








EAIRCon 2025中国具身智能机器人大会是由智猩猩面向具身智能与机器人领域发起主办的大型会议,由主论坛+专题论坛+研讨会+展览区四大板块组成,近40位产业代表与青年科研人员与会分享和讨论,线下参会观众超过1000人。
极佳科技联合创始人、首席科学家朱政博士受邀在大会分会场二上午的具身世界模型技术研讨会带来了报告,主题为《世界模型:从语言智能走向物理智能》。
朱政博士首先介绍了物理智能和世界模型的基本概念。他指出,物理智能注重对于4D物理世界的理解、生成、常识和推理,可能是除语言智能之外,通往通用智能的第二条技术路径。
世界模型本质上是一个预测模型,旨在预测给定动作下事物状态的演变。朱政博士表示,之所以给汽车、机器人等Agent建立世界模型,是受人的智能学习方式为启发。
接着,他介绍了团队在自动驾驶世界模型领域围绕数据生成和闭环仿真所开展的一些工作。朱政博士认为,所有的通用智能问题都正在走向端到端,而端到端的核心正是世界模型。
最后,朱政博士介绍了团队在具身智能世界模型上的多项工作,包括EMMA EgoDemoGen、MimicDreamer等,以及最新提出的由世界模型驱动的VLA系统GigaBrain-0。他表示,希望VLA会融合一部分世界模型的知识,变成下一代的WA (World Action Model)。
以下为朱政的报告全文:
朱政:感谢主持人的介绍,感谢智猩猩的邀请。今天我给大家分享的主题是《世界模型:从语言智能走向物理智能》
首先给大家介绍一下物理智能和世界模型的一些基本概念。然后给大家汇报一下我们在自动驾驶世界模型数据生成方面的一些工作。数据生成做完了,下一步自动驾驶世界模型的主要应用是要进行闭环仿真来训练强化学习算法。最后给大家汇报一下,我们从自动驾驶迁移到具身智能的场景,在具身智能世界模型上面也进行了一系列探索。
一、物理智能与世界模型
首先看一下人工智能的发展历史,其实是从封闭域走向开放域的过程,从感知走向认知决策的过程。如果把语言模型看作是一维的数据,那么图像或者视频就可以认为是2D、2.5D或3D的数据。3D空间再加上一维的时间,就形成了4D时间。这也是空间智能包括世界模型主要探索的对象。
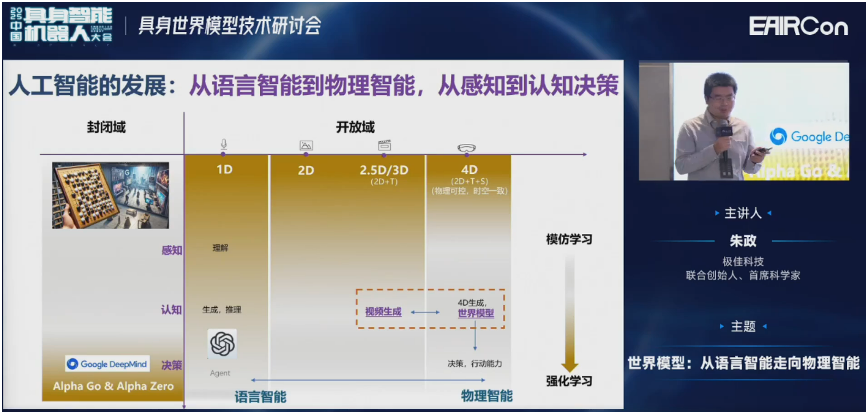
物理智能,注重对于4D物理世界的理解、生成、常识和推理。它的最终目标就是实现机器人agent、自动驾驶车辆、人形机器人在4D空间中的交互和理解。这些大家最熟悉的就是驾驶或者机器人。
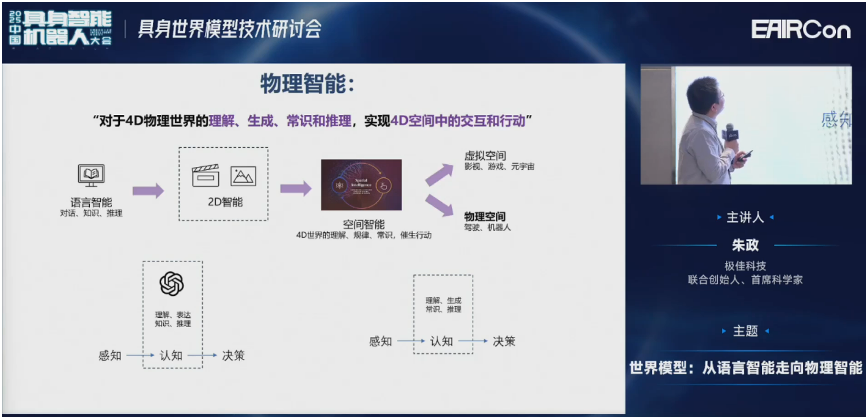
我们认为物理智能可能是除了语言智能之外,通往通用智能的第二条技术路径。大家的终极目标都是一样的,最后到行动,与物理世界进行交互。但是语言智能更多是对内,它是从思维链COT出发,然后到最后的交互。物理智能更多的是对外,从交互出发到最后的行动。
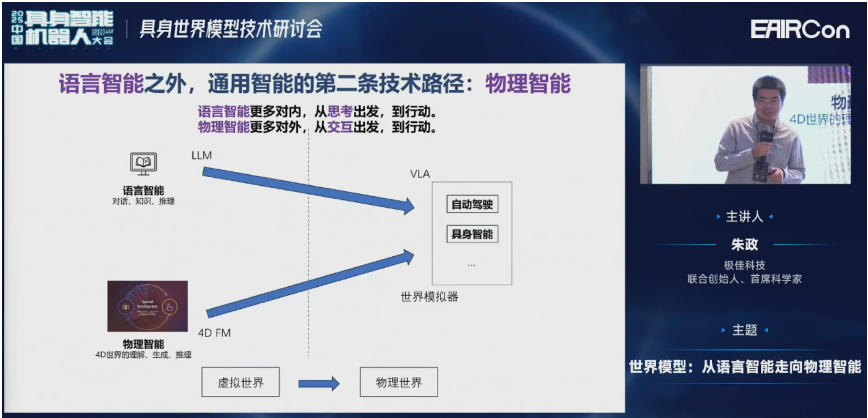
看一下世界模型的具体定义。世界模型在很多时候我们认为它是一个预测的模型,目的就是要预测事物在给定动作下的演变。这个“给定动作”就是我们所说的条件,在不同领域会有不同的condition。比如在Sora里边,给定条件就是一段文本。可以做文生视频、文+图生视频。在自动驾驶里面,可以认为是方向盘的转角,或油门的加减速。在具身智能机器人领域里,可能是关节的位置或末端的位姿等。

这就是为什么我们需要给agent,包括汽车、机器人,建立世界模型,主要是因为我们受到了以人为启发的智能学习方式。人会使用有限的感官,比如视觉、触觉、嗅觉来感知世界,会在内部建立一个简化的世界模型,我们的角色包括行动都是基于这个内部模型。
这里给大家简单介绍一下,我们为什么要建立一个内部模型?为什么不能靠实时感知来与世界交互。假如只靠实时感知的话,是没办法预测世界可能出现的危险或各种变故的。比如一个老司机在开车的时候,他除了会实时感知外部的行人、车辆之外,还会对未来发生的危险进行预判。比如他可以通过观测一个路口的行人,就能判断这个行人是要停下等待车辆通行,还是穿过十字路口,这个时候司机就应该做避让。
再比如一个职业的棒球运动员,可以在0.0几秒之内接到一个高速飞行的棒球。但在这个时间内,其实视觉信号还没有从视网膜传到大脑皮层,实时感知系统还来不及处理这个信号。但是因为人的内部有一套预测系统,也就是所谓的世界模型,它可以提前对事物的未来发展状态进行预测。人之所以能够在多变的世界里边与之交互,很大程度得益于世界模型。当然,自动驾驶车辆或人形机器人,更需要这样的能力。
这张片子大家应该在很多场合都看过,就是Yann LeCun认为,人类的大脑可以分为这么几部分:Configurator、Perception、World Model、短时记忆、Cost、Actor。其中,World Model可能是连接其他几个部分最重要的桥梁。

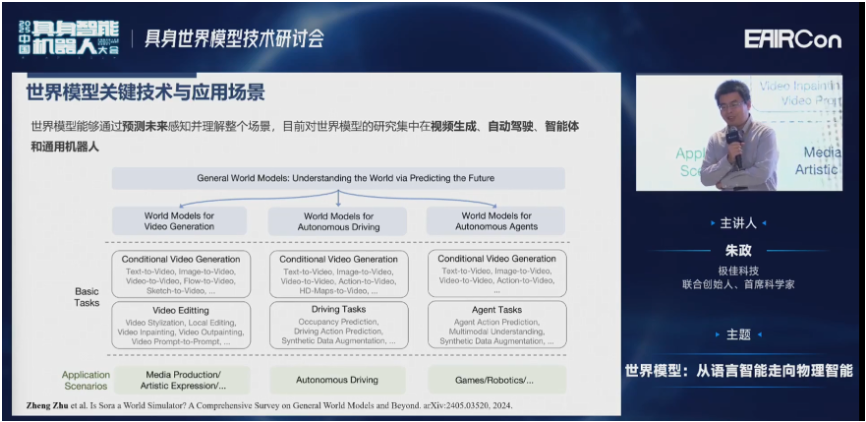
其实在很多领域大家都在谈论世界模型,包括视频生成、自动驾驶、agent(人形机器人)领域。这几个领域的世界模型研究是比较广泛的,分别有一些基本的任务和应用场景。
二、自动驾驶世界模型-数据生成
介绍完背景之后,接下来和大家汇报一下我们在自动驾驶世界模型数据生成上的一些工作。
首先来看一下,我们认为所有的通用智能问题,比如数字世界里的语言模型或者视频生成模型,物理世界的像特斯拉的FSD或者Optimus,都在走向端到端。我们认为端到端的核心就是世界模型。这里面包括了世界模型可以提供闭环模拟器,也可以建立高质量的4D闭环数据。
我们可以看一下之前在没有世界模型的时候,大家采数据是怎么采的。我们可以通过互联网数据作预训练,通过仿真数据也做预训练,或通过车队的实采数据、遥操数据做后训练。但是这里边缺点其实是比较明显的。比如互联网数据或仿真数据缺乏真实性;实采数据、遥操作数据成本比较高,Corner case少,效率低。

