








智东西(公众号:zhidxcom)
文 | Lina
昨天,英伟达2017 GTC China(GPU技术大会中国分会场)在北京举行,智东西作为特邀媒体,从Keynote大厅第一排发来CEO黄仁勋主题演讲的重磅报道(黄仁勋北京激情演讲2小时:搞定国内10大科技巨头 发布最强AI引擎!【附百张完整PPT】)。

演讲后,黄仁勋又接受了智东西等媒体的专访,这位粉丝爱称“老黄/黄教主”的CEO幽默且健谈,不仅谈及计算力、机器人、AI医疗、自动驾驶等问题、还与智东西交流探讨了关于“英伟达云”以及最近大火的“AI芯片”。

(智东西记者与老黄的合影)
一、“AI芯片”将无所不在
从最近的华为麒麟970、到苹果的A11,AI芯片/端智能似乎已经越来越成为趋势所在,AI在终端的落地也已经从软件层步入硬件层。那么这是否意味着未来我们将从云智能走向端智能呢?
面对智东西的这个问题,黄仁勋首先回答——未来是“云智能+端智能”的时代,AI将无处不在。
未来,像咖啡机、保温杯、麦克风、甚至耳环、鞋子这些小物件都会智能化,但是它们的处理芯片并不需要特别强大的通用智能,而是针对非常窄的专门领域进行智能化,比如一个麦克风,只需要声音方面的AI处理能力。
而云智能将会是通用智能,视觉、声音、数据等等,需要拥有一切AI处理的能力。而英伟达这些高性能、大功耗的GPU在云数据中心上有着切实的用武之地(比如老黄在上午的演讲中就特别提到了与BAT三朵云的合作,以及又宣传了一下基于新GPU Tesla V100推出的HGX云计算服务器)
不过,目前英伟达主打终端的GPU板卡是Jetson TX2,这块搭载4核CPU的Pascal架构GPU标准功耗为7.5W,远小于英伟达其他动辄几十上百W的GPU,但对于功耗极为敏感的超小型设备,这个功率还是太大。
为了解决这一问题,英伟达于昨天正式开源了DLA(深度学习加速器)架构,厂商可以免费下载这个专为IoT设备设计的AI架构,自己打造低功耗的AI芯片。
二、“英伟达云”在十月第一周推出
在今年5月时,英伟达曾在美国主会场举办2017 GTC,并且推出了“英伟达GPU云(NVIDIA GPU Cloud)”。

先别误会,英伟达并不是在和亚马逊AWS、微软Azure抢生意的,这个“英伟达云”是在这些云上运行的,并不为用户提供储存、计算等能力,而是可以理解成一套线上深度学习软件集合。
这个英伟达云能让人轻易地从零开始搭建一个深度学习的项目,不用买GPU、也不用搭环境,控制中心还是可视化的,可以看到你的账号之前的项目和正在运行中的项目,非常方便。
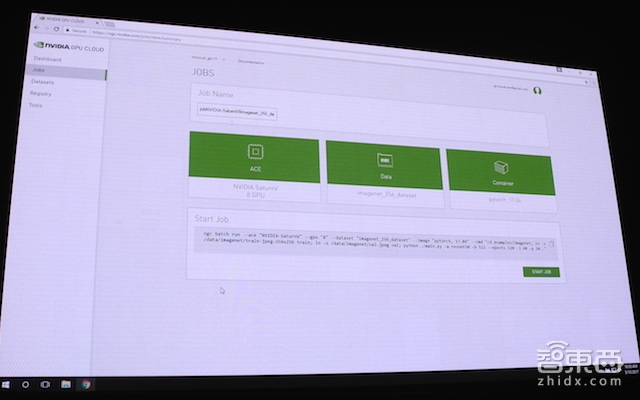
从当时的DEMO中可以看出,用户登录了英伟达云之后,只需要3步就可以创建自己的深度学习项目:
1、选择计算环境(既可以选择英伟达云、亚马逊云等,也选择本地GPU计算)
2、接入数据库(可以选择现有数据库如ImageNet,或者自己上传)
3、选择框架(如Caffe、TensorFlow等)
在本次GTC China上,黄仁勋并没有宣布关于这个英伟达云的新进展,智东西专门就这个问题询问了黄仁勋。老黄表示,英伟达云项目进展很顺利,如无意外今年十月的第一周就能正式跟大家见面了。
三、5-10年内革命机器人产业
同样是在昨天上午的Keynote演讲里,黄仁勋再次介绍了ISSAC机器人训练平台,并且正式宣布推出了世界第一款用于自动机器人的处理器(芯片)Xavier,为机器人提供从软件到硬件的全方位支持。

Xavier芯片已经用在京东的仓储机器人jROVER+京东送货无人机jDRONE等一系列自主机器当中。它集成了8核CPU、Volta TensorCore & CUDA GPU、传感器、8K HDR VP、以及CVA。可以应用在30TOPS的计算机视觉、深度学习等机器人所需要的技能领域,有着超高计算力与超高能效比。这款处理器将于2018年第一季度提供给早期合作伙伴,2018年第四季度全面推出。

