








EAIRCon 2025中国具身智能机器人大会是由智猩猩面向具身智能与机器人领域发起主办的大型会议,由主论坛+专题论坛+研讨会+展览区四大板块组成,近40位产业代表与青年科研人员与会分享和讨论,线下参会观众超过1000人。
清华大学自动化系长聘副教授、灵御智能创始人兼首席科学家莫一林受邀在大会主会场下午的具身智能人形机器人专题论坛带来报告,主题为《具身智能机器人的实现路径探析》。
清华大学副教授莫一林表示,我们最终希望机器人能实现三角形的愿景,即成为一个通用、自主且高效的机器人。但路径仍不明确,目前具身智能的发展甚至可能比07年自动驾驶还要早期。核心原因是数据非常稀缺,通用、高效、自主存在矛盾,也并没有找到很好的人机交互方式。
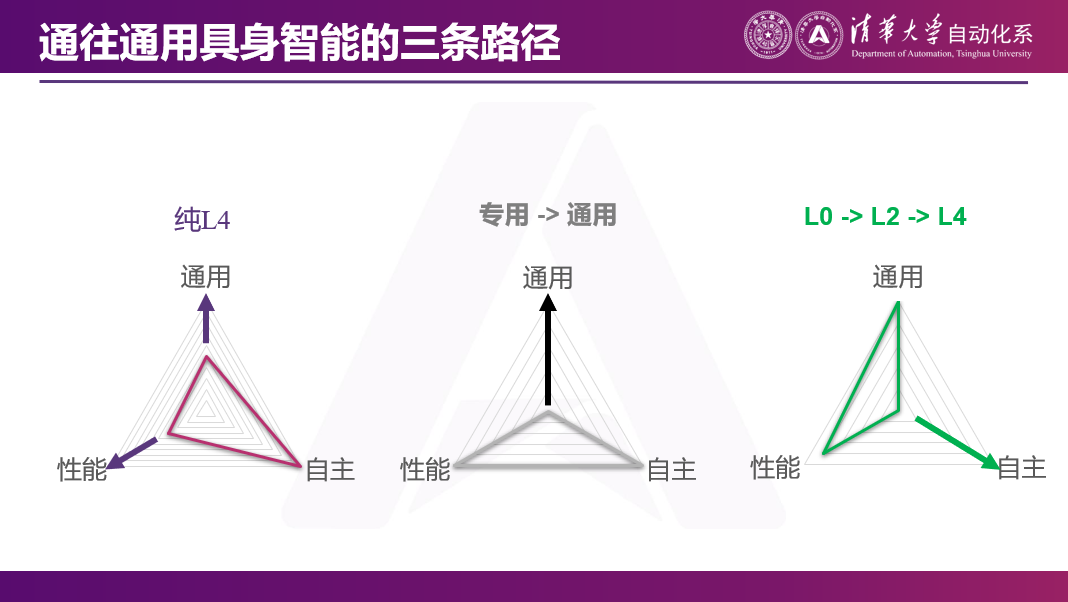
在现在的三角不可得情况下,莫一林老师总结了以下三种技术路线:第一种是基于全自主的模型,在自主的基础之上逐渐提升通用和性能;第二种是在专机的基础上增加通用性;第三种是类似于自动驾驶的技术路径,先通过人类操作实现机器人的落地应用,保证效率和通用性,再逐渐通过采集真实数据,提升自主性。
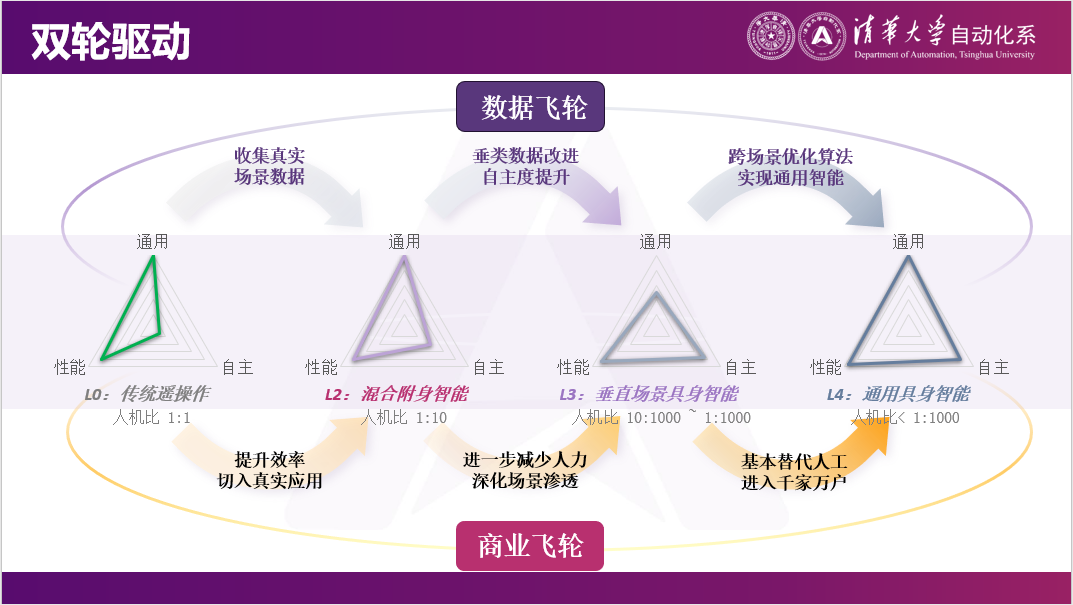
莫一林老师选择的是类似自动驾驶的路线,以遥操作为切入点,先确保通用和高效,牺牲自主性;再通过在真实世界中采集真实数据,逐步实现L0-L2-L4的过渡。
以下为莫一林老师的报告全文:
莫一林:各位老师同学大家好。非常感谢主办方的邀请。向大家自我介绍一下,我是来自于清华大学自动化系,之前主要在做控制理论。机器人是一个很复杂的系统,今天上午也有很多老师讲过。从某种角度来说,控制做的是机器人底层的,类似于如果给机器人发一个指令,让它去实现这个指令,并在过程中克服外界的干扰。
后面我们逐渐在做一些机器狗,或上肢机器人。大约从去年开始,我们逐渐接触到具身智能的概念,并进行了初步探索。我其实在学术圈也做了很多很多年了,也有一些自己的思考,所以也算抛砖引玉,给大家讲一些我对具身智能机器人的理解。
一、具身智能机器人是最具潜力的发展方向
具身智能现在是一个非常火爆的事情。不管是从国家政策的支持,还有资本的下场,包括很多知名企业都在做。

我们回顾整个过程,不管是具身智能的DeepSeek moment也好,ChatGPT moment也好,我们都要去看当中一些重要的时间节点。