如果我们用世界模型代替传统的方式采集数据,总结为四个字叫“多快好省”。
多就是可以规模化的生成。因为GPU可以并行化的生成。
快就是不受限制。
好就是可以挑选生成Corner case或者长尾的分布,它的价值密度比较高。
省的话就是GPU的成本相比较车队或者本体,还是很低的。
接下来给大家汇报一下我们早些年的一些工作。
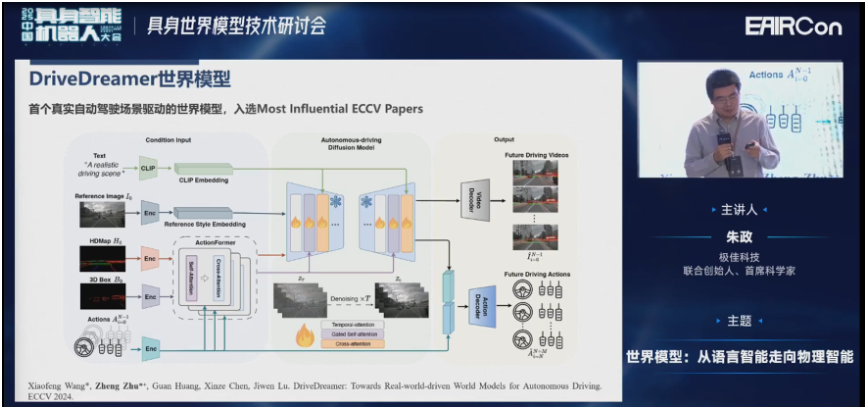
DriveDreamer是我们2023年做的,现在已经成为常用的一个baseline。
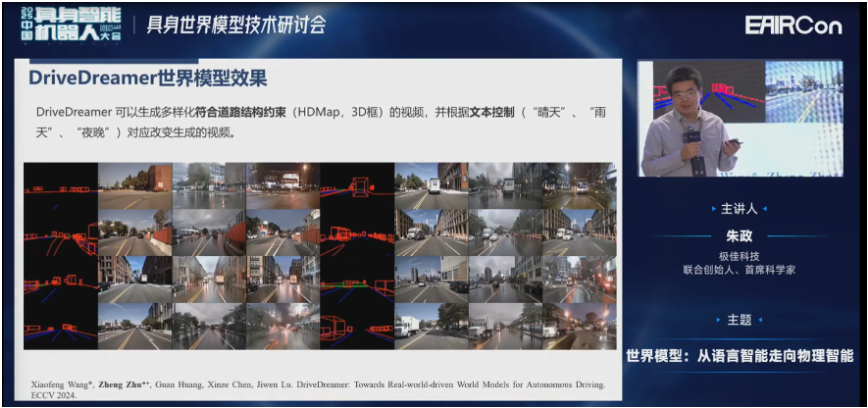
这是我们生成多种不同的天气、背景、时间等。

这是根据结构化信息可以生成,根据文本的控制,像晴天、雨天、夜晚这样一些场景。
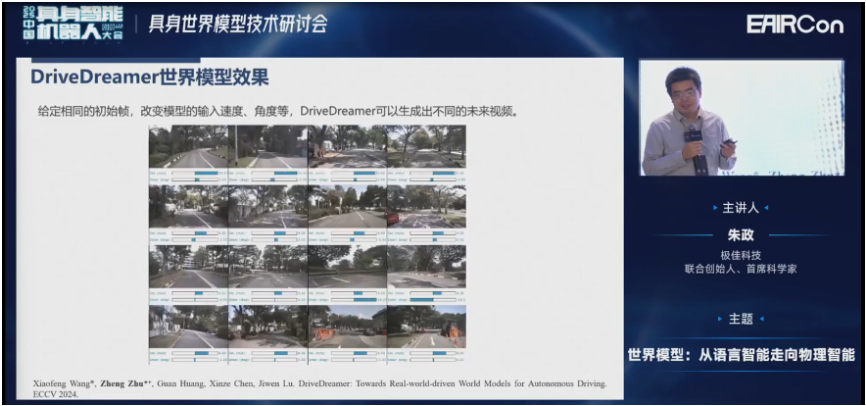
然后我们给定相同的初始值,改变模型的输入,也可以生成不同的未来。
其实世界模型本身就是一个VLA,因为预测未来和预测未来的action其实是一回事。
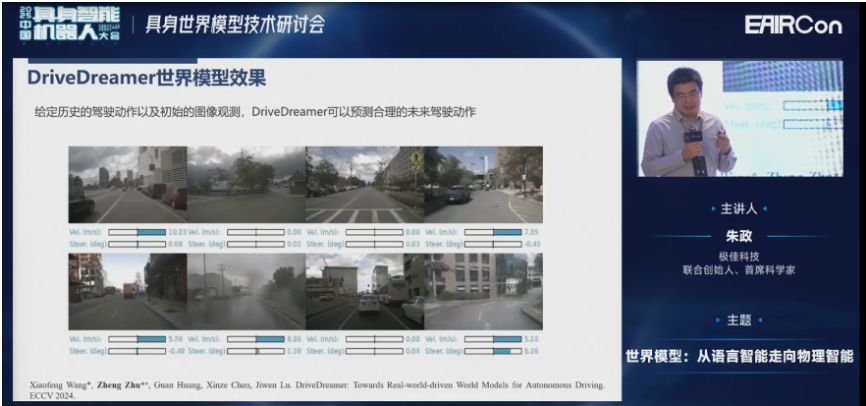
在DriveDreamer里面,结构化信息一般来自于数据集。但像nuScenes、nuPlan或Waymo,它的数据集是预先采集好的离线数据。所以想改变它的结构化信息,比如人工改变不是那么方便。所以我们在DriveDreamer-2里面引入了语言模型,就可以用语言模型去定制化的先生成结构化信息,再根据结构化信息去生成周视的视频。
比如在这张图里边,我想生成一个雨天车辆Cut-in的场景。我先送给一个结构化信息的生成器,再生成结构化信息,进而就可以生成周视的视频。

接下来看一下可视化的结果。第一行、第二行、第三行分别是白天、雨天、夜晚,车辆突然从右边超车。

上面是下雨天,下面是白天的一些场景。这些都是在nuScenes上的一些结果。

三、自动驾驶世界模型-闭环仿真
讲完了数据生成之后,接下来讲讲自动驾驶世界模型闭环仿真。
大家都知道,关于自动驾驶车辆,像一些自动驾驶公司或者车企,这些年积累了几乎上亿公里的数据。但为什么我们刚才还要做自动驾驶的数据生成呢?
因为在这些数据里面,99%的数据可能都是晴天道路直行的数据,Corner case长尾分布非常少。所以这些有价值的数据常常被淹没海量数据里边。而用模仿学习在学习到的时候,又只能学习到数据的平均分布,很难学习到面对长尾问题应该怎么处理。所以我们要做数据生成。
做完数据生成之后,我们训了BEV的算法,训了一些端到端的算法。接下来就是因为大模型的兴起,很多自动驾驶公司开始采用VLA方案。VLA方案一个很重要的问题是需要进行闭环仿真,而世界模型在闭环仿真领域也有很大用处。
接下来可以看一下我们几个探索性的工作。
首先看一下自动驾驶的发展历史,以及我们为什么要做闭环仿真。自动驾驶从2D感知,到BEV的3D感知时代,然后到端到端时代。
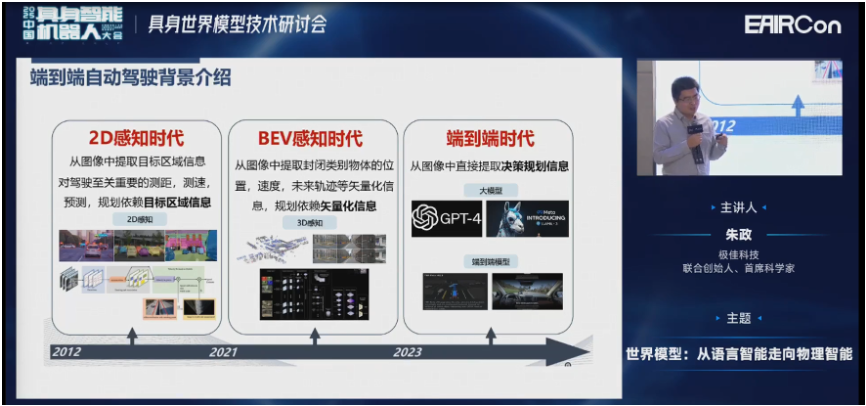
当然端到端会引入很多的优点,这里我就不再赘述了。同时也有一些缺点,有两个比较重要的缺点:
第一个是它的可解释性下降了,我们需要更系统的测试手段。
第二个是车辆的行为会影响所获取的图像。所以没办法像感知一样进行开环的评测,必须要进行闭环的评测。这样才能在车辆偏离录制行为的时间,以初始的图像作为condition,来生成新行为下的图像,这就是所谓的闭环仿真。
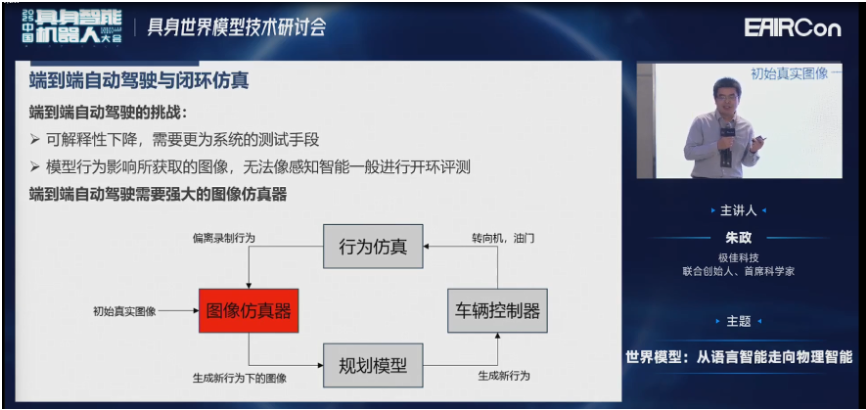
闭环仿真,大概有几种做法。比如通过CARLA模拟器;一些游戏的引擎或三维重建的仿真;也可以通过我们刚才所讲的2D世界模型。但是他们都有一些缺点,大家也都比较明确了,我就不再赘述了。