ISSAC则是今年5月英伟达推出的用于训练机器人的增强学习世界模拟器(ISAAC Robot Simulator)模拟真实世界的逻辑、原理、物理定律等,然后再将机器放进这个世界里不断训练,并且不用遵循物理时间规律,将原本需要几年的训练压缩到几天甚至几个小时。
老黄认为,现在再看机器人,需要忽略传感器、电气化、自动化等等传统机械问题,转而关注于AI及自主机器(Autonomous Machine)。而想要打造自主机器人,则需要解决三个:
1)创造一个用于自主机器的AI平台,比如增强学习。
2)创造一个虚拟环境,让这些机器人在其中自己学会”怎么当一个机器人(learn to be a robot)”
3)当这些机器人学会怎么当机器人之后,我们海需要把AI大脑拿出来,放进一个专用的自主机器处理器中。
目前的这三个问题还没有完全解决,但是老黄表示,我们已经在努力啦!AI引擎、ISSAC虚拟机器人训练平台、还有Xavier处理器,英伟达的这三项工作正在并行推进中,属于一个打造产业基础架构的“打地基”过程。预计到了明天,这些“地基”就能打好了。
基础都打好后,产业界就可以在这些基础架构上快速推动生产。老黄预测,在未来5-10年间,这些将会为机器人产业带来难以置信的进步。
智东西随后也针对Xavier、ISSAC等话题跟英伟达智能机器副总裁Deepu Talla进行了专访,后续将会有详细报道,敬请期待~
四、GPU、CPU、ASIC之争
1)GPU不会取代CPU
首先是CPU,虽然在昨天上午的主题演讲中,老黄拿CPU开了不少涮,但是他认为归根到底,GPU永远不会取代CPU。CPU擅长处理所有问题,是通用处理器,而GPU则更适合处理专用问题,有时甚至能有着数十上百倍的性能优势。
因此,CPU+GPU的架构才是合理的。
2)比ASIC更灵活,市场更大、生态系统更丰富
正如前文所说,随着谷歌TPU、苹果A11等产品的推出,各公司打造自己定制化的AI芯片似乎已经越来越成为趋势所在。这种定制化AI芯片属于ASIC(专用集成电路,Application Specific Integrated Circuit),是根据特定的需求而专门设计并制造出的板卡。
由于是针对某种AI功能打造的,ASIC较之GPU,在某些单点性能上会有着明显的优势。比如谷歌的TPU,在TensorFlow框架下的计算性能比GPU更有优势,而一些IoT的定制AI板卡也会比GPU功耗更小。
老黄认为,GPU的通用性使得它不仅支持TensorFlow框架,还支持Caffe2、mxnet、PaddlePaddle等市面上所有深度学习开源框架,而且能做视频编解码、图像处理、语音等一系列AI应用,更加灵活。而更灵活则意味着市场机会更多、市场更大,研发预算更多,生态系统更丰富。
三年前,英伟达选择将GPU打造成一个专注于Tensor架构的执行处理器(如果觉得这个概念太生涩,那就大概理解成AI网络架构处理器吧),随后又衍生出TensorRT、TensorCore等辅助软件平台/加速器,使得GPU现在成为世界上最好的通用Tensor处理器。
其实,关于GPU和ASIC板卡的争论早已有之,尤其是谷歌的TPU,从项目宣布的那一刻起就有无数人拿TPU去跟GPU比较,比性能、比功耗、比延时等等,本次采访中也有不少人就此问题向老黄提问。
但也许,这个问题不应该这么比较。
现在市面上需要AI计算能力的公司成千上万,类似谷歌这样的科技巨头们,有技术、有资源、同时也有强烈的需求(公司的大体量决定了,只要每块板卡功耗降低一点,总体功耗就能降低许多)打造一块更加适合自己业务的AI板卡。
他们可以选择和芯片公司合作打造专用AI芯片,但是英伟达似乎更希望做一个通用的AI计算平台,瞄准更大的市场,这也是为什么老黄一再强调,往上看英伟达的GPU支持所有深度学习开源框架,往下看它支持所有AI应用。
从这两天传言特斯拉要“抛弃英伟达”联合AMD开发专用自动驾驶芯片的新闻中也可见,英伟达似乎并没有为哪家巨头独立打造专属AI芯片的意思。
至于谷歌或是特斯拉是否会靠售卖这些芯片盈利呢?短期内应该不会。两者产业链构成完全不同,卖芯片并不是谷歌或是特斯拉擅长的领域。
而对于更为广阔的市场而言,其他中小型公司并不具备这样的技术与资源,他们需要购买AI计算能力,而一块通用的、支持所有AI网络架构、支持所有、并且计算性能非常强大的GPU自然成了首选。当使用GPU的AI公司数量达到一定水平后,生态的力量也就显露了出来。
这也是为什么,在人工智能时代,英伟达的股价能够一路飙升,成为AI届的“当红辣子鸡”。
如果真要说对英伟达可能造成的影响,那大概就是谷歌会减少对GPU的购买吧。
当然从长期来看,英伟达也可能面临着AI计算能力云端化,AI芯片专业化并且平价化的趋势。对于前者而言,现在英伟达正努力推进云数据中心业务,而对于后者而言,英伟达也开源了DLA框架,暂时让厂家免费使用,打造自己的低功耗AI芯片。至于未来是否会靠DLA框架来收取专利费,成为新型商业变现模式,那就是另一个故事了。