我们首先要提到的是2019年OpenAI在Science上发表的一篇论文,这是他们用的灵巧手,这种灵巧手很贵,可能需要100万一只。他们做了通过强化学习控制灵巧手来单手拧魔方的视频。这件事情最开始大家都认为是非常困难的,因为手和魔方之间的接触很难用传统的方法解决。比如,手到底什么地方碰到魔方,这件事情是很难建模的。所以在2019年,OpenAI展示了一种基于强化学习的方法,不光是在打游戏或下围棋能够实现很好效果,而且在真实机器人应用中也能实现很好的效果。
2020年,ETH团队在Science Robotics上首次将强化学习算法应用于他们设计的ETH animal机器狗上,从而实现了优于传统控制方法的效果。
后来到了21年,也是我认为一个很大的突破是NVIDIA推出了Isaac仿真环境。因为比如19年OpenAI在做这件事情的时候,使用了百台计算机集群。这是因为要进行物理世界的仿真,尤其是模拟手与魔方的交互,最初只能通过CPU进行仿真,这就需要大规模的集群和众多CPU核来做这件事情。但Isaac仿真环境使得物理世界的仿真在GPU上实现。现在,甚至一张消费级的NVIDIA显卡就可以跑数万个机器狗的仿真。这个在19年的时候,可能需要百台CPU集群才能做到的。这些都是跟强化学习有关的。
到了2023年,谷歌推出了第一个VLA模型,第一次把language引入到机器人中,这也是一个现在非常主流的技术路线。

今年4月或5月,谷歌推出了名为Gemini Robotics的模型,该模型能够执行多种操作,包括处理柔性物体。它能够听从人类的指令,并根据这些指令做一些东西。(链接可查看视频:https://mp.weixin.qq.com/s/ag4dmZ9m2iS0kXlT_AEzBQ)
大家的VLA模型放出来的demo都看上去是非常好的。但PI放出了很多失败的案例。这是π0模型的一些失败的案例,而且是经过长时间加速的。可以看到它反复的展开衣服,包括尝试把盘子里的东西夹起来,然后放到盒子里面,最后还导致一些东西掉出来了。事实上我认为这些单纯的通过模仿学习的VLA模型,在很多情况下,其实并没有达到可用的程度,可能会放出很多漂亮的演示视频,但它距离成功率达到99%或99.9%,还是有很大距离的。(链接可查看视频:https://mp.weixin.qq.com/s/ag4dmZ9m2iS0kXlT_AEzBQ)