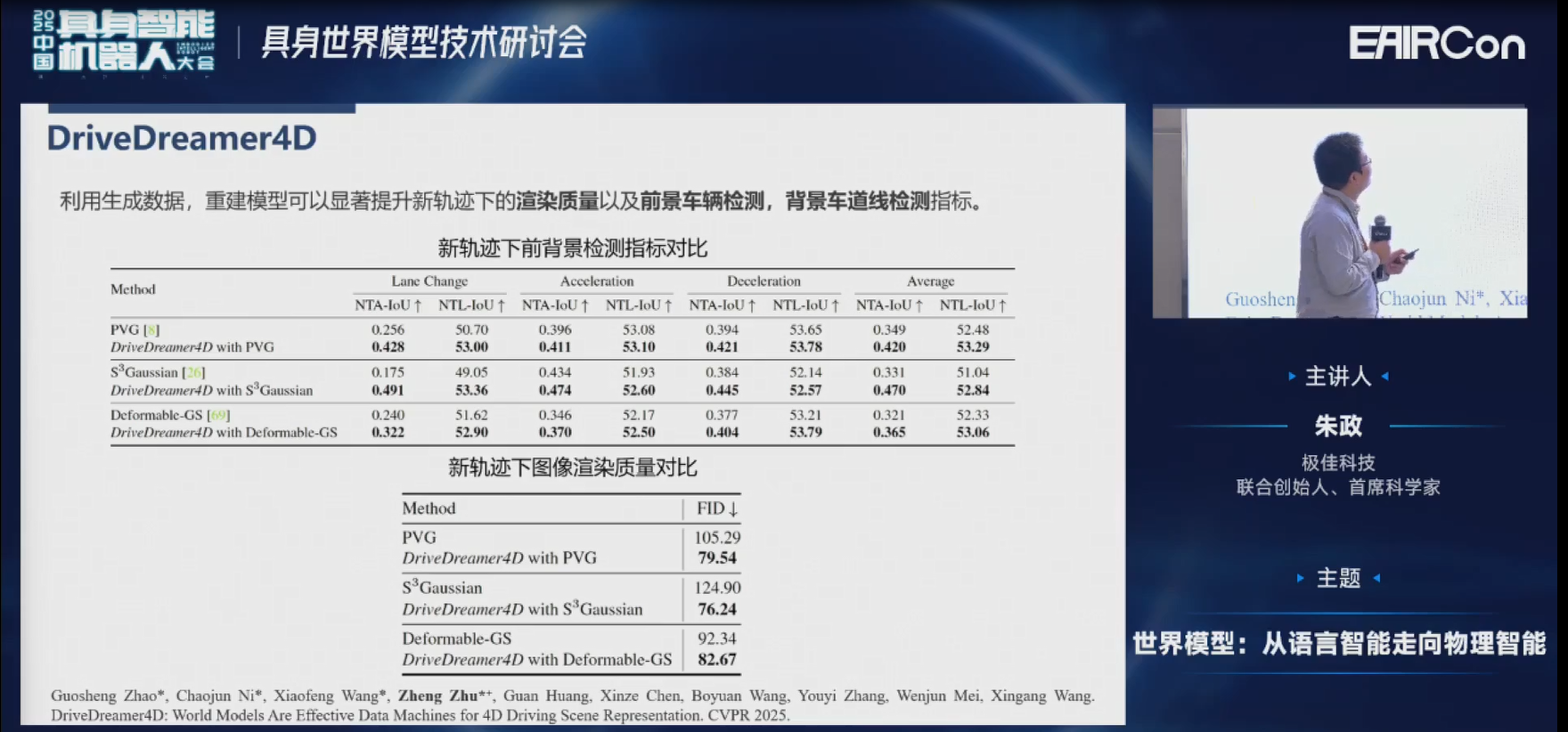
为了避免像DriveDreamer、DriveDreamer-2这些2D视频所带来的闭环仿真的挑战,我们在DriveDreamer4D里引入了重建,它是联合了生成+重建。通过结构化信息生成的视频,可以加到重建模型里,来填补它没有见过新视角的缺陷。这样它新老视角都见过,会重建的更好。

具体来说,像DriveDreamer4D里,我们会利用首帧+结构化信息生成一些新轨迹的视频,然后把新老轨迹混合起来训练4DGS。靠这么一套Pipeline下来,我们在多个方法里都达到SOTA的结果。

以下是PVG的结果。左边原始的PVG有很多伪点、浮影等,但右边都比较好的被克服了。

这是Deformable-GS的结果。

这是S3Gaussian的结果。

然后这些定量化的结果我就不再赘述了,大家有兴趣的话可以看一下我们的文章。
在做完DriveDreamer4D的时候,其实有进一步挖掘的空间。在上一篇工作里面,我们是直接用生成的方法去生成新视角的数据,加给重建模型进行训练。但这种方式没有做到生成和重建联合优化。
所以我们在这ReconDreamer这篇工作里,先对场景进行重建。重建完之后,可以渲染新视角的视频。当然这个时候因为它没有见过新视角,所以一定会有各种伪点、浮影等,甚至有大量的黑块。然后再送给视频生成模型进行修复,修复完之后的数据再经过一个循环提供给重建模型,这样就可以做到两者联合优化。
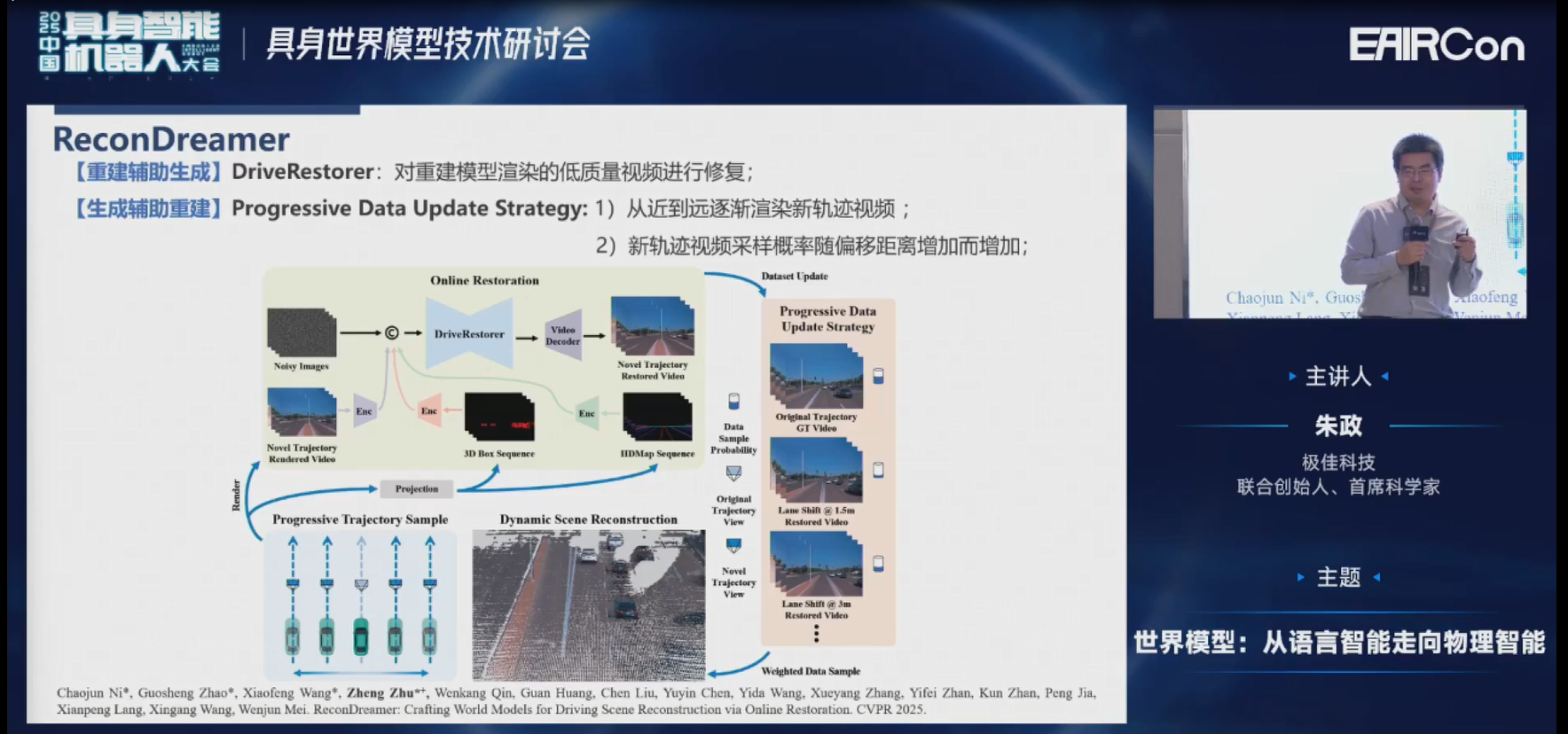
左边是直接在新视角下渲染的结果,右边是经过视频生成修复模型之后修复的结果,可以发现效果有了非常大的提升。

这是我们在当时第一次做到了可以偏移两个车道,也就是偏移6米之后的结果。
相比较之前的Street Gaussians,或DriveDreamer4D,还是有非常大的提升。

