良贷款客户类型比例限制等)也融入到知识网络中,以便在指标展示时直接提示用户是否违反了监管规定和指标约定。通过该系统,我们还能针对不良贷款比例超标的企业,基于银行数据的汇总,分析其与不同企业之间的交易往来,并进行不良贷款回溯分析,这正是典型的基于图的根因分析。
在APEC多国贸易领域,有非常多的结构化数据和非结构化的贸易相关的交易数据。我们把这些数据整合到企业的本地知识体系当中,可以开放给APEC成员国企业。帮助 APEC 成员国的企业查找上下游渠道商。系统还能智能生成贸易分析报告、风险投资回报比等详细信息,帮助企业决策出口产品到哪个APEC成员国能带来最大收益,以及在特定国家进行何种类型的贸易。

通过我们的智能体平台,两个礼拜内就可以帮助企业快速搭建具备业务场景价值的智能应用。

上图展示了我们为一家头部央企的集团搭建的智能平台架构,赋能并落地多个业务场景,包括私域文档智能问答、企业供应链智能问数、AI科技情报智能分析,有效支持企业生产运营。例如,在生产线上,我们实现了智能化的风险检测,并结合企业安全知识库,为企业建立风险预警机制。当生产过程中出现潜在问题时,系统能够及时向工厂或企业提供风险点提示。这一切都依托于集团安全生产知识库的完善构建。平台成功融合了多模态数据与企业文本知识数据,为智能化生产提供了强大支撑。
我们通过一个平台可以赋能多个业务场景,同时还能够帮助企业将数据持续不断地沉淀在统一的我们一个知识平台和知识引擎当中。
从今年4月以来,我们已与多家头部央国企展开深入合作,在人工智能场景平台的落地方面积累了丰富经验,覆盖金融、化工能源、汽车制造等多个行业。我们与客户的数字科技企业紧密合作,共同探索人工智能的最佳应用路径。
我们观察到,越来越多企业正在积极探索如何将智能化技术真正融入决策过程。未来,我们希望能与在座的嘉宾和客户一起,共同迈向人工智能赋能千行百业的美好新时代。