这是我觉得是今年一个很大的突破,是Dyna发布的一个demo,引入了在线的真机强化学习。包括像最近的PI新发布的π0.6。Dyna 发布的模型通过真机和真实物理世界产生交互,可以达到99%的可靠性,或非常长时间的运作,不需要人来中途干预。这是我认为是今年一个非常重要的突破。

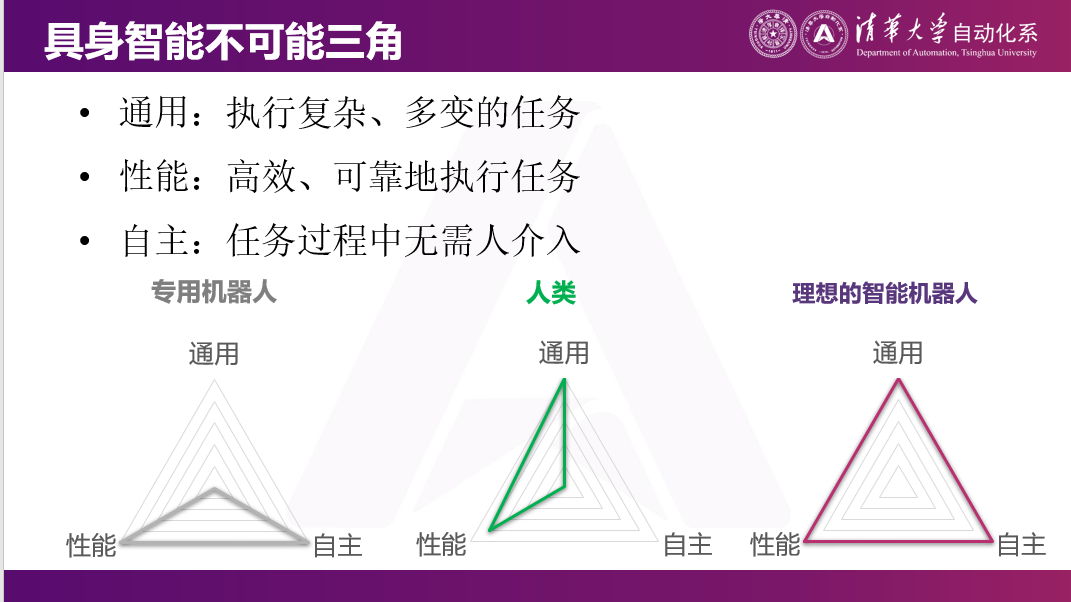
二、具身智能不可能三角:通用、性能、自主
这一次具身智能机器人和之前的机器人有什么区别?我觉得核心是之前我们做的更多的是专机,比如工业机械臂,是被编程好来做这件事情的;我们做一个扫地机器人就只能扫地,干不了其他事情。
我们这一代机器人,之所以选择人形或其他各种灵活的构型,核心目标是希望在之前专机的基础之上,还能做到通用。如果要分析一个机器人的各个性能指标的话,我觉得这三个维度是最核心的:通用、性能、自主。
通用就是它可以在复杂环境下执行多样任务,甚至是之前没有见过的任务。
性能某种角度来说有两个方面:一个方面是干的事情有多可靠,成功率有多高;另一方面就是干这件事情的速度,能不能以一个接近人类甚至超越人类的速度把这件事情做好。
最后是自主性,就是我这个机器连续运行多长时间,没有人干预,这是我们希望做到一件事情。
事实上,上一代的专用机器人是有非常好的性能。在很多情况下,这些工业机械臂、扫地机器人等可能干的比我们自己都好,因为它们在干非常专的事情,同时可以做到100%的自动来干这件事情。
但另一方面,人肯定是通用的,什么任务都能干。人的性能从某种角度来说也是相当不错的。但人没有机器的自主,这件事100%是人做的。
而我们理想的机器人是这样一个兼具了通用、性能和自主三角形的状态。
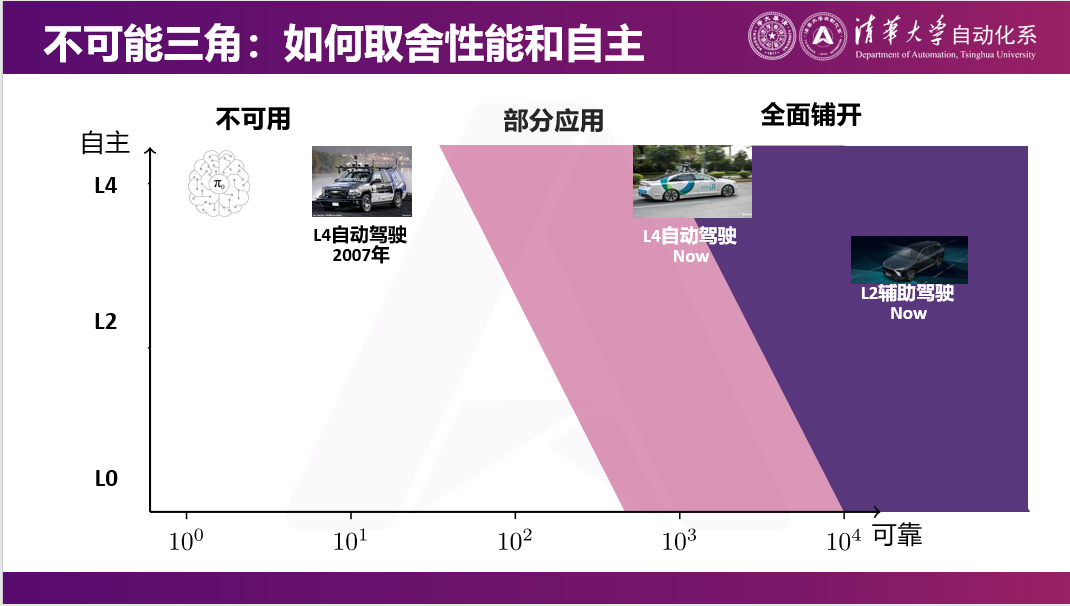
三、具身智能可能比07年自动驾驶还要早期
如果现在我们去客观评价一下,现在具身智能发展到了什么程度。同样我们去看自动驾驶,大概在07年的时候已经可以完成。在DARPA组织的Urban Challenge(自动驾驶挑战赛)里,已经可以完成四、五个小时在城市道路上和人共享道路,没有接管、违规和交通事故。这是07年自动驾驶的水平。
但是到今天,如果说L4级别的自动驾驶,事实上我认为它属于还没有完全渗透到生活中各个方面的阶段,可能是在大规模商业落地刚要开始的阶段。反过来看,辅助驾驶的人机混驾模式。如果现在去买一辆新能源的车,但它没有辅助驾驶,大概率也不太好卖,大家总归是希望自己的车有一些简单的高速巡航等功能。