然后我们做了非常多其他数据集的一些结果,包括nuScenes数据集,定量化结果就不再赘述了。
因为我们发现ReconDreamer这一套工作确实比较有潜力,所以在持续挖掘。我们发现ReconDreamer有一个问题:虽然新视角的渲染质量提升很大,但在原视角是有所下降的。那么新老视角两个能不能同时提升呢?我们发现在ReconDreamer++里面是可以的。
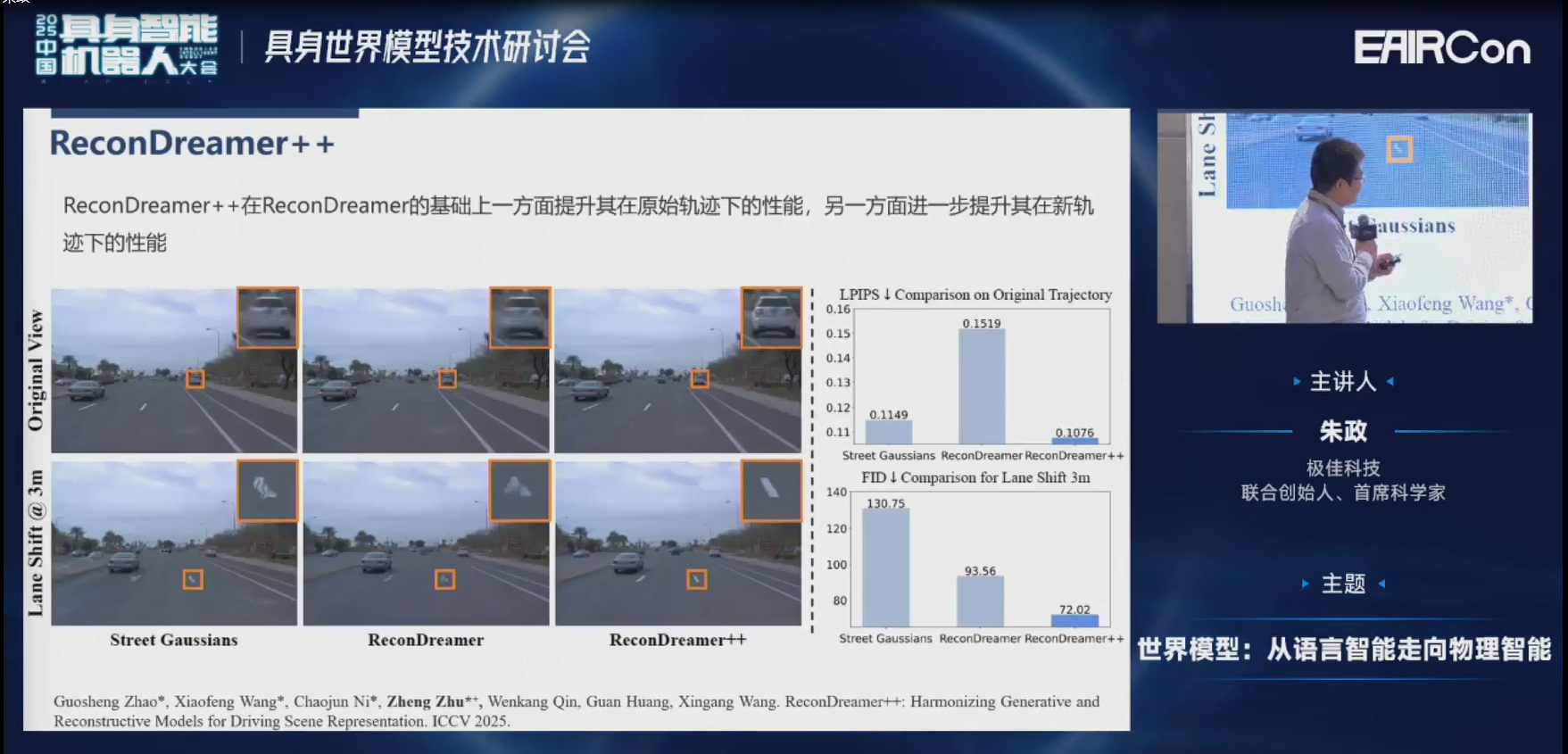
具体来说,我们现在是把整个场景解耦为路面、背景、前景、动态物体,来提升它的几何一致性。另外,我们会把新轨迹的偏移作为输入,来修正高斯球的参数。这样可以缓解生成的新视角数据和原视角数据之间的的gap。
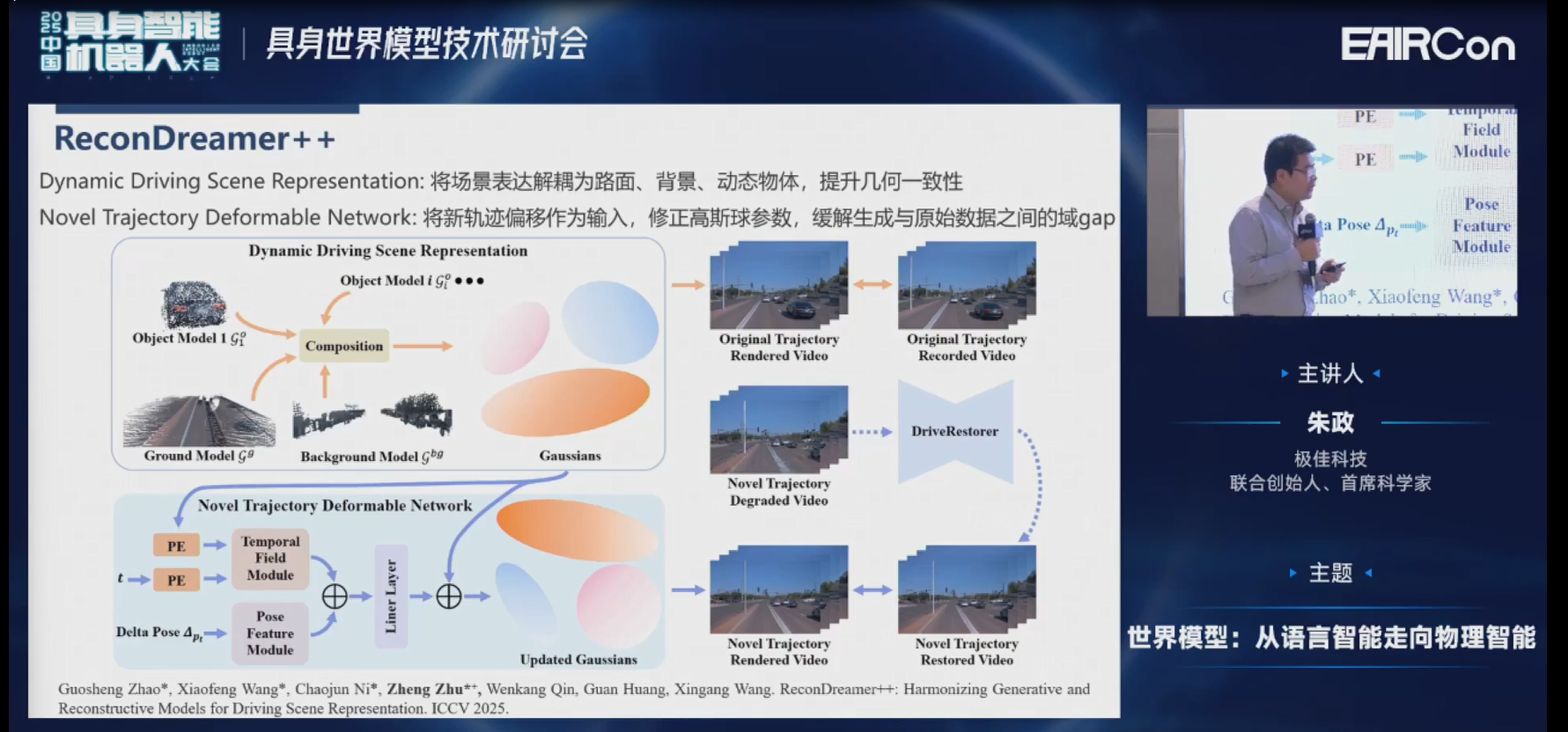
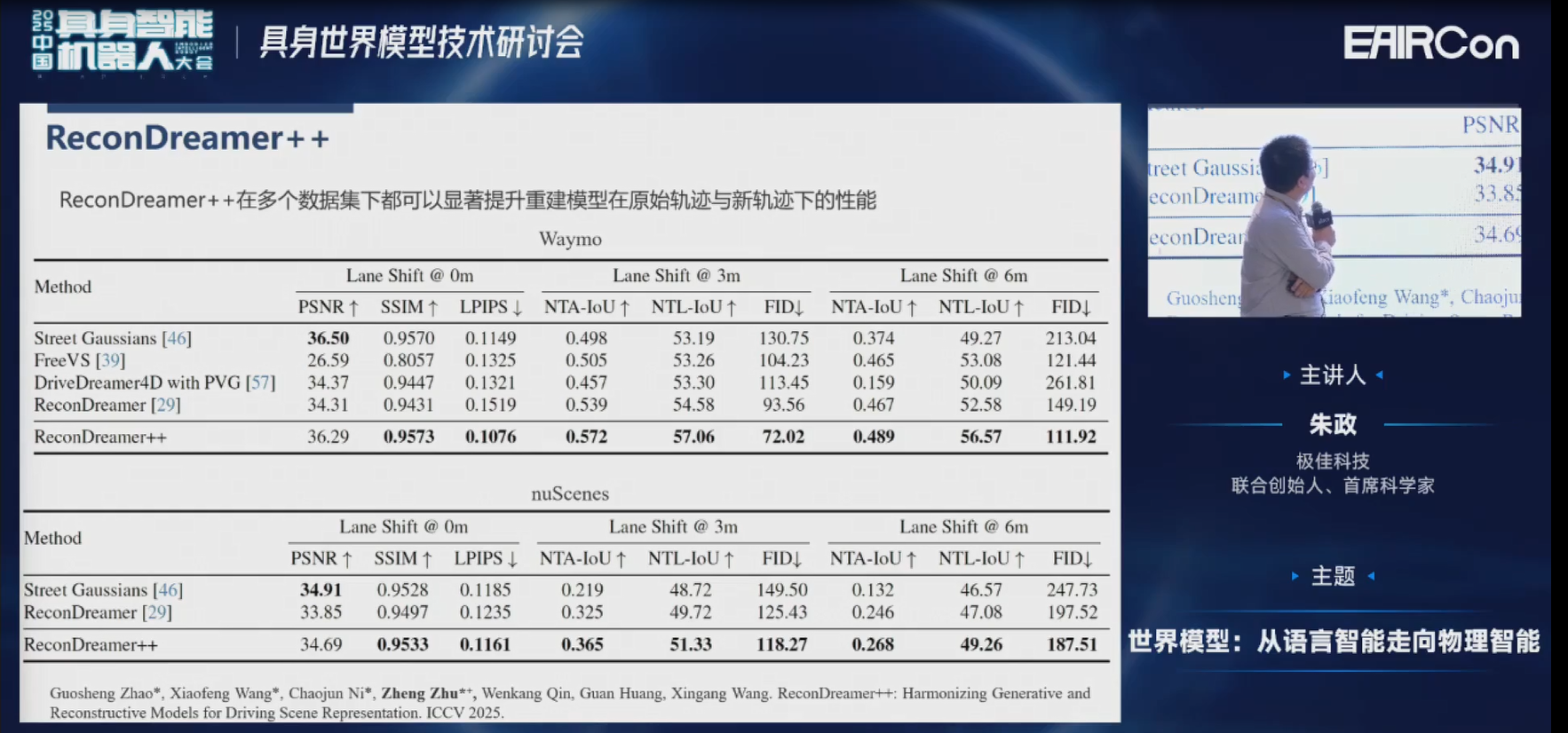
我们接下来看一下实验的结果。这是我们在Waymo原轨迹下的实验结果,可以发现原轨迹也没有下降,可以保持的很好。

然后偏移3米,就是偏移一个车道,效果也有了大幅度的提升。

另外,我们还做了非常多跨数据集的实验,比如Pandaset的实验、nuScenes的实验。
这是一些定量化的结果。因为时间关系,我就不再赘述了。
刚才讲了非常多,生成+重建的工作进行闭环仿真。闭环仿真的一个很重要的目标就是和强化学习相结合。因为强化学习可以探索出更广泛的搜索空间,是可以超越人类水平,甚至超越老司机的丝滑程度。
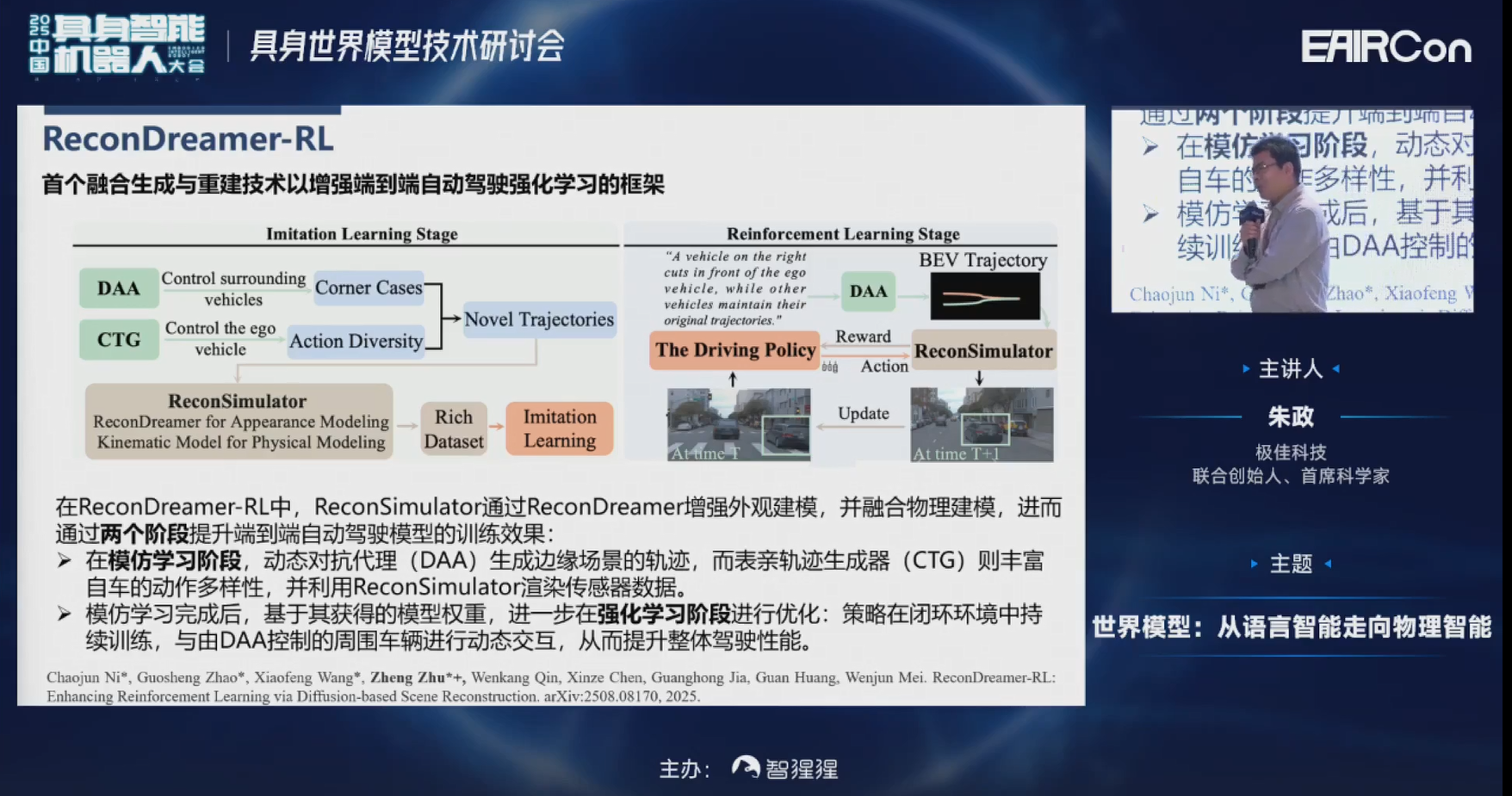
那么,如果把强化学习引入到刚才的ReconDreamer里会发生什么呢?可以来看一下。