如果以这个标准来说,07年大概能做到若干个小时不需要去控制这个车。但现在的VLA模型或具身智能在非常复杂环境下,可能就很难做到长时间没有接管,连1小时没有接管都非常难。所以如果从这个维度去看的话,我们甚至比07年自动驾驶可能还要早期。
四、具身智能数据量远小于可用水平
为什么会这样呢?我觉得这个核心的原因是数据,数据非常稀缺。稀缺到什么程度呢?人形机器人或具身智能机器人,现在从机器人身上采集到的最大的数据集大概在万小时到10万小时的级别。最新的Generalist发布的,他说他采了27万个小时,一周可以再多采1万个小时,这是他的水平。
再看一下特斯拉,特斯拉一年获得数据是500亿英里的数据,这是他一年获得的数据,全部都用来训练,比如FSD等,都是用基于这些数据去训练的。
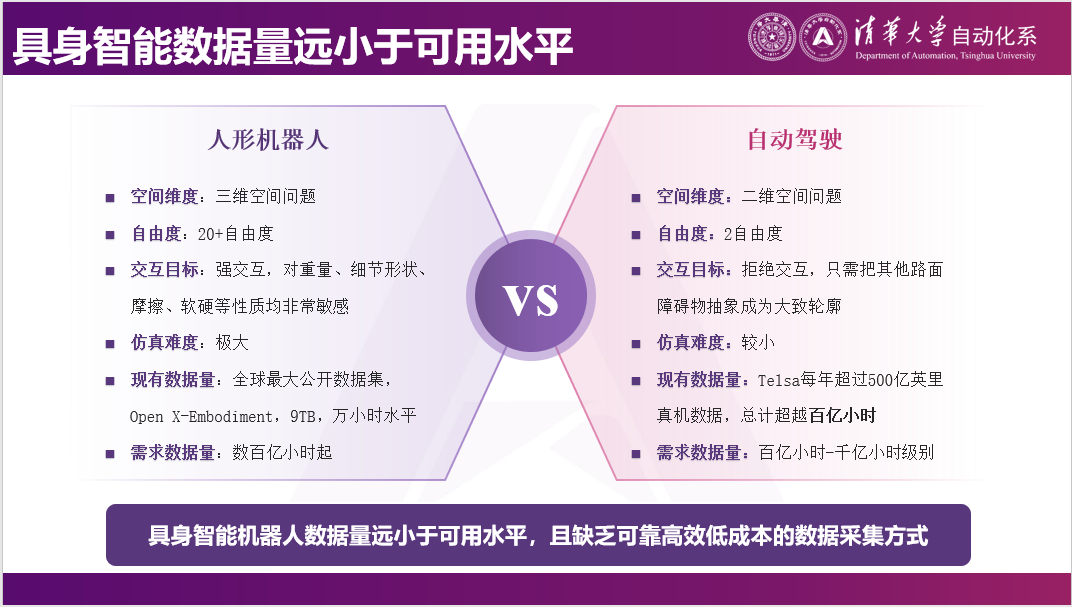
但是对比具身智能和自动驾驶的难度,我们会认为具身智能远远比自动驾驶要困难的多。因为自动驾驶更多的是二维的问题,不需要考虑三维的环境,你的车本身也飞不起来,它的控制量很少,只有油门和方向盘。它不需要和周围的物体产生任何交互,不需要知道这个东西是软的还是硬的,是重的还是轻的,因为不能碰任何这些东西。
反过来说,如果我们要做一个灵巧操作机器人的话,一个机械臂就是六个自由度,一个灵巧手20几个自由度又出去了。这个问题必然是三维空间的问题,而且一定要和物体产生交互,这个物体的轻重、软硬,到底是涩的,还是滑的,这些都会极大影响我和它交互的效果。所以我觉得现在的具身智能机器人上有欠缺,核心的原因是数据非常少。
当然也有很多方法,比如有人提出通过数据增强,或世界模型通过仿真的方式来获得数据。
这个是逐际动力的张巍老师发布的一个demo。但是同样的argument,自动驾驶一样可以数据增强,且远比机器人做数据增强要简单的多。所以是否能够通过简单的数据增强,弥补5到6个数量级,因为现在是万小时对亿小时的差别。如果能弥补5到6个数量级差距的话,技术需要非常强才能做到。
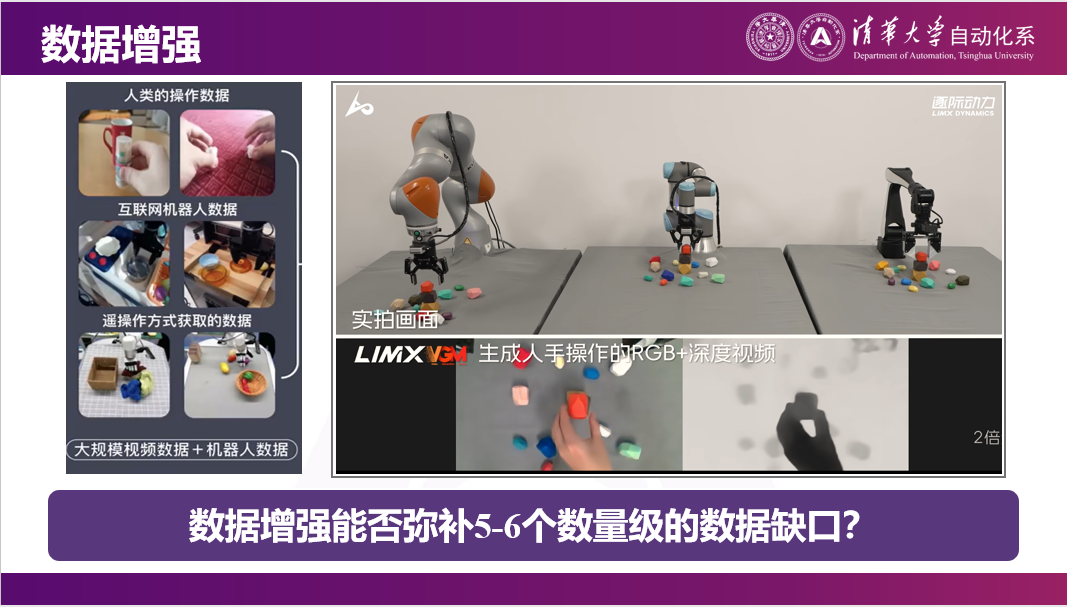
另外,我们也会看到,最近特斯拉开始逐渐用人去采数据。用真人采数据,希望成本能够便宜一点。因为对人来说,就是穿了一套衣服,可能会简单一点。
但是我觉得这个里面其实有两个argument。