因为之前的强化学习算法都是在模拟器里训练的,或者像RAD是在3DGS里进行训练的,所以对新视角的探索可能是不足的。为了避免这种情况出现,用了前面生成+重建的一套pipeline。它可以同时在原轨迹和新轨迹下为强化学习算法提供一个高质量的传感器数据的反馈。

另外,我们会采用一些动力学的模型来确保车辆运动轨迹,在物理上是可行的。

另外,在训练强化学习算法时,大家都知道有一个痛点,就是现在的数据集里长尾分布实在是太少了。比如他车变道、自车变道,或者像一些行人鬼探头等。所以我们对像nuScenes或nuPlan这类数据集也做了非常多的增强。像DriveDreamer-2里,我们可以通过文本来生成他车变道,包括自车变道的行为,可以把nuScenes数据这样的长尾分布进行比较明显的改善。

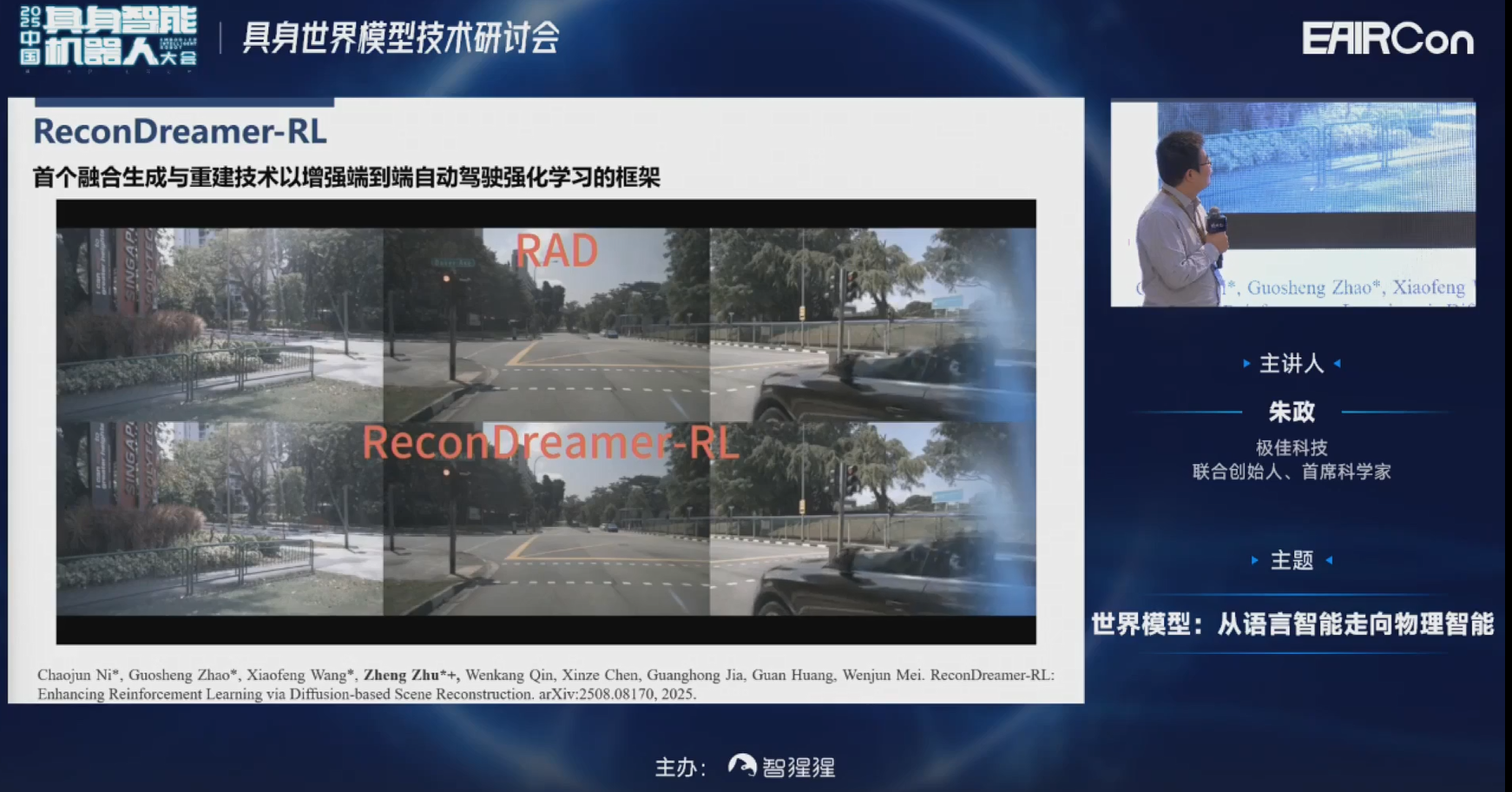
接下来,看一下可视化的实验结果。上面是RAD,它在各种Corner case下碰撞率还是比较高的。但在下面的DriveDreamer-RL里边,基本可以避免碰撞的发生。
四、具身智能世界模型
最后一部分是在具身智能世界模型上。
我们发现appearance,就是物体的外观对于VLA的鲁棒性影响非常大。外观形成的因素比较复杂,包括物体的颜色、材质、光照、拍摄时间不同等,都会对VLA的鲁棒性带来比较大的挑战。所以我们通过EMMA这个工作,对于柔体、流体、刚体的外观做了非常多的增强。

第一行是在真机实采下的一些白色衣服,或在仿真器里布置的一些场景。
第二行是condition的信息,我们用的是depth的信息,这个信息比较容易获取,也比较快速。
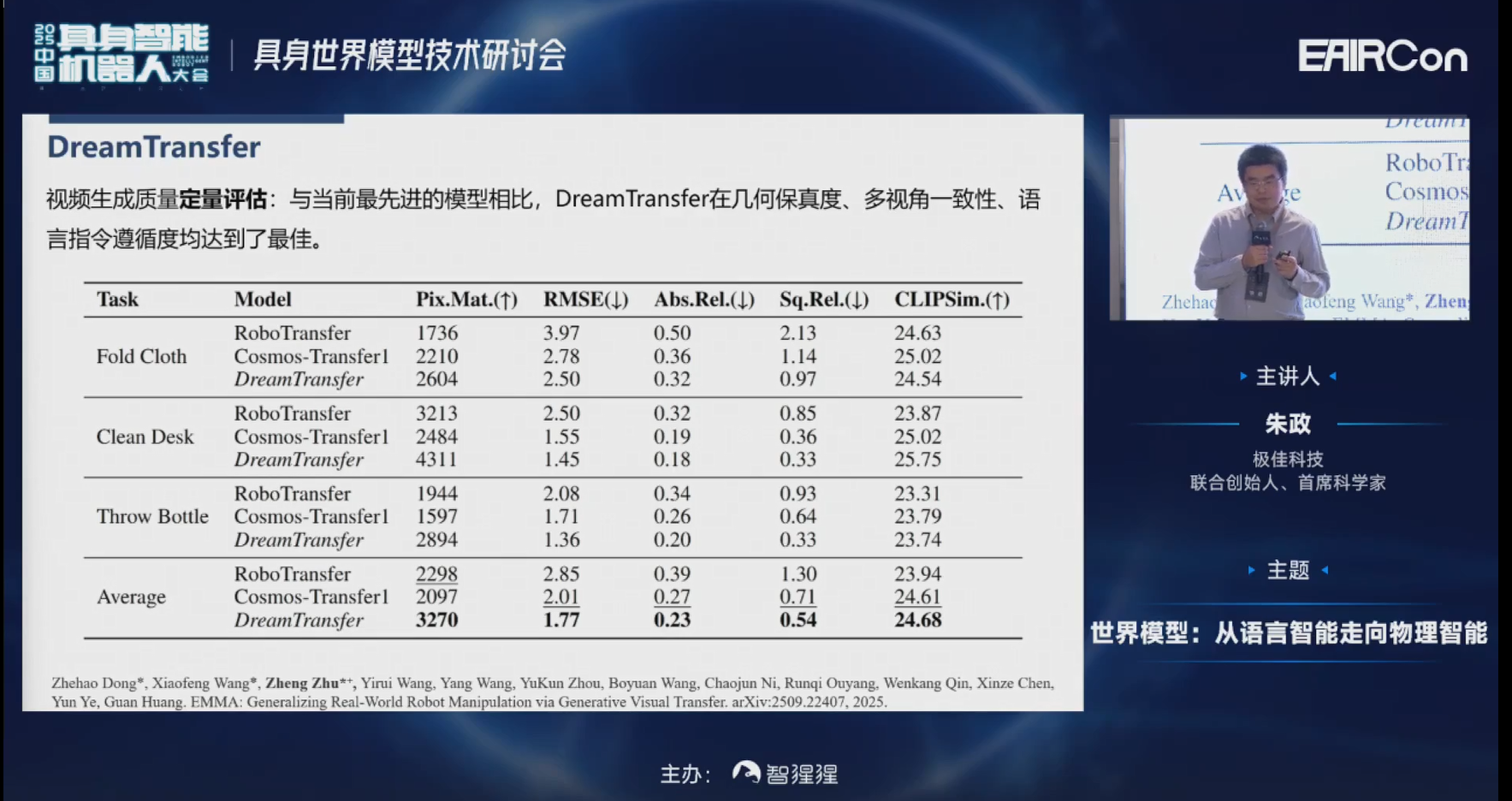
第三行、第四行分别是一些其他方法,比如我们最新的一些EMMA的结果。我们现在可以通过控制条件对多视角一致的颜色、纹理、材质进行比较好的增强。
这里包括了两部分:
第一部分是一个DreamTransfer的模块,主要负责数据生成;
第二部分是生成了数据之后,怎么把生成的数据和真实数据进行优雅的混合,用一种比较好的策略来训练VLA。

DreamTransfer训完之后,它的控制条件是Prompt+Depth的信息。多视角一致,是通过联合建模得到的。模型训练之后,可以通过自然语言指令,对真实或者仿真的数据,进行各种表观、背景及光照条件的编辑。