一个问题是这件事情是否真的是一个低成本的事情?因为如果用人去采数据的话,不管怎么说,他要佩戴一套很复杂的衣服,也是为了采数据而去采数据。那这件事情就是你付给这个人的工资还是那么多,成本也不一定真的降下来,因为采数据的过程本身并没有产生任何价值。
另外,我觉得还有一个很大劣势,像我们现在国内很多机器人的灵巧手,并没有像特斯拉这么高的自由度。在这种情况下,你用人手去操作一个物体,人能做出来的动作,机器人不一定能做出来。比如我们用一个夹爪,手可能是做了一个拧瓶盖的动作,但夹爪根本就不可能做出这个动作。在这种情况下,你必须要有一个非常昂贵的、拟人的本体,才有可能把人类采集的数据直接用上去。

五、目前没有找到很好的人机交互方式
现在具身智能另外一个稀缺的事情:我们并没有找到一个能很好的和机器人交互的方式。
现在大量的交互的方式,要不然就是不需要交互。比如在各种展会上看到demo,其实那个机器人就是一直在干一件事情,不需要跟它去说话。另外一个方式,类似于ChatBot式的交互方式,像大模型一样,我跟它说一句话让它去干。但这里就有一个很大的问题,比如我现在有一个很杂乱的房间,和机器人说让它把这个房间收拾了。如果大家请过小时工或者家里有人来帮忙收拾的话,那你肯定会发现他收拾的结果和你想象的是不一样的,因为你没有告诉怎么收拾。为了让机器人收拾的结果和你习惯的东西摆放位置是一样的,就需要给它非常多的语言信息,其中是否用语言去交互就很成问题。

因为我做是比较理论的,这里引用了我们学科中一个重要的信息论的结论,就是从信息的角度来说,这件事儿是不可能的。有这样的一个Shannon信息处理不等式。就是告诉机器人一句非常简洁的话,比如把房间收拾了,然后又希望它做这个事情是非常可控,按照你的想法把房间收拾了。这个事情从某种角度来说就是不可能的,因为这个任务很复杂,机器人也没有读心术,它不可能知道你心里想的是什么。所以任务的复杂性,交互的简洁性和机器人在干这件事情当中的可控性,这几件事情是矛盾,是由Shannon信息处理不等式所决定的。我们老祖宗也说,书不尽言,言不尽意。你说一句话,别人的理解肯定是有偏差的,是不一样的。

实际上如果我们以这个角度去思考问题的话,可以想象自动驾驶本身是一个比较well-behaved,是一个定义的比较好的问题。因为自动驾驶的任务是简单的,就是从点A到点B。比如我告诉它去机场,这个任务一旦设定所有信息量就告诉它了,机器是一个完全可控的状态。它就是去机场,交互也很简洁,任务本身是一个简单的。