这是我们一些定量的结果,就不再赘述了。
数据生成之后,因为生成的数据受视频生成模型的限制,不一定所有生成的数据质量都是很高的,里面充斥着大量的低质量数据。所以我们需要先根据一系列定义好的Metrics进行筛选。筛选完之后和真实数据联合训练VLA的时候,还需要对样本进行自动化权重的分配,让模型关注到这些困难的样本,关注到Corner case,以便提升VLA的鲁棒性。

这是我们定量化的实验结果。可以发现,相比较仅用真实数据,在一个全新的测试机器人上,面对没有见过的颜色、光照上成功率只有28%。但是加上我们的数据增强之后,成功率可以达到65%。
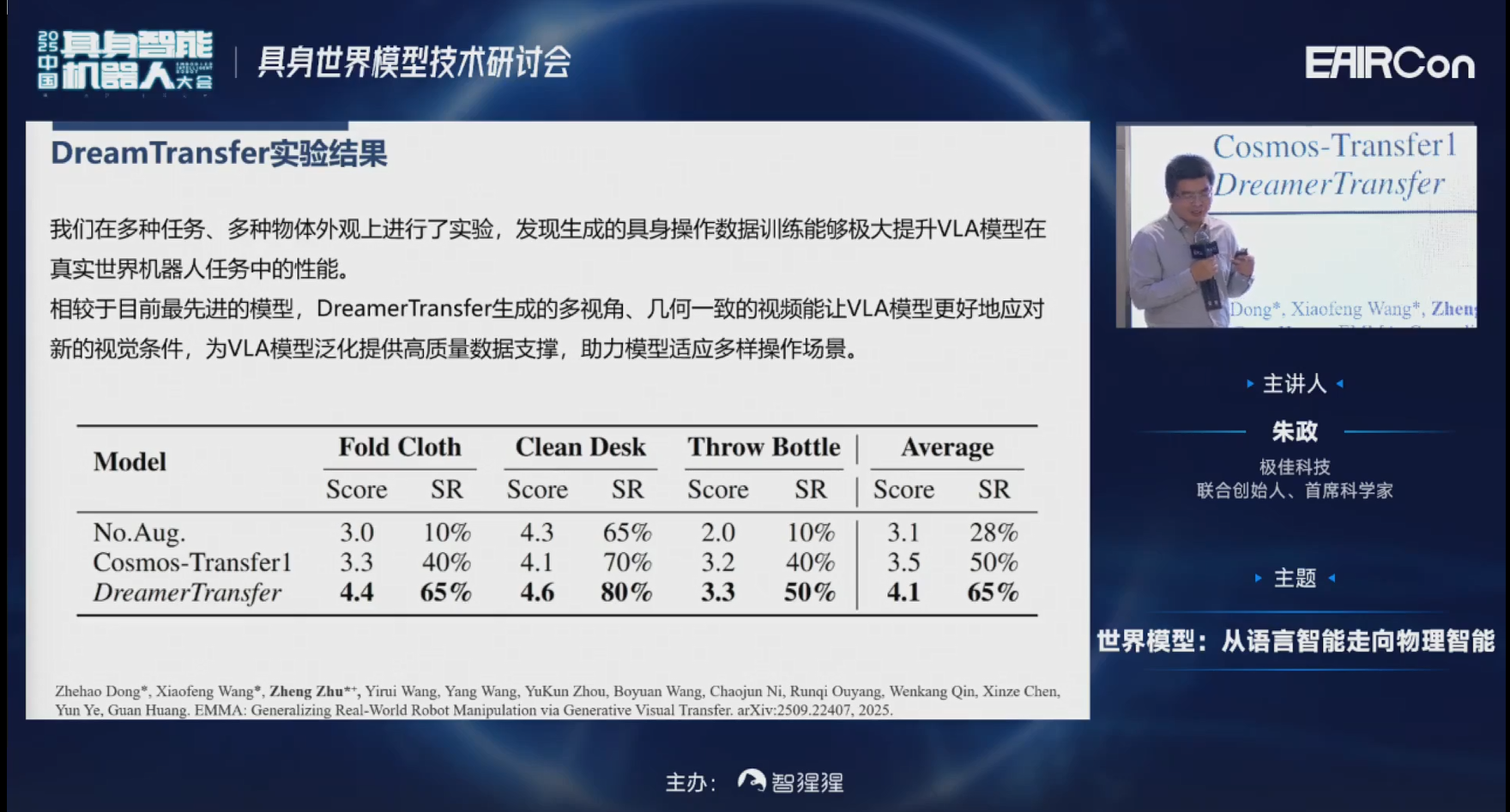
进一步再加上混合训练策略,成功率可以进一步达到78%;并且执行轨迹的质量也有所提高,平均执行时间变短了。
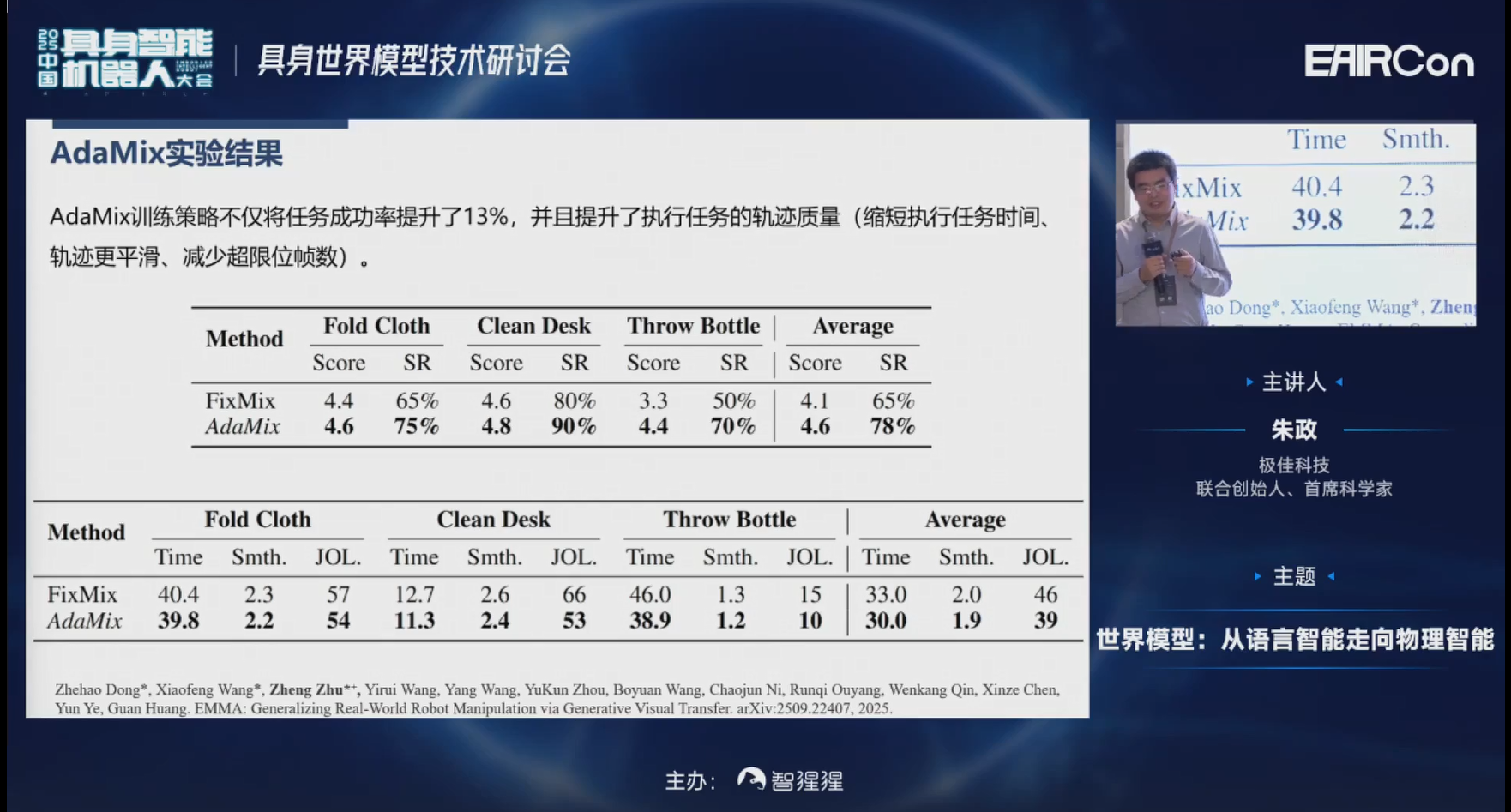
接下来看一下可视化的效果。第一行是真机采集的数据,第二行是我们的condition,第三行是我们生成的多视角一致增强之后的数据。

这是一些仿真实验的结果。

这里是更多的一些实验结果。

接下来看一下VLA的实验结果。这个模型在训练的时候只见过白色或黑色的工服。但在测试时可以叠各样颜色、款式或纹理等的衣服。

在这个实验里,虽然训练时只见过白色的碗,但是inference时对不同的颜色的陶瓷碗,也可以比较好的处理。

这是一个扔瓶子的实验,训练时只见过怡宝矿泉水瓶,但是对于碳酸饮料瓶、可乐瓶子,都可以比较好的处理。

讲完这个表观变化之后,其实机器人在操作时还有非常多其他的挑战。比如另一个挑战是视角的变化,尤其是在机器人加装了移动底盘的时候。因为不可能确保移动底盘每次都恰好停在同一个位置进行操作,它靠前、靠后、靠左、靠右都有可能的。所以VLV的策略需要对视角也做到鲁棒。