另外,有时候就是需要机器人很可控,它在执行一个很复杂任务,交互必然复杂。比如手术机器人,医生要做一个远程手术的话,需要一直控制机器人在做这件事情。
另外一种可能性就是任务很复杂,交互很简洁。结果就是这个机器人不是听你的话在做,而且按照它自己的意志做这件事情。这个事情发展到极致,可能就是类似于像终结者这样,这种东西是不是可以被接受的呢?今天上午有很多老师讲安全,讲伦理,这个我觉得是一个需要去探讨的问题。
六、遥操作是一种人机交互方式
所以我觉得即使是在现在,做具身智能很大程度上是受到LLM的影响,一个自然的与智能体交互的方式,就是和它说话。这件事情我觉得是一个很值得探讨的事情。尤其是当你与一个物理世界的智能体互动时,比如通过手势、眼神或指向某个物体的方式,是否是一种更有效的方法?我认为在许多情况下,答案是肯定的。肢体语言实际上传递了大量信息,这也是为什么我们认为遥操作本身并不是一个很low的事情,从某种角度来说,是一种和机器人交互的方式。

七、当前几种具身智能的技术路线
我们最终希望机器人能实现这个三角形的愿景,即成为一个通用、自主且高效的机器人。但在现在的三角不可得情况下,我觉得有几种可能的技术路线。
第一种是基于π0等全自主的模型,我们已经看到现在已经能够在全自主模型上,尽量让机器人更高效的完成更多任务,在自主的基础之上去做通用和性能的提升。
第二种是在专机上增加通用性。比如在扫地机器人上加一个机械臂,它不光能扫地,还能把地上的东西捡起来。比如在工业机器人上增加摄像头,那它就能看到那个工件,可以直接算出来不同的工件怎么抓,不需要编程。这是从专用到通用的技术路线。
另外一条相对易于想象,是类似于自动驾驶的技术路径。我们先通过人类操作来实现机器人的落地应用,在这个过程中,机器人的自主性较弱。落地之后,因为背后有操作员,可以保证效率和通用性。然后,我们再逐渐通过采集真实场景中的真实数据,逐渐过渡到自动驾驶。
这是两个例子。上面是今年石头发布的一款带机械臂的扫地机器人。下面是一个梅卡曼德做的深框抓取的例子。在这个例子中,它是通过一个摄像头,来分辨各种奇形怪状的物体应该怎么样抓取。

另外,我们也认为上午星尘智能的老师分享的路线可能是另一个可行的方案。这条路线是从无自动驾驶功能逐渐过渡到人机混合驾驶,最终实现完全自动驾驶。这就需要人与机器人的紧密配合。因为以前的机器人纯粹就是一个机器人,如果是自主的话,那也不需要人。但现在就需要开发一套人侧(硬件),怎么让机器人去理解人的意图,还需要让人和机很好的配合起来。