这个时候,我们可以通过一系列方法对于视角也进行增强。比如可以先进行视角的变换,然后进行一个action retargeting,最后就可以把原视角变换成新视角。当然变换过程中也会因为观测不到视角,出现一些黑块、变形等。所以我们会用一个视频生成模型进行修复。最后,这些生成的数据就可以和原来数据混合在一起,训练policy的策略。
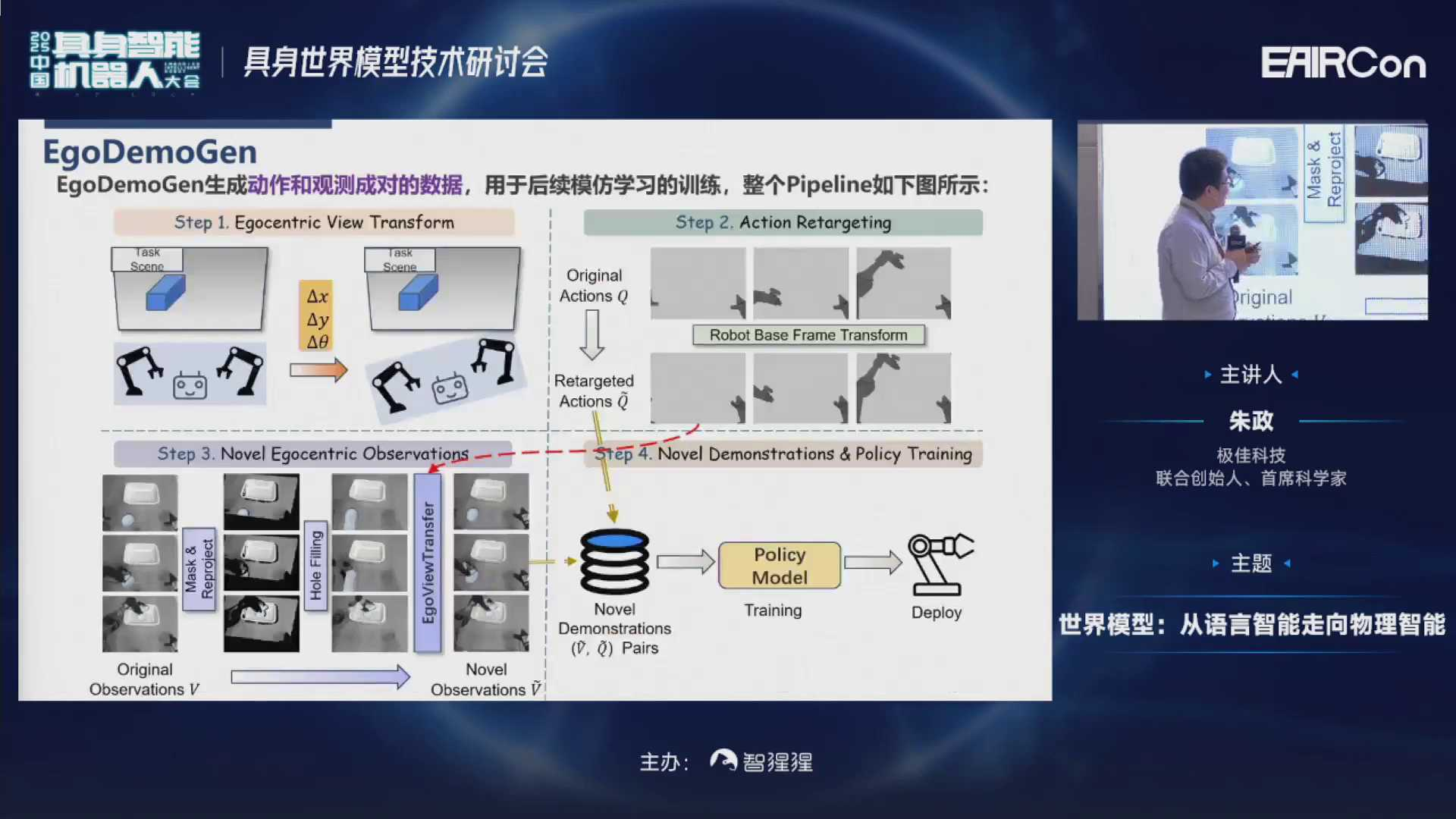
在这里可以发现,不管是在仿真环境还是真机实验下,加上EgoDemoGen之后,在标准视角和随机新视角下,成功率都有所提升。

可以看一下一些可视化的实验结果。第一列是标准的视角,第二列、第三列分别是一些新视角。可以发现,基本上视角的变换对于policy执行是没有什么影响的。

我们来可以看一下中间的一些实验结果。这个第一列是原视角的,最后一列是变换完新视角的。中间倒数第二列是我们加了一些机械臂的约束来保证生成质量。

除了表观会变化、视角会变化之外,另一个就是前景物体本身的姿态也会变化。比如我要去拿桌子上的水杯,水杯每次可能摆在不同的位置。这时候可以通过采集一条人类的演示,然后对前景物体进行各种自由组合来达到这个目的。
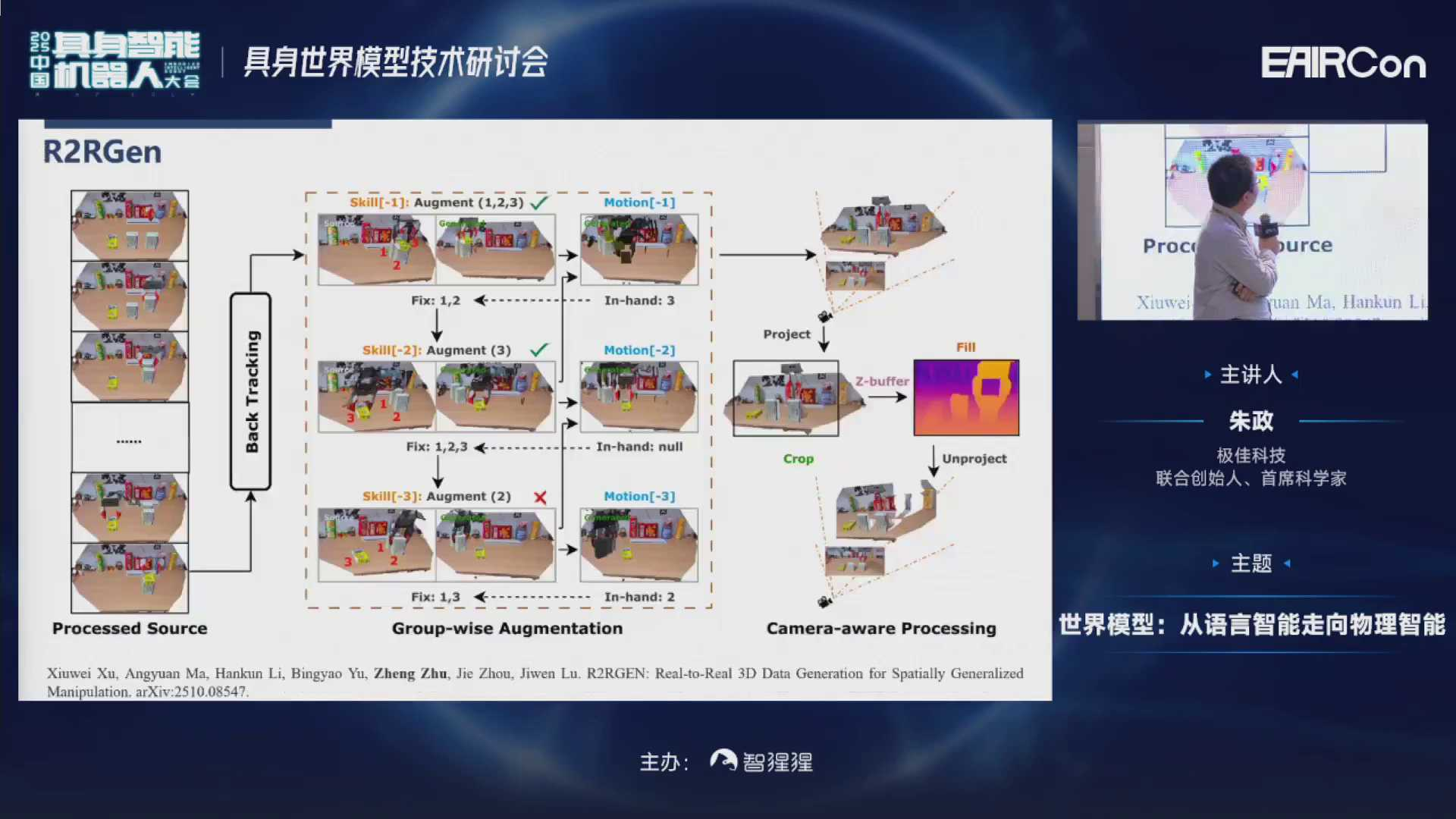
我们可以看到这个视频。先采集一条这样的数据;然后通过Real2Real的方式对点云进行操作,组合出各种前景不同的变化;最后,这些模型可以被混合起来,去训练一个新的策略网络。(链接可查看视频:https://mp.weixin.qq.com/s/VmuUURZnwirvz1D1Lm_mpg)
我们再看一下这个视频。加入这样的数据之后,尤其是在机器人加上了移动底盘的时候,它的视角,包括前景位置每次都可能发生不同的变换。但是模型也可以比较好的执行任务。根据视频可以发现,香蕉虽然每次摆在不同的网格点,但都可以比较好的抓取。(链接可查看视频:https://mp.weixin.qq.com/s/VmuUURZnwirvz1D1Lm_mpg)
除了刚才讲到的可以对真机数据进行各种增强之外,还可以利用互联网第一人称的数据。
互联网第一人称的数据相比较真机数据有两个优点:
第一个是执行速度快,比如我们通过VR等去遥操一个臂,叠衣服大概需要花20秒到30秒。但人手叠衣服非常快,可能只需要花3秒钟就可以叠一件衣服。
第二点是用第一人称数据其实是不需要本体的,很多时候只需要去带一个Vision Pro,带一个VR眼镜来采集关节、手的位置点就行了。
所以在这两个成本的加持下,我们可以获取非常多第一人称的数据。