这是我们做的一些工作,是机器人在做力控问题。因为在现实生活中,并不是人的手在什么地方,机器人手就应该在什么地方。一个很简单例子是,人的手在这儿,但是机器人为了到这儿,要打穿一堵墙。它到不了这个地方,要不然把墙打穿,要不然把自己手打坏。所以现实中的机器人,为了和真实世界中受控的物体产生交互,一定是力控的状态。也就是说机器人是柔顺的,能够分辨出在什么方向上应该施加什么力,在什么方向上又应该是有弹性的。(链接可查看视频:https://mp.weixin.qq.com/s/ag4dmZ9m2iS0kXlT_AEzBQ)
左边是我们做的用粉笔写字的例子。用毛笔写字更多的是关于位置的控制,因为毛笔本身是软的。但是用粉笔写字时,为了保证每一笔都写的非常准确,不能抬笔,不能落下,也不能用太大的力气,这就需要对桌面施加一个相对恒定的压力。右边是叠衣服的一个例子。这两个例子虽然都是通过遥控来做到的,但遥控可以达到非常好的上限,可以完成非常通用的任务。
八、遥操作机器人的核心应用场景
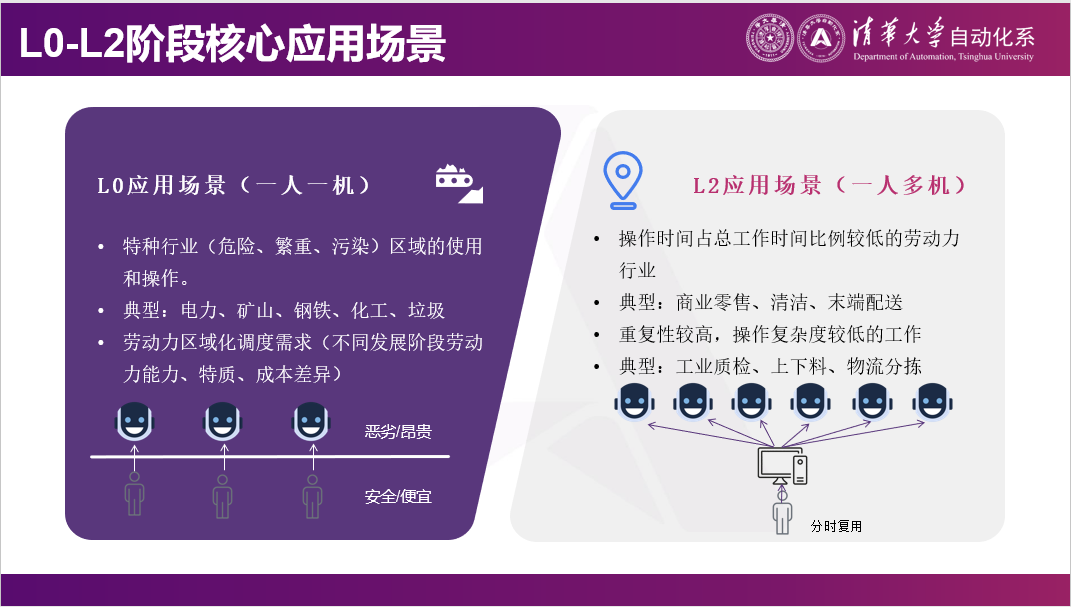
事实上我们也跟很多人在聊,遥控机器人是不是有一些落地场景。实际上,单纯的遥控在很多情况下已经可以产生一些应用了。比如有很多危险场景,最常见的遥操作已经落地的例子是无人矿山。因为矿山里面很可能就是有时候会出现事故,所以希望遥操作一些挖掘机等。
另外,就像今天上午星尘智能的老师说,有一些劳动力的价格是有差别的,如果能远程操作的话,就能用一个比如墨西哥人去控制美国的机器人,或者用一个马来西亚人去控制新加坡的机器人。
还有一类非常有意思的应用,也是当时找到我们,但我们没有想到的。这些应用并不希望人出现。比如在养殖业,人身上会携带各种病原体。在养猪或养鸡场,如果人进去,可能会携带病原体,那可能人感冒了,动物也会感冒。再比如金库,如果人进去,在金库里面进行某些操作,再出来,那就需要很多安全手段来防止人把东西拿出来。但是机器人可以永远关在里面,永远也不出来。所以这种纯粹的遥控已经有一些例子了。
另外还有一些非常有趣的场景,我们把它定义为操作比较少的场景。例如工业巡检与维护,机器人大量的时间是在导航和移动上。在这个情况下,人就不需要在机器人导航的时候,在背后盯着;或者完全可以一个人盯着比如十个机器人。那机器人在移动或处理简单任务的时候,就是它自己在做。但是当机器人需要比如拧一个阀门或摁一个按钮等专用的维护操作时,就可以切到人类模式。