但第一人称的数据很多时候在直接用的情况下是存在很多问题的,和直接用来训VLV的数据,还是存在的一些视角、动作、视觉方面的差异。

所以我们在MimicDreamer工作里分别提出了三个模块,把这三个差异消除掉,实现三者对齐。然后把第一人称的数据直接用于训练VLV模型。
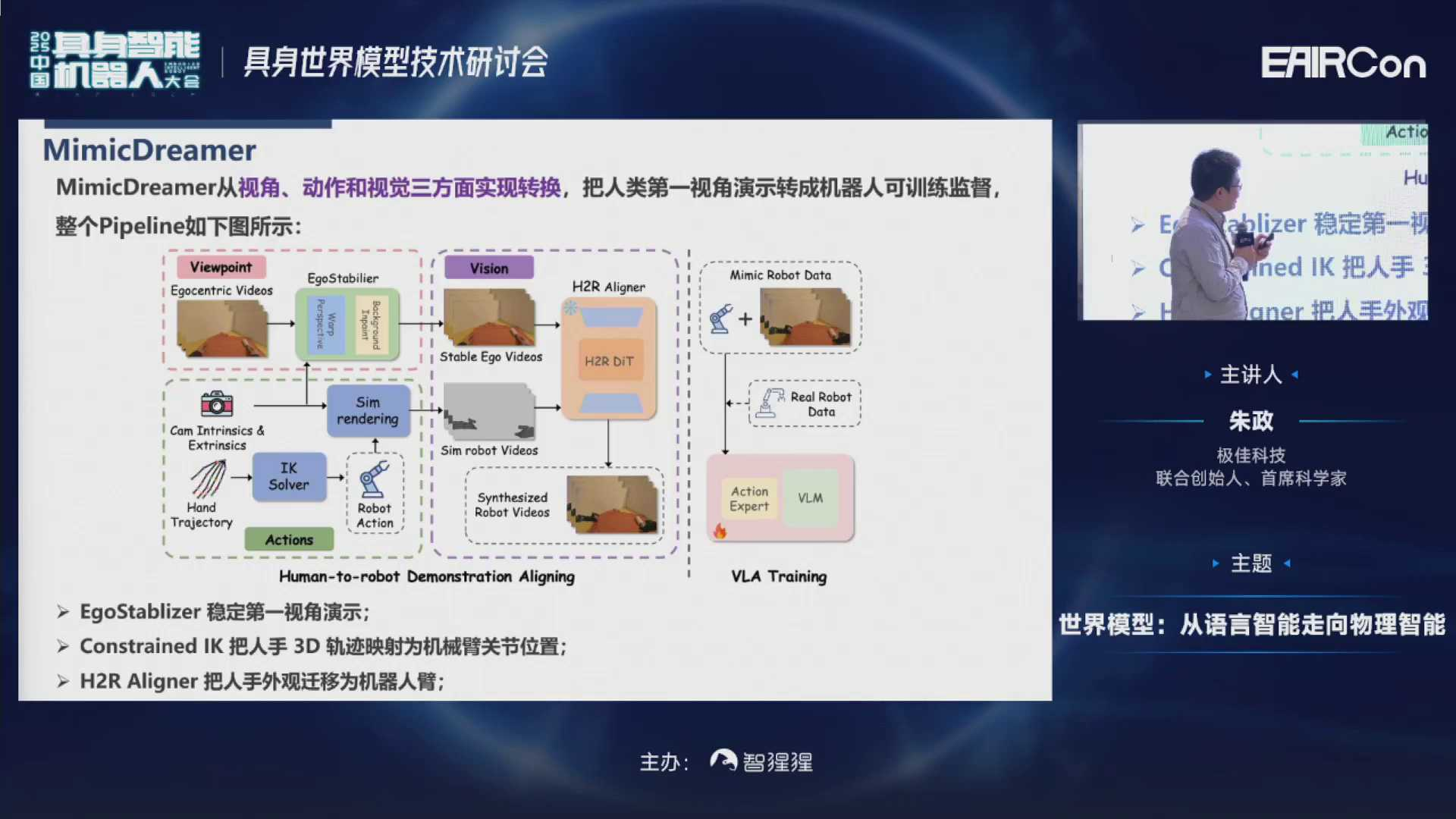
可以发现,在一些定量的实验任务里,MimicDreamer生成的人机对齐数据,结合少量真机数据作为示教,就可以实现few-shot的效果。
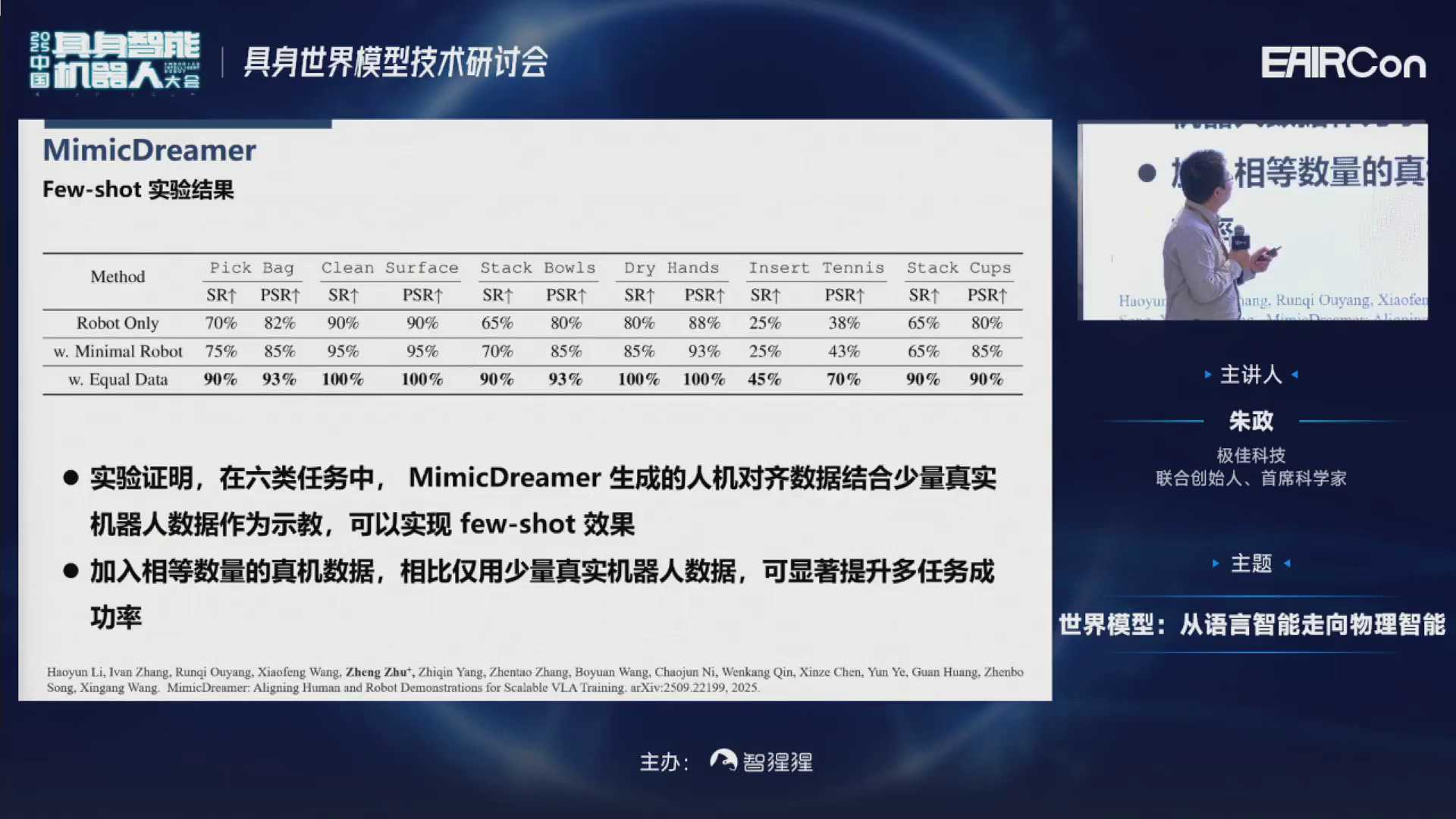
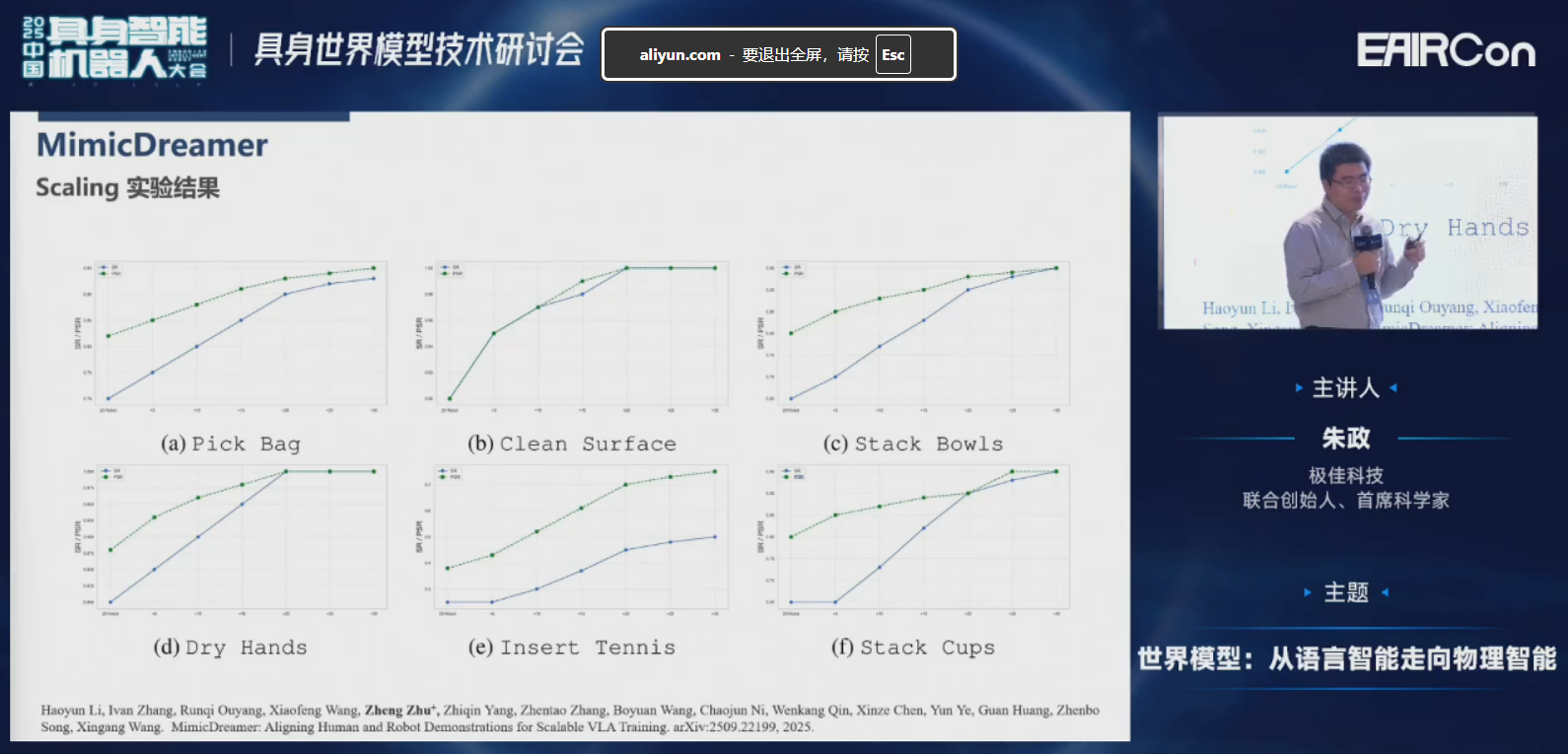
接下来看一下Scaling的一些实验结果。这六张图分别是6种Scaling,纵轴是成功率,横轴是20条真机实验数据,后面分别是加上了第一人称的数据。我们发现:随着第一人称的数据越加越多,整体成功率有比较大的提升的。
这是VLA执行的一些结果。所有的VLA执行结果都是在第一人称数据下进行训练,然后直接部署的。

基于上面讲的各种各样世界模型的加持,我们也做了一款产品叫GigaBrain-0,这是第一个由世界模型驱动的VLA系统。在这里面我们用到了真机数据、视频生成的数据、Real2Real的数据、Sim2Real的、视角变换的数据,以及第一人称视角的数据。

相比较其他的一些系统,比如π0、π0.5、GR-3、GR00T N1.5,我们GigaBrain-0数据涵盖面应该是最广的。

最后看一下我们的宣传片。这是不同视角拍的,一镜到底的视频:机器人把衣服从洗衣机里拿出来,然后搬到桌子上,最后再把它叠好。(链接可查看视频:https://mp.weixin.qq.com/s/VmuUURZnwirvz1D1Lm_mpg)
还有一些Sim2Real的实验数据,Real2Real的数据、视角变换的数据,还有根据相同的首帧给它不同的promote,生成的数据,以及第一人称的数据,转换成机械臂的数据。
另外,还有一些机器人冲倒咖啡或饮料的数据,这样的数据在仿真引擎里是很难得到的。还有收拾桌面的一些例子,人可以随机打断它,然后给它布置一个新任务。
还有一个撕卷纸的例子,是我们用夹爪来完成的,还是比较困难的,因为我们没有用灵巧手或触觉传感器。这个机器人叠衣服的例子是实际速度播放的,它会先把衣服抖平,再去叠衣服。
所以,现在的具身智能世界模型,我们首先进行了第一步的探索,就是做数据的增强,可以给VLA提供这么多的数据。第二步是现在我们正在探索的,用世界模型去构建一个模拟器,然后用强化学习在里边训练VLA模型,代替之前在模拟器里训练的,它会存在Sim2Real的gap。
此外,我们也可以代替π*0.6用的真机强化学习,因为它需要Human-in-the-loop。我们现在正在探索这件事情,大概今年年底会发布相关的一些工作。最后,我们希望VLA会融合一部分世界模型的知识,变成下一代的WA (World Action Model)。
以上就是我今天的报告,谢谢大家。