今天上午我们都在畅想具身智能未来可能的发展路径。我觉得在五年甚至十年之内,可能会看到很多遥控机器人。当然它不一定是百分之百时间在遥控,可能有10%的时间是在遥控的,但它背后终归是有一个人的。通过逐渐把人机比提上去,把经济的账算过来。在这个过程中,我们也可以采集大量数据,像自动驾驶一样,逐渐实现自动驾驶。
因为数据很少,另外一个很重要的就是一些传统的机器人经典算法,是不需要数据的。比如像我们之前做的模型预测控制、全身控制等,是不需要任何数据就可以做的。但因为这些没有真实数据,所以在真实场景里性能不是那么好。

但后面像我之前提到的19年OpenAI、20年ETH把强化学习引入了。但是事实上我们现在做强化学习,很多时候都是在做一个非常通用的神经网络,比如这是一个奔跑的机器狗,强化学习就需要和真实世界交互,需要在真实世界中采集很多数据。
我们觉得一个好的事情是:不一定要通过强化学习训练一个非常通用的神经网络,可以把一些知识预先内嵌到被学习的对象里。举一个很简单的例子,大家在伸手抓一个东西的时候不会想我的每一个关节到底应该弯曲多少度,因为这件事情是直接计算出来的。在机器人里叫逆运动学,这件事情也可以直接计算出来。比如机器人想抓这个东西,不需要强化学习的算法告诉它每个关节要多少度,只需要告诉它末端要到什么地方,可以自动把这件事情算出来,那就省掉了对机械臂的学习。

同样的,比如换一个更长的机械臂,或者一个更短机械臂,因为背后的算法都在这个地方,可能会有更好的迁移性能,而且学习的也会更快。
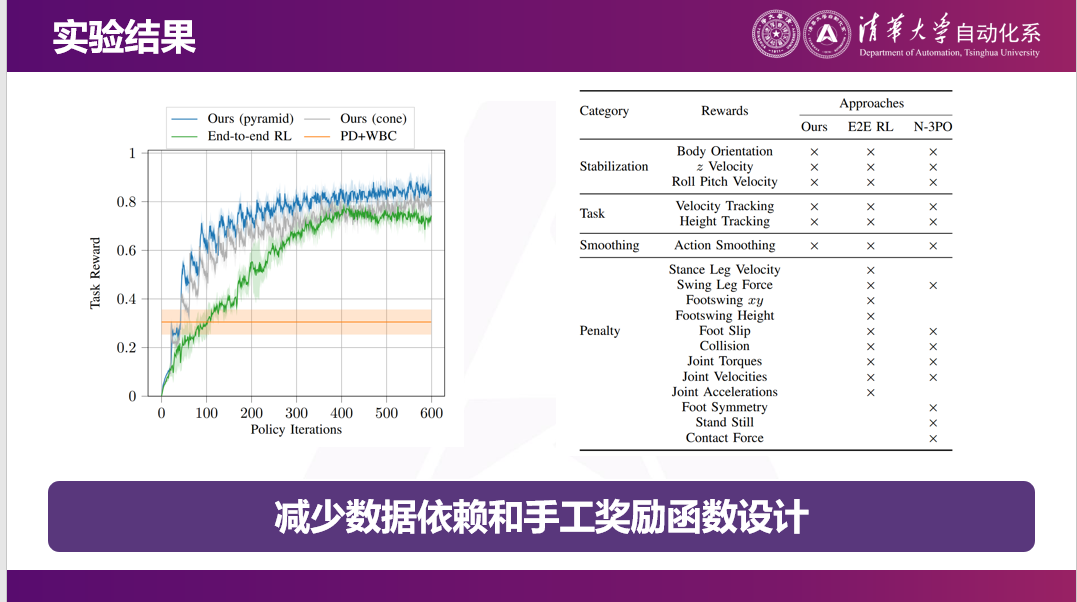
这是我们最近在TRO上的一个工作,这是我们最后实现的效果。传统的强化学习就没有办法做到约束的保持。但因为我们内嵌了很多结构信息,就可以做到机器狗在地上不会打滑,也不会把这个东西给踩漏。(链接可查看视频:https://mp.weixin.qq.com/s/ag4dmZ9m2iS0kXlT_AEzBQ)
最后总结一下
我觉得具身智能的目标是明确的,应该实现通用、高效、自主这三件事情,但它的结果是不明确的。这里面最核心的就是数据缺口。在这个数据缺口的情况下,可能只能实现这三个目标中的两个。我们选择的一条路线可能是通过遥控的方式,牺牲自主性,逐渐提升自主性,先确保通用和高效。
我汇报就到这里,谢谢大家。

